L1,L2以及Smooth L1是深度学习中常见的3种损失函数,这3个损失函数有各自的优缺点和适用场景。
首先给出各个损失函数的数学定义,假设
x
x
x 为预测值与Ground Truth之间的差值:
-
L1 loss表示预测值和真实值之差的绝对值;也被称为最小绝对值偏差(LAD),绝对值损失函数(LAE)。总的说来,它是把目标值
y
i
y_i
yi 与估计值
f
(
x
i
)
f(x_i)
f(xi) 的绝对差值的总和最小化。
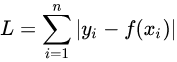
-
L2 loss表示与测值和真实值之差的平方;L2范数损失函数,也被称为最小平方误差(LSE)。它是把目标值
y
i
y_i
yi 与估计值
f
(
x
i
)
f(x_i)
f(xi) 的差值的平方和最小化。一般回归问题会使用此损失,离群点对次损失影响较大。

-
SmoothL1与L1类似,但在预测值与真实值差异非常小时,调整为
0.5
x
2
0.5x^2
0.5x2
但是,L1和L2有各自的缺点不足,而SmoothL1综合了二者的优点:
- L2损失函数相比于L1损失函数的鲁棒性更好。因为L2范数将误差平方化(如果误差大于1,则误差会放大很多),模型的误差会比L1范数大的多,因此模型会对这种类型的样本更加敏感,这就需要调整模型来最小化误差。但是很大可能这种类型的样本是一个异常值,模型就需要调整以适应这种异常值,那么就导致训练模型的方向偏离目标了。
- L2对离群点非常敏感,会出现与真实值差异较大的预测值主导loss的情况,最终造成梯度爆炸;
- L1对离群点相对鲁棒 ,但其导数为常数,且在0处不可导;这会导致训练后期预测值与真实值差异很小时,L1难以继续收敛;
- SmoothL1结合了L2和L1的优点,对噪声鲁棒,在0处可导可以收敛到更高的精度;
从3个损失函数各自的导数也能看出其特征:
- 对于L2损失函数,其导数与
x
x
x成正比;这就导致训练初期,预测值与真实值差异过大时,损失函数的梯度非常大,梯度爆炸导致训练不稳定;
- 对于L1损失函数,其导数为常数;这就导致训练后期,预测值与真是差异很小时,损失函数的导数绝对值仍然为1,而如果learning rate不变,损失函数将在稳定值附近波动,难以继续收敛达到更高精度;
- 对于SmoothL1损失函数,在
x
x
x较小时对梯度会变小,而在
x
x
x很大时其梯度的绝对值达到上限1,梯度不会爆炸。可以说,SmoothL1避开了L1和L2损失的缺陷,因此SmoothL1用的也比较广泛。
最后,3种损失函数的图像如下:
什么是正则化
在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况。正则化是机器学习中通过显式的控制模型复杂度来避免模型过拟合、确保泛化能力的一种有效方式。如果将模型原始的假设空间比作“天空”,那么天空飞翔的“鸟”就是模型可能收敛到的一个个最优解。在施加了模型正则化后,就好比将原假设空间(“天空”)缩小到一定的空间范围(“笼子”),这样一来,可能得到的最优解能搜索的假设空间也变得相对有限。有限空间自然对应复杂度不太高的模型,也自然对应了有限的模型表达能力。这就是“正则化有效防止模型过拟合的”一种直观解析。

L2正则化
在深度学习中,用的比较多的正则化技术是L2正则化,其形式是在原先的损失函数后边再加多一项:
1
/
2
λ
θ
i
2
1/2λθ^2_i
1/2λθi2 ,那加上L2正则项的损失函数就可以表示为:
L
(
θ
)
=
L
(
θ
)
+
λ
∑
i
n
θ
i
2
L(θ)=L(θ)+λ∑^n_i θ^2_i
L(θ)=L(θ)+λ∑inθi2,其中θ就是网络层的待学习的参数,λ则控制正则项的大小,较大的取值将较大程度约束模型复杂度,反之亦然。
L2约束通常对稀疏的有尖峰的权重向量施加大的惩罚,而偏好于均匀的参数。这样的效果是鼓励神经单元利用上层的所有输入,而不是部分输入。所以L2正则项加入之后,权重的绝对值大小就会整体倾向于减少,尤其不会出现特别大的值(比如噪声),即网络偏向于学习比较小的权重。所以L2正则化在深度学习中还有个名字叫做“权重衰减”(weight decay),也有一种理解这种衰减是对权值的一种惩罚,所以有些书里把L2正则化的这一项叫做惩罚项(penalty)。
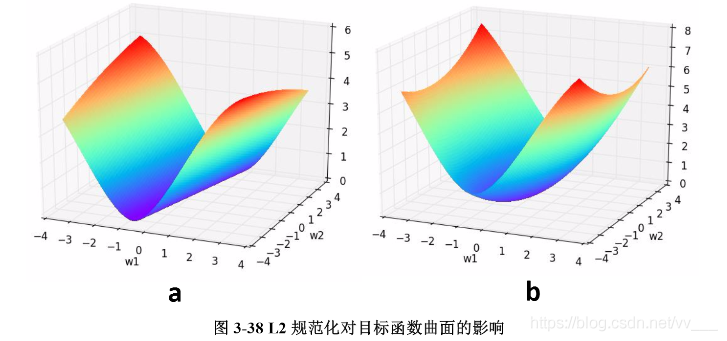
我们通过一个例子形象理解一下L2正则化的作用,考虑一个只有两个参数
w
1
w_1
w1和
w
2
w_2
w2的模型,其损失函数曲面如下图所示。从a可以看出,最小值所在是一条线,整个曲面看起来就像是一个山脊。那么这样的山脊曲面就会对应无数个参数组合,单纯使用梯度下降法难以得到确定解。但是这样的目标函数若加上一项
0.1
×
(
w
1
2
+
w
2
2
)
0.1×(w^2_1+w^2_2)
0.1×(w12+w22),则曲面就会变成b图的曲面,最小值所在的位置就会从一条山岭变成一个山谷了,此时我们搜索该目标函数的最小值就比先前容易了,所以L2正则化在机器学习中也叫做“岭回归”(ridge regression)。
参考文献