
论文地址:https://arxiv.org/pdf/2108.09702.pdf
代码地址:https://github.com/dongzhang89/SR-SS
出处:ICCV2021
一、背景
语义分割的目的是对图中的每个像素进行分类,现有的效果较好的网络基本可以解决 85% 的问题,然而其他15%的问题作者发现基本上是由于以下两个原因:
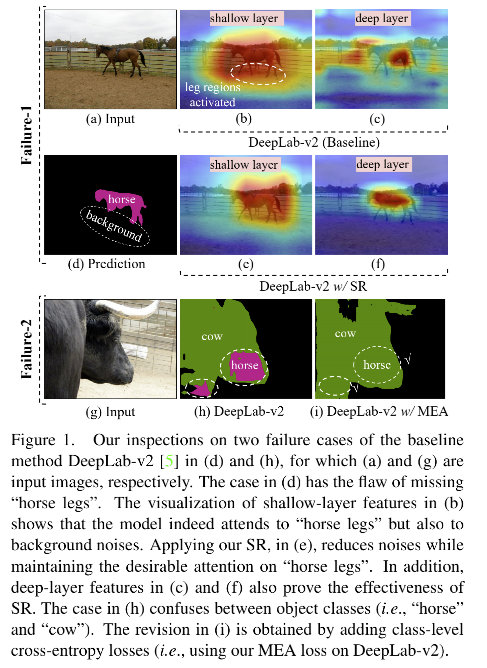
- Failure-1:缺失了小目标或目标的某一部分(该问题的原因在于未充分利用细节部分,如图1d的“马腿”)
- Failure-2:错误预测大目标的某一部分的类别(该问题的原因在于未充分利用视觉上下文信息,如图1h)
二、动机
缓解 Failure-1:
作者在图 1 中表示了自己的观点,作者发现如图 1b 所示,在浅层的时候小目标的各个部分都可以很清楚的看到,所以,如果能较好的利用这些信息,则可以缓解 Failure-1,如图1e所示。
现有的方法如 Hourglass、SegNet、U-Net、HRNet,基本上都通过reshape+combining feature 的方法来解决。共性实现方式大多是这样的:pixel-wise addition, map-wise concatenation, pixel-wise transformation,但是这都会引入很多的参数量。
缓解 Failure-2:
作者发现如图 1 中的“牛”这个目标,如果使用 image-level 的 classification loss 来训练模型,则可以很好的缓解 Failure-2:即在 pixel-level 来混合 foreground objects (‘cow’) 和 local pixel cues (‘horse’)。直观的原因在于 loss 会惩罚预测成没有看到的 class-level 的上下文(如:牛不会有一个马嘴)。
所以,本文中作者使用这样的直观想法并且提出了一个 loss function 来每个图像提升上下文的编码。
三、方法
作者提出了 Self-Regulation,其有三个不同种类的 loss 组成:
- Multi-Exit Architecture loss(MEA):对每个block 应用 image-level multi-label classification loss+ pixel-level segmentation loss
- Self-Regulation loss using Feature maps(SR-F):Teacher 和 Student block 输出特征之间的蒸馏 loss
- Self-Regulation loss using classification Logits(SR-L):Teacher 和 Student block 的分类得分之间的蒸馏 loss
MEA Loss: Multiple-Exit Architecture(MEA),首次提出是在 [23] 中,为了提升模型的推理速度,本文中,使用 MEA 是为了在一个模型中同时训练分类和分割任务。
SR-F && SR-L Loss:图3展示了 conv 结构和 U-shape 结构的 pipline
- 在标准的 U-shape 结构中,Encoder 是由一系列卷积模块组成,Decoder 是由相同数量的解卷积模块组成。
- 在 Encoder 中,最浅层 block 输出的特征图被作为深层 block 的真值(在计算 SR-F loss时)
- 在 Decoder 中(或 conv 结构的Encoder),最深层输出的 classification 概率被当做真值来指导浅层 block 的学习(在计算 SR-L loss时)
- 在反向传播 loss 时,模型在每个 layer 同时被指导学习 pixel-level(被最浅层指导)和 semantic-level(被最深层指导)的信息,所以能够生成较好的特征表达。

