
最近发生了一件大事儿,APIJSON 再也不用担心被人质疑性能问题了哈哈!
某周三腾讯 CSIG 某项目组(已经用 APIJSON 做完一期)突然反馈了查询大量数据性能急剧下降的情况:
某张表 2.3KW 记录,用 APIJSON 万能通用接口 /get 查数据 LIMIT 100 要 10s,LIMIT 1000 要 98s!
可把我吓了一跳,这么慢还怎么用。。。想了会先让他们 Log.DEBUG = false 关掉日志看看:
还同样那张表,还是同样的同域 CURL 请求 /get,LIMIT 100 降为 2s,LIMIT 1000 降为 30s。
看起来勉强够用,一般都是分页查 10 条 20 条的样子,但他们的业务“LIMIT 1000 的需求还挺多的”。
这可是腾讯内第一个用 APIJSON 的团队及项目,不仅用了好几个月,还在内网写了多篇文章帮忙推广,
怎么都不能辜负他们的信任和期望,更不能让这个事件成为 APIJSON 性能差的污点从而影响用户口碑。

我看着日志寻思着应该是数组内主表生成了 1000 个 SQLConfig 并调用 getSQL 等过程导致解析耗时过长,
而除了第 0 条,剩下的 999 条记录都完全没必要重复这个过程,尤其是期间大量打印日志非常耗时。
当时是为了兼容多表关联查询,自己的业务又几乎没有 LIMIT 100 以上的需求,所以影响不大就忽略了。
现在如果把第 0 条数据的解析结果(ObjectParser, SQLConfig 等类及变量状态)缓存起来给后面的复用,
