一、引言
在恶意软件发展的初期,恶意软件编写者会直接将控制服务器的域名或IP直接写在恶意软件中(即使是现在也会有恶意软件遵从这种方式,笔者部署的蜜罐捕获的僵尸网络样本中,很多经过逆向之后发现也是直接将IP写在软件中)。对于这种通信的方式,安全人员可以明确知道恶意软件所通信的对象,可以通过黑名单的方式封锁域名及IP达到破坏恶意软件工作的目的。DGA(Domain
generation
algorithms),中文名:域名生成算法,其可以生成大量随机的域名来供恶意软件连接C&C控制服务器。恶意软件编写者将采用同样的种子和算法生成与恶意软件相同的域名列表,从中选取几个来作为控制服务器,恶意软件会持续解析这些域名,直到发现可用的服务器地址。这种方式导致恶意软件的封堵更为困难,因此DGA域名的检测对网络安全来说非常重要。
本文将针对DGA域名的检测,开展以下几个方面的内容:
1)针对开源DGA域名与正常域名进行初步的数据分析,查看正常域名与DGA域名的不同及其各自的数据分布;
2)尝试利用自然语言处理的方式对DGA域名进行可视化;
3)利用两种深度学习的模型对DGA域名进行分类。
二、一个DGA算法的例子
为了让读者对DGA算法生成的域名有更加直观的认识,列举一种DGA算法murofet(v2),该算法以时间与一个密钥作为种子来生成相应的域名地址,代码如下:
def dga(date, key):
for index in range(1020):
seed = 8*[0]
seed[0] = ((date.year & 0xFF) + 0x30) & 0xFF
seed[1] = date.month & 0xFF
seed[2] = date.day & 0xFF
seed[3] = 0
r = (index) & 0xFFFFFFFE
for i in range(4):
seed[4+i] = r & 0xFF
r >>= 8
seed_str = ""
for i in range(8):
k = (key >> (8*(i%4))) & 0xFF if key else 0
seed_str += chr((seed[i] ^ k))
m = hashlib.md5()
m.update(seed_str)
md5 = m.digest()
domain = ""
for m in md5:
tmp = (ord(m) & 0xF) + (ord(m) >> 4) + ord('a')
if tmp <= ord('z'):
domain += chr(tmp)
tlds = [".biz", ".info", ".org", ".net", ".com"]
for i, tld in enumerate(tlds):
m = len(tlds) - i
if not index % m:
domain += tld
break
print(domain)
由该算法生成的域名(以时间2020-8-11和密钥D6D7A4B1)如下
xqqjqfytpqiyolo.biz
xqqjqfytpqiyolo.com
oazniteyqkphxtpy.net
oazniteyqkphxtpy.org
kionbqkwttxtvur.info
kionbqkwttxtvur.biz
dghtuswqqsrugw.org
