正则表达式与三剑客
Linux正则表达式
由一类特殊字符及文本字符所编写的模式,其中有些字符不表示其字面意义,而是用于表示控制或通配符的功能。
分两类: 基本正则表达式,BRE;扩展正则表达式,ERE。
基本正则表达式DRE集合
| 元字符 |
作用 |
| ^ |
只匹配行首 |
| $ |
只匹配行尾 |
| ^$ |
组合符,表示空行 |
| . |
匹配任意一个且只有一个字符,不能匹配空行 |
| \ |
转义符 |
| * |
匹配前一个字符连续出现0次或多次,一般结合 . 使用;通配符的 * 才可以单独使用,注意区分。 |
| .* |
组合符,匹配任意长度的任意字符, |
| [abc] |
匹配[]集合内的任意一个字符,a或b或c,可以写成[a-c] |
| [^abc] |
匹配除了 ^ 后面的任意字符,表示对[abc]的取反 |
|
匹配完整的内容 |
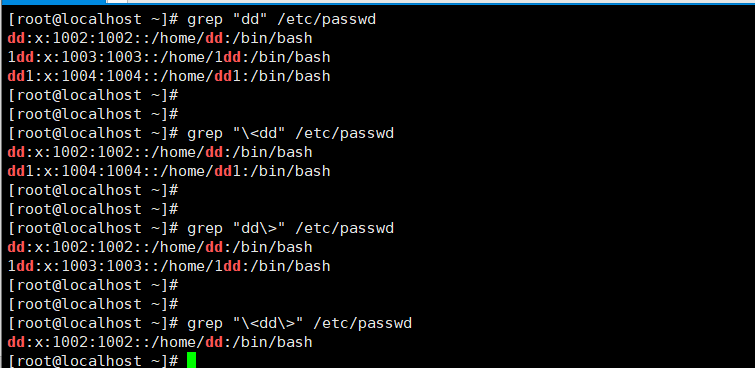
| < 或 > |
定位单词的左侧或右侧, |
| \> |
锚定词首,用于单词的最左侧 |
| \< |
锚定词尾,用于单词的最右侧 |
理解锚定词首和词尾:
扩展正则表达式ERP集合
扩展正则必须使用grep -E 才能生效
| 元字符 |
作用 |
| + |
至少匹配前一个字符一次或多次 |
[:/]+ |
匹配括号内的":" 或者 “/” 字符一次或多次 |
| ? |
匹配前一个字符0次或1次,前面的字符可有可无 |
| a{n,m} |
匹配前一个字符最少n次,最多m次 |
| a{n,} |
匹配前一个字符最少n次 |
| a{n} |
匹配前一个字符正好n次 |
| a{,m} |
匹配前一个字符最多m次 |
| () |
分组过滤,被括起来的内容表示一个整体 |
()小括号:
将一个或多个字符捆绑再一起,当做一个整体处理
小括号还要一个功能是:分组过滤被括起来的内容,括号内的内容表示一个整体;
括号内的内容可以被后面的 “\n” 正则引用,n为数字,表示引用第几个括号的内容
\1: 表示从左侧起,第一个括号中的模式所匹配到的字符
\2: 表示从左侧起,第二个括号中的模式所匹配到的字符
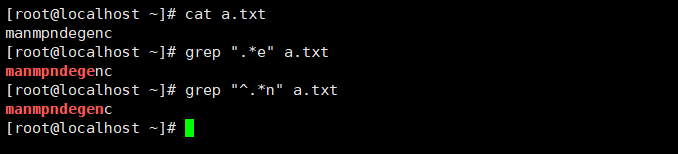
贪婪匹配
^.*o
^以某个字符为开头;
. 任意0个或多个字符;
* 代表匹配所有的内容;
o 普通字符字母o;
意思是:一直匹配到字母o结束,这种匹配相同字符到最后一个字符的特点,称之为贪婪匹配;
案例:
grep
文本搜索工具,根据用户指定的模式(过滤条件)对目标文本逐行进行匹配检查,打印匹配到行。
模式:由正则表达式的元字符及文本字符所编写出的过滤条件。
参数:
-c 只统计匹配的行数
-E 支持使用扩展正则表达式的元字符,等于egrep
-i 忽略字符的大小写
-I 查询多文件时只输出包含匹配字符的文件名
-n 显示匹配行与行号
-o 只输出匹配内容
-v 显示不能被匹配模式匹配到的行
-q 静默模式,即不输出任何信息
-m 最多匹配多少次
-w 只匹配过滤的单词
-s 不显示不存在或无匹配文本的错误信息
案例:
找出root相关的行,且显示行号,
[root@localhost ~]# grep -n "root" /etc/passwd
1:root:x:0:0:root:/root:/bin/bash
10:operator:x:11:0:operator:/root:/sbin/nologin
找出root相关的行,并统计匹配的行数
[root@localhost ~]# grep -c "root" /etc/passwd
2
仅输出匹配内容
[root@localhost ~]# grep -o "root" /etc/passwd
root
root
root
root
显示不能被匹配到的行
[root@localhost ~]# grep -v "root" /etc/passwd
常与正则表达式配合使用,查找过滤功能强大
找出/etc/init.d/functions文件中的所有函数名
[root@localhost ~]# grep -E "[a-zA-Z]+\(\)" /etc/init.d/functions -o
sed
简称流编辑器,是操作和转换文本内容强大的工具,注意sed和awk使用单引号。
常用功能包括结合正则表达式对文件实现快速增删改查,其中查询功能中最常用的是过滤和取行。
参数:
-n 取消默认的sed输出,常与sed内置命令p一起使用