那不就可以把 2s 压缩到只比 SQL 执行耗时 133ms 多出少量 APIJSON 解析过程耗时 的时长了?
“我有方案了,应该可以把 2s 优化到 200ms 左右” “我这周末优化下” 我拍着脑门给出一个承诺。
这个组的后端同事职业本能地探究细节:“现在的 30s 主要耗时在哪里?” “怎么搞?”
“执行 SQL 133ms 耗时正常,整体慢是 日志(大头) 和 解析(小头) 的锅” “SQLExecutor 应该一次返回整个列表给 Parser”
看起来这个同事得到了些许安慰:“这个可以优化的话,LIMIT 1000 耗时 30s 估计也只要几秒了”
周末除了 APIAuto-机器学习 HTTP 接口工具 的简单更新:
- 零代码回归测试:用经验法解决冷启动问题,在没有校验标准时也能进行断言
- 自动生成注释:新增根对象全局关键词键值对的语法提示
剩下重点都是 APIJSON 的性能优化,我分成了两步:
1.查数组主表时把 SQLExecutor.execute 查到的原始列表全部返回,缓存到新增的 arrayMainCacheMap
https://github.com/Tencent/APIJSON/commit/bb4896d208e813a3f5eec21f60e1c083621b1f92
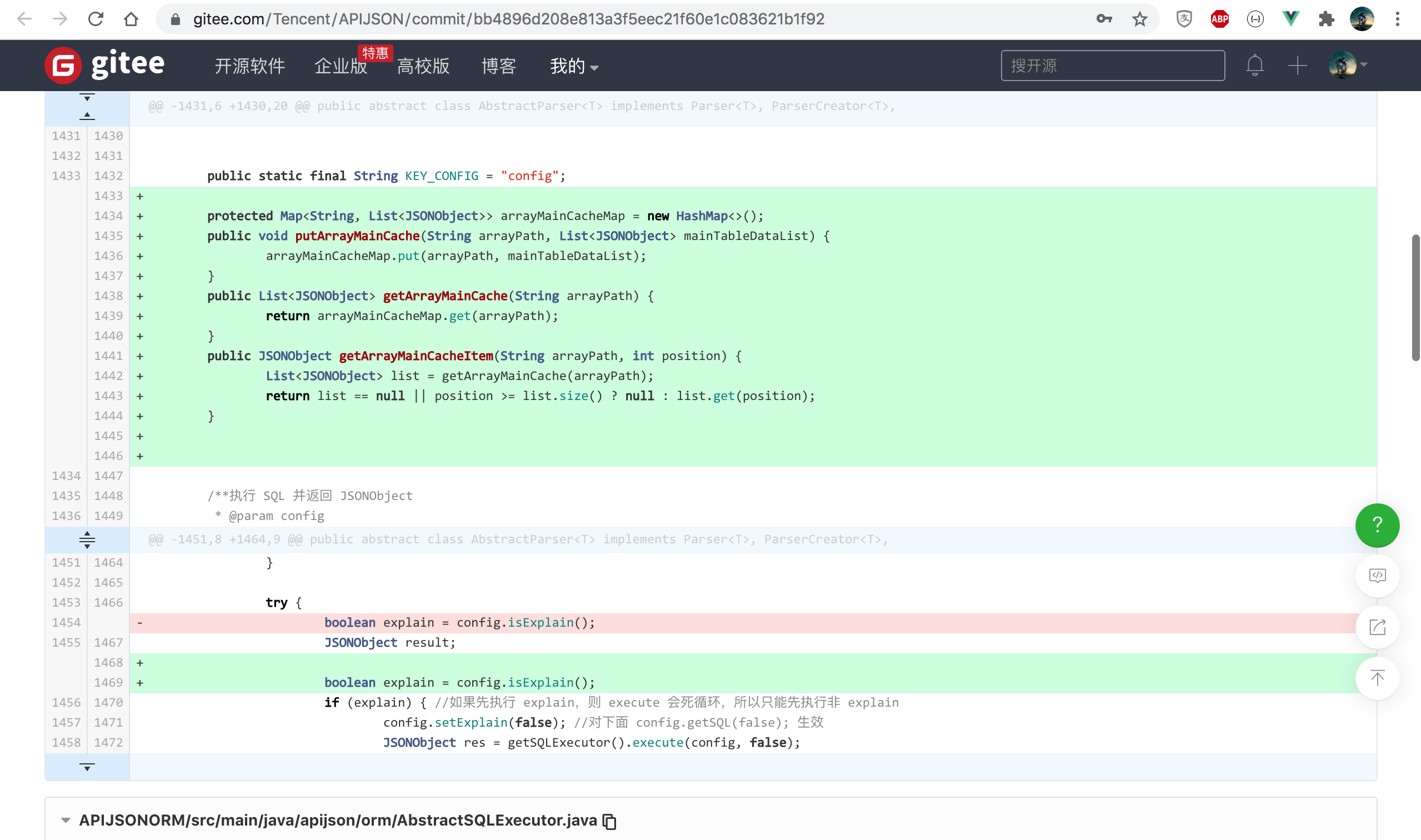
2.查数组主表时把第 0 个 ObjectParser 实例缓存到新增的 arrayObjectParserCacheMap
https://github.com/Tencent/APIJSON/commit/a406242a81f2b303a1c55e6a4f5c3c835e62e53a

期间尝试修改返回类型 JSONObject 为 List<JSONObject> 发现改动范围过大,而且只有这个场景需要,
于是就改为在 JSONObject 中加个肯定不会是表字段的特殊字段 @RAW@LIST 来带上 ResultSet 对应的 List;
改完后性能确实大幅提升,但发现除了第 0 条,后面的数组项全都丢了副表记录,于是反复调试修改多次终于解决;
接着按第 2 步优化,性能再次大幅提升,手动测试也没问题,用 APIAuto 一跑回归测试发现计数字段 total 没返回,
这次运气好点,因为之前也碰到过同样问题,我解决后加了比较详细的注释说明,所以回顾审视后没多久就解决了。
每步完成后,我都对 TestRecord[], 朋友圈多层嵌套列表 等查询 LIMIT 100 用优化前后代码各跑 10 次以上,
最终无论是 都取最小值,还是 去掉几个最小和最大值后其余取平均值,得出的前后性能对比结论基本一致:
步骤 1 将单表列表耗时降低为原来 42%,朋友圈多层嵌套列表降为原来的 82%;
步骤 2 将单表列表耗时降低为原来 60%,朋友圈多层嵌套列表降为原来的 77%;
算出总体上将单表列表耗时降低为原来 25%,朋友圈多层嵌套列表降为原来的 63%
