近年来,短视频作为一种新兴的互联网内容传播形式,逐渐获得各大平台和粉丝的青睐,其时长简短并适合在移动状态和休闲状态下观看的特点,将产品受众面拓展到整体网民的88.3%,上至老年人,下至小孩子,都多多少少可以自己创作一些短视频作品以供娱乐。

那么,有没有一款免费的AI语音合成软件可以满足这部分短视频爱好者的需求呢?小编这就带大家来了解一下。
凤凰配音小程序是一款免费并且好用的AI语音合成软件,微信小程序搜索“凤凰配音”即可,我们可以将其收藏进常用小程序里,再次使用时便可以直接打开,方便快捷。
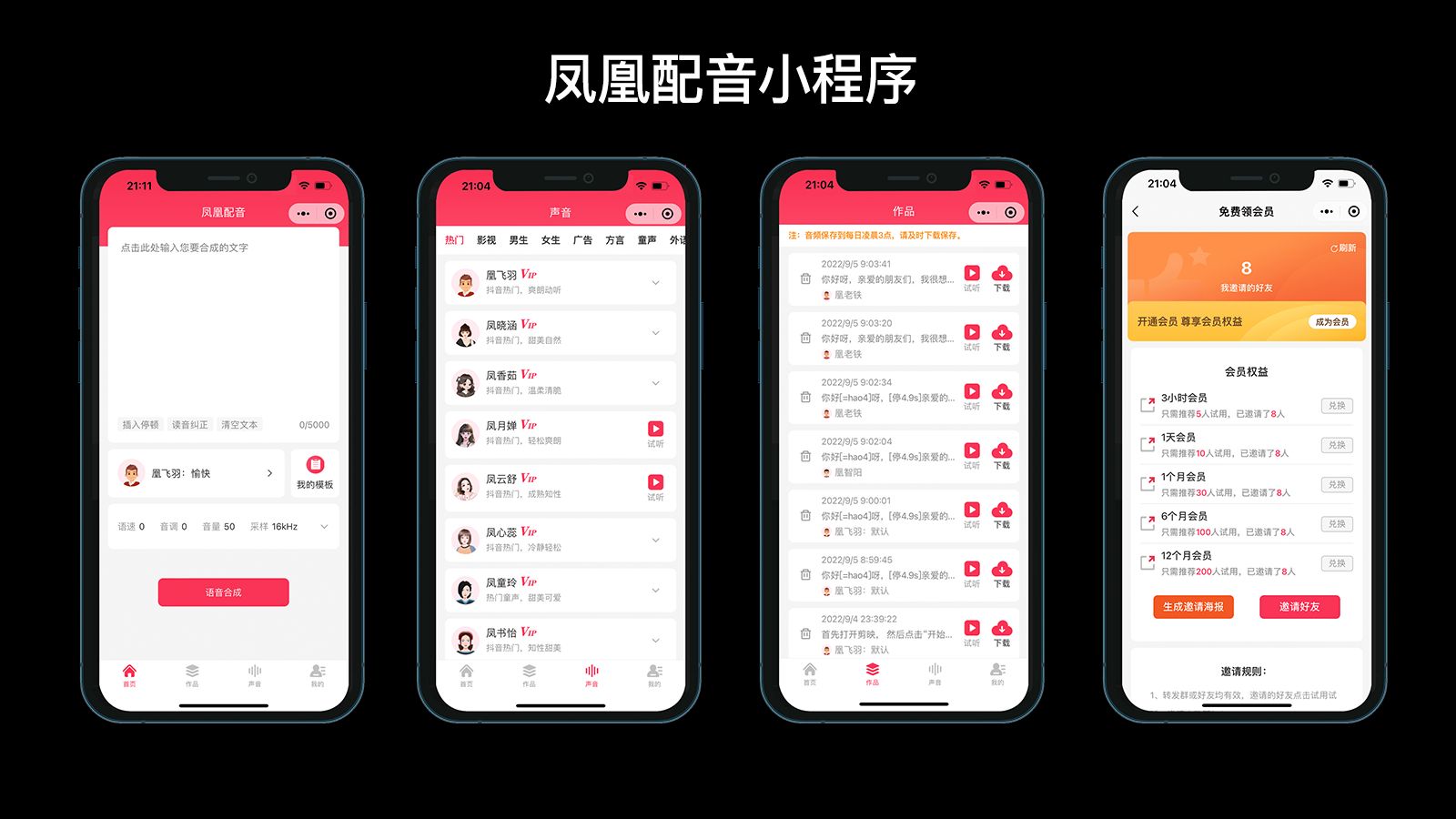
几百个配音员可供选择,我们日常所听到的声音,包括:影视解说、配音旁白、广告宣传、商场广播、各种男声女声童声、豪爽的东北方言、热辣的四川方言、软软的江浙沪方言等等,在这里都能找到,并且它的配音技术在同类型产品中也是名列前茅的,声音极度贴近真人,语气语调的抑扬顿挫和情感起伏,让配音达到了以假乱真的程度,非常牛气。

另外,凤凰配音在操作上也实现了功能齐全和设置方便的结合最大化,支持单人和多人配音,文字可根据自己的需求设置间隔及停顿等等,让整个配音作品更加自然流畅,声情并茂。
一款好的AI语音合成软件可以使整个创作过程事半功倍,让作品更加出色更加完美,如果你还没有找到合适又好用的AI语音合成软件,不妨试试凤凰配音小程序吧,相信它不会让你失望。