-i 直接将修改结果写入文件,
-e 多次编辑,不需要管道符
-r 支持扩展正则
语法:
sed [选项] [sed内置命令字符] [输入文件]
sed常用内置命令字符:
| sed的内置命令字符 |
解释 |
| a |
对文本追加,在指定行后面添加一行/多行文本 |
| d |
删除匹配行 |
| i |
插入文本,在指定行前添加一行/多行文本 |
| p |
打印匹配行的内容,通常p与参数-n一起使用 |
| s/正则/替换内容/g |
匹配正则内容,然后替换内容(支持正常),g代表全局匹配 |
| c |
把选定的行改为新的文本 |
| = |
打印当前行号码 |
| # |
把注释扩展到下一个换行符以前 |
| w |
表示把行写入到一个文件 |
| y |
表示把一个字符翻译为另外的字符(但是不用于正则表达式) |
| G |
获取内存缓冲区的内容,并追加到当前模板文本的后面 |
| r |
从file中读行 |
sed 匹配范围
| 范围 |
解释 |
| 空地址 |
全文处理 |
| 单地址 |
指定文件某一行 |
| /patter/ |
被模式匹配到的每一行 |
| 范围区间 |
10,20 十到二十行;10,+5 第十行向下五行, |
| 步长 |
1~2:表示奇数行; 2~2 :两个步长,表示偶数行 |
基础案例:
y命令
把1~10行内所有abcde转变为大写,注意,正则表达式元字符不能使用这个命令:
sed '1,10y/abcde/ABCDE/' file
d命令;删除模式空间内容,改变脚本的控制流,读取新的输入行
删除空白行
sed '/^$/d' file
sed取ip地址
ifconfig | sed -e '2s/^.*inet//' -e '2s/netmask.*$//gp' -n
组合多个表达式取ip地址
sed '表达式' | sed '表达式' 等价于: sed '表达式; 表达式'
[root@localhost ~]# ifconfig | sed ''2s/^.*inet//' ; '2s/netmask.*$//gp'' -n
192.168.178.3
当需要从第N处匹配开始替换时,可以使用 /Ng
[root@localhost ~]# echo asasasasas |sed 's#as#AS#2g'
asASASASAS
[root@localhost ~]# echo asasasasas |sed 's@as@AS@3g'
asasASASAS
[root@localhost ~]# echo asasasasas |sed 's/as/AS/g'
ASASASASAS
找出系统版本号
sed -r 's/^.*release[[:space:]]([^.]+).**/\1/p' /etc/centos-release -n
向文本中插入空白行
[root@localhost ~]# cat b.txt
This is the header line.
This is the first data line.
This is the second data line.
This is the last line.
[root@localhost ~]# sed 'G' b.txt
This is the header line.
This is the first data line.
This is the second data line.
This is the last line.
[root@localhost ~]#
[root@localhost ~]#
这里技巧在于,sed的G命令,会简单的保持空间内容附加到模式空间后,当sed启动的时候,保持开机默认只有一个空行,讲它附加到已有行后面,就是上述的效果。
向文本插入空白行,去掉最后一行的空白
[root@localhost ~]# sed '$!G' b.txt
This is the header line.
This is the first data line.
This is the second data line.
This is the last line.
[root@localhost ~]# sed '2!G' b.txt
This is the header line.
This is the first data line.
This is the second data line.
This is the last line.
