前言
我爬虫课程的文字版内容沉淀在语雀的知识库中,一开始感觉很不错,随着课程一直在卖,很快就超过了200人的限制,我已经是个人版中最高级的会员了,但语雀知识库的协作人数依旧限制在200人...即花钱无法解决问题。
先说一下我的需求,我需要一个可以承载一批文档的地方,做到只给固定的一些用户阅读。
我不希望对每篇文章都进行授权处理,希望有类似共享文件夹的效果,只对文件夹进行权限控制,用户可以访问文件夹,便可以访问其中的内容。
我不希望用户可以修改文档内容,但却希望他们可以留下评论,比如写些疑惑,我对疑惑的答疑也会沉淀在文档中。
语雀知识库是我一开始选择的方案,但问题就是人数的限制,官方似乎也没打算解决,当然,我也没想着解决,再复制多个一个知识库,不就又可以承载200人了。
但,一篇内容要在多个知识库中同步,每次人员到达上限时,又要开新的知识库,最终还是让我失去的耐心,所以我打算进行迁移。
先说,迁移的主观感受:巨难受....
我想着,先用腾讯文档,这样用户不需要注册新的应用(使用语雀,需要注册语雀),简单微信授权便可以直接阅读文档了。
但遇到了一些问题,然后我又尝试了石墨、金山、飞书,最终矮个里挑将军,选择了飞书作为新的承接主体。
因为每款文档应用都不希望用户迁移,所以你会遇到一些麻烦....本文便记录一下我遇到的问题和我的解决方案。
语雀的导出限制
当我们希望导出整个知识库时,会发现,你只能导出图片版PDF和语雀特有的lakebook格式。
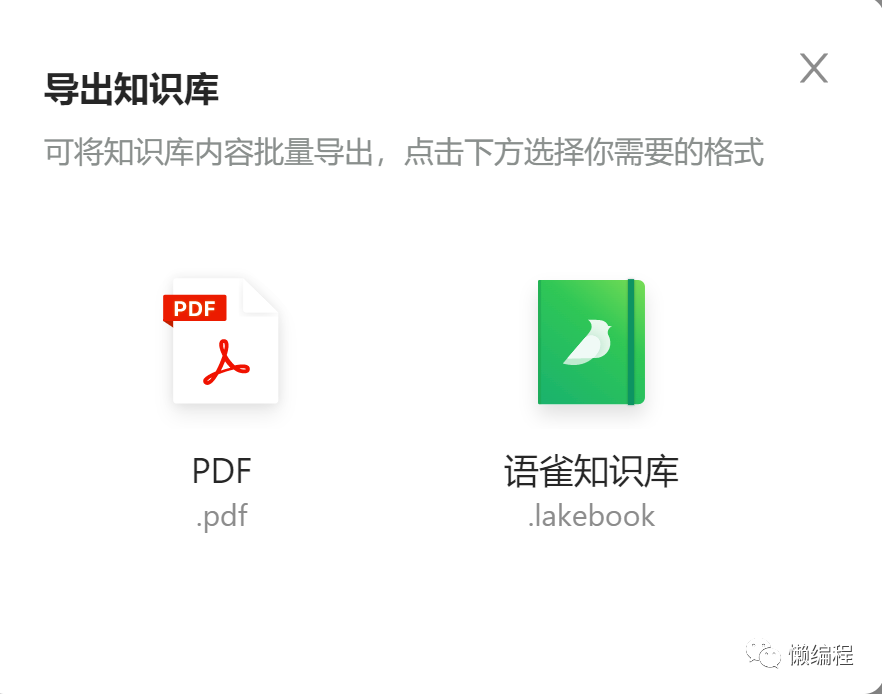 什么叫图片版PDF?就是PDF文件中的内容其实是图片,即你无法对里面的内容进行修改,但就算是文字版的PDF,修改起来也很麻烦,这是PDF格式限制导致的。
什么叫图片版PDF?就是PDF文件中的内容其实是图片,即你无法对里面的内容进行修改,但就算是文字版的PDF,修改起来也很麻烦,这是PDF格式限制导致的。
至于lakebook,是语雀特意搞的格式,是混淆的,美其名曰,保护用户数据,但用脚指头想都知道,语雀限制了导出,让你无法轻松将数据迁移走。
这有点像一些数据类Saas服务,导入功能非常完善,你上手起来非常快,当企业感觉不满足需求,想导出数据时,会发现,基本的导出格式,居然没有...