MacBook Pro 英寸 2015 年初期 13 Intel i5 双核 2.9 GHz,250G SSD,OSX EI Capitan 10.11.6
Docker Community Edition 18.03.1-ce-mac65 (24312)
MySQL Community Server 5.7.17 - 跑在 Docker 里,性能会比直接安装的差不少
Eclipse Java EE Neon.1a Release (4.6.1) - 全量保留日志,比用有限保留日志的 IntelliJ IDEA 2018.2.8 (IU-182.5262.2) 慢一个数量级
实测结果如下:
TestRecord[] 查询前后对比 耗时降至 35%,性能提升 186% 为原来 2.9 倍:
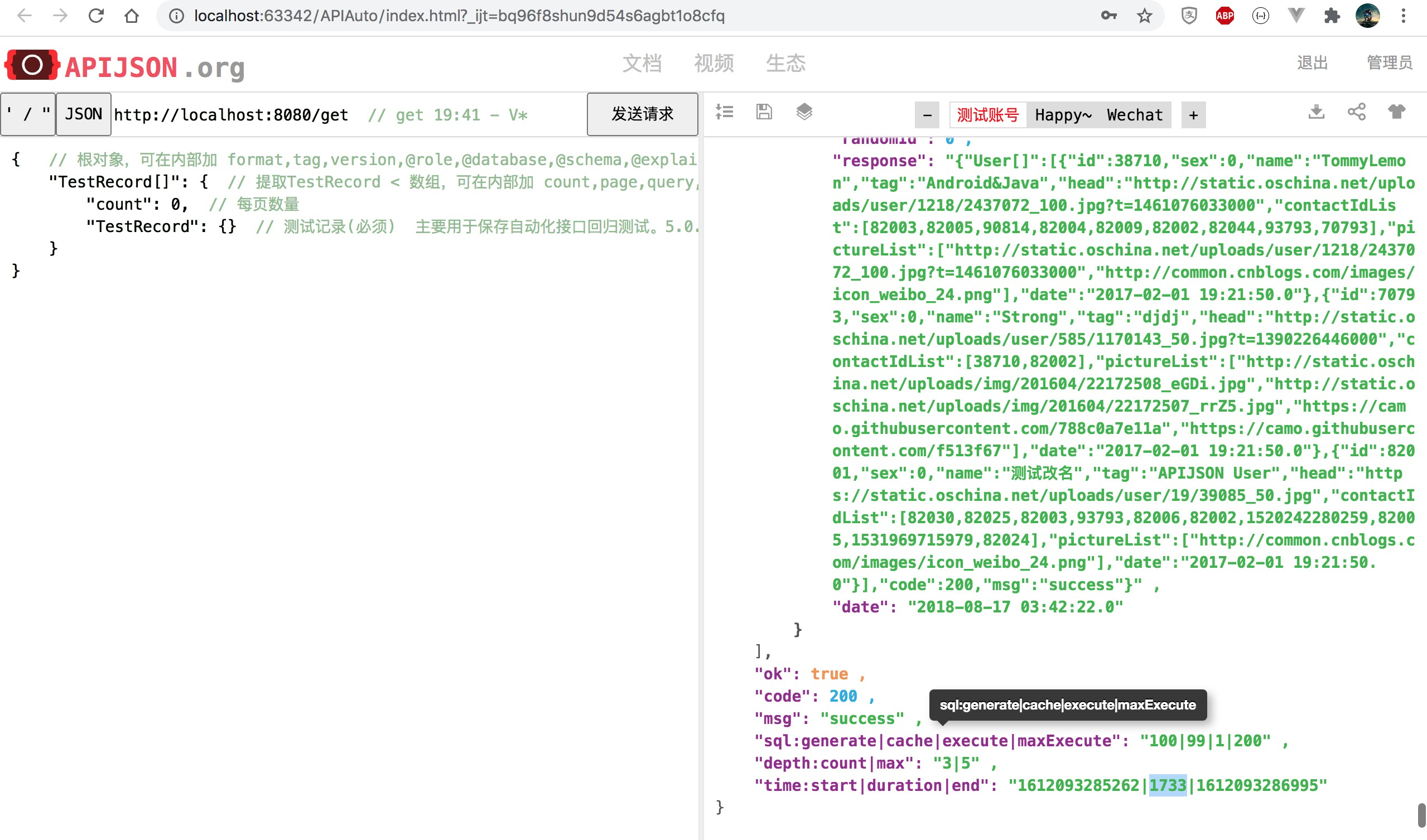

朋友圈列表查询前后对比 耗时降至 34%,性能提升 192% 为原来 2.9 倍:

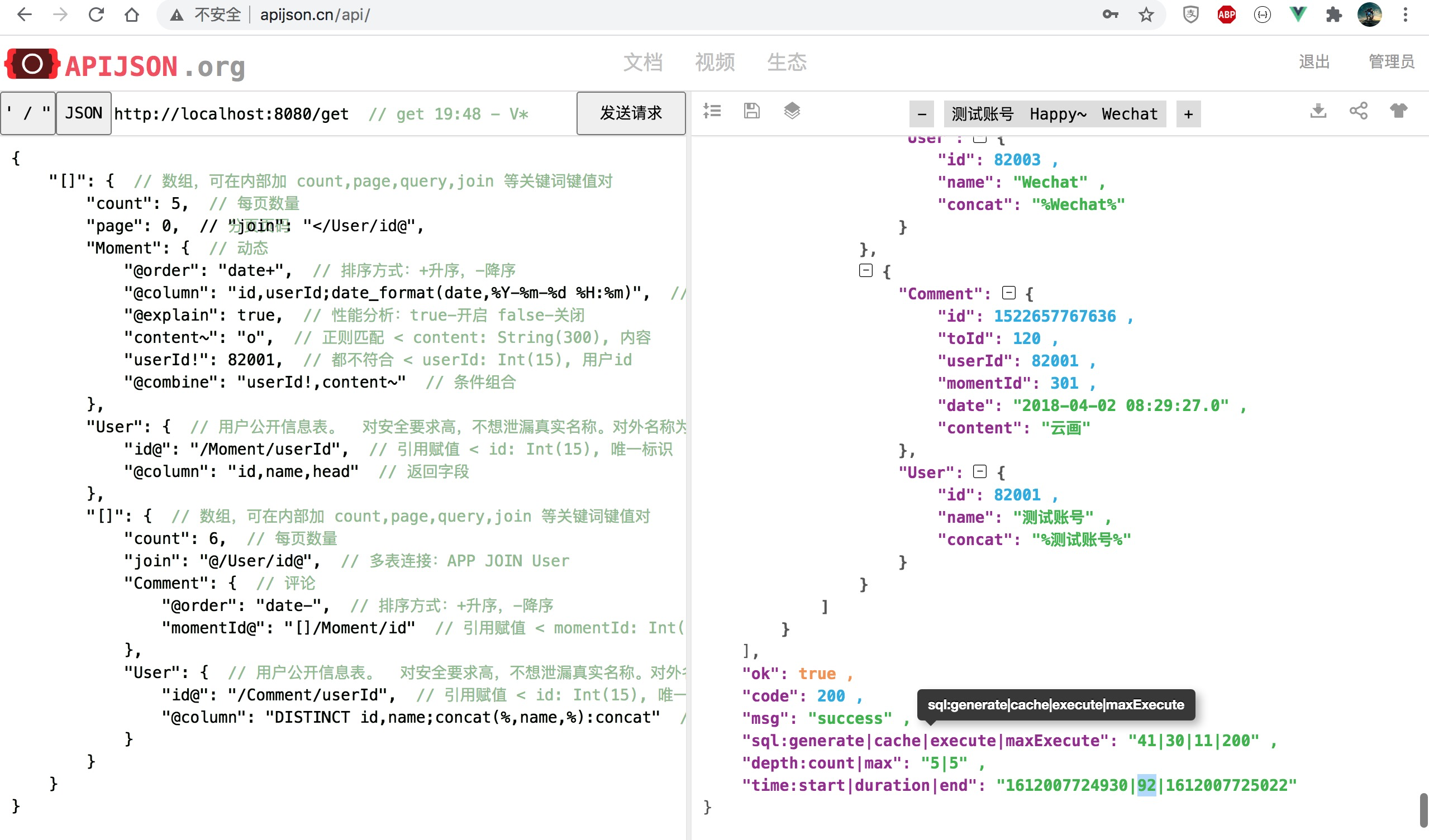
改为 [], []/User[], []/[] 组合且每个数组长度 count 都改为 0(对应 100 条),最多返回 100*(1 + 100 + 100*2) = 30100 条记录:

注:找不到 5651ms 对应那张图了,用最接近的图替代
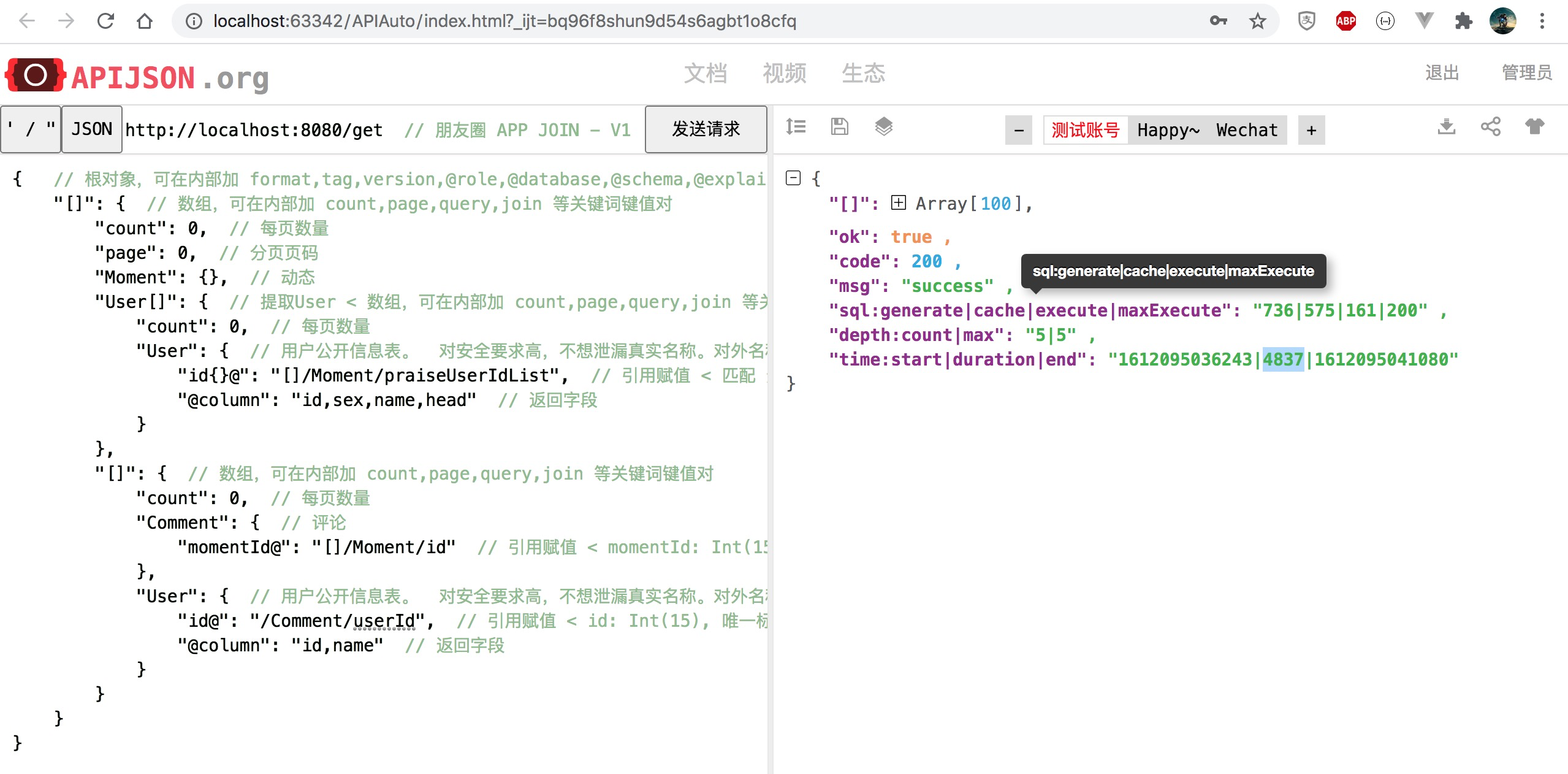