sed进阶
1.全局替换
默认是替换匹配到的第一个内容,g命令,全局替换
[root@localhost ~]# head -2 /etc/passwd |sed 's/root/+++/'
+++:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
[root@localhost ~]# head -2 /etc/passwd | sed 's/root/+++/2'
root:x:0:0:+++:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
[root@localhost ~]# head -2 /etc/passwd |sed 's/root/+++/g'
+++:x:0:0:+++:/+++:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
2.打印模式空间,所以出现两次
[root@localhost ~]# head -2 /etc/passwd | sed 's/root/+++/p'
+++:x:0:0:root:/root:/bin/bash
+++:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
# 配合-n 使用,取消sed默认输出,只输出替换成功的行
[root@localhost ~]# head -2 /etc/passwd | sed 's/root/+++/p' -n
+++:x:0:0:root:/root:/bin/bash
寻址:
默认对每行进行操作,增加寻址后对匹配的行进行操作
-
/正则表达式/s/old/new/g
-
行号s/old/new/g
-
可以使用两个寻址符号,也可混合使用行号和正则地址
案例:
sed '1,3s/adm/!/' file
sed '/root/s/bash/!!!/' /etc/passwd
sed '/^bin/,$s/nologin/!/' /etcpasswd
head -6 /etc/passwd |sed '/^bin/s/nologin/++/'
以bin开头一直到结尾,只要出现nologin就替换
[root@localhost ~]# head -6 /etc/passwd |sed '/^bin/,$s/nologin/++/'
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/++
daemon:x:2:2:daemon:/sbin:/sbin/++
adm:x:3:4:adm:/var/adm:/sbin/++
lp:x:4:7:lp:/var/spool/lpd:/sbin/++
sync:x:5:0:sync:/sbin:/bin/sync
#相当于以/^bin/开头到结尾只要出现/nologin/便替换,出现多次可加g,全局替换
####sed的增删改和读写
删除
追加,插入,更改
打印
下一行
读文件,写文件
退出命令
案例:
1.删除--d指令;删除模式空间内容,改变脚本的控制流,读取新的输入行
[root@localhost ~]# cat bfile
b
a
aa
aaa
ab
abb
abbb
[root@localhost ~]# sed '/ab/d' bfile
b
a
aa
aaa
[root@localhost ~]# sed 's/ab/+/' bfile
b
a
aa
aaa
+
+b
+bb
# 区分s和d,s会替换匹配到的字符,而d会删除匹配到的行
改变控制流;就是使用d指令后,后面跟着其他指令都不会被执行
[root@localhost ~]# sed '/ab/d;s/a/!/' bfile
b
!
!a
!aa
#进行d删除的是没有被替换的
追加;插入和更改命令;可以配合-i参数使用,
2.追加行--a指令,在指定行的下一行追加
[root@localhost ~]# sed '2a 192.168.178.120 m01' /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.178.120 m01
3.插入--i指令,在指定行的上一行插入内容
[root@localhost ~]# sed '1i 192.168.178.120 m01' /etc/hosts
[root@localhost ~]# sed '1i 192.168.178.120 m01' /etc/hosts
192.168.178.120 m01
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
4.更改命令--c指令
[root@localhost ~]# sed '2a 192.168.178.120 m01' /etc/hosts -i
[root@localhost ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.178.120 m01
[root@localhost ~]# sed '/^192/c 192.168.178.111 web02' /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.178.111 web02
5.读文件--r指令
[root@localhost ~]# cat bfile
b
a
aa
aaa
ab
abb
abbb
[root@localhost ~]# sed '/ab/r afile' bfile
b
a
aa
aaa
ab
i love linux and python
abb
i love linux and python
abbb
i love linux and python
# 意思是在bfile中每匹配到一次/ab/就读入a文件一次,可以利用重定向生合并成新的文件
[root@localhost ~]# sed '/ab/r afile' bfile > c.txt
6.写入文件:w指令
[root@localhost ~]# cp /etc/passwd a.txt
[root@localhost ~]# sed -n '/root/w b.txt' a.txt
[root@localhost ~]# cat b.txt
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
相当于把在a.txt中匹配到的root行写入到b.txt中
7.打印行号 = 等号
[root@localhost ~]# sed '=' /etc/hosts
1
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
2
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
3
192.168.178.120 m01
# 有点丑,还可以使用nl ,cat grep这样的命令
8.下一行命令 n指令;读取下一个输入行,用下一个命令处理新的行而不是第一个命令
[root@localhost ~]# sed '/ab/{ n; s/a/2/; }' bfile
b
a
aa
aaa
ab
2bb
abbb
#意思是匹配到ab的行,跳到下一行然后s替换a为2,所以当匹配到ab的时候,跳到下一行把abb替换成了2bb。
[root@localhost ~]# cat bfile
b
a
aa
aaa
ab
abb
abbb
9.退出命令q
[root@localhost ~]# sed '2q' /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
# 匹配到第二行就退出
与p结合 -n效果一样,但是q指令效率更高
[root@localhost ~]# sed -n '1,2p' /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
# 可以使用time命令查看执行时间
sed – next命令
sed小写的n命令会告诉sed编辑器移动到数据流中的下一行文本。
sed编辑器在移动到下一行文本前,会在当前行执行完毕所有定义好的命令,单行next命令改变了这个流程
案例:
[root@localhost ~]# cat data.txt
This is an apple.
This is a boy.
This is a gril.
[root@localhost ~]# sed '/^$/d' data.txt
This is an apple.
This is a boy.
This is a gril.
#加入想要指定删除某个语句后面的空行,就可以使用n指令
[root@localhost ~]# sed '/apple/{n;d}' data.txt
This is an apple.
This is a boy.
This is a gril.
