前言
众所周知,机器学习分类模型常用评价指标有Accuracy, Precision, Recall和F1-score,而回归模型最常用指标有MAE和RMSE。但是我们真正了解这些评价指标的意义吗?
在具体场景(如不均衡多分类)中到底应该以哪种指标为主要参考呢?多分类模型和二分类模型的评价指标有啥区别?多分类问题中,为什么Accuracy = micro precision = micro recall = micro F1-score? 什么时候用macro, weighted, micro precision/ recall/ F1-score?
二分类模型常见指标
- 准确度(accuracy):
accuracy= T P + T N T P + F P + T N + F N \frac{TP+TN}{TP+FP+TN+FN} TP+FP+TN+FNTP+TN
准确度是指分类正确的预测数与总预测数的比值,准确度越高,分类器越好。
但是准确度并不是一个好指标,因为一旦数据严重不均衡时,accuracy不起作用。比如我们看X光片,真实数据是:99%都是无病的,只有1%是有病的,假设一个分类器只要给它一张X光片,它就判定是无病的,那么它的准确率也有99%,显然这个指标意义不大。当数据异常不平衡时,Accuracy评估方法的缺陷尤为显著。
- 混淆矩阵
二分类问题中,样本共两种类别:Positive和Negative。当分类器预测结束,我们可以绘制出混淆矩阵(confusion matrix)。其中分类结果分为如下几种:
|
Actual Positive |
Actual Negative |
| Predicted Positive |
TP |
FP |
| Predicted Negative |
FN |
TN |
- True Positive (TP): 把正样本成功预测为正。
- True Negative (TN):把负样本成功预测为负。
- False Positive (FP):把负样本错误地预测为正。
- False Negative (FN):把正样本错误的预测为负。
在二分类模型中,Accuracy(准确率)、Precision(精确率)、Recall(召回率)和F1 score的定义如下:
Accuracy= T P + T N T P + F P + T N + F N \frac{TP+TN}{TP+FP+TN+FN} TP+FP+TN+FNTP+TN
Precision= T P T P + F P \frac{TP}{TP+FP} TP+FPTP
Recall= T P T P + F N \frac{TP}{TP+FN} TP+FNTP
F1-score= 2 ∗ P r e c i s i o n ∗ R e c a l l P r e c i s i o n + R e c a l l \frac{2*Precision*Recall}{Precision+Recall} Precision+Recall2∗Precision∗Recall
其中,Precision着重评估在预测为Positive的所有数据中,真实Positive的数据到底占多少?Recall着重评估在所有的真实Positive数据中,到底有多少数据被成功预测为Positive?
举个例子,一个医院新开发了一套癌症AI诊断系统,想评估其性能好坏。我们把病人得了癌症定义为Positive,没得癌症定义为Negative。那么, 到底该用什么指标进行评估呢?
如果用Precision对系统进行评估,那么其回答的问题就是:
在诊断为癌症的一堆人中,到底有多少人真得了癌症?
如果用Recall对系统进行评估,那么其回答的问题就是:
在一堆得了癌症的病人中,到底有多少人能被成功检测出癌症?
如用Accuracy对系统进行评估,那么其回答的问题就是:
在一堆癌症病人和正常人中,有多少人被系统给出了正确诊断结果(患癌或没患癌)?
精准率和召回率之间是互相矛盾的,如果提高召回率,精准率就不可避免的下降,如果精准率提高,召回率就不可避免的下降。那什么时候注重Precision还是Recall?
在稳定TP的情况下,主要是更关注FP和FN的哪一个。以垃圾邮件屏蔽系统为例,垃圾邮件为Positive,正常邮件为Negative,False Positive是把正常邮件识别为垃圾邮件,这种情况是最应该避免的(你能容忍一封重要工作邮件直接进了垃圾箱,被不知不觉删除吗?)。我们宁可把垃圾邮件标记为正常邮件 (FN),也不能让正常邮件直接进垃圾箱 (FP)。在这里,垃圾邮件屏蔽系统的目标是:尽可能提高Precision值,哪怕牺牲一部分Recall。
F1 score是Precision和Recall两者的综合(调和平均数),主要用途来比较两个分类器的性能,取值范围为0到1,数值越大越好;
多分类模型常见指标
在多分类(大于两个类)问题中,假设我们要开发一个动物识别系统,来区分输入图片是猫,狗还是猪。给定分类器一堆动物图片,产生了如下结果混淆矩阵。
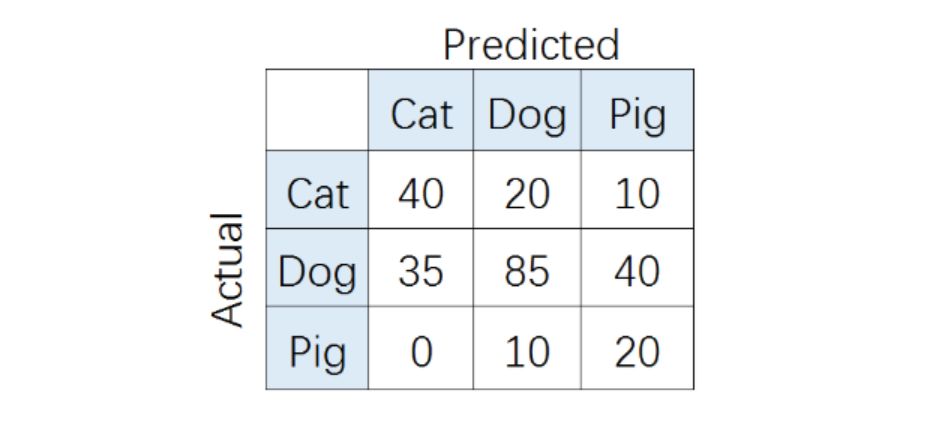
在混淆矩阵中,正确的分类样本(Actual label = Predicted label)分布在左上到右下的上对角线上。其中,Accuracy的定义为分类正确(对角线上)的样本数与总样本数的比值。Accuracy度量的是全局样本预测情况。而对于Precision和Recall而言,每个类都需要单独计算其Precision和Recall。

比如,对类别「猪」而言,其Precision和Recall分别为:
Precision= T P T P + F P \frac{TP}{TP+FP} TP+FPTP= 20 20 + 50 \frac{20}{20+50} 20+5020= 2 7 \frac{2}{7} 72
Recall= T P T P + F N \frac{TP}{TP+FN} TP+FNTP= 20 20 + 10 \frac{20}{20+10}