文章参考:
Abnormal Event Detection in Videos
using Spatiotemporal Autoencoder
Learning Temporal Regularity in Video Sequences
数据集1&数据集2
本文主要内容
阅读相关论文的方法
部分的代码实现
第一篇
马来西亚拉曼大学的研究者发表的,主要内容为:
- 提出了一种基于时域的网络架构,实现异常检测。
- 网络结构主要包括两部分:
主要贡献的部分
- 提出了autoencoder去学习数据中的特征
- 用autoencoder的特征实现网络结构的学习
实现方法
最基础的原则:异常视频的最近帧数会和前面的帧数有较大差别
构建的是点对点端到端的模型,包括空间特征提取和一个时域编解码器,训练时只用正常的视频进行训练,最后通过一个重建阈值进行正常/异常视频的分割
主要操作分为以下三步
预处理
- 视频的图片 resize 到 227x227大小
- 像素归一化0~1
- 每个提取的图像减去全局平均图像(全局平均图是数据集中的所有图的平均)
- 接着归一化到0均值和一个方差值
- 输入到模型的图像是视频的10个连续的图像帧,步长是可变化的:
- 可能步长有1, 2, 3,即123,135,147这样采用视频帧作为输入
特征提取
论文中提取的方法 :
分为了两部分,一部分是空间域的自动编码,另一部分是时域的编解码,用于学习时域信息。
spatial autoencoder 网络结构:
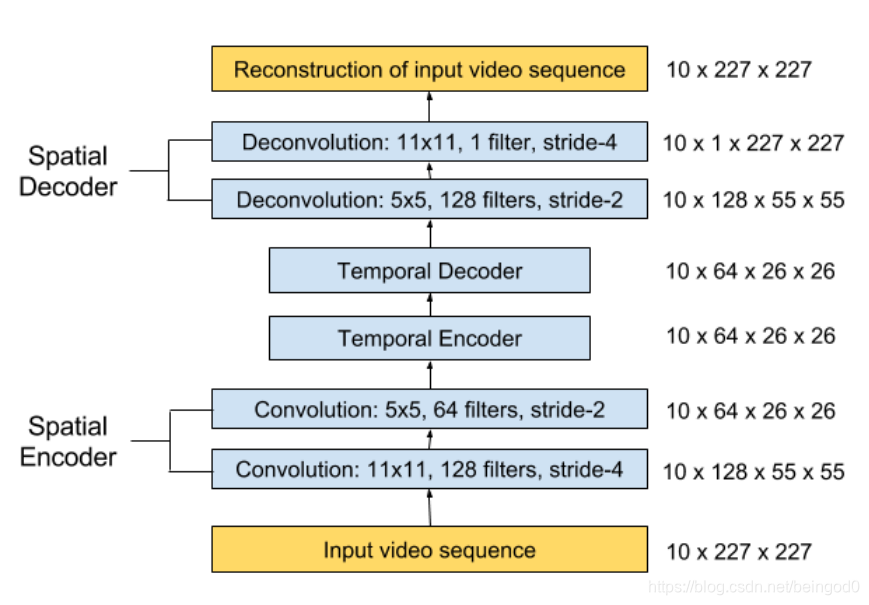
temporal encoder-decoder model模型:
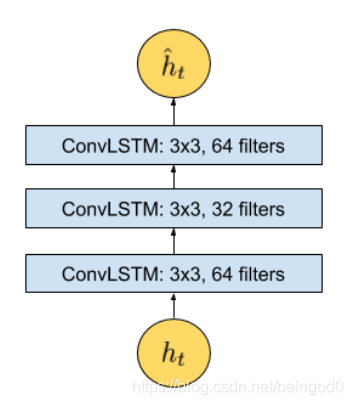
这一部分包含三层LSTM卷积层
RNN
接下来简单说明了下RNN,RNN理论上可以学习到一个很长时间序列的信息,但实际上由于梯度消失的原因,RNN很难学到前很多帧的信息。
RNN常见的类似下面的原理
h1=f(Ux1+Wh0+b)
y1=softmax(Vh1+c)
f为激活函数,h0 为0时刻的隐藏层,x1为输入,U,W,b,V,c为模型的参数,y1为输出
由公式可以看出,RNN每一层都有前一层的ht参与,会出现梯度连乘的情况,导致梯度爆炸或梯度消失。
LSTM
LSTM通过一个遗忘门,避免了RNN中会出现的梯度爆炸或消失的情况。