# sed编辑器匹配到apple这一行,通过n指令,让sed编辑器移动到文本的下一行,也就是空行,通过d指令删除。此时sed执行完毕命令后,继续重复查找apple,如果找到继续删除apple的下一行,如果找不到就不会执行任何动作。
sed特殊指令–多行模式
N: 将下一行加入到模式空间
D:删除模式空间中的第一个字符到第一个换行符
P:打印模式空间中 的第一个字符到第一个换行符
案例:
# N指令演示
大写N指令将下一行文本添加到模式空间中已有的文本的后面,实现多行文本处理。
这个作用可以将数据流的两个文本合并在同一个模式空间里处理。
案例1:
[root@localhost ~]# cat a.txt
hel
lo
[root@localhost ~]# sed 'N' a.txt
hel
lo
[root@localhost ~]# sed 'N;s/\n//' a.txt
hello
# 配合通配符点 . 使用
[root@localhost ~]# sed 'N;s/hel\nlo/+++/' a.txt
+++
#点 . 去匹配换行符的一种例外情况
[root@localhost ~]# sed 'N;s/hel.lo/+++/' a.txt
+++
sed 大写D,只删除模式空间里的第一行,该指令会删除到换行符位置的所有字符
结合NP使用案例:
创建数据文件:
[root@localhost ~]# cat >b.txt << EOF
> hell
> o bash hel
> lo bash
> EOF
[root@localhost ~]# cat b.txt
hell
o bash hel
lo bash
需求把hello bash 替换成 hello sed,
[root@localhost ~]# sed 's/hello bash/hellp sed/' b.txt
hell
o bash hel
lo bash
因出现在了多行,所有无法直接替换实现
思路:
[root@localhost ~]# sed 'N;s/hell.o bash/hello sed\n/;s/.hel\nlo bash/hello sed/;P;D' b.txt
hello sed
hello sed
sed 保持空间
se除了一块模式空间用于sed编辑器执行命令的时候,保存待检测的文本以为,还有一块空间叫做保持空间的缓冲区域。保持空间也是多行的一种操作方式,将内容暂存在保持空间,便于做多行处理。
保持空间命令
| 命令 |
描述 |
| h/H |
将模式空间的内容存放到保持空间,小写h是覆盖模式,大写H是追加模式 |
| g/G |
将保持空间的内容取出到模式空间,同样小写是覆盖,大写是追加。 |
| x |
交换模式空间和保持空间的内容 |
案例:
使用sed实现如下效果:
[root@localhost ~]# head -6 /etc/passwd |cat -n |tac
6 sync:x:5:0:sync:/sbin:/bin/sync
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
2 bin:x:1:1:bin:/bin:/sbin/nologin
1 root:x:0:0:root:/root:/bin/bash
[root@localhost ~]# cat -n /etc/passwd |head -6 | sed -n 'G;h;$p'
6 sync:x:5:0:sync:/sbin:/bin/sync
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
2 bin:x:1:1:bin:/bin:/sbin/nologin
1 root:x:0:0:root:/root:/bin/bash
[root@localhost ~]#
[root@localhost ~]# cat -n /etc/passwd |head -6 | sed -n '1!G;h;$p'
6 sync:x:5:0:sync:/sbin:/bin/sync
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
2 bin:x:1:1:bin:/bin:/sbin/nologin
1 root:x:0:0:root:/root:/bin/bash
# 或者
[root@localhost ~]# cat -n /etc/passwd |head -6 | sed '1!G;h;$!d'
6 sync:x:5:0:sync:/sbin:/bin/sync
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
2 bin:x:1:1:bin:/bin:/sbin/nologin
1 root:x:0:0:root:/root:/bin/bash
sed编辑会将一些处理命令应用到数据流中的每一个文本行,单个行,或者一些区间行,也支持排除某个区间。sed支持使用感叹号 ! 来排除命令,让某给命令不起作用
sed脚本模式
(一)用法:
# sed -f scripts.sh file //使用脚本处理文件
建议使用 ./sed.sh file
脚本的第一行写上
#!/bin/sed -f
1,5d
s/rot/hello/g
3i777
5i888
a999
p
(二)用法
脚本文件是一个sed的命令清单
在每行的末尾不能有任何空格,制表符(tab)或其他文本
如果在一行中有多个命令,应该使用分号分隔
不需要且不可用引号保护命令
#号开头的行为注释
awk
文本和数据进行处理的编程语言
简介:awk是一种编程语言,用于Linux/unix下对文本和数据进行处理。数据可以来自标准输入(stdin),一个或多个文件,或其他命令的输出,它支持用户定义函数和动态正则表达式等先进功能,是Linux/unix下的一个强大编程工具。awk有很大内建功能,如:数组,函数等,这是它和c语言的相同之处,灵活性是awk最大的优势。
语法:
awk 可选参数 条件动作 文件
常用命令选项:
-F 指定输入分隔符
-v 定义或修改
-f 从脚本文件中读取awk命令
awk的模式和操作
awk脚本是由模式和操作组成的。
模式
模式可以是以下任意一个:
- /正则表达式/:使用通配符的扩展集