语雀知识库的导出是搞不了了,我可不想硬刚lakebook,但语雀可以将单篇文章导出成markdown或word。
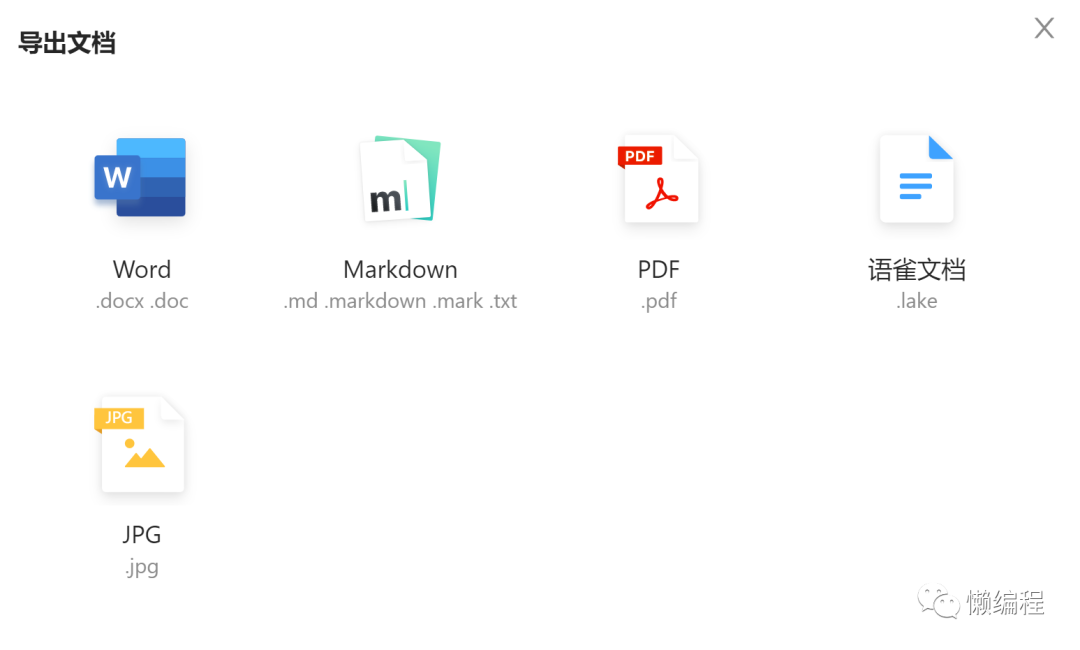
考虑多,我有近120篇文档,要是通过手动导出,人会傻掉,所以决定再研究一下,很快,我发现了语雀提供API操作,其中就有获得文档具体内容的API。
关于语雀API的细节,可以看它的对接文档:https://www.yuque.com/yuque/developer/api
比较简单,就是response中的数据格式跟文档表述的格式出入较大,很多字段,其实我也不知道干啥的,通过语雀提供的【获取单篇文档详细信息】的接口,我们可以获得文档的原始markdown。
我对接完多个接口,然后将数据保存到本地,保存方法如下:
def save_docs(namespace):
save_docs_dir = 'docs'
if not os.path.exists(save_docs_dir):
os.makedirs(save_docs_dir)
with open('docs_list.json', 'r', encoding='utf-8') as f:
docs_list = f.read()
docs_list = json.loads(docs_list).get('data', [])
for d in docs_list:
slug = d['slug']
title = d['title']
url = urljoin(root_url, f'repos/{namespace}/docs/{slug}')
resp = requests.get(url, headers=headers, params={'raw': 1})
result = resp.json()
markdown_content = result.get('data', {}).get('body', '')
# 正则去除语雀导出的<a>标签
markdown_content = re.sub("<a name=\".*\"></a>","", markdown_content)
title = title.replace('/', ',')
with open(os.path.join(save_docs_dir, f'{title}.md'), 'w', encoding='utf-8') as f:
f.write(markdown_content)
完整代码,翻到文末则可获得。
至此,我将知识库中的所有文档都保留了下来。
这里有个无法避免的坑,那便是语雀API返回的数据中,不会包含任何目录结构的数据,即我们同步到其他平台时,需要我们自己手动再整理一次文档的排列....