dghtuswqqsrugw.com
xiwkittytnlksuss.info
xiwkittytnlksuss.org
观察上述域名,看不到明显的规律,也没有可读的单词,呈现出来一种随机性。该DGA算法的完整源码,在GitHub上[1],该Github的作者收集了很多DGA算法,并用python实现,可以作为一种数据源。
三、域名数据分析
为了更直观的认识DGA域名与正常域名的不同,本小节通过对域名的一些特性进行分析。正常域名的数据来源是S3上top1-m的正常域名[2],DGA域名来自360
netlab[3],数据是持续更新的,本次分析的数据下载于2020年8月7号,其中两部分的数据数量如下:
表3.1 域名数量分布
| 类别 |
数目 |
| DGA域名 |
1308585 |
| 正常域名 |
706546 |
3.1 不同DGA家族数据量分布
在360的DGA数据中,一共存在48个DGA家族,但是每个家族的数量分布也是非常不同的,有些家族数量远比其他的家族要多。
 图3.1
图3.1
不同DGA家族的域名数据分布
在图2.1中,选取了按照数据排名的前20个DGA域名,并绘制他们的数量分布,可以看到banjori和emotet的数量非常多,数量上达到了40W+。
3.2 域名长度分布
注:域名解析过程中,采用python的第三方库tldextract,该库解析解析域名是,会将一个网址分为三个部分,分别是subdomain,domain,suffix。后续内容如果不做特殊说明,将只针对domain进行数据分析。
3.2.1 正常域名长度分布
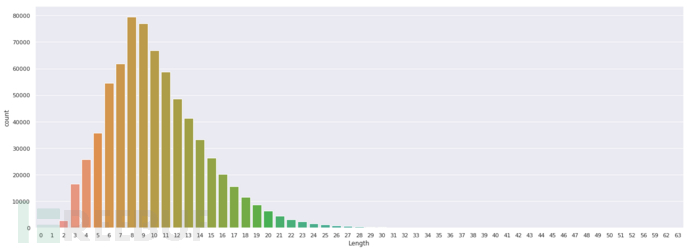 图3.2 正常域名长度分布
图3.2 正常域名长度分布
正常域名的长度大致集中在8-10左右,整体分布非常像瑞利分布。
3.2.2 DGA域名长度分布
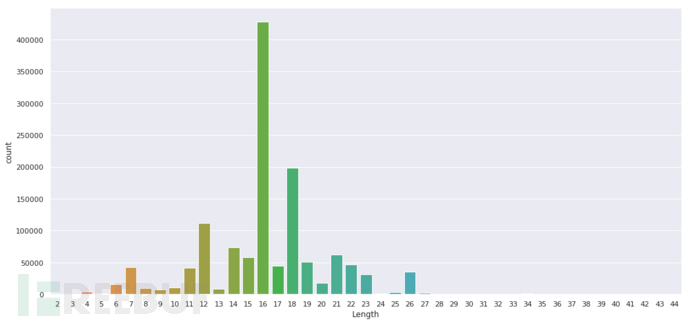 图3.3 DGA域名长度分布
图3.3 DGA域名长度分布
从图2.2的长度分布中可以看出,其中比较突出的两个长度是16和18,再其次长的是12,这个让笔者想起了另外一个家族,tinba算法就是按照12为数量限制循环生成字符组成域名。
对于DGA与正常域名,可以发现他们两者的几点不同:1)DGA的长度分布区间要比正常域名小,DGA长度分布区间为2-44,而正常域名的长度分布为1-63;2)DGA与正常域名的长度分布明显不同,DGA域名长度分布没有明显的分布规律,在某几个数字呈现出极高的数据量,而正常域名长度呈现出一些递增递减的规律,在8、9处达到顶峰。
3.2.3 不同DGA家族域名长度分布
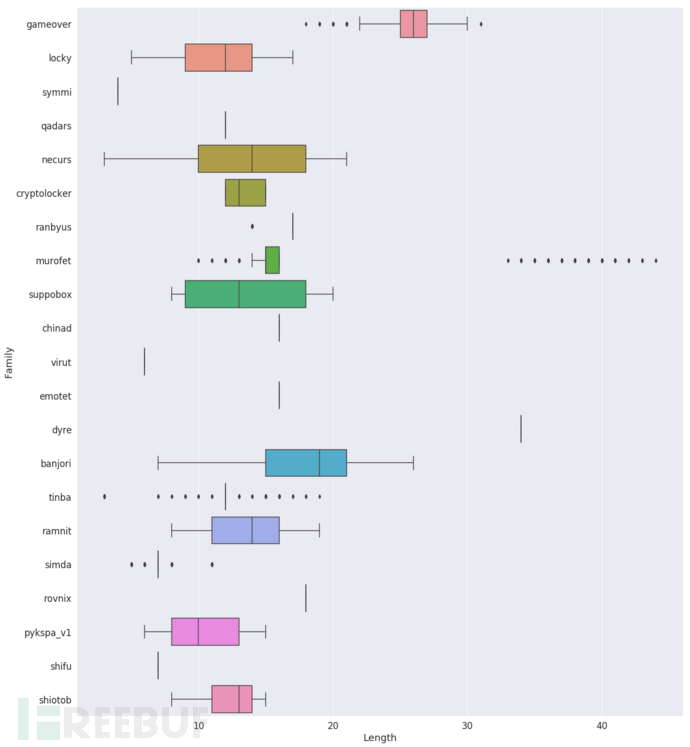 图3.4
图3.4
不同DGA家族域名长度箱型图分布
从上图2.4中可以看出,某些家族(选取域名数量大于等于1000的家族)的域名,长度稳定稳定分布在某个程度,例如dyre家族的域名长度为34,qadars家族长度固定为12,而其他一些家族的域名长度分布的区间较大,例如murofet,如图2.5所示。
 图3.5
图3.5
murofet家族的长度分布
3.3 域名字符分布
通过查看域名的字符分布,可以看出某些DGA家族使用的字符范围。本部分的字符范围为’a’-‘z’加上两个特殊字符’-‘和‘_’。
