POM
1.什么是POM?
POM(Page Object Model) 页面对象模型 有的人也会说PO(Page Object)模式。本质就是用一个页面对象模型(python里面是类)来管理维护一组页面元素的对象库。在PO下,应用程序的每一个页面都有一个对应的Page类。每一个Page类维护着该页面的元素集和操作这些元素的方法.
2.优势
- 代码可读性强
- 可维护性高
- 复用性高
- PO模式和非PO模式对比
| 非PO模式 |
PO模式 |
| 面向过程的线性脚本 |
POM把页面元素定位和业务操作流程分开。实现解耦合。 |
| 复用性差 |
UI元素的改变不需要修改业务逻辑代码。只需要找到对应的PO页修改定位即可,数据代码分离 |
| 维护性差 |
PO能使我们的测试代码提高代码的可读性,高复用性,可维护性。 |
原来我们的项目是断言和业务分离,但是我们的元素,元素的操作方法以及case流程都写在一个函数内部。后期如果页面元素定位改变,我们需要找到case中这一块内容进行更改。如果多个函数调用到这个元素。那么就要多处更改。这样是不利于我们后期的维护的。
3.如何设计
1.抽象每一个页面
2.页面中元素不暴露,仅报错操作元素的方法
3.页面不应该有繁琐的继承关系
4.页面中不是所有元素都需要涉及到,核型业务元素做建模使用
5.把页面划分功能模块,在Page中实现这些功能方法
4.代码实现
1.构建基本Page类 封装各个页面共有的操作方法
# -*- coding: utf-8 -*-
"""
@author: ZJ
@email: 1576094876@qq.com
@File : BasePage.py
@desc:
@Created on: 2021/1/21 19:27
"""
from selenium import webdriver
from selenium.webdriver.support.select import Select
from selenium.webdriver.support.wait import WebDriverWait
from woniusalePOM.Page.getBrowser import Get_Browser
class Page(object):
driver = None
def __init__(self):
# 1. 实例化driver对象
self.driver,self.wait = Get_Browser.get_bro()
def get(self,url):
self.driver.get(url)
def find_ele(self,*args):
print(args)
ele = self.driver.find_element(*args)
return ele
def click(self,ele):
ele.click()
def send_keys(self,ele,text):
ele.clear()
ele.send_keys(text)
def sel_by_text(self,ele,text):
sel = Select(ele)
sel.select_by_visible_text(text)
def ex_js(self,js_str,value):
self.driver.execute_script(js_str.format(value))
2.抽离页面对象类
2.1 首页页面对象
# -*- coding: utf-8 -*-
"""
@author: ZJ
@email: 1576094876@qq.com
@File : HomePage.py
@desc:
@Created on: 2021/1/21 20:12
"""
import time
from selenium.webdriver.common.by import By
from woniusalePOM.Page.BasePage import Page
class HomePage(Page):
username_loc = ("id","username")
password_loc = ("id","password")
verifycode_loc = ("id","verifycode")
login_loc = (By.CLASS_NAME,"form-control.btn-primary")
logout_loc = (By.LINK_TEXT,"注销")
def login(self):
self.get('http://localhost:8080/WoniuSales-20180508-V1.4-bin/')
self.send_keys(self.find_ele(*self.username_loc),"admin")
self.send_keys(self.find_ele(*self.password_loc),"123456")
self.send_keys(self.find_ele(*self.verifycode_loc),"0000")
self.click(self.find_ele(*self.login_loc))
def logout(self):
self.click(self.find_ele(*self.logout_loc))
if __name__ == '__main__':
HomePage().login()
2.2 会员管理页面对象
# -*- coding: utf-8 -*-
"""
@author: ZJ
@email: 1576094876@qq.com
@File : VipPage.py
@desc:
@Created on: 2021/1/21 21:29
"""
from selenium.webdriver.common.by import By
from woniusalePOM.Page.BasePage import Page
from woniusalePOM.Page.HomePage import HomePage
class VipPage(Page):
vipmanagement_loc = (By.LINK_TEXT,"会员管理")
customerphone_loc = ("id",'customerphone')
customername_loc = ("id",'customername')
childsex_loc = ("id",'childsex')
