在高可用领域,除了通过规范化运维和软硬件优化,提升平均失效时间(MTBF), 降低平均恢复时间(MTTR)也非常关键,本文主要讲述的内容是其中的故障转移和故障恢复部分。
降低平均恢复时间(MTTR)
- 宕机的原因
- 运行环境(操作系统、硬盘、网络等)原因占 35%
- 性能问题(DDL/长事务导致资源耗尽等)占 35%
- 复制原因占 20%
- 其他(数据丢失或损坏)占10%
- 基于复制的冗余
- 使用 MySQL 的复制功能搭建热备份
- 主备相隔粒度越大,可用性保障等级越高(机柜<机房<城市)
- 故障转移
- 应用和数据库连接方式会影响故障转移的时效,应用可以通过虚拟IP/DNS/中间件等形式访问数据库
- 虚拟IP,一个虚拟 IP 绑定一个真实 IP,故障转移时把绑定的 IP 修改为备库的 IP 即可实现快速故障转移
- DNS,一个 DNS 可以绑定多个 IP,可以实现快速故障转移,同时可以实现负载均衡
- 中间件,通过重写 JDBC 等接口,灵活调用和访问数据库,可以实现快速故障转移、读写分离、负载均衡,同时可以实现分库分表等分布式查询等
故障探测
I. 探测方法
- ping 虚拟ip
- select 获取 test 库中的 heartbeat 表
- update 更新 test 库中的 heartbeat 表
create table heartbeat (ts timestamp);
II. 探测结果汇总
- 网络异常: 网络连接超时,无法从网络上找到对应主机
- 被探测实例单机网络故障
- 被探测实例所在机房网络故障
- HA 程序所在机器网络故障
- HA 程序所在机房网络故障
- 主机异常: 网络连接被拒绝,找到主机,无法在主机上找到对应服务端口的实例
- 实例异常: 探测连接创建超时,服务端口存在,但是创建连接时超时
- 读写异常: 成功创建连接,但 select/update 操作执行超时,但是无法执行读/写操作
III. 探测程序部署架构
- 单点部署,自身不具备高可用
- 热备部署,自身具备高可用
- 使用 Keepalived 进行监控和切换
- 如果发生机房间的网络故障,容易产生脑裂(两个机房都认为对方有问题)
- 分布式部署,避免脑裂
- HA 程序使用 ZooKeeper 保存、识别 MySQL 实例和自身的状态,也可以利用它实现分布式锁,进行并发同步
- 需要至少在三个机房各一台机器,部署至少 3 个节点的 ZooKeeper 集群
- 利用 PAXOS 协议对分布式一致性©和分区容错性§的强支持,避免脑裂,准确判断问题节点
故障转移和修复
- 根据探测结果判断是否出现故障,如果是故障,则判断是否是提供服务的主库
- 查看备库备库状态,确认备库可用,并且备库 Replication 的延迟小于阈值
- 等待备库应用 relay log(需要设置应用超时时间),然后
stop slave;
- 记录备库 relay log 对应主库的位点
- 掉用中间件/DNS/VIP 的接口,把应用流量转移到备库
- 把新主库设置为 RW
- 老主库再次连接上后,kill 掉它上面的所有连接,保证应用流量都到备库,避免 DNS 等 catch 功能导致的切换不干净
- 老主库再次连接上后,把它设置为 RO
- 老主库恢复后,进行故障恢复:
- 修复数据:切花前备库往往存在一点延迟,根据记录的位点,从老主库 binlog 提取数据,来修复新主库
- 修复复制:重新启动复制后,往往会出现主键冲突,需要谨慎对比和修复数据,不能盲目 skip 复制的错误
故障转移程序依赖的数据
- 主备关系和实时状态
- 故障转移黑名单
- 每个实例的故障转移类型:中间件、DNS、VIP
- 每种故障转移类型的切换接口
- 每个实例的故障转移级别:遇到哪一种类型的故障(探测结果)进行切换
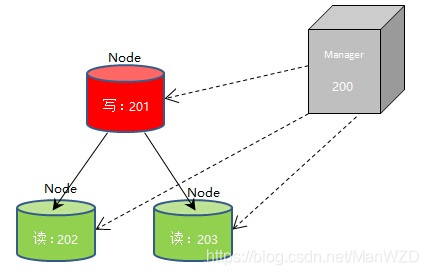
MHA 介绍
- 架构
- Manager 单点部署
- Node 随 MySQL 实例部署
| IP |
角色 |
| 192.168.1.200 |
Manager |
| 192.168.1.201 |
Node |
| 192.168.1.202 |
Node |
| 192.168.1.203 |
Node |
参考文档
《高性能 MySQL》