本文借鉴于知乎用户秦路的专栏https://zhuanlan.zhihu.com/p/27910430,这里只是自己理解基础上加以扩充和整理修改,丰富细节。
由于手头用户消费数据的缺失我们这次采用专栏的数据进行实战。原数据在此:链接: https://pan.baidu.com/s/1IMd1ZOm2sTQSu-JKBAfy2A 提取码: dg38
#首先还是常规的导入库和读取文件
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime
#设定绘图风格
plt.style.use('ggplot')
#由于原数据没有列名,我们手动传入列名列表,并以任意空格为分隔符号
columns = ['user_id', 'order_dt', 'order_products',
'order_amount']
df =pd.read_table(r'/Users/herenyi/Downloads/
CDNOW_master.txt', names = columns, sep = '\s+')
#查看下读取后的数据集概况
df.head()
df.describe()
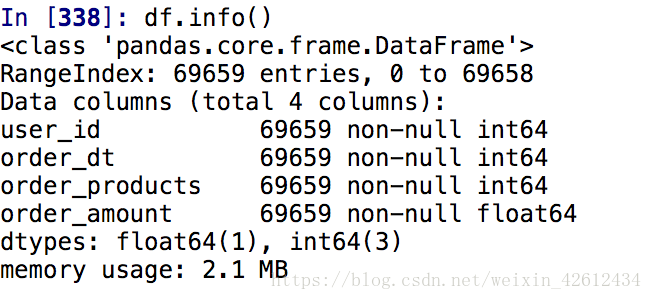
df.info()

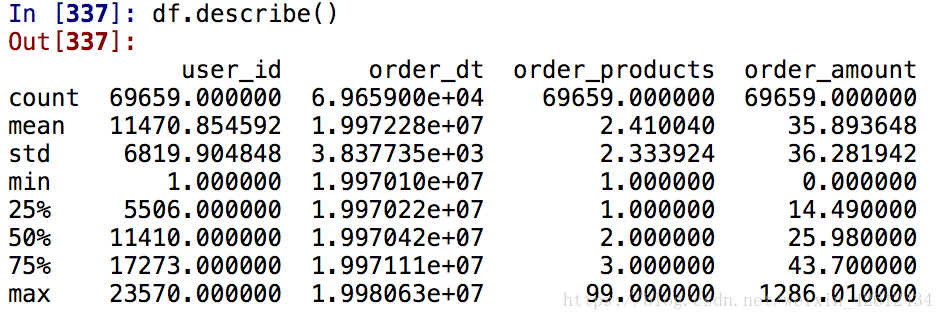
从上可知,这是一个关于用户购买某项东西的消费记录,主要有用户ID,购买时
间,订单个数和订单金额四项,平均每笔订单消费金额为35美金,标准差为36美
金,中位数为25,也就是说平均数大于中位数,也就是正偏分布,大多数用户消费
金额集中在小额,小部分用户贡献大额消费,符合消费类数据的二八分布。由于没
有空缺数据,可以不用清理直接开始分析,同时我们注意到日期数据是整数型,需
要转换成时间格式。
#加入两个时间新列
df['order_date'] = pd.to_datetime(df.order_dt, format ='%Y%m%d')
df['month'] = df.order_date.values.astype('datetime64[M]')
df.head()
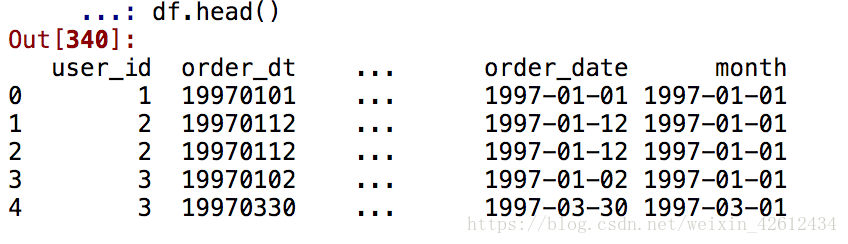
pd.to_datetime可以将特定的字符串或者数字转换成时间格式,其中的format参数表
示输出的格式,%Y匹配四位数年份,%m匹配月份,%d匹配日期。若想输出year-
month-day这形式,则是%Y-%m-%d。
astype也可以将时间格式进行转换,比如[M]转化成月份。我们将月份作为消费行为
的主要事件窗口,选择哪种时间窗口取决于消费频率。
#按用户ID进行分组
user_grouped = df.groupby('user_id').sum()
user_grouped.head()
user_grouped.describe()
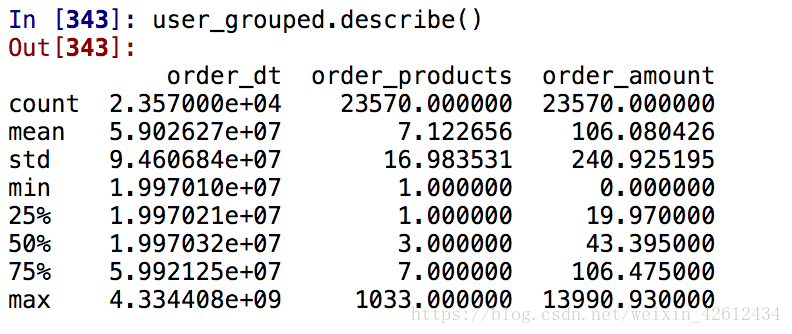
由于原表只按订单来记录,按用户分组下看下数据集概述,毕竟我们这是用户消费