birthday_loc = "document.querySelector('#childdate').value='{}'"
creditkids_loc = ("id",'creditkids')
creditcloth_loc = "document.querySelector('#creditcloth').value={}"
add_loc = (By.XPATH,"/html/body/div[4]/div[1]/form[2]/div[2]/button[1]")
def addvip(self):
self.click(self.find_ele(*self.vipmanagement_loc))
self.send_keys(self.find_ele(*self.customerphone_loc),"138776259")
self.send_keys(self.find_ele(*self.customername_loc),"zsss")
self.sel_by_text(self.find_ele(*self.childsex_loc),"男")
self.ex_js(self.birthday_loc,"2020-10-13")
self.send_keys(self.find_ele(*self.creditkids_loc),0)
self.ex_js(self.creditcloth_loc,0)
self.click(self.find_ele(*self.add_loc))
if __name__ == '__main__':
HomePage().login()
VipPage().addvip()
5.单例模式
1.什么是单例模式
任何一个类在进行实例化时,每一次实例化都会生成一个新的实例,并且分配一块新的内存空间,而单例模式是指在程序的生命周期中,只做一次实例化,只分配一块内存空间,以确保所有的操作和调用仅在同一块内存空间内发生。
单例模式,属于创建类型的一种常用的软件设计模式。通过单例模式的方法创建的类在当前进程中只有一个实例。
2.为什么用单例
上方的代码如果我们没有使用单例的话,多个页面对象就会创建多个浏览器对象。浪费资源消耗时间。所以我们就可以通过单例模式让整个程序运行过程中,共用同一个浏览器对象(只创建一个实例)
3.创建单例的方式
1.通过类
class GetDriver(object):
driver=None
@classmethod
def getdriver(cls):
if not cls.driver:
cls.driver = webdriver.Chrome(executable_path=r'D:\Pycharm\PythonProject\woniu37\GUI\drivers\chromedriver1.exe')
return cls.driver
a1 = GetDriver.getdriver()
a2 = GetDriver.getdriver()
1.KDT 基本概念
反射机制
反射就是通过字符串的形式,导入模块,方法,属性等。如果是方法则返回方法引用 如果是属性则返回属性的值
Python有四个内置函数:
| 函数 |
功能 |
| getattr(object, attr[, default]) |
获取指定字符串名称的对象属性或方法,如果对象有该属性则返回属性值,如果有该方法则返回该方法的内存地址,如果都没有就报错,如果指定了默认值找不到不会报错会取默认值 |
| hasattr(object, attr) |
判断指定字符串名称的对象是否有该属性或方法,返回True或False |
| setattr(object, attr, value) |
为指定字符串名称的对象设置属性,如果对象已有该属性则覆盖属性值,如果没有该属性则新增属性并赋值 |
| delattr(object, attr) |
删除指定字符串名称的对象的某属性,如果对象没有该属性会报错 |
kdt和ddt的区别。
在ddt中,按照业务流程已经封装好了对应的执行方法,在cases层中,直接调用业务层中封装好的方法,加上断言就可执行测试.
在kdt中,组件仓库中,只有对每个元素或者每个接口实现的操作步骤,并没有完整的业务逻辑。业务逻辑需要在文档中,通过字符串的方式来实现对应方法的调用,甚至需要对断言进行单独封装,断言的调用也是在文档中直接调用。
总结:ddt文档中,只有数据,而kdt中不光有数据,还有执行逻辑。那么框架的人员其实可以不用再去管业务逻辑。只需要设计框架。提供给业务逻辑一套规则
case编写
# 用例编写格式 : keyword,ObjectType=ObjectName,ObjectValue
open,Firefox,http://localhost:8080/WoniuSales-20180508-V1.4-bin/
send_key,id,username,admin
send_key,id,password,123456
send_key,id,verifycode,0000
click,class,form-control.btn-primary
#### 关于webdriver中使用class_name找元素当class多个时必须用.代替空格的原因
https://blog.csdn.net/cyjs1988/article/details/75006167
实现原理
- 规范用例设计标准,让框架使用人员按照业务流程及规范。设计测试用例脚本
- 根据业务流程 分析业务中可能会涉及的具体操作动作,然后根据这些动作封装对应的关键字库
- 解析测试用例
- 将解析好的数据。根据反射机制。去框架中调用对应的关键字执行对应的操作
- 收集运行过程数据 用于产出最终报告

关键字代码
class KDT:
def open(self,browser,url):
"""
打开指定浏览器访问指定地址
:param browser:
:param url:
:return:
"""
if browser == "Chrome":
self.driver = webdriver.Chrome(executable_path=r'D:\Pycharm\PythonProject\woniu37\GUI\drivers\chromedriver1.exe',)
elif browser == "Firefox":
