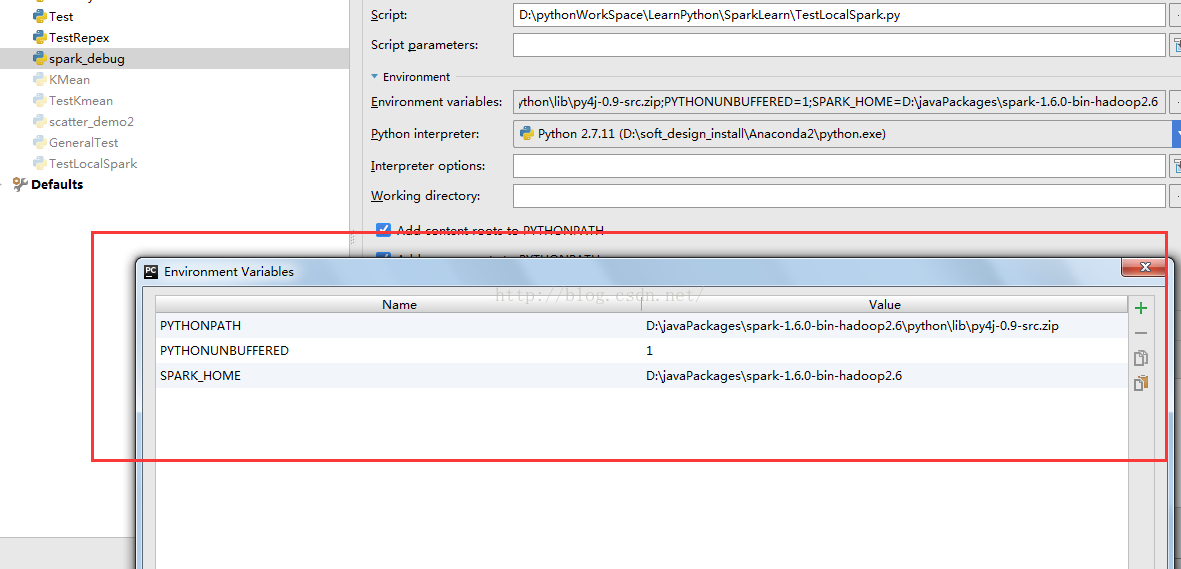
1.2 Spark环境变量配置
解压下载的文件,假设解压 目录为:D:\Spark-1.6.0-bin-hadoop2.6。将D:\spark-1.6.0-bin-hadoop2.6\bin添加到系统Path变量,同时新建SPARK_HOME变量,变量值为:D:\spark-1.6.0-bin-hadoop2.6
1.3 Hadoop相关包的安装
spark是基于hadoop之上的,运行过程中会调用相关hadoop库,如果没配置相关hadoop运行环境,会提示相关出错信息,虽然也不影响运行。
去下载hadoop 2.6编译好的包https://www.barik.net/archive/2015/01/19/172716/,我下载的是hadoop-2.6.0.tar.gz,解压下载的文件夹,将相关库添加到系统Path变量中:D:\hadoop-2.6.0\bin;同时新建HADOOP_HOME变量,变量值为:D:\hadoop-2.6.0。同时去github上下载一个叫做 winutils 的组件,地址是 https://github.com/srccodes/hadoop-common-2.2.0-bin 如果没有hadoop对应的版本(此时版本是 2.6),则去csdn上下载 http://download.csdn.net/detail/luoyepiaoxin/8860033,
我的做法是把CSDN这个压缩包里的所有文件都复制到 hadoop_home的bin目录下
二 Python环境
Spark提供了2个交互式shell, 一个是pyspark(基于python), 一个是spark_shell(基于Scala). 这两个环境其实是并列的, 并没有相互依赖关系, 所以如果仅仅是使用pyspark交互环境, 而不使用spark-shell的话, 甚至连scala都不需要安装.
