半监督学习
transductive learning:unlabeled data is the testing data
inductive learning:unlabeled data is not the testing data
一、生成方法:self-training
- 将初始的有标签数据集作为初始的训练集
(X_train, y_train)=(X_l, y_l)
根据训练集训练得到一个初始分类器C_int。
- 利用C_int对无标签数据集X_u中的样本进行分类,选出最有把握的样本(X_conf, y_conf) (可以使用SVM方法和逻辑回归方法同时yu)
这里可以使用K近邻算法
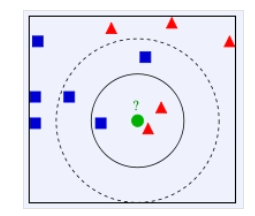
- 如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
- 如果K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
-
从X_u中去掉(X_conf, y_conf)
-
将(X_conf, y_conf)加入到有标签数据集中
(X_train, y_train) ← (X_l, y_l) ∪ (X_conf, y_conf)
-
根据新的训练集训练新的分类器,重复步骤2到5直到满足停止条件(例如所有无标签样本都被标记完了或者该模型找不到“有把握”的预测结果)
最后得到的分类器就是最终的分类器。
二、graph-based method 基于图的半监督方法
在存储开销上,若样本数为O(m),则算法中所涉及的矩阵规模为O(m^2);算法很难处理大规模数据。
构图过程中仅能考虑训练样本集,难以判别新样本在图中的位置;在接收新样本时,将其加入原数据集对图进行重构并重新进行标记传播,或是需要引入额外的预测机制。
假设多有的样本点(包括已标记和未标记)以及之间的关系可以映射为一张图;数据集中的每个样本对应于图中的一个结点,若两个样本相似度很高,则对应的结点之间存在一条边,边的“强度”正比于样本之间的相似度;
将有标记样本对应的结点想象为染过色,未标记样本的结点未染色;
基于D_l和D_u构建一个图G=(V,E)
结点集V = {x1,…,x_l,x_l+1,…,x_l+u}
边集E表示为一个亲和矩阵;
基于图的算法使用图的拉普拉斯矩阵;图的节点之间的边的全职矩阵为W;W_ij表示两个结点之前边的权值;当两个结点无边时,w_ij = 0;边的权值有多种定义方式;定义为k近邻或者高斯核矩阵的形式。
k 近邻定义:如果结点x_i是结点x_j 的 k 个最邻近结点中的一个,那么w_ij = 1,否则w_ij = 0;

第二项迫使学得结果在有标记样本的预测与真实的标记尽可能相同;第一项迫使相近样本具有相似的标记(离散的类别标记);
三、co-training协同训练(基于分歧的方法)
需要生成具有显著分歧、性能尚可的多个学习器;当数据不具备多视图时,不容易设计
将每个数据从不同的角度进行分类;不同的角度可以训练出不同的分类器;
- 初始化数据,将有标签数据L分为两个集合L1(包括k个属性)和L2(包括m个属性);
- 分别用L1和L2训练出一个模型分类器F1和F2
- 分别用模型F1和F2去预测,选出最有把握的一些结果;
- 把F1预测的结果放入L2,把F2预测的结果放入L1(交叉放置)
- 更新L和U
- 反复迭代k次,得到两个最终的分类器C1,C2