self.driver = webdriver.Firefox(executable_path=r'D:\Pycharm\PythonProject\woniu37\GUI\drivers\geckodriver.exe')
self.driver.implicitly_wait(10)
self.driver.get(url)
def click(self,by,value):
ele = self.driver.find_element(by,value)
ele.click()
def send_keys(self,by,value,content):
ele = self.driver.find_element(by, value)
ele.send_keys(content)
if __name__ == '__main__':
kdt = KDT()
getattr(kdt,"open")("Chrome","http://localhost:8080/WoniuSales-20180508-V1.4-bin/")
getattr(kdt,"send_keys")("id","username","admin")
getattr(kdt,"send_keys")("id","password","123456")
getattr(kdt,"send_keys")("id","verifycode","0000")
getattr(kdt,"click")("class name","form-control.btn-primary")
读取文件实现关键字驱动
kdt = KDT()
def start(filename):
with open(filename,encoding="utf-8") as f:
testcaselist = f.readlines()
for testcase in testcaselist:
if testcase[0] != "#": # 跳过注释
print(testcase)
stepdetail = testcase.strip().split(",") # 去除换行符
print(stepdetail)
oper = stepdetail[0] # 获取操作
# 使用反射机制 获取该操作方法。并执行
getattr(kdt,oper)(*stepdetail[1:])
if __name__ == '__main__':
start("testcase")
问题:当前只是一个case。那如果是多个case?
2.数据持久层设计
在学自动化之前。我们通常都是用execl来保存我们的测试用例
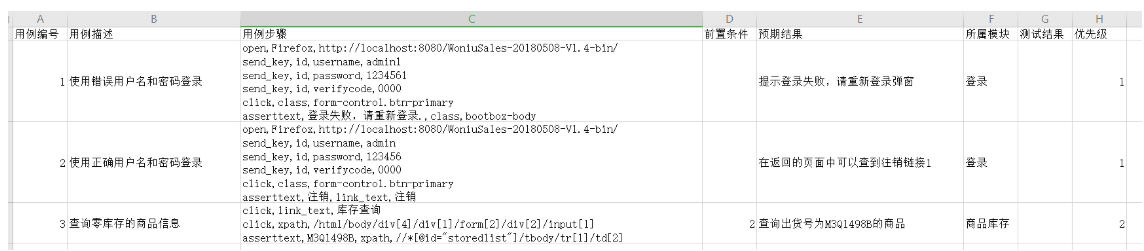
通常有 用例编号,用例标题,用例步骤,前置条件,预期结果,所属模块,测试结果,优先级几个字段
那我们现在能否直接读取我们写的测试用例来实现自动化测试呢?
这边是我们之前写好的一个测试用例的execl
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Bxo4cxhq-1670223088246)(https://woniumd.oss-cn-hangzhou.aliyuncs.com/test/zhangjing/20210108154943.png)]
那我们是不是可以将这个execl简单修改,将步骤改成我们之前的关键字 实现。这样后期我们直接读取execl就可以执行case了
3.解析数据设计
1.python读excel的相关操作
安装方法:pip install xlrd
官方文档:https://xlrd.readthedocs.io/en/latest/api.html
使用
1、导入模块
import xlrd
2、打开Excel文件读取数据
data = xlrd.open_workbook(filename)# 打开execl文件,返回整个表空间
3、获取一个工作表
table = data.sheets()[0] #通过索引顺序获取
table = data.sheet_by_index(0) #通过索引顺序获取
table = data.sheet_by_name(u'Sheet1') #通过名称获取
# 这三个函数都是返回一个xlrd.sheet.Sheet()对象
4、返回表中所有工作表名称
names = data.sheet_names()
5、行操作
rows = table.nrows # 返回该sheet中的有效行数
table.row(row) # 返回row行中所有的单元格对象组成的列表
6、列操作
ncols = table.ncols # 返回该sheet中的有效列数
table.col(colx, start_rowx=0, end_rowx=None) # 返回该列中所有的单元格对象组成的列表
7、单元格操作
table.cell(row,col) # 返回单元格对象
table.cell(row,col).value # 返回单元格对象
table.cell_value(row,col) # 返回单元格中的数据
2.构建解析器
解析自动化测试用例的一个类
# -*- coding: utf-8 -*-
"""
@author: ZJ
@email: 1576094876@qq.com
@File : parseexecl.py
@desc:
@Created on: 2022/2/22 15:18
"""
import xlrd
class ParseExecl:
"""对execl表格的相关操作 用来获取表格内的信息"""
def __init__(self,filepath,index=0):
self.fileobj = xlrd.open_workbook(filepath)
self.table = self.fileobj.sheet_by_index(index)
self.nrows = self.table.nrows
self.ncols = self.table.ncols
def get_kdtstep(self,row):
cellvalue = self.table.cell_value(row,5)
allstep = cellvalue.split("\n")
return allstep
def get_title(self,row):
cellvalue = self.table.cell_value(row,2)
