标准化/归一化(神经网络中主要用在激活之前,卷积之后)(持续补充)
归一化在网络中的作用
1、去除量纲的干扰,防止数值过小的特征被淹没;
[年龄:20 ,身高:180,收入:10000],收入和年龄相差较大,训练网络的时候可能会将年龄这个特征淹没。
2、保证数据的有效性;
稳定网络训练时前向传播和反向传播过程的梯度,网络训练本质上训练的是参数,当数据差异过大(比如输入一个是1,另一个是100000),模型参数会不稳定,模型难以收敛。
数据在未进行归一化时,可能会有大部分处在激活函数的饱和区,这样会影响前向传播的激活值,同时也会影响反向传播的梯度。当进行归一化后,如下图,归一化后的数值能够很好的映射到激活函数上。

画图代码
import math
import matplotlib.pyplot as plt
import numpy as np
m = 0 # 均值
n = 1 # 标准差
x = np.linspace(-5,5)
y = np.exp(-(x-m)**2/(2*n**2))/(math.sqrt(2*math.pi)*n)
x_sigmoid = np.linspace(-10,10)
y_sigmoid = 1/(1+np.exp(-x_sigmoid))
plt.plot(x,y,label='standard normal distribution')
plt.plot(x,y_sigmoid,label='sigmoid')
plt.legend()
plt.grid()
plt.show()
3、稳定数据的分布。
当深层网络中数据分布若在某一层开始有明显的偏移,会使得接下来这一问题加剧。
1、线性归一化(进行线性拉伸,可以增加对比度)
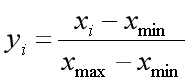
2、零均值归一化((像素值-均值)/方差)
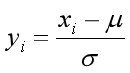
经过处理的数据符合标准正态分布。
3、Batch Normalization(批标准化方法)
这里给一个链接Batch Normalization 学习笔记,讲的很清楚,这里我先暂且空下,后续补充。
Batch Normalization的好处(提高训练速度,稳定模型训练):
这里给一个链接Batch Normalization 学习笔记,讲的比较清楚,但具体代码中处理的过程不太详细下面给出我的理解(图片制作不易,如需原图请私信联系):

1、减轻了对参数初始化的依赖,前向激活值和反向梯度更加有效;
2、平滑了优化目标函数曲面,梯度更加稳定,可以使用更高的学习率,从而跳出局部极值,增强了泛化能力。
Batch Normalization的缺点及改进
缺点:
1、要求固定的Batch长度和均匀采样;
2、当batch过小时计算不稳定。
改进:
采用Batch Renormalization(后续遇到进行补充)。先使用Batch Normalization训练网络到一个相对稳定的状态,稳定后采用Batch Renormalization。
4、其它归一化方法
| 方法(特点) |
归一化范围 |
| Batch Normalization(通用) |
N*H*W |
| Layer Normalization(适合非特定长输入) |
C*H*W |
| Group Normalization (适合小的batch输入) |
G*H*W |
| Instance Normalization (适合图像生成以及风格迁移类应用) |
H*W |