模拟 to C 应用的这个极端情况下 生成 SQL 数从 1397 减少至 750,耗时降至 83%,性能提升 20% 为原来 1.2 倍。
最多才降低耗时为原来 25%?那估计他们组原来 2s 只能优化到 500ms(承诺 200ms 左右),30s 只能优化到 7.5s。
天,牛都吹出去了,这下怎么办?... 算了算了,都一点了,先睡吧,先发版明天让他们试试看,唉...
于是我就打着哈欠把 APIJSON 和 APIAuto 都部署到 apijson.cn,简单自测没问题,然后到两点多就洗洗睡了...
(后面又反复多次自测,虽然结果都和以上接近,但 Release 上用了更保守低调的数值)
第二天上午通知腾讯 CSIG 某项目组的同事更新 APIJSON,下午同事在 APIJSON 咨询群 大赞“给力!”并发了几张截屏。
一看 LIMIT 1000000 我虎躯一震:好家伙,上来就线上生产环境百万数据暴力测试,年轻人不讲武德了么?
---------- | ---------- | ---------- | ---------- | -------------
Total | Received | Time Total | Time Spent | Current Speed
72.5M | 72.5M | 0:00:05 | 0:00:05 | 20.0M
/get >> http请求结束:5624
一时没控记住记几,在公司连续大喊 “我靠!一百万五秒!一百万五秒!查一百万条记录耗时五秒!”
差点还喊出洗脑广告 “OMG,顶它顶它顶它!!!”
把周边同事吓了一跳,过了一会有几个后端同事反应过来纷纷点赞!
冷静下来我仔细分析:
由于他们这次用 CURL 测试接口时,对应的 APIJSON 服务关掉了日志,不能直接看到服务从接收参数到响应结果的耗时,
所以按以上数据计算是 总耗时 5624ms - 数据 72.5M/下载速度 20.0M每秒 = 1999ms,也就是服务执行过程耗时仅仅 2s!
显然 APIJSON 这次性能优化效果显著远超预期,同时 2.3KW 大表查 100W 记录仅 1s 左右也反应了 腾讯 TDSQL 的迅猛!
。
。
然而后来同事反馈,这次带条件查出来实际上不到 100W,只有 12W 多数据。
瞬间把我从丰满的理想拉回了骨感的现实,嗯,革命尚未成功,仍需再接再厉!
。
。
。
经过了几个版本迭代,4.8.0 终于迎来再一次大幅性能提升,这次终于做到了!
APIJSON 4.7.0 和 4.8.0 腾讯 CSIG 某项目性能测试结果
1. 测试环境
1.1 机器配置
腾讯云tke docker pod, 4 核 / 16G。
1.2 db机器配置
腾讯云8核32000MB内存,805GB存储空间
1.3 测试表建表DML、数据量(mysql 5.7)
CREATE TABLE `t_xxxx_xxxx` (
`x_id` bigint(11) unsigned NOT NULL AUTO_INCREMENT,
`x_xxxx_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT 'xID',
`x_xid` int(11) unsigned NOT NULL DEFAULT '0' COMMENT 'xxID',
`x_xx_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT 'xID',
`x_xxxx_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT 'xxxID',
`x_xxxxx_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT 'xxID',
`x_xxxx_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT 'xxID',
`x_uin` bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT 'xxuin',
`x_send_time` datetime DEFAULT NULL COMMENT '推送消息时间',
`x_xxxx_result` int(11) unsigned NOT NULL DEFAULT '0' COMMENT 'xx结果',
`x_xxx_xxxx_result` varchar(255) DEFAULT '' COMMENT 'xx结果',
`x_result` tinyint(4) unsigned NOT NULL DEFAULT '0' COMMENT '0错误 1正确 2未设置',
`x_create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间, 落地时间',
`x_credit` int(11) unsigned NOT NULL DEFAULT '0' COMMENT 'xx数量',
`x_xxxxxx_xxx_id` varchar(32) NOT NULL COMMENT '公共参数, 上报应用',
`x_xxxxxx_source` varchar(32) NOT NULL COMMENT '公共参数, 上报服务名',
`x_xxxxxx_server` varchar(32) NOT NULL COMMENT '公共参数, 上报服务端ip',
`x_xxxxxx_event_time` datetime NOT NULL COMMENT '公共参数, 上报时间',
`x_xxxxxx_client` varchar(32) NOT NULL COMMENT '公共参数, 客户端ip',
`x_xxxxxx_trace_id` varchar(64) NOT NULL COMMENT '公共参数',
`x_xxxxxx_sdk` varchar(16) NOT NULL COMMENT '公共参数, sdk版本',
PRIMARY KEY (`x_id`, `x_uin`),
UNIQUE KEY `udx_uid_xxxxid` (`x_uin`, `x_xxxx_id`),
KEY `idx_xid` (`x_xid`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT = 'xx事件表';
select x_xid, count(x_id) counter from t_xxxx_xxxx group by x_xid order by counter desc limit 10;
| x_xid |
counter |
| xxxx36 |
696376 |
| xxxx38 |
418576 |
| xxxx63 |
384503 |
| xxxx40 |
372080 |
| xxxx41 |
301364 |
| xxxx08 |
248243 |
| xxxx46 |
223820 |
| xxxx07 |
220234 |
| xxxx44 |
207721 |
| xxxx02 |
152795 |
1.4 日志打印设置
Log.DEBUG = false;
AbstractParser.IS_PRINT_REQUEST_STRING_LOG = false;
AbstractParser.IS_PRINT_REQUEST_ENDTIME_LOG = false;
AbstractParser.IS_PRINT_BIG_LOG = false;
2. 测试脚本 (使用Table[]: {Table: {}}格式)