- 关系表达式:使用运算符进行操作,可以是字符串或数字的比较测试
- 模式匹配表达式:用运算符 ~ 匹配 和 !~ 不匹配。
- BEGIN语句块,pattern语句块,END语句块
操作
操作是由一个或多个命令,函数,表达式组成,之间由换行符或者分号隔开,并且位于大括号内,主要部分是:
awk脚本基本机构
awk 'BEGIN{print "start"} pattern{ commands} END{ print "end"}' file
内置变量
| 内置变量 |
解释 |
| $n |
指定分隔符后,当前记录的第n个字段 |
| $0 |
完整的输入记录 |
| FS |
输入字段分隔符,默认是任何空格 |
| OFS |
输出字段分隔符,默认是一个空格 |
| RS |
输入记录分隔符(输入换行符);指输入时的换行符 |
| ORS |
输出记录分隔符(输出换行符),输出时用指定符号代替换行符 |
| NF |
当前行的字段的个数,即当前被分隔成了几列,$(NF-1)表示倒数第二行, |
| NR |
行号,当前处理的文本的行号 |
| FNR |
各文件分别计数的行号 |
| FILENAME |
当前文件名 |
| ARGC |
命令行参数的个数 |
| ARGV |
包含命令行参数的数组;ARGV表示的是一个数组,数组中保存的是命令行所给的参数 |
案例:
取IP
[root@localhost ~]# ifconfig |awk 'NR==2{print $2}'
找出能登录的用户
[root@localhost ~]# awk -F ":" '/\/bin\/bash$/{print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
显示2-5行,且显示行号
[root@localhost ~]# awk 'NR==2,NR==5{print NR,$0}' /etc/passwd
显示文件的第一列,倒数第二列,最后一列
[root@localhost ~]# awk -F ":" '{print $1,$(NF-1),$NF}' /etc/passwd
取用户名和解释器
[root@localhost ~]# awk -F ":" '{print $1,$NF}' /etc/passwd
[root@localhost ~]# awk -v FS=":" '{print $1,$NF}' /etc/passwd
-V 定义,修改
FS 输入分隔符,默认空格
指定输出分隔符OFS案例,
[root@localhost ~]# awk -F ":" -v OFS="----------" '/^root/{print $1,$NF}' /etc/passwd
root----------/bin/bash
修改分隔符,改为\t制表符,默认四个空格
[root@localhost ~]# awk -F ":" -v OFS="\t\t\t\t\t" '/^root/{print $1,$NF}' /etc/passwd
root /bin/bash
#对比输出效果
使用FNR变量,分别对文件计数
[root@localhost ~]# awk '{print FNR,$0}' /etc/selinux/config /etc/hosts
内置变量RS
[root@localhost ~]# cat test.txt
cc1 cc2 cc3 cc4 cc5
cc6 cc7 cc8 cc8 cc10
bb1 bb2 bb3 bb4 bb5
bb6 bb7 bb8 bb9 bb10
默认是回车符换行,通过-v RS=' ' 修改后,一遇到空格便换行处理
[root@localhost ~]# awk -v RS=' ' '{print $0}' test.txt
cc1
cc2
...
bb10
[root@localhost ~]#
内置变量ORS,默认每一行结束是回车符换行,利用ORS修改输出换行符
[root@localhost ~]# awk -v ORS='---' '{print NR,$0}' test.txt
1 cc1 cc2 cc3 cc4 cc5---2 cc6 cc7 cc8 cc8 cc10---3 bb1 bb2 bb3 bb4 bb5---4 bb6 bb7 bb8 bb9 bb10---
ARGC和ARGV
ARGC和ARGV允许awk从shell中获取命令行参数的总数,但是awk不会把脚本文件当中参数的一部分
变量ARGC:ARGC变量表示命令行上的参数,包括和文件名
[root@localhost ~]# awk 'BEGIN{print ARGC}'
1
[root@localhost ~]# awk 'BEGIN{print ARGC}' /etc/passwd
2
[root@localhost ~]# awk 'BEGIN{print ARGC}' /etc/passwd /etc/hosts
3
ARGV表示的是一个数组,数组中保存的是命令行所给的参数
变量ARGV数值值从索引0开始,表示awk本身,索引1表示第一个命令行参数
[root@localhost ~]# awk 'NR==1{print ARGV[0],ARGV[1],ARGV[2]}' test.txt /etc/passwd
awk test.txt /etc/passwd
ARGV[0] 表示awk
ARGV[1] 表示文件名 test.txt
ARGV[2] 表示文件名 /etc/passwd
总结:awk内置变量的引用不用加美元符。
算数运算
| 运算符 |
描述 |
| + - |
加,减 |
| * / & |
乘,除与求余 |
| + - ! |
一元加,减和逻辑非 |
| ^ *** |
求幂 |
| ++ – |
增加或减少,作为前缀或后缀 |
案例:
[root@localhost ~]# awk 'BEGIN{a=0;print a++,++a;}'
0 2
[root@localhost ~]# awk 'BEGIN{a=1;print a++,++a;}'
1 3
[root@localhost ~]# awk 'BEGIN{a=2;print a++,++a;}'
2 4
每处理一次+1
a++先赋值,再运算
++a先运算,再赋值
注意:所有用作算术运算符进行操作,操作数字段转为数值,所有非数值都变为0.