SR-F Loss:Shallow to Deep
如图3所示:
- 每个卷积 block 或解卷积 block 可以被看做独立的特征抽取器,ending block(最浅或最深block)可以在不同情况下被当做 teacher 或 student ,因为本文的self-regulation(自调节)是双向的。
- middle blocks 永远都是 student
- Teacher 和 Student 的转换函数分别为:
T
θ
(
x
)
T_{\theta}(x)
Tθ(x) 和
S
ϕ
(
x
)
S_{\phi}(x)
Sϕ(x),其中
θ
、
ϕ
\theta、\phi
θ、ϕ 分别为对应的网络参数
SR-F Loss 的目标:让网络更多的保留浅层blocks保留下来的细节信息
实现方法: 使用最浅 block (即第一个)作为 Teacher(Shallow Teacher)来控制深层 blocks (Deep Students)
Loss 第一步: 交叉熵损失
使用 cross-entropy 来衡量 Shallow Teacher 的特征图
T
θ
[
1
]
T_{\theta}^{[1]}
Tθ[1] 和第 i 个 Deep Student 特征图
S
ϕ
[
i
]
S_{\phi}^{[i]}
Sϕ[i] 之间的距离,得到如下 SR-F Loss:

-
i
∈
[
2
,
N
]
i\in[2,N]
i∈[2,N],
N
N
N 为 conv block 的个数
-
t
j
t_j
tj:
T
θ
[
1
]
T_{\theta}^{[1]}
Tθ[1] 的第 j 个位置的向量
-
s
j
s_j
sj:
S
ϕ
[
i
]
S_{\phi}^{[i]}
Sϕ[i] 的第 j 个位置的向量
-
M
M
M:特征图大小
Loss 第二步: 使用知识蒸馏(KD)
为了提高效率,作者使用了知识蒸馏的温度控制方法[17],Loss 如下:

- 每个特征图的
t
j
1
/
τ
t_j^{1/ \tau}
tj1/τ 和
s
j
1
/
τ
s_j^{1/ \tau}
sj1/τ 都被归一化了
-
τ
\tau
τ 是温度参数,能起到平滑空间的效果,值越大,对特征图中的最大值和最小值的差距抑制越大
Loss 第三步: 对所有 Deep Students 求和

SR-L Loss:Deep to Shallow
SR-L 的目标:让网络的浅层 block 能够捕捉更多的全局上下文信息,来更好的应对背景的噪声
实现方法:
-
将最深层作为 Teacher(Deep Teacher),来指导所有的浅层(Shallow Students)
-
作者认为,最深层输出的 classification 概率得分包含了高层的语义信息,所以将 Deep Teacher 的类别得分作为指导
-
给定 Deep Teacher 的类别得分
T
θ
[
N
]
T_{\theta}^{[N]}
Tθ[N],和 Shallow Students 的得分概率
{
S
ϕ
[
k
]
}
k
=
1
N
−
1
\{S_{\phi}^{[k]}\}_{k=1}^{N-1}
{Sϕ[k]}k=1N−1,作者同样使用公式1-3的方法,不同的是计算两者的概率 cross-entropy 损失,所以 SR-L loss公式如下:

Overall Loss Function:
下面用 layer-wise 的形式展示了 SR Loss,该 loss 能同时进行分类和分割,如图2所示,由多个分类器和分割器组成:
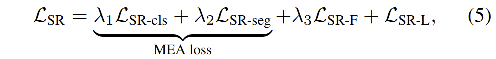
-
L
S
R
−
s
e
g
L_{SR-seg}
LSR−seg 和
L
S
R
−
c
l
s
L_{SR-cls}
LSR−cls 都是使用 one-hot 编码为真值的 cross-entropy loss,这一对组成的 loss 叫做 MEA loss
-
L
S
R
−
F
L_{SR-F}
LSR−F 和
L
S
R
−
L
L_{SR-L}
LSR−L 通过学习由其他层产生的 “soft knowledge” 来进一步提升网络的效果
-
λ
1
=
0.2
\lambda_1=0.2
λ1=0.2,
λ
2
=
0.8
\lambda_2=0.8
λ2=0.8,
λ
3
=
1
\lambda_3=1
λ3=1
四、效果
1、消融实验:

2、weakly-supervised 方法的对比

3、fully-supervised 方法对比

4、可视化

- 上半部分为在 pascal voc 上的效果,可以看出在baseline中预测有误的像素,在使用了 MEA loss 后都有所改善,这得益于模型中每层都学习了更多的语义和细节信息。
- 在使用 SR loss后可以看出,模型对一些小的目标部分的效果更好了(如 horse legs 和 horse tail)
- Pascal 中失败的部分:所有方法都对显示器的 neck 部分分割失败了(绿色虚线框),也可能是因为分类器在训练显示器这个类的时候,很少关注 neck 部分
- Cityscapes 中失败的部分:小的目标如远处的交通信号没有被分割出来