行为分析。从用户角度看,每位用户平均购买7张CD,最多的用户购买了1033张,
属于狂热用户了。用户的平均消费金额100元,标准差是240,中位数是3张,说明
是长尾分布,存在小部分购买多张碟的高消费用户。下面我们就开始按月度来进行
分析。
#导入中文
from matplotlib.font_manager import FontProperties
chinese = FontProperties(fname = r'/Users/Shared/Epic Games/Fortnite/Engine/Content/Slate/Fonts/DroidSansFallback.ttf')
ax = df.groupby('month').order_amount.sum().plot()
ax.set_xlabel('月份', fontproperties=chinese)
ax.set_ylabel('消费金额(美元)', fontproperties=chinese)
ax.set_title('不同月份的用户消费金额', fontproperties=chinese)
ax = df.groupby('month').order_amount.sum().plot()
ax.set_xlabel('月份', fontproperties=chinese)
ax.set_ylabel('CD碟数(张)', fontproperties=chinese)
ax.set_title('不同月份的用户购买张数', fontproperties=chinese)
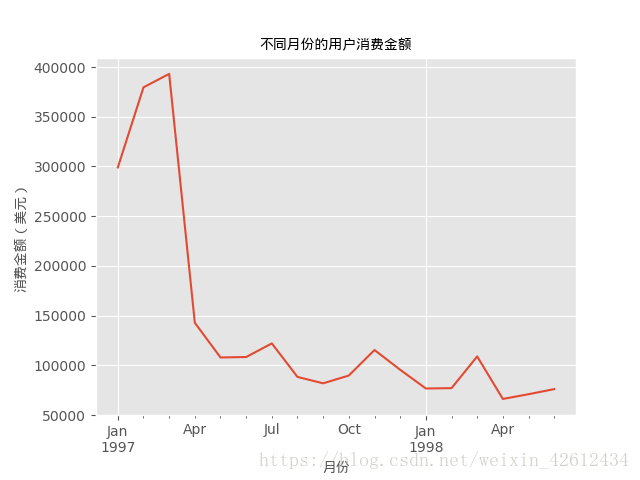
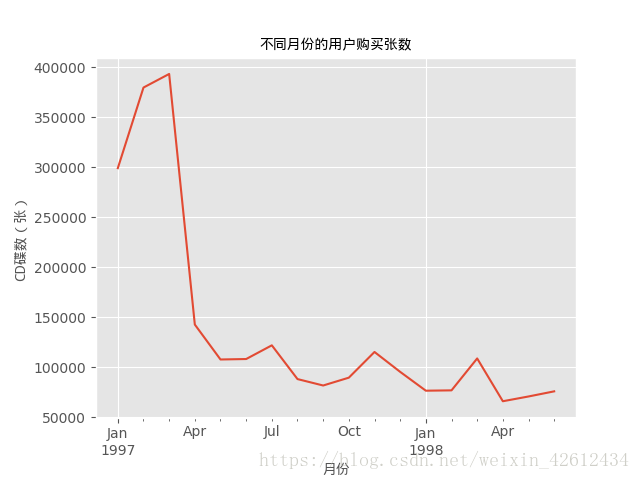
由图片可知,无论是消费金额还是CD碟数都呈现相同的趋势,而且前三月数据都呈
现出异常状态,由于我们不知道原数据到底从何获得,只能做出这三个月有促销活
动,抑或是这是新开的店之类的,前三个月大多都是新人之类的假设,我们不得而
知,继续往下看。
ax = df.groupby('user_id').sum().plot.scatter('order_amount', 'order_products')
ax.set_xlabel('消费金额', fontproperties=chinese)
ax.set_ylabel('CD碟数(张)', fontproperties=chinese)
ax.set_title('每个用户消费金额与购买个数的关系', fontproperties=chinese)
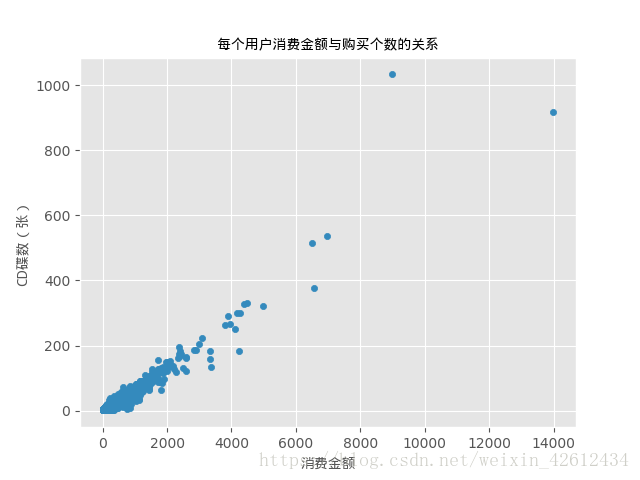
这是用户的消费金额与购买数量的关系。可以看到,因为是cd网站的消费记录,产
品价格没有太大区间差别,每个用户的消费金额跟购买数量呈现一定的线性关系。
为了更好的观察,我们尝试用直方图来呈现数据.
plt.figure(figsize = (12,4))
plt.subplot(121)
ax = df.grou