3.3.1 正常域名字符分布
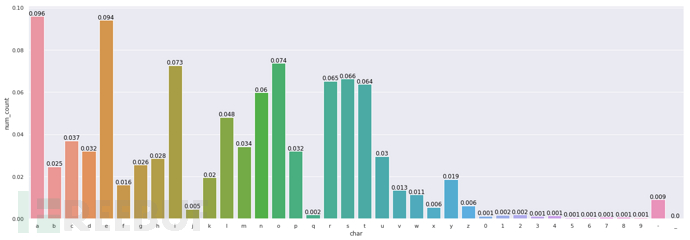
图3.6 正常域名字符分布
3.3.2 DGA域名字符分布
 图3.7 DGA域名字符分布
图3.7 DGA域名字符分布
对于DGA域名字符与正常域名字符分布,两者有一定的差别,比如正常域名在某些字符上,取值的概率比较小;DGA域名使用数字的概率比正常域名更高。下面来看一下,某些家族的字符分布。
3.3.3 不同DGA域名家族的字符分布
因为文章空间的限制,这里举出几个域名数量多,且其分布比较典型的例子。
 图3.8
图3.8
emotet家族域名字符分布
图2.8展示了emotet家族的域名分布,一共统计了40W+的该家族域名,其在’a’-'y’上是均匀分布;同时参考图2.4中,域名长度分布,该家族的域名长度稳定在16的位置。而下面的gamaover家族,展现出更不一样的风格。
 图3.9
图3.9
gameover家族域名字符分布
gameover家族的字符分布覆盖了除了特殊字符之外的所有字符,同时只在‘1’处展现出凸起,其他地方大致上都是同概率的。
3.4 小节
本部分主要从一些数据分布的角度,介绍了DGA域名与正常域名的不同,仅仅考虑了域名长度和字符取用的两个角度,同时简单展示了不同的家族在长度和字符上的习惯。从上述的结果可以看到,DGA域名与正常域名的数据分布上有一定的差别。
四、域名可视化
本部分利用两种方式来进行域名可视化,通过自然语言处理的方式获取域名的向量,然后利用降维的方式得到可在二维向量展示的向量,最后利用前面得到的二维向量来绘制相应的散点图。但是从实际图的反馈结果上来看,整体的效果不好。
4.1 词袋模型
词袋模型通过计算某些字符出现的次数来进行向量化表示,不考虑词出现的次数以及位置。机器学习库sklearn中CountVectorizer方法就是完成这部分工作。在CountVectorizer的参数中,通过指定analyzer=‘char’使其分析字符级别的gram,而参数ngram_range是控制gram的个数,ngram在该部分域名分析中是指多个字符连接起来的子字符串。关于这部分内容,有兴趣的读者可以搜索相关文章来学习。下面举一个2-gram的例子来说明函数的使用。
from sklearn.feature_extraction.text import CountVectorizer
sample_domain = ['google','baidu','alibaba','freebuf']
cv = CountVectorizer(analyzer = 'char', ngram_range = (2,2))
print(cv.fit_transform(sample_domain).toarray())
#[[0 0 0 0 0 0 0 0 0 1 1 0 0 1 0 1 1 0 0]
# [0 1 0 1 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0]
# [1 0 1 2 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0]
# [0 0 0 0 1 0 1 1 1 0 0 0 0 0 0 0 0 1 1]]
print(cv.get_feature_names())