awk格式化输出
要点:
1.与print命令的最大不同是printf需要指定format
2.format用于指定后面的每个item项的输出格式
3.printf语句不会字段打印换行符,
format格式的指示符都以%开头,后面跟一字符;如下:
%c:显示字符的ASCII码;单个字符
%d, %i:十进制整数
%e, %E:科学计数法显示数值
%f:显示浮点数
%g, %G:以科学计数法的格式或浮点数的格式显示数值
%u:无符号整数
%%:显示%自身
printf修饰符号:
-:左对齐;默认右对齐
+:显示数值符号;printf "+%d"
案例:
print默认动作不会添加换行符
[root@localhost ~]# cat 1.doc
a
ab
abc
[root@localhost ~]# awk '{print $0}' 1.doc
a
ab
abc
[root@localhost ~]# awk '{printf $0}' 1.doc
aababc
格式化输出,部分效果图如下:
awk -F ":" 'BEGIN{printf "%-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\n","用户名","密码","UID","GID","用户注释","用户家目录","用户使用的解释器"} {printf "%-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %s\n",$1,$2,$3,$4,$5,$6,$7}' /etc/passwd
参数解释:
BEGIN{printf }:执行BEGIN模式
%s是格式替换符,替换字符串
%s\t 格式化字符后,添加制表符,一个制表符是四个空格
%-25s 格式化字符串,-代表左对齐,25个字符长度
必须一一对应,一个选项对应一个格式化符号

awk模式pattern
特殊的pattern:BEGIN和END
BEGIN模式是处理文本之前需要执行的操作
END模式是处理完所有行之后执行的操作
案例:
常用于条件设置
[root@localhost ~]# awk '{print $1}' 1.doc
a
ab
abc
[root@localhost ~]# awk 'BEGIN{print "i love linux"}{print $1}END {print "and i love c++"}' 1.doc
i love linux
a
ab
abc
and i love c++
例2:
[root@localhost ~]# head -5 /etc/passwd |awk 'BEGIN{FS=":"}{print $1}'
root
bin
daemon
adm
lp
[root@localhost ~]# head -5 /etc/passwd |awk 'BEGIN{FS=":"}{print $1,$2}'
root x
bin x
daemon x
adm x
lp x
[root@localhost ~]# head -5 /etc/passwd |awk 'BEGIN{FS=":";OFS="-"}{print $1,$2}'
root-x
bin-x
daemon-x
adm-x
lp-x
awk的表达式
赋值操作符
| 运算符 |
描述 |
| = += -= *= /= %= ^= **= |
赋值语句 |
例如:
自定义变量
var1= "name"
var2= "hello" "world"
var3= $1
[root@localhost ~]# awk 'BEGIN{var="HELLO WORLD";print var}'
HELLO WORLD
[root@localhost ~]# awk 'BEGIN{var="HELLO WORLD";var1="i am bash";print var,var1}'
HELLO WORLD i am bash
自增操作符
a+=1;等价于:a=a+1;
数值计算
[root@localhost ~]# awk 'BEGIN{x=4;x=x^2;print x}'
16
逻辑运算符
布尔操作符
~ 匹配正则表达式
!~ 不匹配正则表达式
关系运算符
| 运算符 |
描述 |
| < <= > >= != == |
关系运算符 |
[root@localhost ~]# awk 'BEGIN{a=5;if(a >= 1){print "ok"}}'
ok
判断两个数值是否相等可以使用两个等号。
awk进阶
if条件语句:
if语句:{if(表达式) { 语句;语句;…}}
if …else语句:{if(表达式) {语句;语句;…} else {语句;语句;…}}
条件语句使用if开头,根据表达式的结果来判断执行哪条语句,若需要取命令结果,只能使用$()不支持``
if(表达式)
awk语句1
[else
awk语句2
]
如果有多个语句需要执行可以使用{}将多个语句括起来
如果表达式成立返回值为1,如果表达式成立返回值为0。
awk中if语句没有使用fi结尾
案例:
如果UID在1000-2000之间就打印出用户信息
[root@localhost ~]# awk -F ":" '{if ($3 > 1000 && $3 < 2000)print $0}' /etc/passwd
cc:x:1001:1001::/home/cc:/bin/bash
dd:x:1002:1002::/home/dd:/bin/bash
1dd:x:1003:1003::/home/1dd:/bin/bash
dd1:x:1004:1004::/home/dd1:/bin/bash
###
[root@localhost ~]# cat kpi.txt
user1 70 72 74 76 74 72
user2 80 82 84 82 80 78
user3 60 61 62 63 64 65
user4 90 89 88 87 86 85
user5 45 60 63 62 61 50
第二列大于等于80就打印出user
[root@localhost ~]# awk '{if($2>=80)print $1}' kpi.txt
user2
user4
#如果if后面跟着多个语句,则可以使用大括号括起来
[root@localhost ~]# awk '{if($2>=80) {print $1;print $2}}' kpi.txt
user2
80
user4
90
# awk也支持else
[root@localhost ~]# awk '{if($2>=80)print $1;else print $1,$2}' kpi.txt
user1 70
user2
user3 60
user4
user5 45