下图是实现LSTM的基本结构网络,还有一个公式说明的方式,这部分需要去细细的品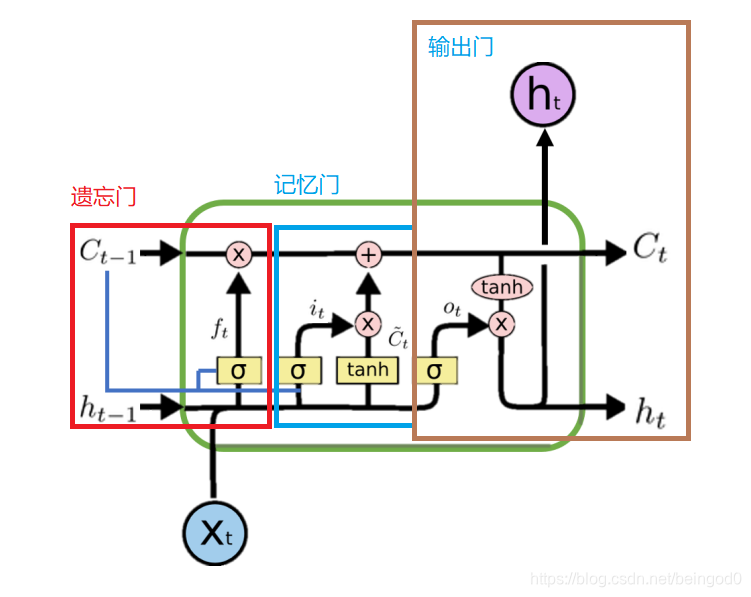
遗忘门为上图中的ft相关部分,δ为sigmiod函数,ft=sigmoid(Wf[ht-1,xt]+bf),这里经过了ft后,得到一个0~1的矩阵,决定对上一时刻的信息哪些部分进行遗忘操作。
记忆门:
对应下面的公式(2)和(3),这样就有了公式(4),实现了LSTM中主要的 “长Long memory” 主干路
输出门:
这里得到的是隐状态ht,实际上进一步的输出需要对ht做进一步处理。
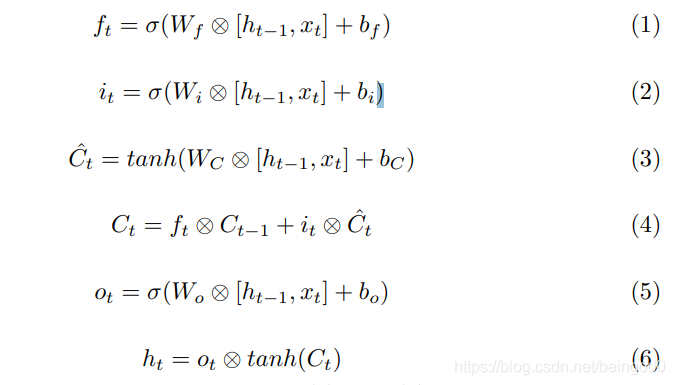
而作者正式在上述的基础上,实现了ConvLSTM的,他将上述的输入改为了图像输入,并将卷积替换了部分的⊗
正则化分值
使用了欧氏距离计算输入帧和reconstructed frame之间的距离
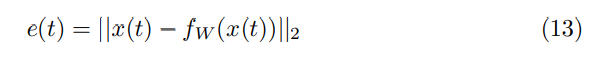
Fw是学习好的权重模型
将上述距离归一化,可以得到Sa(t),得分的情况可以通过计算Sr(t)来获得
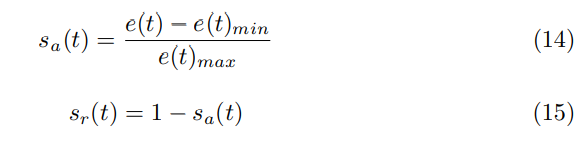
异常检测
异常检测可以分两种模式,一种是通过设定阈值来实现,当分值低于阈值时开始报警。阈值可以通过ROC曲线来查找
另一种方法是通过计数来实现划分,需要有足够计数帧数,才能认定这连续的异常帧是有意义的异常段视频
源码
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
import tensorflow.keras.backend as K
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.layers import ConvLSTM2D, Conv2D, TimeDistributed, BatchNormalization, Conv2DTranspose, LayerNormalization
from os import listdir
from os.path import isfile, join, isdir
from PIL import Image
import numpy as np
def get_clips_by_stride(stride, frames_list, sequence_size):
""" For data augmenting purposes.
