目录
1.ORM是什么
2.flask-sqlalchemy介绍及安装:
3.设计数据库模型并创建表
4.使用ORM插入,修改,删除数据
5.使用ORM查询数据并展示
1.ORM是什么:对象关系的映射
它的作用是在关系型数据库和对象之间作一个映射,这样,我们在具体的操作数据库的时候,就不需要再去和复杂的SQL语句打交道,只要像平时操作对象一样操作它就可以了 。
那什么是SQL:
SQL是存取数据以及查询、更新和管理关系数据库系统。
2.flask-sqlalchemy介绍及安装:
安装: pip install -U Flask-SQLALchemy
源码安装: python setup.py install
安装依赖: pip install mysqlclient
3.设计数据库模型并创建表
(1).flask-sqlalchemy配置:
数据库URI: SQLALCHEMY_DATABASE_URI
(数据库URI它是统一资源标识符是一个用于标识某一互联网资源名称的字符串)
MySQL数据库URI参数格式:
mysql://scott:tiger@localhost/mtdatatabase
mysql:数据库类型
scott:tiger@localhost:用户名/密码/ip
mtdatatabase:MySQL数据库名称
引入:
from flask-sqlalchemy import SQLAIchemy
(2).绑定到Flask对象:
db = SQLAIchemy(app)
(3).ORM模型创建:
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
primary_key=True 是主键的意思
(4).指定表的名称:
__tablename__ == 'haha_user'
(5).手动创建数据库:
创建表:db.create_all(bind='db1')
(6).删除表:
db.drop_all()
(7).ORM模型字段类型支持
| Integer/Float |
整数/浮点数 |
| String (size) |
有长度限制的字符串 |
| Text |
一些较长的文本(如:文章详情/商品详情) |
| DateTime |
表示为python datetime 对象的 时间和日期 |
| Boolean |
存储布尔值 |
| Pckle Type |
储存一个持久化的Python对象 |
| LargeBinary |
储存一个任意大的二进制数据 |
(8).数据库模型设计:
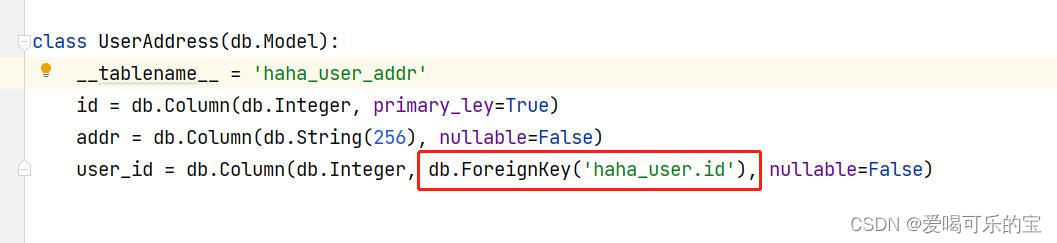
一对多关系,外键关联:
就好比一个客户他有很多个收货地址,客户与地址之间的关系就叫一对多的关系
addresses = db.relationship('UserAddress',backref=address',lazy=True)
user = db.relationship('User', backref=db.backref('address', lazt=True))
他不会在表格里面显示一行,就是为了反向引用方便。
想要关联哪个表的什么数据用db.Foreignkey('表的名称'.数据)
4.使用ORM插入,修改,删除数据
新增/修改数据
1.构造ORM模型对象
user = User('admin',admin@example.com)
2.添加到db.session(备注:可添多个对象)
db.session.add(user)
3.提交到数据库
db.session.commit()
物理删除数据:
查询ORM模型对象
user = User.query.filter_by(username='zhangsan').first()
添加到db.session
db.session.delete(user)
提交到数据库:
db.session.commit()
5.使用ORM查询数据并展示
返回结果(list)
查询所有的数据:User.query.all()
按条件查询: User.query_filter_by(username='zahngsan')
User.query.filter(User.nickname.endswith('三’).all()
排序: User.query.order_by(User.username)
查询TOP 10 User.query.limit(10).all()
返回单个ORM对象:
根据pk查询: User.query.get(1)
获取第一条记录: User.query.first()
多表关联查询: db.session.query(User).join(Address)
User.query.join(Address)
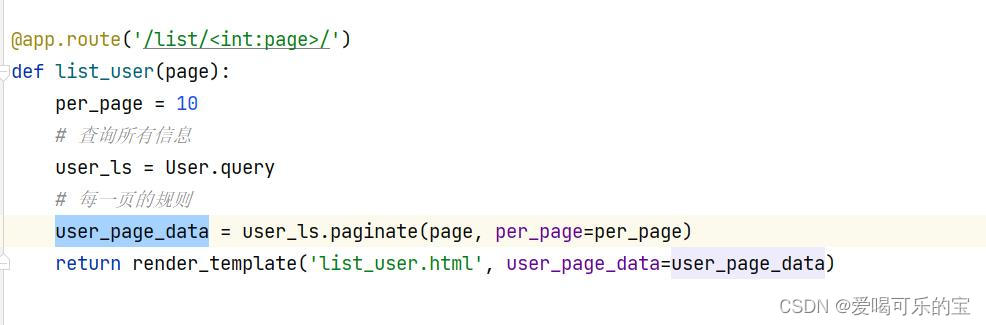
分页:
方式一:使用offset 和 limit
.offser(offset).limit(limit)
方式二: 使用paginate分页支持
.paginate(page=2,per_page=4) 返回Pagination的对象
查询用户信:User.query
| has_prev/has_next |
是否有上一页/下一页 |
| item |
当前页的数据列表 |
| prev_num/next_num |
上一页/下一页的页码 |
| total |
总记录数 |
| page |
当前页码 |
| pages |
总页数 |
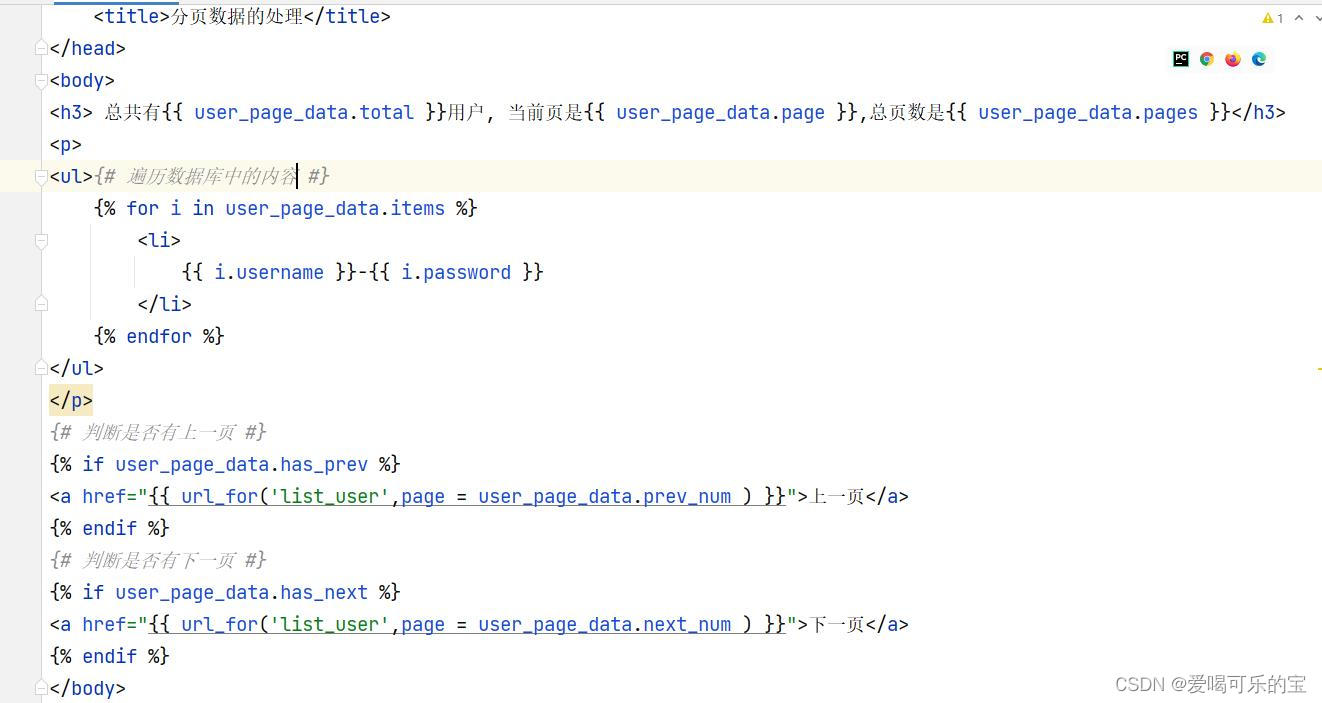
分页操作的实际应用: