
介绍
假设需要对人们是否戴眼镜进行分类,但是没有数据或资源训练自定义模型。
在本教程中,你将学习如何使用预训练的CLIP模型创建自定义分类器,无需任何训练。这种方法称为零快照图像分类,它使得能够对在原始CLIP模型训练期间未明确观察到的的类进行图像分类。
为了方便起见,下面提供了一个易于使用的jupyter笔记本,并提供完整的代码。
CLIP:理论背景
CLIP (对比语言-图像预训练)模型是OpenAI开发的多模式视觉和语言模型。它将图像和文本描述映射到相同的潜空间,使其能够确定图像和描述是否匹配。
CLIP是通过对超过4亿个来自互联网的图像-文字对数据集进行对比式训练开发的[1]。令人惊讶的是,经过预训练的CLIP生成的分类器已经表现出与受监督的基线模型竞争的结果,在本教程中,我们将利用这个预训练模型来生成眼镜检测器。
CLIP对比训练
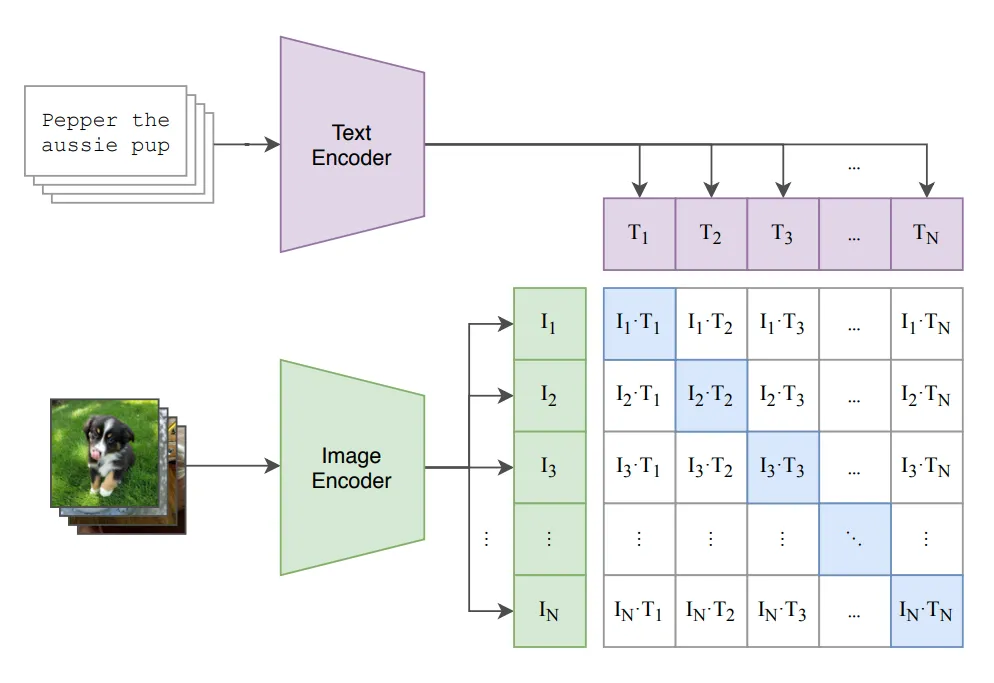
CLIP模型由图像编码器和文本编码器(图1)组成。在训练中,一批图像通过图像编码器(ResNet变体或ViT)处理以获得图像表示张量(嵌入)1。与此同时,它们对应的描述通过文本编码器(Transformer)进行处理,以获得文本嵌入。
CLIP模型是训练来预测哪一个图像张量属于批次中的哪个文本张量。这是通过共同训练图像编码器和文本编码器以最大化批次中真实配对的图像和文本嵌入之间的余弦相似度[2],同时使配对不正确的嵌入之间的余弦相似度减小而实现的(图1,对角线轴上的蓝色方块)。优化使用这些相似度得分的对称交叉熵损失来执行。
创建自定义分类器
使用CLIP创建自定义分类器时,将类别名称转换为文本嵌入向量经过预训练的文本编码器进行处理,同时使用预训练的图像编码器对图像进行嵌入(图2)。然后计算图像嵌入和每个文本嵌入之间的余弦相似度,并将图像分配给最高余弦相似度得分的类别。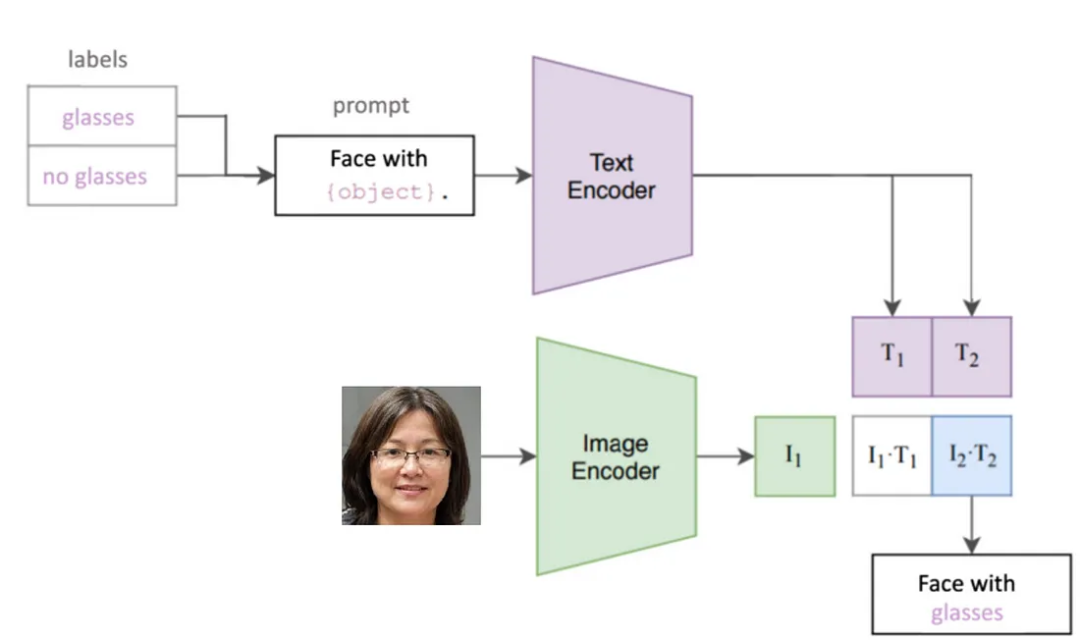
代码实现
数据集
在本教程中,我们将创建一个图像分类器,检测人们是否戴眼镜,并使用Kaggle上的“戴眼镜或不戴眼镜”数据集[3] 来评估分类器的性能。
尽管数据集包含5000张图像,但我们将只利用前100张以加快演示速度。数据集包含一个包含所有图像的文件夹以及一个包含标签的CSV文件。为了便于加载图像路径和标签,我们将自定义Pytorch数据集类来创建CustomDataset()类。你可以在提供的笔记本代码中找到它。

加载CLIP模型
安装并导入CLIP及其相关库后,我们加载所需的模型和torchvision转换流水线。文本编码器是一个Transformer,而图像编码器可以是Vision Transformer(ViT)或ResNet50等ResNet变体。你可以使用命令clip.available_models()查看可用的图像编码器。
print( clip.available_models() )
model, preprocess = clip.load("RN50")
提取文本嵌入向量
首先通过文本分词器(clip.tokenize())处理文本标签,将标签单词转换为数值。这会产生大小为N x 77(N是类别数量,二分类下的两个类别是77)的填充张量,作为文本编码器的输入。
文本编码器将张量转换为大小为N x 512的文本嵌入张量,其中每个类别由单个向量表示。要编码文本并检索嵌入,请使用model.encode_text()方法。
preprocessed_text = clip.tokenize(['no glasses','glasses'])
text_embedding = model.encode_text(preprocessed_text)
提取图像嵌入向量
在传递给图像编码器之前,每个图像都要经过预处理,包括中心裁剪、标准化和调整大小,以满足图像编码器的要求。预处理后,图像传递给图像编码器,该编码器生成大小为1 x 512的图像嵌入张量作为输出。
preprocessed_image = preprocess(Image.open(image_path)).unsqueeze(0)
image_embedding = model.encode_image(preprocessed_image)
相似度结果
为了衡量图像编码和每个文本标签编码之间的相似度,我们将使用余弦相似度距离度量。model()接收预处理的图像和文本输入,将它们传递到图像和文本编码器中,并计算相应的图像和文本特征之间的余弦相似度,再乘以100(图像对数分)。然后使用softmax将logits归一化为每个类别的概率分布列表。
由于我们不训练模型,因此我们将使用torch.no_grad()禁用梯度计算。
with torch.no_grad():
image_logits, _ = model(preprocessed_image, preprocessed_text)
proba_list = image_logits.softmax(dim=-1).cpu().numpy()[0]
将最大概率的类别设置为预测类别,并提取其索引、概率和相应的标记。
y_pred = np.argmax(proba_list)
y_pred_proba = np.max(proba_list)
y_pred_token = ['no glasses','glasses'][y_pred_idx]
包装代码
我们可以创建一个名为CustomClassifier的Python类来包装这个代码。初始化时,加载预训练的CLIP模型,针对每个标签生成嵌入文本表示向量。
我们将定义一个classify()方法,它将图像路径作为输入,并返回带有其概率得分的预测标签(存储在一个名为df_results的DataFrame中)。
为了评估模型的性能,我们将定义一个validate()方法,它使用PyTorch数据集实例(CustomDataset())检索图像和标签,然后调用classify()方法预测结果并评估模型的性能。此方法返回一个DataFrame,其中包含所有图像的预测标签和概率得分。max_images参数用于限制图像数量为100。
class CustomClassifier:
def __init__(self, prompts):
self.class_prompts = prompts
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.model, self.preprocess = clip.load("RN50", device=self.device) # "ViT-B/32"
self.preprocessed_text = clip.tokenize(self.class_prompts).to(self.device)
print(f'Classes Prompts: {self.class_prompts}')
def classify(self, image_path, y_true = None):
preprocessed_image = self.preprocess(Image.open(image_path)).unsqueeze(0).to(self.device)
with torch.no_grad():
image_logits, _ = self.model(preprocessed_image, self.preprocessed_text)
proba_list = image_logits.softmax(dim=-1).cpu().numpy()[0]
y_pred = np.argmax(proba_list)
y_pred_proba = np.max(proba_list)
y_pred_token = self.class_prompts[y_pred]
results = pd.DataFrame([{'image': image_path, 'y_true': y_true, 'y_pred': y_pred, 'y_pred_token': y_pred_token, 'proba': y_pred_proba}])
return results
def validate (self, dataset, max_images):
df_results = pd.DataFrame()
for sample in tqdm(range(max_images)):
image_path, class_idx = dataset[sample]
image_results = self.classify(image_path, class_idx)
df_results = pd.concat([df_results, image_results])
accuracy = accuracy_score(df_results.y_true, df_results.y_pred)
print(f'Accuracy - {round(accuracy,2)}')
return accuracy, df_results
单个图像可以使用classify()方法进行分类:
prompts = ['no glasses','glasses']
image_results = CustomClassifier(prompts).classify(image_path)
分类器的性能可以通过validate()方法进行评估:
accuracy, df_results = CustomClassifier(prompts).validate(glasses_dataset, max_images =100)
需要注意的是,使用原始的['无眼镜','有眼镜']类标签,我们在没有训练任何模型的情况下获得了不错的0.82的准确性,通过提示工程,我们甚至可以进一步提高我们的结果。
提示工程
CLIP分类器将文本标签编码为学习的潜在空间,并将其相似性与图像潜在空间进行比较。修改提示的措辞可能会导致不同的文本嵌入,从而影响分类器的性能。
为了提高预测精度,我们将通过试错探索多个提示,并选择产生最佳结果的提示。例如,使用“没有眼镜的男人的照片”和“戴眼镜的男人的照片”这些提示会产生0.94的准确度。
prompts = ['photo of a man with no glasses', 'photo of a man with glasses']
accuracy, df_results = CustomClassifier(prompts).validate(glasses_dataset, max_images =100)
分析多个提示产生了以下结果:
[ '无眼镜','有眼镜',]——0.82的准确度
[ '没有眼镜的脸','有眼镜的脸' ]——0.89准确度
['没有眼镜的男人的照片','戴眼镜的男人的照片']——0.94准确度
正如我们所见,调整措辞可以显著提高性能。通过分析多个提示,我们从0.82的基线准确性改进到了0.94。但是,避免过度拟合提示到数据集很重要。
结论
CLIP模型是开发各种任务的zero-shot分类器的非常强大的工具。使用CLIP,能够轻松地生成具有高度满意的准确性的即时分类器。
但是,CLIP可能会在细粒度分类、抽象或系统性任务(如计数对象)以及预测未在其预训练数据集中覆盖的真正超出分布的图像等任务中遇到困难。因此,应事先评估其在新任务中的性能。
使用下面提供的Jupyter笔记本,你可以轻松创建自己的自定义分类器。只需按照说明添加数据,即可在短时间内拥有个性化的分类器。
感谢阅读!
Jupyter笔记本
安装
将此笔记本放入所需目录。安装并导入所需的库:
!pip install clip-by-openai
!pip install pandas
!pip install -U scikit-learn
!pip install opendatasets
!pip install ipywidgets
!jupyter nbextension enable --py widgetsnbextension --sys-prefix
import numpy as np
import torch
import os
import clip
from PIL import Image
from tqdm.notebook import tqdm_notebook as tqdm
import pandas as pd
from sklearn.metrics import accuracy_score
import zipfile
import random
数据集处理
从Kaggle手动下载眼镜数据集https://www.kaggle.com/datasets/jeffheaton/glasses-or-no-glasses如果你有kaggle.json密钥文件,可以使用数据集标识符为“glass or no glass.zip”的“kaggle dataset download”命令(获取密钥文件的说明可在https://www.geeksforgeeks.org/how-to-download-kaggle-datasets-into-jupyter-notebook/)
!kaggle datasets download -d jeffheaton/glasses-or-no-glasses
# Extract zip dataset
with zipfile.ZipFile('glasses-or-no-glasses.zip', 'r') as zip_ref:
zip_ref.extractall()
显示图像的Helper函数
def display_random_images(dir_path, num_images, seed, save_path=None):
random.seed(seed)
image_paths = []
for subdir, dirs, files in os.walk(dir_path):
for file in files:
file_path = os.path.join(subdir, file)
if file_path.endswith(".png") or file_path.endswith(".jpg") or file_path.endswith(".jpeg"):
image_paths.append(file_path)
random_images = random.sample(image_paths, num_images)
images = [Image.open(image_path) for image_path in random_images]
widths, heights = zip(*(i.size for i in images))
total_width = sum(widths)
max_height = max(heights)
new_im = Image.new('RGB', (total_width, max_height))
x_offset = 0
for im in images:
new_im.paste(im, (x_offset,0))
x_offset += im.size[0]
if save_path:
new_im.save(save_path)
display(new_im)
显示从“眼镜”数据集中随机选择的图像
display_random_images(dir_path = 'faces-spring-2020', num_images=6, seed = 12, save_path = 'random_data.jpg')
使用pytorch数据集类从CSV中提取图像路径和标签
class CustomDataset(torch.utils.data.Dataset):
def __init__(self, csv_path, images_folder):
self.df = pd.read_csv(csv_path)[['id','glasses']]
self.images_folder = images_folder
self.class2index = {"no glasses":0, "glasses":1}
def __len__(self):
return len(self.df)
def __getitem__(self, index):
filename = f'face-{self.df.iloc[index, 0]}.png'
label = self.df.iloc[index, -1]
image_path = os.path.join(self.images_folder, filename)
return image_path, label
path_images = r"faces-spring-2020/faces-spring-2020"
path_csv = r"train.csv"
glasses_dataset = CustomDataset(path_csv, path_images)
CLIP自定义分类器
“CustomClassifier”类定义了使用预先训练的CLIP模型的自定义zero-shot图像分类器。“classify”方法对单个图像进行分类,而“validate”方法对图像目录进行分类并评估性能。
class CustomClassifier:
def __init__(self, prompts):
self.class_prompts = prompts
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.model, self.preprocess = clip.load("RN50", device=self.device) # "ViT-B/32"
self.preprocessed_text = clip.tokenize(self.class_prompts).to(self.device)
print(f'Classes Prompts: {self.class_prompts}')
def classify(self, image_path, y_true = None):
preprocessed_image = self.preprocess(Image.open(image_path)).unsqueeze(0).to(self.device)
with torch.no_grad():
image_logits, _ = self.model(preprocessed_image, self.preprocessed_text)
proba_list = image_logits.softmax(dim=-1).cpu().numpy()[0]
y_pred = np.argmax(proba_list)
y_pred_proba = np.max(proba_list)
y_pred_token = self.class_prompts[y_pred]
results = pd.DataFrame([{'image': image_path, 'y_true': y_true, 'y_pred': y_pred, 'y_pred_token': y_pred_token, 'proba': y_pred_proba}])
return results
def validate (self, dataset, max_images):
df_results = pd.DataFrame()
for sample in tqdm(range(max_images)):
image_path, class_idx = dataset[sample]
image_results = self.classify(image_path, class_idx)
df_results = pd.concat([df_results, image_results])
accuracy = accuracy_score(df_results.y_true, df_results.y_pred)
print(f'Accuracy - {round(accuracy,2)}')
return accuracy, df_results
单个图像的预测:
image_path = r'faces-spring-2020/faces-spring-2020/face-1.png'
prompts = ['no glasses', 'glasses']
image_results = CustomClassifier(prompts).classify(image_path)
print(f"Prediction - '{image_results.y_pred_token[0]}'")
Classes Prompts: ['no glasses', 'glasses']
Prediction - 'no glasses'
整个图像文件夹的分类和评估。
accuracy, df_results = CustomClassifier(prompts).validate(glasses_dataset, max_images =100)
display(df_results)
Classes Prompts: ['no glasses', 'glasses']
0%| | 0/100 [00:00<?, ?it/s]
Accuracy - 0.82
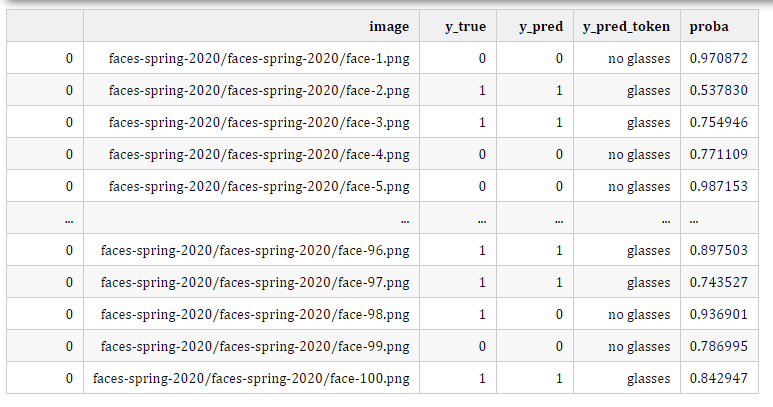
100 rows × 5 columns
Prompt工程
prompts = ['face without glasses', 'face with glasses']
accuracy, df_results = CustomClassifier(prompts).validate(glasses_dataset, max_images =100)
Classes Prompts: ['face without glasses', 'face with glasses']
0%| | 0/100 [00:00<?, ?it/s]
Accuracy - 0.89
prompts = ['photo of a man with no glasses', 'photo of a man with glasses']
accuracy, df_results = CustomClassifier(prompts).validate(glasses_dataset, max_images =100)
Classes Prompts: ['photo of a man with no glasses', 'photo of a man with glasses']
0%| | 0/100 [00:00<?, ?it/s]
Accuracy - 0.94
参考引用
[0] Code: https://gist.github.com/Lihi-Gur-Arie/844a4c3e98a7561d4e0ddb95879f8c11
[1] CLIP article: https://arxiv.org/pdf/2103.00020v1.pdf
[2] Cosine similarity review: https://towardsdatascience.com/understanding-cosine-similarity-and-its-application-fd42f585296a
[3] ‘Glasses or No Glasses’ dataset from Kaggle, license CC BY-SA 4.0: https://www.kaggle.com/datasets/jeffheaton/glasses-or-no-glasses
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