if else
awk 也支持if语句不成立,则执行其他语句
[root@localhost ~]# cat data
10
20
30
40
50
[root@localhost ~]# awk '{if($1>30) print $1*2;else print $1/2}' data
5
10
15
80
100
[root@localhost ~]# awk -F ":" '{if($3==0) {count++} else{i++}} END{print "管理员个数:" count;print "系统用户 数:" i}' /etc/passwd
管理员个数:1
系统用户数:25
总结:
{ if() {}} else if(){} else if(){} else() {}
while语句
while循环会遍历数据,且检查结束条件
语法:
while(条件)
{
语句
}
案例:
求每行相加后的平均值;也就是相加三个列的值,$1,$2,$3,再求平均值
[root@localhost ~]# cat data1
130 120 135
160 113 140
145 170 215
[root@localhost ~]# awk '{sum=0;i=1;while(i<4){sum+=$i;i++} avg=sum/3;print "Average:",avg}' data1
Average: 128.333
Average: 137.667
Average: 176.667
# 解读:awk默认每次处理一行,i表示字段数,所以i=1的时候,sum=sum+$i,i++累计,循环至i<4,再/3
do循环
do{
awk 语句1
}while(表达式)
wak在do{}中,无论表达式是否成立,至少执行一次语句,,如果不成立,直接结束,如果成立再执行while循环,
例如:
[root@localhost ~]# awk 'BEGIN{total=0;i=0; do{total+=i;i++;} while(i<=100)print total;}'
5050
for循环
for循环有两种格式
格式1:
for(变量 in 数组)
{awk语句}
格式2:
for(初始值;循环判断条件;累加)
awk语句1
案例:
[root@localhost ~]# cat data1
130 120 135
160 113 140
145 170 215
相加每行三个字段的值,求平均值
[root@localhost ~]# awk '{total=0;for(i=1;i<4;i++) {total+=$i} avg=total/3;print "Average:",avg}' data1
Average: 128.333
Average: 137.667
Average: 176.667
案例2:求api中的总成绩和平均成绩
[root@localhost ~]# cat kpi.txt
user1 70 72 74 76 74 72
user2 80 82 84 82 80 78
user3 60 61 62 63 64 65
user4 90 89 88 87 86 85
user5 45 60 63 62 61 50
过程:
使用awk求每一行的累加值再求平均值;先求出一行,再求全部
[root@localhost ~]# head -1 kpi.txt
user1 70 72 74 76 74 72
[root@localhost ~]# head -1 kpi.txt |awk '{for(c=2;c<=7;c++) {print $c}}'
70
72
74
76
74
72
[root@localhost ~]# head -1 kpi.txt |awk '{for(c=2;c<=7;c++) {sum+=$c} {print sum}}'
438
[root@localhost ~]# head -1 kpi.txt |awk '{for(c=2;c<=7;c++) sum+=$c;print sum/6}'
73
# 扩展脚本通用性
[root@localhost ~]# head -1 kpi.txt |awk '{for(c=2;c<=NF;c++) sum+=$c;print sum/(NF-1)}'
73
[root@localhost ~]# awk '{for(c=2;c<=NF;c++) sum+=$c;print sum/(NF-1)}' kpi.txt
73
154
216.5
304
360.833
# 发现除了第一次是平均值以为,其他都再原有基础上累计,因此需要在循环前设定一个初始值
[root@localhost ~]# awk '{sum=0;for(c=2;c<=NF;c++) sum+=$c;print sum/(NF-1)}' kpi.txt
73
81
62.5
87.5
56.8333
影响控制的其他语句
break 退出整个循环
continue 退出当前循环
next 读入下一个输入行,并返回到脚本的顶部,这可以避免对当前输入执行其他的操作过程
exit 如果END存在的话,使主输入循环退出并控制转移到END;如果没有定义END或在END中使用exit会终止脚本的执行
awk的数组功能
awk允许自定义变量在程序中使用,awk自定义的变量可以是任意数目的字母,数字,下划线,不得以数字开头,而且区分大小写。
数组:一种有某种关联的数据(变量),通过下标一次访问
数组名[下标]=值
下标可以使用数组也可以使用字符串
处理数组:
为了能够在单个变量中,存储多个值,许多编程语言都提供了数组,awk也支持关联数组功能,也就是可以理解为字典的作用。
例如:
"name":"cc"
"age":"18"
关联数组的索引可以是任意文本字符串,每一个字符串都可以对应一个数值
定义数组变量
var[index]=element
var是变量名字,index是索引,element是数组元素,是值
案例:
[root@localhost ~]# awk 'BEGIN{student["name"]="xiaoming";print student["name"]}'
xiaoming
关联数组的计算
[root@localhost ~]# awk 'BEGIN{num[1]=6;num[2]=7;sum=num[1]+num[2];print sum}'
13
for(变量 in 数组名)
使用数组名[变量]的方式依次对每个数组的元素进行操作
关联数组的问题是必须要知道索引是什么,否则无法取值
可以利用for循环遍历出所有的索引
案例:
[root@localhost ~]# awk 'BEGIN{
var["a"]=1
var["b"]=2
var["d"]=3
var["h"]=4
for (s in var)
{print "Index: ",s,"- Value: ",var[s]}}'
Index: h - Value: 4
Index: a - Value: 1
Index: b - Value: 2
Index: d - Value: 3
注意:索引值的返回是没有顺序的,但是对应的值是唯一的。
delete 数组[下标]
一但删除了索引,就无法用它提取元素了
ARGV
ARGC
案例: kpi.txt
取出所有人的kpi的平均值
[root@localhost ~]# awk '{ sum=0;for(column=2;column<=NF;column++) sum+=$column;avg[$1]=sum/(NF-1)}END{for(user in avg) print user,avg[user]}' kpi.txt
user1 73
user2 81
user3 62.5
user4 87.5
user5 56.8333
[root@localhost ~]# awk '{ sum=0;for(column=2;column<=NF;column++) sum+=$column;avg[$1]=sum/(NF-1)}END{for(user in avg) sum2+=avg[user];print sum2}' kpi.txt
360.833
[root@localhost ~]# awk '{ sum=0;for(column=2;column<=NF;column++) sum+=$column;avg[$1]=sum/(NF-1)}END{for(user in avg) sum2+=avg[user];print sum2/NR}' kpi.txt
72.1667
#解读:
sum=0,每次循环前初始化sum,
for(c=2;c<=NF;c++),for循环,c=2初始值,c<=NF,循环条件,c++累加
sum+=$c,等于sum=sum+$c,每循环一次sum的值累加一次
把avg[$1]=sum/(NF-1)的每个值定义成一个数组
END模式,user变量的值在avg数组遍历循环
sum2+=avg[user]就每个user的平均取值累计
sum2/NR 求出它的平均值
awk脚本模式
ARGV和ARGC
[root@localhost ~]# cat arg.awk
BEGIN{
for(x=0;x<ARGC;x++)
print ARGV[x]
print ARGC
}
[root@localhost ~]# awk -f arg.awk 11 22 33
awk
11
22
33
4
(一)脚本编写
#!/bin/awk -f
以下是awk引号里面的命令清单,不要使用引号保护命令,多个命令用分号间隔
BEGIN{FS=":"}
NR==1,NR==3{print $1"\t"$NF}
...
(二)脚本执行
方法1:awk 选项 -f awk的脚本文件,要处理的文本文件
awk -f awk awk.sh filename
对比:
sed -f sed.sh -i filename
方法2:
./awk的脚本文件(或者绝对路径) 要处理的文本文件
./awk.sh filename
对比:
./sed.sh filename
ENVIRON变量
环境变量关联数组。该变量用关联数组提前shell环境变量,注意点:关联数组使用 文本字符串 作为数组的索引,而不是数值。
在计算机科学中,关联数组 又称映射,字典,是应该抽象的数据结构,它包含这类似于(键,值)的有序对。一个关联数组中的有序对可以重复,也可以不重复。
数组索引中的key是shell的环境变量名,值是shell 环境变量的值。
[root@localhost ~]# awk 'BEGIN{print ENVIRON["HOME"],ENVIRON["PATH"]}'
/root /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
umn=2;column<=NF;column++) sum+=$column;avg[$1]=sum/(NF-1)}END{for(user in avg) sum2+=avg[user];print sum2/NR}’ kpi.txt
72.1667
#解读:
sum=0,每次循环前初始化sum,
for(c=2;c<=NF;c++),for循环,c=2初始值,c<=NF,循环条件,c++累加
sum+=
c
,
等
于
s
u
m
=
s
u
m
+
c,等于sum=sum+
c,等于sum=sum+c,每循环一次sum的值累加一次
把avg[$1]=sum/(NF-1)的每个值定义成一个数组
END模式,user变量的值在avg数组遍历循环
sum2+=avg[user]就每个user的平均取值累计
sum2/NR 求出它的平均值
#### awk脚本模式
ARGV和ARGC
[root@localhost ~]# cat arg.awk
BEGIN{
for(x=0;x<ARGC;x++)
print ARGV[x]
print ARGC
}
[root@localhost ~]# awk -f arg.awk 11 22 33
awk
11
22
33
4
(一)脚本编写
#!/bin/awk -f
以下是awk引号里面的命令清单,不要使用引号保护命令,多个命令用分号间隔
BEGIN{FS=":"}
NR1,NR3{print KaTeX parse error: Undefined control sequence: \t at position 3: 1"\̲t̲"NF}
…
(二)脚本执行
方法1:awk 选项 -f awk的脚本文件,要处理的文本文件
awk -f awk awk.sh filename
对比:
sed -f sed.sh -i filename
方法2:
./awk的脚本文件(或者绝对路径) 要处理的文本文件
./awk.sh filename
对比:
./sed.sh filename
#### ENVIRON变量
环境变量关联数组。该变量用关联数组提前shell环境变量,注意点:关联数组使用 **文本字符串** 作为数组的索引,而不是数值。
在计算机科学中,关联数组 又称映射,字典,是应该抽象的数据结构,它包含这类似于(键,值)的有序对。一个关联数组中的有序对可以重复,也可以不重复。
数组索引中的key是shell的环境变量名,值是shell 环境变量的值。
[root@localhost ~]# awk ‘BEGIN{print ENVIRON[“HOME”],ENVIRON[“PATH”]}’
/root /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin