在训练dbnet的时候,需要进行数据分析的一些方法来分割数据集. 这里刚好整理一下:
# _*_ coding:utf-8 _*_ #用于解决编码问题
x.strip()
strip()方法删除前导空格和尾随空格。

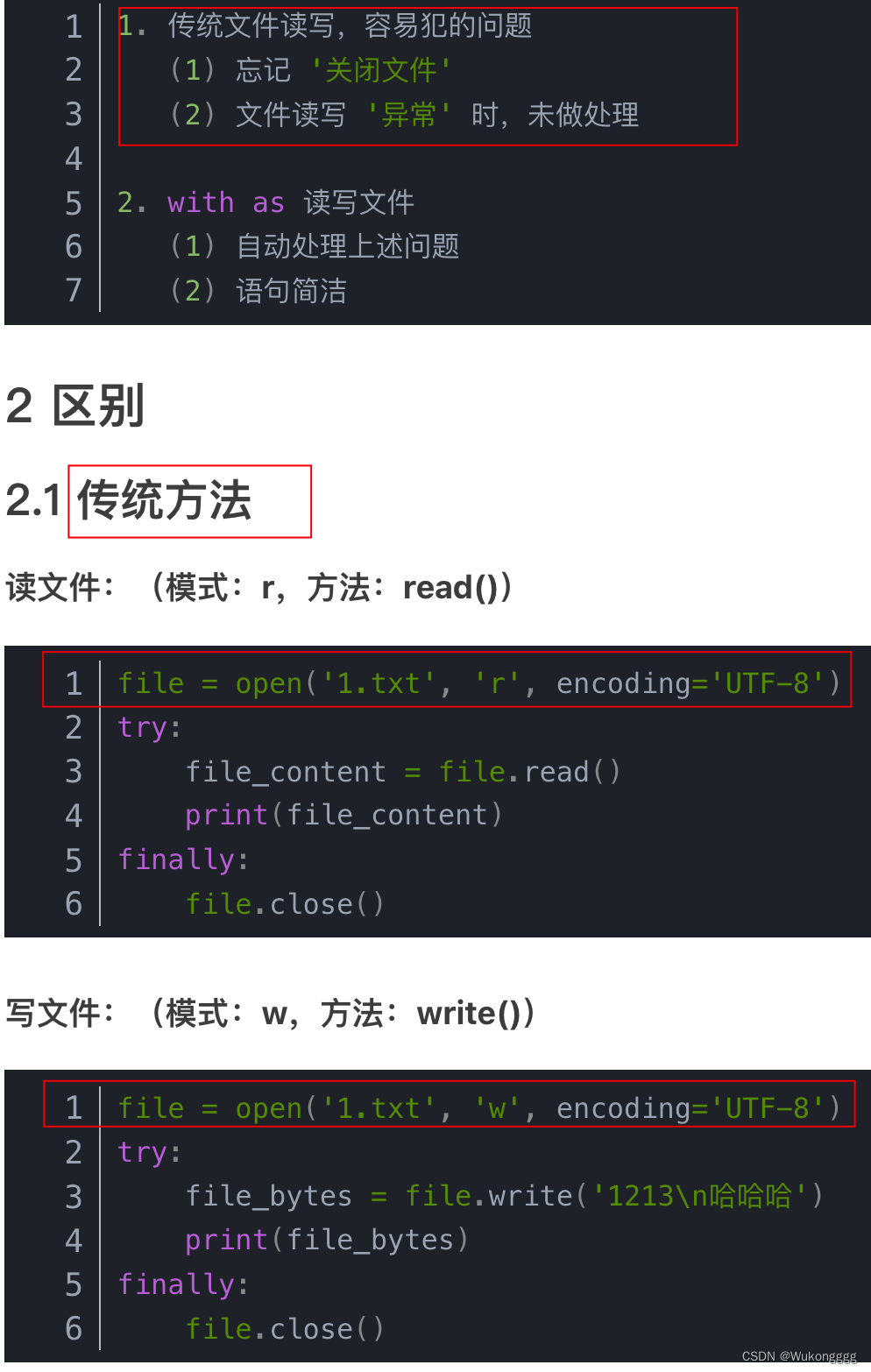
with open() as 方法
with open('1.txt', 'r', encoding='UTF-8') as file:
print(file.read())
#file.readline() 读一行
#file.readlines() 读所有行. 后续搭配for读单行
#file.close()
#file.write()
note.split('\t') , 返回的是一个数组. 通过索引取前部分和后部分. \t被隐藏
os.path.join(a,b)
img_path.replace('修改前', '修改后')
json.loads(tmp[1]) #将str变为dict,使得取值.
[str(x[0])+', '+str(x[1]) for x in points] #每一行points的内部连接
', '.join(tmp) #tmp用', '连接起来

res.append(tmp+', '+str(box['transcription'])+'\n')
#变量+'字符串'+str(非字符串) 才可以拼接
for root, dirs, files in os.walk(file_dir):#遍历文件夹、根目录、目录文件夹、目录里的文件

res_labels= random.shuffle(res_labels) #打乱一个数组
res_labels[:5] #取不到5行 res_labels[5:] #5行以后的
res_labels[:5] #取不到5行
#通过~取反,选取不包含数字1的行
df1=source_df[~source_df['货币代号'].isin([1])]