HashMap是Java中很重要一个部分,内容较多,因此笔者在此将其拆成一个个小块,作为自己学习知识整理的同时,也和广大网友一起讨论。
也因此,在完成系列的学习之前,将以这种小节的形式进行学习分享,并在学习结束后进行整合,排序。
一、HashMap的实际结构
首先,我们必须了解一下HashMap的实际结构:
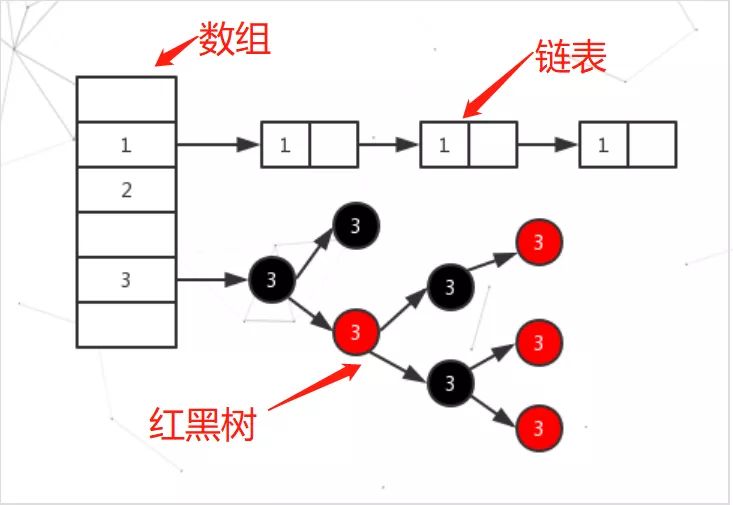
(图片来自:'是一篇很好的博客,如有时间,希望大家也能花时间在这篇博客中学习一二) https://blog.csdn.net/weixin_39621427/article/details/112096553 如上图所示,HashMap本质是一个数组,其中数组中的每个元素可以指向一套红黑树/一个链表(一定是两种之一)。
https://blog.csdn.net/weixin_39621427/article/details/112096553 如上图所示,HashMap本质是一个数组,其中数组中的每个元素可以指向一套红黑树/一个链表(一定是两种之一)。
在HashMap初始化中,存在一个参数:
树化阈值(TREEIFY_THRESHOLD):
当数组的节点数超过树化阈(yu,四声)值后 ,会被转化为红黑树的储存结构,可以加快遍历速度。
在源码中,树化阈值被默认设定为8,如下所示:
pubic static final int TREEIFY_THRESHOLD = 8
二、HashMap元素的添加
序
在正常的使用中,我们会这样进行HashMap的初始化和元素的添加:
Map<String,Integer> map = new HashMap<String, Integer>();
map.put("a",1);
其中,.put方法就是HashMap中添加元素的方法,那么让我们看看其源码是如何实现的吧。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
在源码中,我们很容易发现,put方法的实现都在putVal方法中,因此,我们对put方法的重点就在putVal方法中。
putVal方法
查询源码,我们可以看到putVal的源码如下,乍看起来内容较多,在笔者的学习过程中,网络上大部分的资料均是直接开始介绍整套代码的作用,对于初学者来说,需要认知的事情太多,学习起来困难,复习起来更是无从下手,因此,笔者在这里就以初学者的角度开始,转换一下学习的方法。
首先,大致看上去,putVal中包含多个if-else结构,因此,如果我们能将每个if的条件判断弄清楚,那么整个putVal的运行逻辑就一清二楚啦。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
1、方法的声明
从方法的头部往下看,首先,我们需要关注的是方法的声明。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict)
如图,我们发现putVal是存在返回值类型,有5个输入参数的函数,那么我们首先就需要对其中的5个输入参数进行分析。
我们知道,自己在调用put的时候,往往只提供了两个输入参数key与value,那么剩下的参数put是如何传递下去的呢?
在这里,我们就要看看put的源码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
如上,put是分别将:
- key的哈希值
- key
- value
- false
- true
传递下去的,因此,我们必须清楚除了key与value之外的其他三个值代表的意思。
1)参数1:hash(key)
在这里,我们发现这里调用了方法hash,详细内容笔者将会在其他博客中详细讲解,在这里,我们只需要知道hash是一种数据处理方法,而hash(key)就是将key通过处理之后得到的一个数即可。
同时,我们还需要记住,hash是一种处理方法,那么就会有以下的情况,也因此,我们在后面需要针对处理:
- 相同的key,经过处理后得到的hash(key)相同
- 不同的key,通过处理后得到的hash(key)可能相同
2)参数4:boolean onlyIfAbsent
表示只有当对应位置为空的时候替换元素。默认为false,即当对应位置不为空的时候,会将旧的value替换成新输入的value。
在jdk1.8中,新增了方法public V putIfAbsent(K key, V value)可以更改该参数。
3)参数5:boolean evict
默认为true,仅在初始化的时候,会传递为false。
2、If-else结构
0)序:
Node<K,V>[] tab; Node<K,V> p; int n, i;
我们发现,在putVal初始,便定义了诸多参数,虽然其初始化内容和赋值在文后,但我们在最开始对其的作用进行了解后,更能方便我们后面对其进行理解。
- Node<K,V>[] tab : 对应整个HashMap数组
- Node<K,V> p : 对应数组的下标(数组尾的下标)
- int n : 对应HashMap数组的长度
- int i : 对应数组的遍历参数
1)第一个If
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
在第一个if中,tab被赋值为HashMap数组。
其中,判断tab是否为空(HashMap数组是否为空)
或者 数组长度是否为零
如果是,则进行数组的初始化(通过调用resize()方法实现),默认长度为16。(会在其余博客中讲解)。
2)第二个if(无hash冲突)
在第二个if中,出现了if-else结构,是整个方法中占比最大的部分。
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
如果当前的数组尾部为空(==null),则将当前输入的参数存入。
3)第二个if对应的else(hash冲突)
在该代码块中,出现了两个新的参数,同样,也在此进行介绍,以方便后文的理解。
Node<K,V> e; K k;
- Node<K,V> e :用于记录该节点中是否存在与新元素key相同的标识,如e为Null则不存在。 (如存在则e不会指向 Null,而是指向key相同的元素的位置。)
- K k :用于存储key值
如前文所述,if对应的是数组尾部为空,那么此处对应的就是数组尾部不为空(位置已存在其他元素)。那么这里,如上文中对于hash(key)的介绍,这里会出现两种情况分别对应内容中的第三个if-else结构:
- 相同的key导致发生冲突
- 不同的key的hash值相同,发生冲突
3-1)第三个if(新元素与节点的key值相同)
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
如上所示,判断内容为:
判断:当前数组尾的元素的key和输入参数的key是否相同
e:指向当前节点的位置
如判断相同,则用e来储存当前元素的信息,并最终将当前位置元素的Value值用新输入的Value替代。
替换代码在3-1)的下方,文中稍后讲解。
3-2)else if(节点的key值不相同,且p为treeNode)
此处判断当前元素p是否为TreeNode,若是,则将红黑树直接插入键值对。
3-3)else(节点的key值不相同,且p不为treeNode)
for循环->开始遍历该节点,以binCount作为计数器,用于计算当前节点的元素数量。
注意:此处for循环中,e的数值在一直更新。
3-3-1)for中的第一个if
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
遍历:直至节点的末尾(节点元素的.next指向null),如直至末尾仍然无与新元素相同的key值,则将新元素存储在该节点的末尾。
其中的if:判断节点元素的数量是否超过树化阈值(详见本文第一节内容,默认为8),如超过阈值,则将目前的链表模式转换为红黑树模式。
e:最终为null。
3-3-2)for中的第二个if
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
看上去十分熟悉是吗,其实是与3-1中的判断语句一致。
判断:遍历当前节点元素的时候,存在与新元素相同的key,则最终实行Value的更新操作。
e:最终不为null,指向与新元素的key相同的元素位置。
3-4)第四个if
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
第四个if是执行语句,如前文中存在与新元素相同的key值,则其对应的Value更新为新元素的Value。
在执行这种Value的更新的时候,会直接return退出函数,不会对HashMap的大小(参数size)进行增加。
3-5)第五个if-最后的if
if (++size > threshold)
resize();
当不为Value值的更新的时候,即为新元素的插入。
此时,将HashMap的大小增加1,同时
判断:增加后的size是否超过扩容阈值,如超过,则进行扩容操作(会在其他博客中讲解)。
至此,结束整个Put的分块式讲解,在这里,笔者将所有的判断整理成框图,相信大家在分块理解后,能很好地理解整个框图的逻辑啦。
