什么是交叉验证?
交叉验证是一种模型验证技术,可用于评估统计分析(模型)结果在其它独立数据集上的泛化能力。它主要用于预测,我们可以用它来评估预测模型在实践中的准确度。
交叉验证的目标是定义一个数据集,以便于在训练阶段(例如,验证数据集)中测试模型,从而限制模型过拟合、欠拟合等问题,并且帮助我们了解模型在其它独立数据集上的泛化能力。值得一提的是,验证集和训练集必须满足独立同分布条件,否则交叉验证只会让结果变得更加糟糕。
验证有助于我们评估模型的质量
验证有助于我们挑选出那些能够在预测数据集上取得最好性能的模型
验证有助于我们避免过拟合与欠拟合
什么是过拟合/欠拟合?
欠拟合指的是模型没能够从训练数据中学习到足够的模式。此时,模型在训练集和测试集上的表现都非常差。
过拟合则有两种情况:第一种,模型学习到过多的噪声;第二种,模型学习到的模式泛化能力差。此时,模型在训练集上表现很好,但是在测试集上表现则非常差(对于分类任务而言,可以看作是模型学习到了同类别的不同实例之间的区别,并把它们作为分类依据,所以面对新的实例时分类性能不佳)。
而最佳的模型应该能够在训练集和测试集上都表现得很好。
不同的验证策略
通常,依据数据集中分割方式的不同,会有不同的验证策略。
训练测试集划分/Holdout 验证 —— 组数为 2
在该策略中,我们简单地将数据集划分成两组:训练集和测试集,并且要求训练集和测试集之间的样本不存在任何重叠,如果存在重叠,那么验证手段将失效。在准备发布最终模型之前,我们可以在整个数据集上重新训练模型,而不需要更改任何超参数。
 但是这种划分方式存在一个主要的缺陷:
但是这种划分方式存在一个主要的缺陷:
如果我们的划分方式并不是随机的呢?比如,我们数据的某个子集只有来自于某个州的人,或者某个子集中只含有某一特定水平收入的员工,又或者子集中只含有女性或特定年龄的人,这时我们该怎么办?尽管我们一直在极力避免,但是这些情况都将导致模型的过拟合,因为此时无法确定哪些数据点会出现在验证集中,并且针对不同的数据集,模型的预测结果也可能完全不同。因此,只有当我们拥有充足的数据时,这种做法才是合适的。
k 分划分 —— 组数为k
由于永远不会有充足的数据来训练模型,因此如果将数据集中的某一部分划分出来用于验证还会导致模型出现欠拟合的问题。由于训练数据样本减少,我们的模型面临着丢失掌握重要模式/趋势机会的风险,从而增加偏差引起的误差。因此,我们需要一种方法,它既能够为训练模型提供充足的数据样本,又能够为验证步骤保留一定数量的数据。k 分(k-fold)交叉验证正是我们所需要的。
k 分交叉验证可以看做是执行了多次的简单二分划分验证,然后我们在执行了 k 次不同的简单划分验证之后继续简单地将得分进行平均。数据集中的每个数据点只能在验证集中出现一次,并且在训练集中出现 k-1 次。这种做法将大大减轻欠拟合现象,因为我们使用了几乎所有的数据来训练模型,同时还能显著减少过拟合现象,因为大部分数据也被用来做验证。
当我们的数据量较小时,或者在不同的划分数据集中,我们的模型性能或者最优参数存在较大的区别时,k 分交叉验证是一种很好的选择。通常情况下,我们设置 k=5 或 k=10,这些值来自于经验总结,大量实验证明当 k 取这些值时,验证结果不会存在过高的偏差或者方差。
留一法 —— 组数训练数据集大小
当 k 等于数据集中的样本数时,留一法(Leave one out)实际上可以看做 k 分交叉验证的一个特例。这意味着每次使用 k-1 个样本作为训练样本而剩下 1 个样本作为验证样本,然后照此遍历数据集。
如果我们的数据量非常小并且模型的训练速度非常快,那么可以考虑该方法。
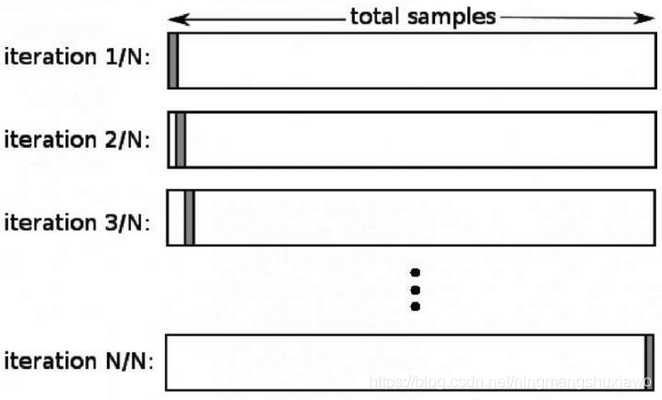
额外补充 —— 分层法(Stratification)
通常,在使用训练集/测试集划分或者是 k 分交叉验证的时候,我们会将数据集进行随机重排,以便于得到随机的训练/验证集划分。在这种情况下,可以将不同的目标分布应用于不同的划分区域中。通过分层法,当我们在分割数据时,我们可以在不同的划分区域中获得相似的目标分布。
该方法对以下情况有效:
小数据集
数据不平衡
多分类问题
通常而言,对于一个类别平衡的大型数据集,分层划分法和简单的随机划分基本一样。
什么时候使用?
如果我们有充足的数据,并且对于不同的划分方式,我们都能获得相近的成绩以及最优参数模型,那么训练集/测试集二分划分是一种不错的选择。而如果恰恰相反,也就是对于不同的划分方式,模型的测试成绩和最优参数都存在着较大的差异时,我们可以选择 k 分交叉验证。如果数据总量非常少,则可以考虑使用留一法。此外,分层法有助于使验证结果更加稳定,并且对于小型且类别不平衡的数据集尤其管用。
k 分交叉验证的 k 该取多少?
当 k 的取值越大时,由偏差导致的误差将减少,而由方差导致的误差将增加,此外计算的代价也将上升。显然,你需要更多的时间来计算,并且也会消耗更多的内存。
当 k 的取值越小时,由方差导致的误差将减少,而由偏差导致的误差将增加。此外,这时所需的计算资源也将减少。
针对大型数据集的时候,我们通常将 k 设置为 3 或者 5,但是对于小型数据集我们还是建议采用留一法。
交叉验证是一种通过估计模型的泛化误差,从而进行模型选择的方法。没有任何假定前提,具有应用的普遍性,操作简便, 是一种行之有效的模型选择方法。
人们发现用同一数据集,既进行训练,又进行模型误差估计,对误差估计的很不准确,这就是所说的模型误差估计的乐观性。为了克服这个问题,提出了交叉验证。基本思想是将数据分为两部分,一部分数据用来模型的训练,称为训练集;另外一部分用于测试模型的误差,称为验证集。由于两部分数据不同,估计得到的泛化误差更接近真实的模型表现。数据量足够的情况下,可以很好的估计真实的泛化误差。但是实际中,往往只有有限的数据可用,需要对数据进行重用,从而对数据进行多次切分,得到好的估计。
交叉验证方法
留一交叉验证(leave-one-out):每次从个数为N的样本集中,取出一个样本作为验证集,剩下的N-1个作为训练集,重复进行N次。最后平均N个结果作为泛化误差估计。
留P交叉验证(leave-P-out):与留一类似,但是每次留P个样本。每次从个数为N的样本集中,取出P个样本作为验证集,剩下的N-P个作为训练集,重复进行
次。最后平均N个结果作为泛化误差估计。
以上两种方法基于数据完全切分,重复次数多,计算量大。因此提出几种基于数据部分切分的方法减轻计算负担。
K折交叉验证:把数据分成K份,每次拿出一份作为验证集,剩下k-1份作为训练集,重复K次。最后平均K次的结果,作为误差评估的结果。与前两种方法对比,只需要计算k次,大大减小算法复杂度,被广泛应用。
模型选择方法的评价
衡量一个模型评估方法的好坏,往往从偏差和方差两方面进行。
Error = Bias^2 + Variance+Noise
Variance反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。反应预测的波动情况。
什么是Noise(噪声)
这就简单了,就不是你想要的真正数据,你可以想象为来破坏你实验的元凶和造成你可能过拟合的原因之一,至于为什么是过拟合的原因,因为模型过度追求Low Bias会导致训练过度,对测试集判断表现优秀,导致噪声点也被拟合进去了
总结
交叉验证是数据科学家评估模型有效性的一个非常有用的工具,特别是用于解决过拟合和欠拟合问题。此外,在确定模型最优超参数问题上,它也是非常有帮助的。
Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,即算法本身的拟合能力.
偏差和方差
在机器学习中,我们用训练数据集去训练(学习)一个model(模型),通常的做法是定义一个Loss function(误差函数),通过将这个Loss(或者叫error)的最小化过程,来提高模型的性能(performance)。然而我们学习一个模型的目的是为了解决实际的问题(或者说是训练数据集这个领域(field)中的一般化问题),单纯地将训练数据集的loss最小化,并不能保证在解决更一般的问题时模型仍然是最优,甚至不能保证模型是可用的。这个训练数据集的loss与一般化的数据集的loss之间的差异就叫做generalization error=bias+variance。
注:Bias和Variance是针对Generalization(一般化,泛化)来说的。
Bias是 “用所有可能的训练数据集训练出的所有模型的输出的平均值” 与 “真实模型”的输出值之间的差异;
Variance则是“不同的训练数据集训练出的模型”的输出值之间的差异。
参考
三分钟重新学习交叉验证