#['ab', 'ai', 'al', 'ba', 'bu', 'du', 'eb', 'ee', 'fr', 'gl', 'go', 'ib', 'id', 'le', 'li', 'og', 'oo', 're', 'uf']
上面的代码实现了四个域名的2-gram字符级别的向量化,向量的数据内容就是某个2-gram的字符串出现的次数。例如上面的第三个域名"alibaba",其中带有两个"ba",输出结果的第三个向量中,可以看到对于2-gram的‘ba’的索引处是2。
一般经过词袋模型处理后,还需要利用TF-IDF继续处理。 TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比[5],
利用这种方法来找到相对重要的词。
那么这部分域名向量化整体处理的代码整合起来如下:
# sample_x是域名的数组
cv = CountVectorizer(analyzer='char',ngram_range = ngram_range)
cv_fit = cv.fit_transform(sample_x)
sample_x_tfidf = TfidfTransformer().fit_transform(cv_fit.toarray())
在得到向量之后,还需要降维进行可视化,本使用TSNE进行降维,并利用散点图查看家族的分类。因为手里的计算资源有限,所以每个恶意DGA家族(数量在1000以上)以及正常的域名随机采样500个进行处理。
 图4.1
图4.1
域名可视化(2-gram词袋模型与TF-IDF向量)
在图4.1中,一共22个类别(包括正常域名),其中只有两个类别能够明显看到簇的概念。虽然有些地方也能看到点集中在一些区域,但整体的聚合度并不高。
4.2 word2vec模型
word2vec模型是一种在自然语言处理中常用的域名,可以将单词转化为向量,来进行后续的各种处理。关于word2vec的模型原理这里不再赘述,有兴趣的读者可以看文章[6]。在本篇文章中,处理的对象是域名,那么处理的基础单元是字符,该部分中处理的对象分别是1-gram和2-gram。在经过向量化处理之后,每个字符或者2-gram都得到了相应的向量,但对于整个域名来说,可视化需要计算整个域名的向量,本文中采用比较简单的方法,直接将全部向量相加之后取平均的方式。
4.2.1 单个字符形式(1-gram)
针对全部DGA家族,选取其中域名数量大于1000的域名家族,然后分别采用1000个,进行可视化分析。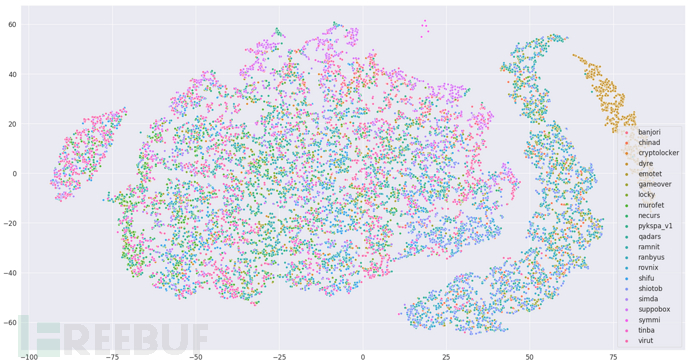
图4.2 word2vec模型(1-gram形式)
图4.2仅绘制了各个家族的散点图,没有包含正常的域名,主要事为了看家族的分类效果。从图中可以看出,只有最右边能看出来某个家族集中在一个簇,其他的部分依然是比较分散。
4.2.2 2-gram形式
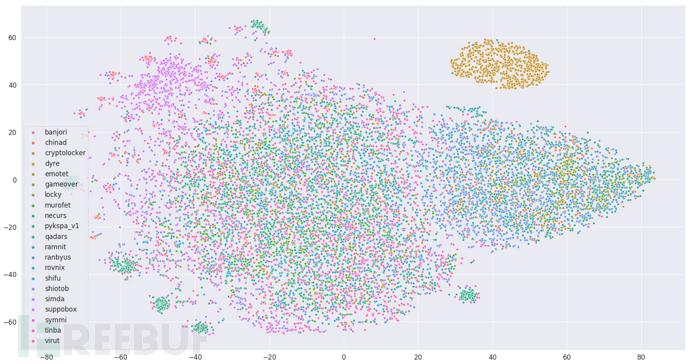 图4.3
图4.3
word2vec模型(2-gram形式)
同样是采用1000个域名,图4.3针对2-gram进行了降维可视化,与4.2相同,也只有一个类能够聚类在一起。
4.3 小节
本部分讲述了如何利用自然处理的方式来进行可视化,主要利用了两种模型:词袋+TF-