Parameters
----------
stride : int
The desired distance between two consecutive frames
frames_list : list
A list of sorted frames of shape 256 X 256
sequence_size: int
The size of the desired LSTM sequence
Returns
-------
list
A list of clips , 10 frames each
"""
# 一个分割器,提取需要的数据,通过frame list支持
# 这里输入步长和长度可以设置,当设定了 sequence_size为10时 返回的clips每一个长度为10
clips = []
sz = len(frames_list)
clip = np.zeros(shape=(sequence_size, 256, 256, 1))
cnt = 0
for start in range(0, stride):
for i in range(start, sz, stride):
clip[cnt, :, :, 0] = frames_list[i]
cnt = cnt + 1
if cnt == sequence_size:
clips.append(clip)
cnt = 0
return clips
def get_training_set():
"""
Returns
-------
list
A list of training sequences of shape (NUMBER_OF_SEQUENCES,SINGLE_SEQUENCE_SIZE,FRAME_WIDTH,FRAME_HEIGHT,1)
"""
# 读取config中数据集的路径,然后提取所有数据准备训练
clips = []
# loop over the training folders (Train000,Train001,..)
for f in sorted(listdir(Config.DATASET_PATH)):
if isdir(join(Config.DATASET_PATH, f)):
all_frames = []
# loop over all the images in the folder (0.tif,1.tif,..,199.tif)
# 这里已经提前把训练数据给分割为图片了,读取的时候直接是读取的图片
for c in sorted(listdir(join(Config.DATASET_PATH, f))):
if str(join(join(Config.DATASET_PATH, f), c))[-3:] == "tif":
img = Image.open(join(join(Config.DATASET_PATH, f), c)).resize((256, 256))
img = np.array(img, dtype=np.float32) / 256.0
all_frames.append(img)
# get the 10-frames sequences from the list of images after applying data augmentation
# 这里按照不同的步长,对于不同的视频集进行采样
for stride in range(1, 3):
clips.extend(get_clips_by_stride(stride=stride, frames_list=all_frames, sequence_size=10))
return clips
# 一些配置类的数据
class Config:
DATASET_PATH ="/content/drive/My Drive/Colab Notebook2/UCSD_Anomaly_Dataset.v1p2/UCSDped1/Train"
SINGLE_TEST_PATH = "/content/drive/My Drive/Colab Notebook2/UCSD_Anomaly_Dataset.v1p2/UCSDped1/Test/Test032"
BATCH_SIZE = 4
EPOCHS = 3
MODEL_PATH = "/content/drive/My Drive/Colab Notebook2/callback/model_lstm.hdf5"
def get_model(reload_model=True):
"""
Parameters
----------
reload_model : bool
Load saved model or retrain it
"""
# 如果直接加载模型
if not reload_model:
return load_model(Config.MODEL_PATH, custom_objects={'LayerNormalization': LayerNormalization})
# 获取训练数据, 数据格式list[[NUMBER_OF_SEQUENCES, (10, 256, 256,1)], ... ]
training_set = get_training_set()
training_set = np.array(training_set)
training_set = training_set.reshape(-1, 10, 256, 256, 1)
# 构建模型
seq = Sequential()
seq.add(
TimeDistributed(Conv2D(128, (11, 11), strides=4, padding="same"), batch_input_shape=(None, 10, 256, 256, 1)))
seq.add(LayerNormalization())
seq.add(TimeDistributed(Conv2D(64, (5, 5), strides=2, padding="same")))
seq.add(LayerNormalization())
# # # # #
seq.add(ConvLSTM2D(64, (3, 3), padding="same", return_sequences=True))
seq.add(LayerNormalization())
seq.add(ConvLSTM2D(32, (3, 3), padding="same", return_sequences=True))
seq.add(LayerNormalization())
seq.add(ConvLSTM2D(64, (3, 3), padding="same", return_sequences=True))
seq.add(LayerNormalization())
# # # # #
seq.add(TimeDistributed(Conv2DTranspose(64, (5, 5), strides=2, padding="same")))
seq.add(LayerNormalization())
seq.add(TimeDistributed(Conv2DTranspose(128, (11, 11), strides=4, padding="same")))
seq.add(LayerNormalization())
seq.add(TimeDistributed(Conv2D(1, (11, 11), activation="sigmoid", padding="same")))
print(seq.summary())
seq.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(lr=1e-4, decay=1e-5, epsilon=1e-6))
# 训练模型
seq.fit(training_set, training_set,
batch_size=Config.BATCH_SIZE, epochs=Config.EPOCHS, shuffle=False)
seq.save(Config.MODEL_PATH)
return seq
def get_single_test():
sz = 200
test = np.zeros(shape=(sz, 256, 256, 1))
cnt = 0
for f in sorted(listdir(Config.SINGLE_TEST_PATH)):
if str(join(Config.SINGLE_TEST_PATH, f))[-3:] == "tif":
img = Image.open(join(Config.SINGLE_TEST_PATH, f)).resize((256, 256))
img = np.array(img, dtype=np.float32) / 256.0
test[cnt, :, :, 0] = img
cnt = cnt + 1
return test
import matplotlib.pyplot as plt
def evaluate():
model = get_model(True)
print("got model")
test = get_single_test()
print(test.shape)
sz = test.shape[0] - 10
sequences = np.zeros((sz, 10, 256, 256, 1))
# apply the sliding window technique to get the sequences
for i in range(0, sz):
clip = np.zeros((10, 256, 256, 1))
for j in range(0, 10):
clip[j] = test[i + j, :, :, :]
sequences[i] = clip
print("got data")
# get the reconstruction cost of all the sequences
reconstructed_sequences = model.predict(sequences,batch_size=4)
sequences_reconstruction_cost = np.array([np.linalg.norm(np.subtract(sequences[i],reconstructed_sequences[i])) for i in range(0,sz)])
sa = (sequences_reconstruction_cost - np.min(sequences_reconstruction_cost)) / np.max(sequences_reconstruction_cost)
sr = 1.0 - sa
# plot the regularity scores
plt.plot(sr)
plt.ylabel('regularity score Sr(t)')
plt.xlabel('frame t')
plt.show()
if __name__ == "__main__":
evaluate()
附带一个opencv将视频流转换为tif的代码
import cv2
import os
import shutil
def video2tiff(vid_name, save_dir):
vid = cv2.VideoCapture(vid_name)
assert vid.isOpened(), "video not exist"
count = 0
if os.path.exists(save_dir):
shutil.rmtree(save_dir)
os.makedirs(save_dir)
while True:
ret, frame = vid.read()
if not ret:
print("end of video")
break
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow("gray image", gray)
cv2.waitKey(10)
cv2.imwrite("%s/%d.tif" %(save_dir, count), gray)
count = count + 1
if __name__ == "__main__":
video_list = os.listdir("training_videos")
for video_name in video_list:
saving_video_tif_path = "train_tif/"+video_name.replace(".avi", "")
video_name = "training_videos/"+video_name
video2tiff(video_name, saving_video_tif_path)
# video2tiff("01.avi", "01")