脚本统计方式:
-
基于linux time命令输出的realtime来统计。
-
分2个场景测试:一个不带where条件、一个带x_xid in (xxxx36,xxxx38)的条件,该条件能匹配出100W+数据,方便覆盖10W-100W之间的任何数据量场景,这里事先用select x_xid, count(x_id) c from t_xxxx_xxxx group by x_xid order by c desc;这样的语句对表做了统计,x_xid=xxxx36有696376条记录,x_xid=xxxx38有418576条记录。
脚本:apitest.sh
#!/bin/bash
printf -- '--------------------------\n开始不带where条件的情况测试\n'
time curl -X POST -H 'Content-Type:application/json' 'http://x.xxx.xx.xxx:xxxx/get' -d '{"T_xxxx_xxxx[]":{"count":100000, "T_xxxx_xxxx":{"@column":"x_uin,x_send_time,x_xxxx_id,x_xid,x_xx_id,x_xxxxx_id,x_xxxx_result,x_result,x_credit"}}}' > 10w_no_where.log
time curl -X POST -H 'Content-Type:application/json' 'http://x.xxx.xx.xxx:xxxx/get' -d '{"T_xxxx_xxxx[]":{"count":200000, "T_xxxx_xxxx":{"@column":"x_uin,x_send_time,x_xxxx_id,x_xid,x_xx_id,x_xxxxx_id,x_xxxx_result,x_result,x_credit"}}}' > 20w_no_where.log
time curl -X POST -H 'Content-Type:application/json' 'http://x.xxx.xx.xxx:xxxx/get' -d '{"T_xxxx_xxxx[]":{"count":500000, "T_xxxx_xxxx":{"@column":"x_uin,x_send_time,x_xxxx_id,x_xid,x_xx_id,x_xxxxx_id,x_xxxx_result,x_result,x_credit"}}}' > 50w_no_where.log
time curl -X POST -H 'Content-Type:application/json' 'http://x.xxx.xx.xxx:xxxx/get' -d '{"T_xxxx_xxxx[]":{"count":800000, "T_xxxx_xxxx":{"@column":"x_uin,x_send_time,x_xxxx_id,x_xid,x_xx_id,x_xxxxx_id,x_xxxx_result,x_result,x_credit"}}}' > 80w_no_where.log
time curl -X POST -H 'Content-Type:application/json' 'http://x.xxx.xx.xxx:xxxx/get' -d '{"T_xxxx_xxxx[]":{"count":1000000, "T_xxxx_xxxx":{"@column":"x_uin,x_send_time,x_xxxx_id,x_xid,x_xx_id,x_xxxxx_id,x_xxxx_result,x_result,x_credit"}}}' > 100w_no_where.log
printf -- '--------------------------\n开始带where条件的情况测试\n'
time curl -X POST -H 'Content-Type:application/json' 'http://x.xxx.xx.xxx:xxxx/get' -d '{"T_xxxx_xxxx[]":{"count":100000, "T_xxxx_xxxx":{"x_xid{}":[xxxx36,xxxx38],"@column":"x_uin,x_send_time,x_xxxx_id,x_xid,x_xx_id,x_xxxxx_id,x_xxxx_result,x_result,x_credit"}}}' > 10w_with_where.log
time curl -X POST -H 'Content-Type:application/json' 'http://x.xxx.xx.xxx:xxxx/get' -d '{"T_xxxx_xxxx[]":{"count":200000, "T_xxxx_xxxx":{"x_xid{}":[xxxx36,xxxx38],"@column":"x_uin,x_send_time,x_xxxx_id,x_xid,x_xx_id,x_xxxxx_id,x_xxxx_result,x_result,x_credit"}}}' > 20w_with_where.log
time curl -X POST -H 'Content-Type:application/json' 'http://x.xxx.xx.xxx:xxxx/get' -d '{"T_xxxx_xxxx[]":{"count":500000, "T_xxxx_xxxx":{"x_xid{}":[xxxx36,xxxx38],"@column":"x_uin,x_send_time,x_xxxx_id,x_xid,x_xx_id,x_xxxxx_id,x_xxxx_result,x_result,x_credit"}}}' > 50w_with_where.log
time curl -X POST -H 'Content-Type:application/json' 'http://x.xxx.xx.xxx:xxxx/get' -d '{"T_xxxx_xxxx[]":{"count":800000, "T_xxxx_xxxx":{"x_xid{}":[xxxx36,xxxx38],"@column":"x_uin,x_send_time,x_xxxx_id,x_xid,x_xx_id,x_xxxxx_id,x_xxxx_result,x_result,x_credit"}}}' > 80w_with_where.log
time curl -X POST -H 'Content-Type:application/json' 'http://x.xxx.xx.xxx:xxxx/get' -d '{"T_xxxx_xxxx[]":{"count":1000000, "T_xxxx_xxxx":{"x_xid{}":[xxxx36,xxxx38],"@column":"x_uin,x_send_time,x_xxxx_id,x_xid,x_xx_id,x_xxxxx_id,x_xxxx_result,x_result,x_credit"}}}' > 100w_with_where.log
也就是 MySQL 5.7 共 1.9KW 记录的大表,统计 CRUL 10-20M/s 网速从发起请求到接收完回包的总时长
| 数量级 |
4.7.0(5次取平均值) |
4.8.0(5次取平均值) |
是否正常回包 |
where条件 |
性能提升 |
| 10W |
1.739s |
1.159s |
是 |
无 |
50%。即((1/1.159-1/1.739)/(1/1.739))*100% |
| 20W |
3.518s |
2.676s |
是 |
无 |
31.5% |
| 50W |
9.257s |
6.952s |
是 |
无 |
33.2% |
| 80W |
16.236s |
10.697s |
-Xmx=3192M时无法正常回包,OOM错误,调大-Xmx参数后ok。 |
无 |
51.8% |
| 100W |
19.748s |
14.466s |
-Xmx=3192M时无法正常回包,OOM错误,调大-Xmx参数后ok |
无 |
36.5% |
| 10W |
1.928s |
1.392s |
是 |
"x_xid{}":[xxxx36,xxxx38],覆盖数据超过100W数据。 |
38.5% |
| 20W |
4.149s |
2.852s |
是 |
"x_xid{}":[xxxx36,xxxx38] |
45.5% |
| 50W |
10.652s |
7.231s |
是 |
"x_xid{}":[xxxx36,xxxx38] |
47.3% |
| 80W |
16.975s |
12.465s |
调整了-Xmx后正常回包 |
"x_xid{}":[xxxx36,xxxx38] |
36.2% |
| 100W |
20.632s |
16.481s |
调整了-Xmx后正常回包 |
"x_xid{}":[xxxx36,xxxx38] |
25.2% |
感谢同事给的详细测试报告,在他已脱敏的基础上二次脱敏,并和他确认后对外公开~
以之前的 APIJSON 4.6.0 连接 2.3KW 大表带条件查出 12W+ 数据来估计:
---------- | ---------- | ---------- | ---------- | -------------
Total | Received | Time Total | Time Spent | Current Speed
72.5M | 72.5M | 0:00:05 | 0:00:05 | 20.0M
/get >> http请求结束:5624
4.6.0-4.7.2 都没有明显的性能优化,所以 4.7.0 只花了约 2s 应该是因为换了张表,平均每行数据量减少了约 65% 为原来的 35%。
APIJSON 4.6.0 查原来 2.3KW 大表中 100W 数据按新旧表数据量比例估计耗时 = 20.632s / 65% = 31.7s;
APIJSON 4.6.0 查原来 2.3KW 大表中 100W 数据按同表查出数据量比例估计耗时 = 100W*72.5M/(12-13W)/(20M/s) = 27.9s-30.2s。
两种方式估算结果基本一致,也可以按这个 35% 新旧表平均每行数据量比例估算排除网络耗时后的整个服务耗时:
APIJSON 4.6.0 查原来 2.3KW 大表中 12W+ 数据量服务耗时 = 总耗时 5.624s - 数据 72.5M/下载速度 20.0Mbps = 2.00s;
APIJSON 4.7.0 查现在 1.9KW 大表中 10W 数据量服务耗时 = 总耗时 1.928s - 数据 72.5M*35%(10/12)/(下载速度 10-20.0Mbps) = 0.00-0.87s;
APIJSON 4.8.0 查现在 1.9KW 大表中 10W 数据量服务耗时 = 总耗时 1.392s - 数据 72.5M*35%(10/12)/(下载速度 10-20.0Mbps) = 0.00-0.33s,降低 62%;
APIJSON 4.7.0 查现在 1.9KW 大表中 100W 数据量服务耗时 = 总耗时 20.632s - 数据 725M*35%(10/12)/(下载速度 10-20.0Mbps) = 0.00-10.06s;
APIJSON 4.8.0 查现在 1.9KW 大表中 100W 数据量服务耗时 = 总耗时 16.481s - 数据 725M*35%(10/12)/(下载速度 10-20.0Mbps) = 0.00-5.91s,降低 41%。
也就是 1.9KW 大表带条件查出 100W 条记录,APIJSON 4.8.0 的从 完成接收参数 到 开始返回数据 的整个服务耗时不到 6s!


APIJSON - 零代码接口和文档
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)