IDF以及WORD2VEC模型。从前面的几个可视化的图来看,效果并不是很好。进行可视化的目的是希望能够在低维空间看到他们的具体分布,但图中的效果较差,可能的原因是降维过程中丢失了信息。
五、深度学习分类
在DGA域名检测过程中,包含两个方面:1)如何判定某个域名是否是DGA域名;2)如何判定该DGA属于哪个家族。本节将分别从这两个方面对实验内容进行阐述。本部分分类实验主要参考了文章[4],文中主要对比了三种四种模型bigram,lstm,cnn,lstm+cnn以及这些模型分别的扩展在DGA检测中的效果。本文中将使用其中的两种模型来进行分类实验,分别是CNN和LSTM;文章[4]中没有进行家族分类,本文引入了家族分类,使用的模型依然是前面的模型。两个任务对于数据集的划分,按照2:1的比例来划分,其中1/3为测试集。
5.1 判断某个域名是否是DGA域名
DGA域名检测过程中的第一个目标是判断该域名是否是DGA域名;在该部分实验中,将直接使用全部数据来进行实验:正常域名、DGA域名,其中域名的数量见表2-1。关于LSTM及CNN的具体原理这里也不详细展开,要说明的是CNN模型使用的是Conv1D层来应对域名这种序列数据。本文中使用模型代码对原文[4]的代码稍微进行了修改,大致功能是一样的,例如替换LSTM为CuDNNLSTM使训练更快。同时使用的数据也不一样,文章[4]中的数据是采用DGA算法生成的,各个类别的数据相当,而本文是直接采用的开源的数据,每个DGA家族之间的数据分布很不均衡,
且家族数据也不一致。下面看一下具体的分类效果。
 图5.1
图5.1
CNN与LSTM的ROC曲线
表5-1 两个模型的性能比较
| 分类器\性能 |
精确率 |
召回率 |
F1分数 |
准确率 |
AUC分数 |
| LSTM |
0.9900 |
0.9913 |
0.9906 |
0.9915 |
0.9993 |
| CNN |
0.9787 |
0.9831 |
0.9808 |
0.9825 |
0.9971 |
两者的ROC曲线差别不是很明显,差距不是很大;同时其他性能的差距也不是很大,在精确率上LSTM达到了99.0%。
5.2 对域名进行家族分类
在对域名的家族分类时,各个域名家族数量分布是非常不一致的,在前面3.1图中也可以看出,各个家族的数量非常悬殊,同时家族的数量甚至不到100,这对后期的分类过程影响非常大。本部分实验选用域名数量在2000以上的家族进行分类,这样能够保证训练集的数量。经过筛选之后剩余域名家族17个。下面来看相应的分类效果。
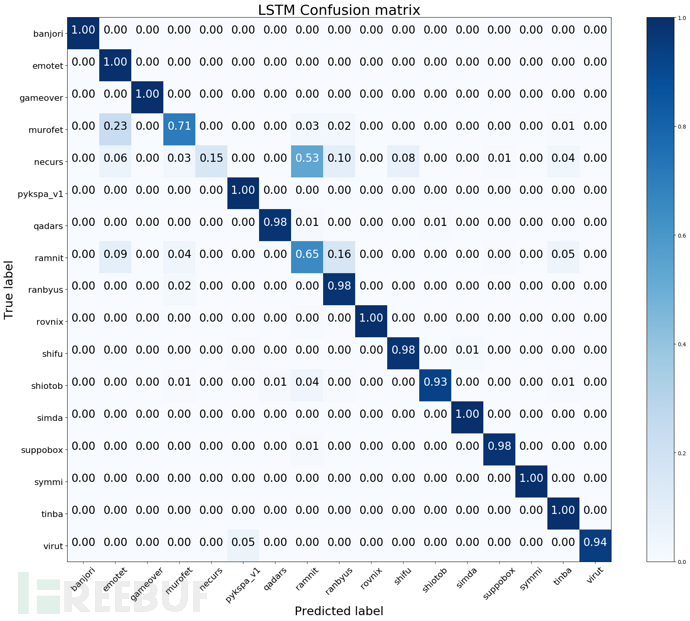
图5.2 LSTM家族分类效果

图5.3 CNN家族分类效果
本部分家族分类过程,采用与5.1节中是否DGA分类过程中同样的模型。根据图5.2与图5.3的域名家族分类效果,两者都存在某些家族全部被误分类的现象,例如DGA家族necurs,在LSTM模型分类结果中,大部分被误分类为ramnit;CNN误分类的情况更多。从整体效果来看,LSTM模型的分类效果更好。而且,在训练过程中就可以发现,CNN模型的损失函数最小值要比LSTM模型大很多。
5.3 小节
本部分针对是否是DGA域名以及DGA家族分类进行了相关实验,采用了CNN与LSTM两种模型。在家族分类任务中,LSTM模型要比CNN的效果更好。在是否是DGA域名的分类过程中,LSTM比RNN提升大致1%。在家族分类中,即使是LSTM模型也存在某个家族分类错误率较高的情况。虽然LSTM能够达到99%的性能,但是在数据量如此大的情况下,特别是针对恶意软件的监控中,误分类可能也会造成较大的影响,还是需要对性能进行更进一步的提升。
六、总结
本文围绕DGA域名的检测开展了一系列的工作,包括以下几点:
1)
对正常域名和DGA域名进行了数据分析,大致展示了一些数学意义上的分布,例如长度、字符。通过该部分内容可以对DGA域名和正常域名的区别有简单的了解;但这部分也有一些欠缺,还有很多工作可以分析,例如DGA域名使用的后缀,域名的熵值分析等。
2)利用自然语言处理的方式将域名转化为向量,并使用降维算法进行降维后在二维空间进行可视化。但这部分的效果不是很好,很多类别都散列在一起,只有极少数的家族能够形成簇,这一点比较失败。导致这种现象的原因应该是多方面的,可能在降维过程中信息产生了丢失。
3)选用深度学习的算法进行相关的分类工作,包括是否是DGA,以及DGA域名的家族分类,采用的模型有LSTM和CNN。从本次实验中的设置来看,LSTM能达到更好的结果。该部分也存在一些问题,例如家族分类中,可以看到有些家族的分类较差。
本文主要是对DGA域名检测过程一次尝试,希望从数据分布的角度了解DGA域名,利用深度学习的方法实现分类过程,同时尝试使用自然语言处理的方式实现可视化。从上述内容看出,本文的实验分析还是由很多欠缺,例如可视化过程中,可以尝试利用特征工程的方式自己构造特征后降维实现;在家族分类中,没有使用后缀信息,有些域名家族会固定使用某些后缀,在后续的研究过程中可以添加这部分信息来提高性能。
最后
分享一个快速学习【网络安全】的方法,「也许是」最全面的学习方法:
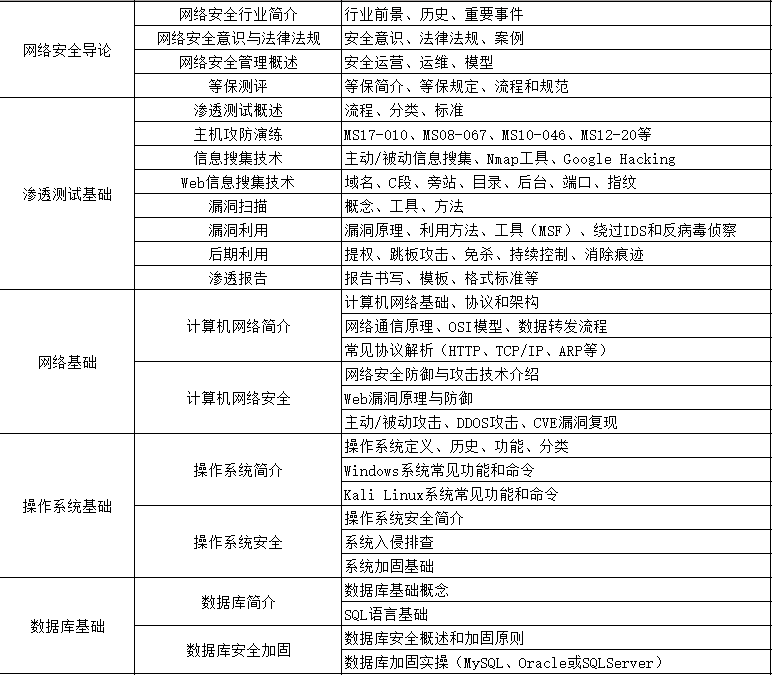
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(一周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(一周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(一周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)
恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k。
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
想要入坑黑客&网络安全的朋友,给大家准备了一份:282G全网最全的网络安全资料包免费领取!
扫下方二维码,免费领取

有了这些基础,如果你要深入学习,可以参考下方这个超详细学习路线图,按照这个路线学习,完全够支撑你成为一名优秀的中高级网络安全工程师:

高清学习路线图或XMIND文件(点击下载原文件)
还有一些学习中收集的视频、文档资源,有需要的可以自取:
每个成长路线对应板块的配套视频:
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。

因篇幅有限,仅展示部分资料,需要的可以【扫下方二维码免费领取】