腾讯、金山、石墨之痛
导出后,我立刻着手弄腾讯文档,我先查了一下腾讯文档的文档,判断一下,它的权限功能是否满足我的需求,完全满足,他可以做到只让文档被微信群中的用户阅读。
然后我着手导入,然后就发现,腾讯文档不支持markdown的导出,是的,如此基础的功能,腾讯文档没有...
那我将markdown转成docx,再用腾讯文档导入不就好了。
简单一搜,便找到了pandoc(https://github.com/jgm/pandoc, 26.6k star)项目,看到这么多star,比较放心,直接下载来用。
嗯,转的效果不太好,导入到腾讯文档中,效果就更不好了,样式完全丢失...接受不了。
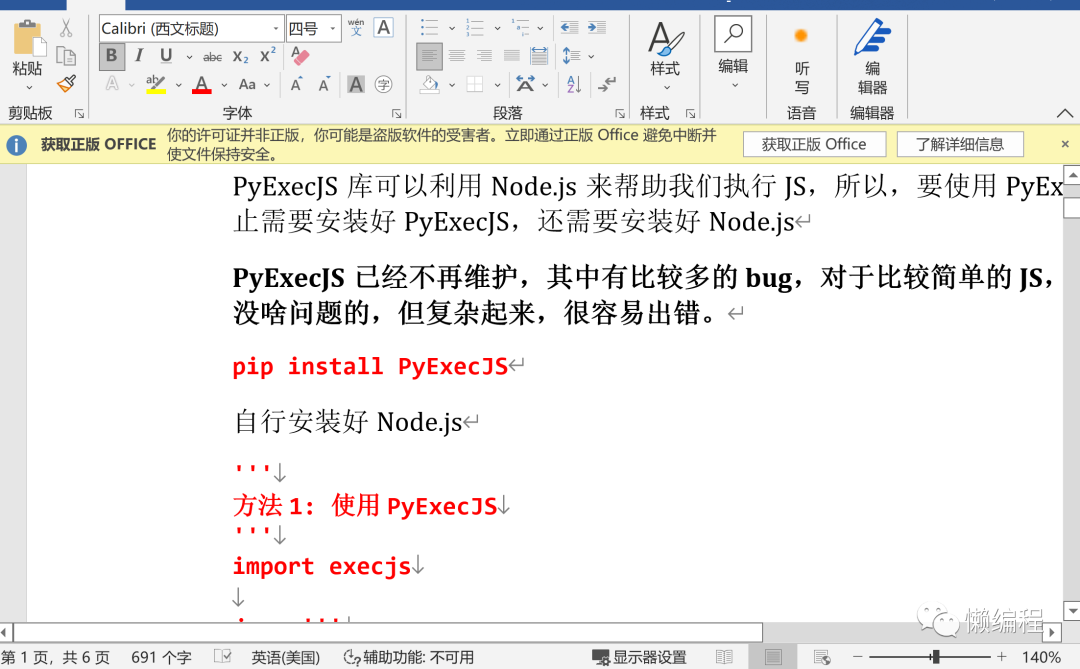
不死心的研究了半天,发现,腾讯文档只能在编辑在线文档时,开启markdown语法支持,到导入时,真的不支持markdown,吐了。
既然如此,我就立刻换成金山文档,也是个老牌子,这次,我先看是否支持markdown,嗯,金山也不支持...金山的优点是,其在线文档的使用方式与本地使用word软件编辑文档相似,但不是我需要的。
随后,便是石墨,石墨是支持的markdown导入的,但石墨的分享时,会要求你注册石墨账户,权衡了之下,打算先研究一下飞书先。
飞书文档
飞书文档的权限控制也可以满足我的需求,但需要用户加我的好友才行,相比于石墨,麻烦了一点,但考虑到字节收购了石墨,借鉴石墨来搞飞书文档的这一层,打算还是着重用一下飞书文档。
我在飞书文档上,创建了文件夹,然后将markdown批量导入
一个问题是,在飞书文档中直接看markdown样式是比较丑的,而且语雀中的图片在飞书文档的markdown样式中无法正常显示,如下图:
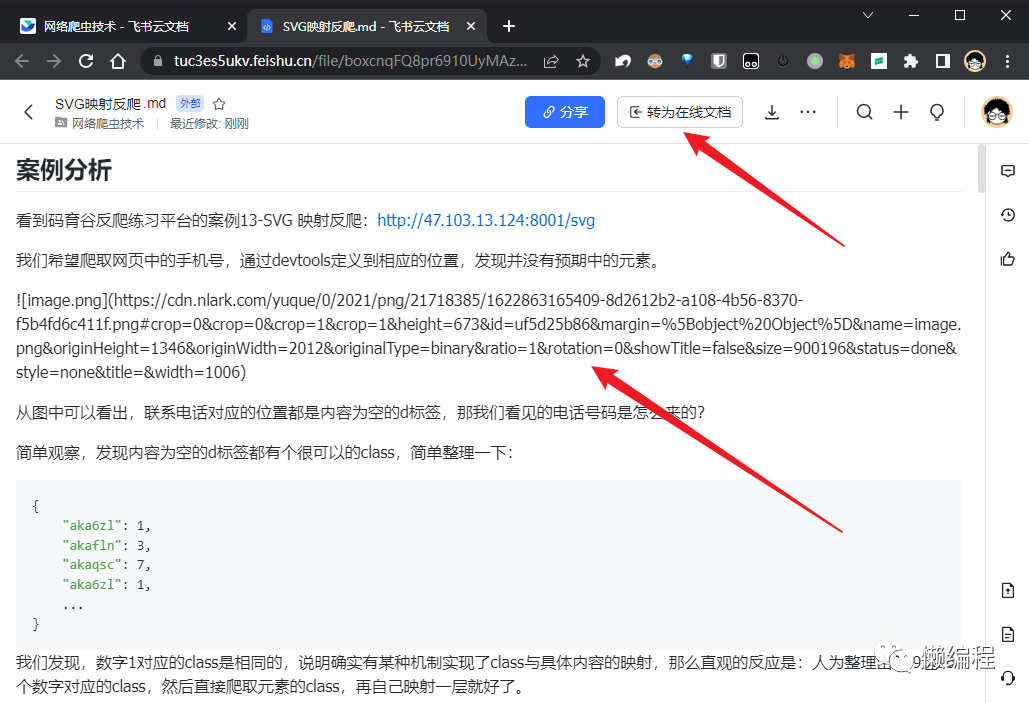
我们在飞书文档中进入其中一个markdown,发现飞书支持将他转为在线文档,转为在线文档后,样式就美观很多,而且图片等内容也正常了。
那问题又来了,120多个markdown文档,我一个个点显然不合理,很自然的,我去找飞书的API,在飞书开放平台中,可以找云空间、文档的API。
阅读完这些文档后,发现...没有markdown转在线文档的API,这就...难受了。
简单思索一下,决定用爬虫技术解决一下。
如果写selenium自动化,可能会费点时间,还是直接抓一下我在飞书文档中点击转在线文档时,请求的API吧。
当我点击【转为在线文档】时,飞书发送create请求,相关图片如下:
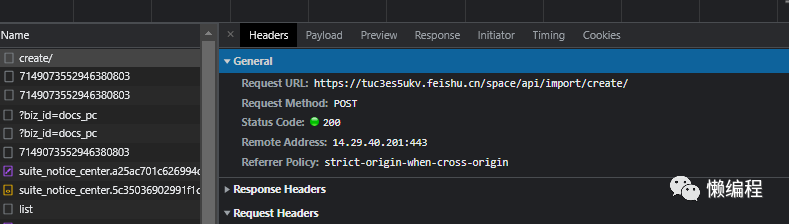
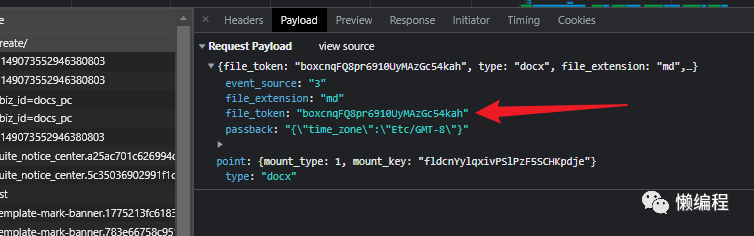
经过简单分析,发现file_token参数用于指定具体的文档,怎么拿到file_token便是关键。
基于爬虫课里提供的JS Hook,可以快速定位出file_token是什么时候生成的,里面的值又是哪个方法来,但在当前的需求下,这种方式也显得麻烦。
简单搜索分析,发现file_token就在html中,其中一个例子:
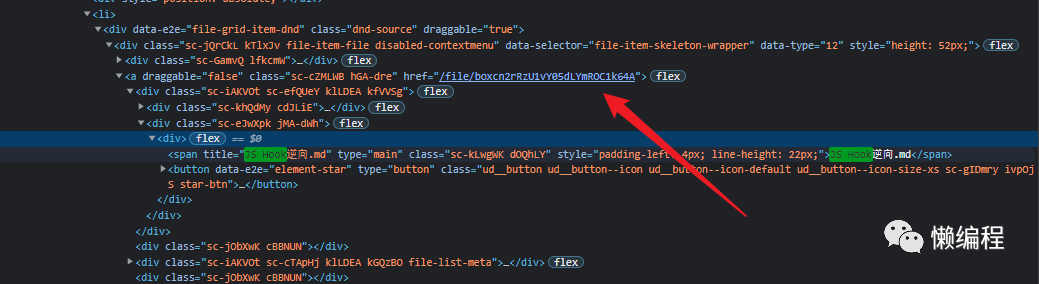
最直接的想法便是将网页的html内容全部复制下来,然后正则匹配,获得其中的内容就好了。
但飞书只将25个文档的内容放在html中,当你滚动鼠标中,相关div元素会变成其他的内容。
简单而言,你滚动就刷新,新的file_token会覆盖就的file_token。
你可以滚动几次,每次都手动保存一下html,或者利用selenium自动滚动,实时获取,但更好的方式是利用JavaScript的Mutation事件。
利用Mutation事件,你可以实时监控DOM树中某个节点的变化。我们基于Mutation事件写出如下JS代码。
// 展示markdown文档类别的父div
mydocs = document.querySelector("#mainContainer > div.app-main-container.flex.layout-row.explorer-v3 > div > div.sc-llYToB.bepCke > main > div.sc-ewSSRw.fDTLhF > div.sc-eicnZh.bSQUzR > div.sc-fvxABq.eCsope.explorer-file-list-virtualized__container.explorer-file-list-virtualized__container-a > div:nth-child(1) > div")
// 监控配置,属性、子节点、字符数据、子树的变化都监控上
DocumentObserverConfig = {
attributes: true,
childList: true,
characterData: true,
subtree: true
};
hrefs = []
DocumentObserver = new MutationObserver(function() {
// 每次div变动,都将其下a节点的href属性记录起来
var items = mydocs.getElementsByTagName('a')
for (let i of items ){
hrefs.push(i.href)
}
});
DocumentObserver.observe(mydocs, DocumentObserverConfig)
在chrome的console中执行上面代码,滚动几次鼠标,hrefs变量中便塞满了href,其中就包含了我们需要的file_token,再利用JS对hrefs做一次去重。
function unique (arr) {
return Array.from(new Set(arr))
}
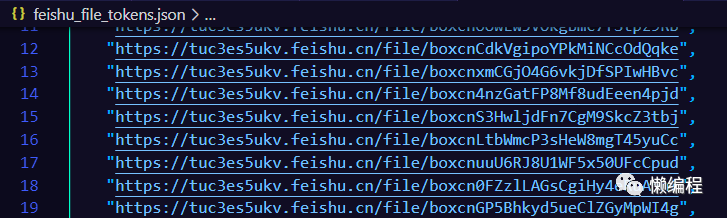
result = unique(hrefs)
将获得的结果保存成json文件,如下图:
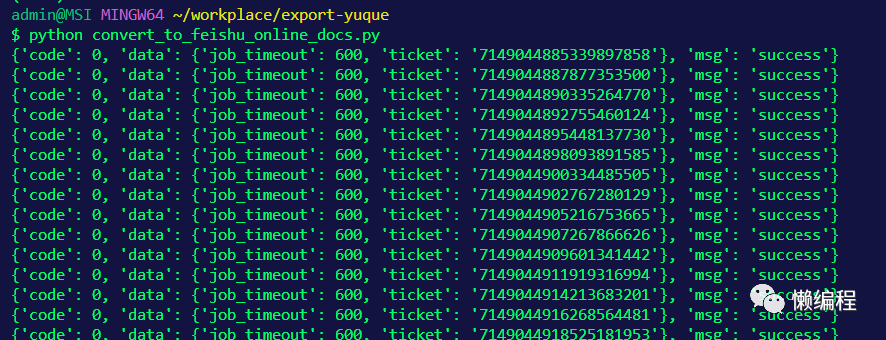
然后,利用curl to python的技巧(爬虫课中提过该技巧),复制前面的create请求,修改一下代码逻辑,让file_token从feishu_file_tokens.json中获取,然后批量请求,便可以实现markdown文件批量转成飞书在线文档的效果:
然后,就是手动整理目录结构了,这个没啥办法,因为在语雀API中没有结构数据,当然,你可以利用OCR的形式,尝试恢复结构,但比较麻烦,就手动弄弄了。
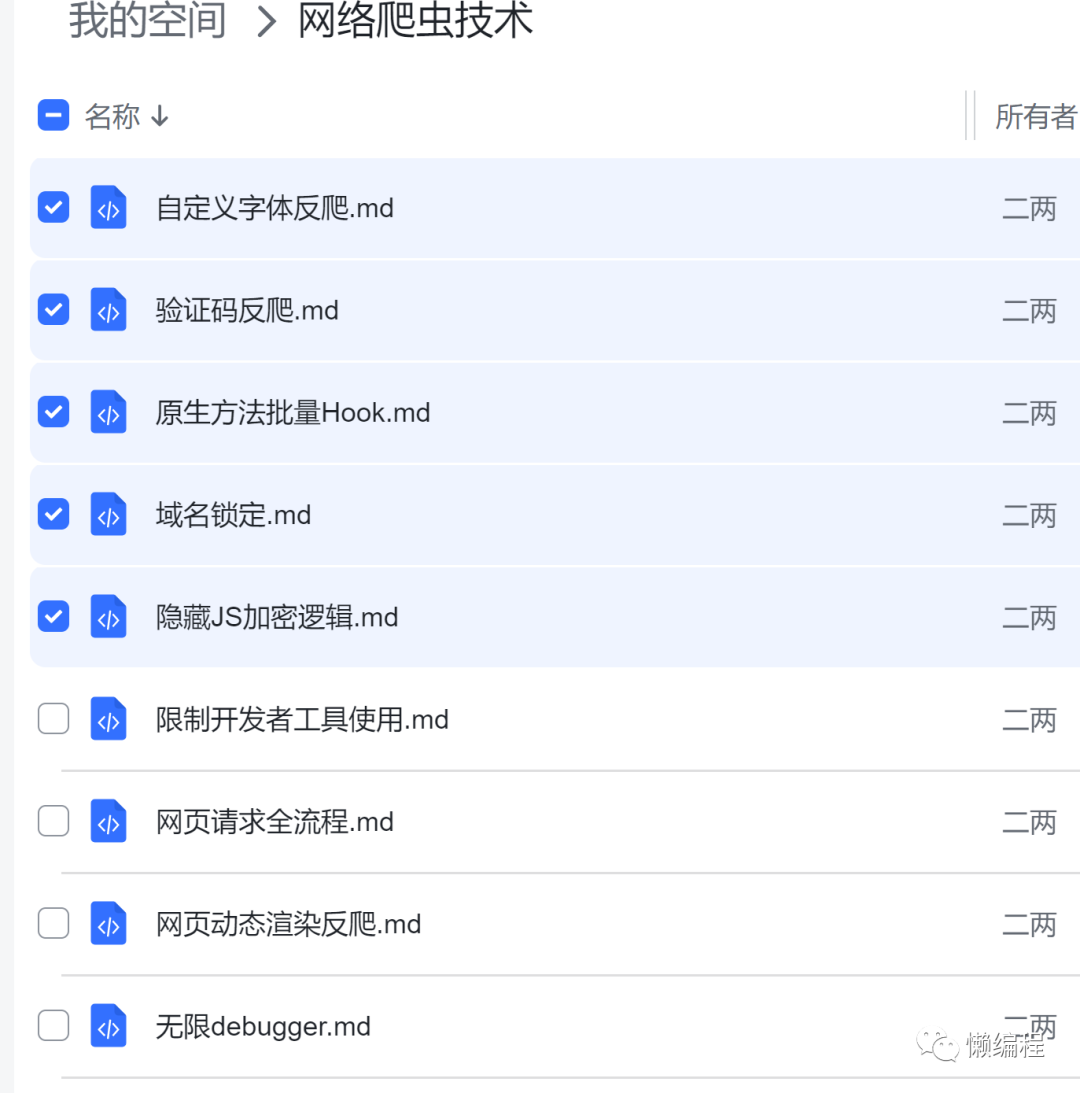
最终效果如下:
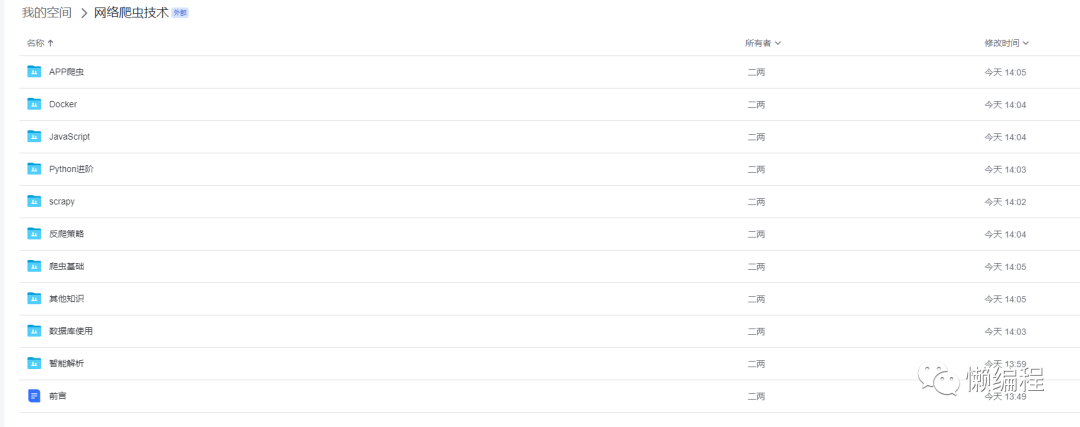
结尾
虽然解决了,但开心不起来,文档类的工具,当你要迁移时,会发现,都不太好用。
本文相关代码我整理弄到了github上:https://github.com/ayuLiao/export-yuque
我是二两,下篇文章见。