2.1 下载并安装Anaconda
anaconda是一个集成了python解释器和大多数python库的系统,安装anaconda 后可以不用再安装python和pandas numpy等这些组件了。下载地址是 https://www.continuum.io/downloads。将python加到path环境变量中
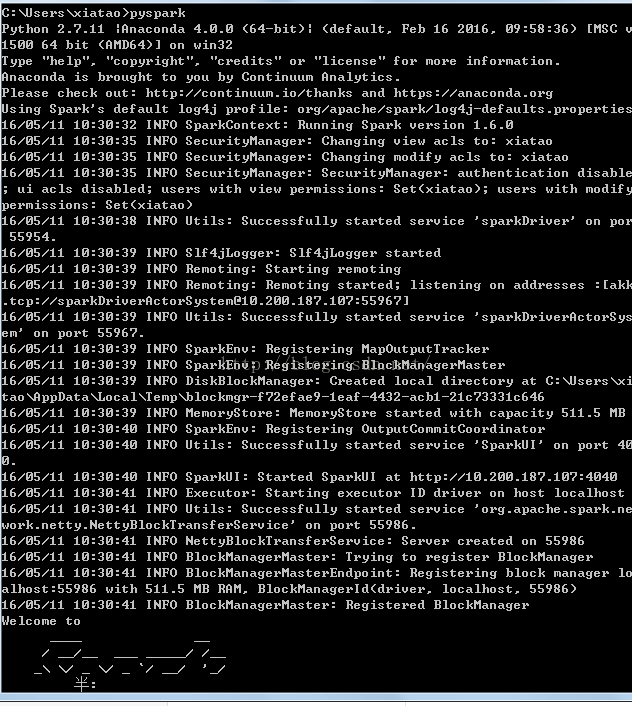
三 启动pyspark验证
在windows下命令行中启动pyspark,如图:
四 在pycharm中配置开发环境
4.1 配置Pycharm
更详细的材料 参考 https://stackoverflow.com/questions/34685905/how-to-link-pycharm-with-pyspark
打开PyCharm,创建一个Project。然后选择“Run” ->“Edit Configurations”
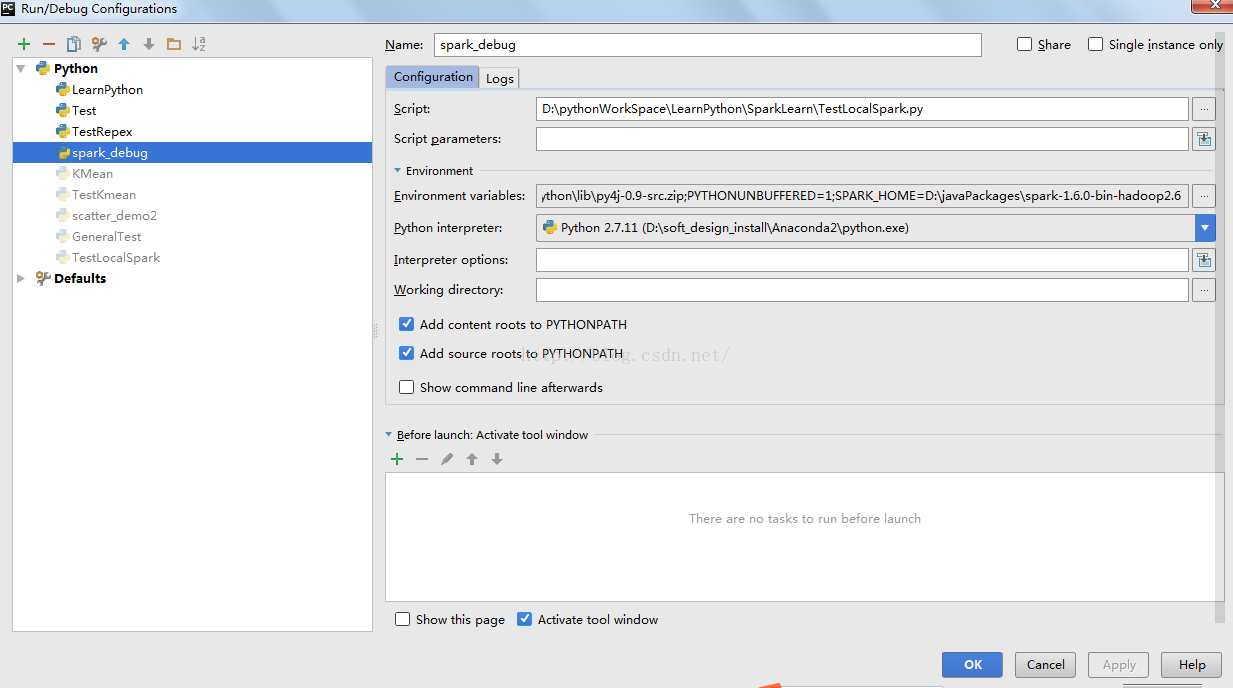
选择 “Environment variables” 增加SPARK_HOME目录与PYTHONPATH目录。
4.2 测试程序
先测试环境是否正确,代码如下:
import os
import sys
# Path for spark source folder
os.environ['SPARK_HOME']="D:\javaPackages\spark-1.6.0-bin-hadoop2.6"
# Append pyspark to Python Path
sys.path.append("D:\javaPackages\spark-1.6.0-bin-hadoop2.6\python")
try:
from pyspark import SparkContext
from pyspark import SparkConf
print ("Successfully imported Spark Modules")
except ImportError as e:
print ("Can not import Spark Modules", e)
sys.exit(1)
如果程序可以正常输出: "Successfully imported Spark Modules"就说明环境已经可以正常执行。
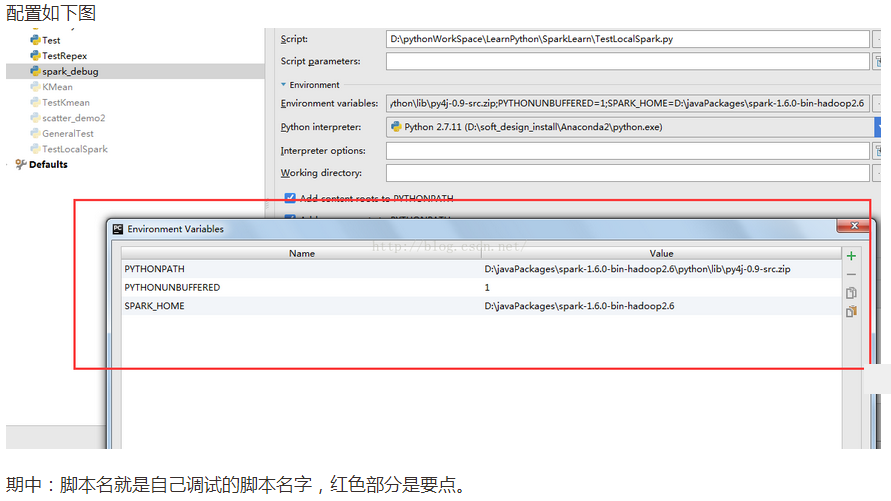
如下图,黄色框内的是具体的spark环境和python环境:
测试程序代码来源于 github :https://gist.github.com/bigaidream/40fe0f8267a80e7c9cf8
转原博客地址:http://blog.csdn.net/huangxia73/article/details/51372557
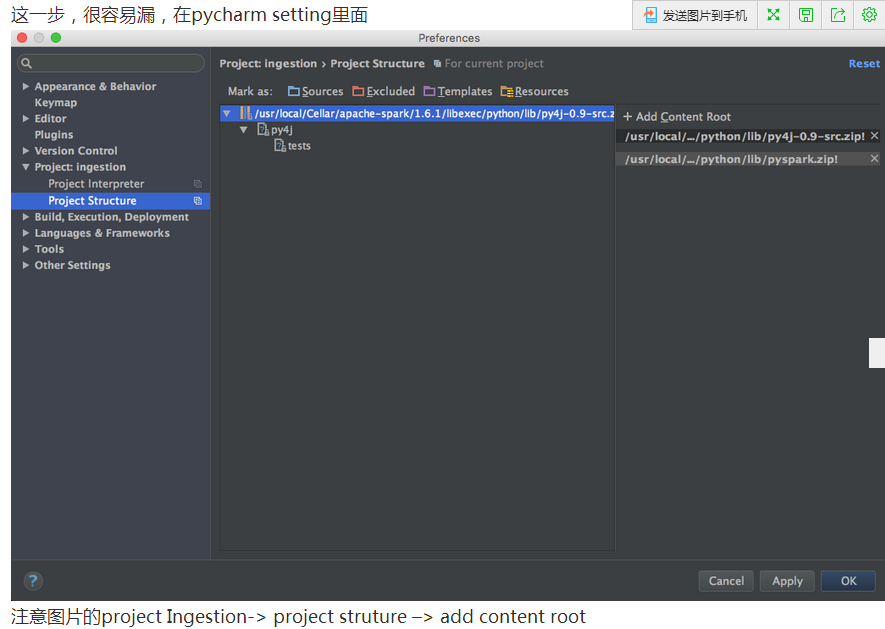
注意:
可能会报没有 py4j ( 它是python用来连接java的中间件)
可以用命令安装:pip install py4j