return cellvalue
def get_preposition_kdt(self,row):
cellvalue = self.table.cell_value(row,4)
return cellvalue
def getmodule(self,row):
cellvalue = self.table.cell_value(row,1)
return cellvalue
def getrowbymodule(self,module_name):
"""
根据模块名称找到当前文件所有该名称的行号
:param module_name:
:return:
"""
# allrow = []
# for row in range(self.nrows):
# if self.getmodule(row)=="module_name": # 条件成立说明这一行的模块名符合要求
# allrow.append(row)
allrow = [row for row in range(self.nrows) if self.getmodule(row)==module_name ]
# print(allrow)
return allrow
def getrowvalues(self,row):
res = self.table.row_values(row)
return res
if __name__ == '__main__':
# # 1.打开文件 得到文件对象
# fileobj = xlrd.open_workbook(r'D:\Pycharm\PythonProject\auto-test52\TestData\woniukdt.xlsx')
# # 2.获取要操作的表格
# table = fileobj.sheet_by_index(0)
# print(table.nrows)
# print(table.ncols)
execlobj = ParseExecl(r'D:\Pycharm\PythonProject\auto-test52\TestData\woniukdt.xls')
res = execlobj.getrowvalues(5)
print(res)
# print(bool(res))
4.构建执行文件
1构建一个执行函数
需求:根据用户的输入的文件名,要执行的caseid或者模块去执行对应的case步骤
# -*- coding: utf-8 -*-
"""
@author: ZJ
@email: 1576094876@qq.com
@File : run.py
@desc: 整个项目的入口 运行该文件启动该项目
执行格式 python run.py 要执行的文件名 browser= rowlist=
可以直接接收终端传递过来的参数 执行对应的需求
b 可以设置为 Firefox表示用火狐执行 或者 Chrome 用谷歌执行
rowlist 如果用户需要自定义执行想要的case 可以通过它设置
rowlist=[1,3,5] 表示只会执行第 1行3行5行用例 行号从0开始
m 表示用户指定模块执行
@Created on: 2022/2/22 17:12
"""
# -*- coding: utf-8 -*-
"""
@author: ZJ
@email: 1576094876@qq.com
@File : run.py
@desc: 入口文件 通过入口文件执行项目中的case
python run.py 参数
支持以下参数 格式 键=值
rows=[3,4,5]
m=登录
f=要执行的用例文件名
python run.py rows=[3,4,5] m=登录
@Created on: 2022/4/7 10:45
"""
# 需求1: 根据文件 执行文件中所有的kdtcase
# r'D:\Pycharm\PythonProject\woniu54\AutoTest\testdata\woniusaleskdt.xls'
import os
import sys
sys.path.append( os.path.dirname( os.path.dirname( os.path.abspath(__file__)) )) # D:\Pycharm\PythonProject\woniu54
from AutoTest.Common.execute import Execute
from AutoTest.Common.parseexecl import ParseExecl
from AutoTest.Common.setting import Config
def start(filename,rows=[],module=None,):
# print(os.path.join(Config.TestDataPath,filename),)
px = ParseExecl( os.path.join(Config.TestDataPath,filename), start_row=2)
allrow = []
if rows: # 说明 用户指定了要执行的行 #[1,7]
allrow.extend(rows) # extend 将参数里面的元素逐一添加到列表中
if module: # 说明用户指定 某个模块执行
# 根据模块名 提取要执行的行号
modulerow =px.get_row_bymodule(module)
allrow.extend(modulerow)
if not allrow: # 用户什么都没指定 allrow才会没数据
allrow = px.get_docase_row()
# 实例化执行者对象 开始调用执行函数
# ex = Execute(r'D:\Pycharm\PythonProject\woniu54\AutoTest\testdata\woniusaleskdt.xls')
ex = Execute(px) # ParseExecl(filename, start_row=2)
print("要执行的行:",allrow)
for row in allrow:
print("------------------------",row)
ex.docase(int(row))
if __name__ == '__main__':
filename = "woniusaleskdt.xls" # 声明要执行的文件
rows = []
module=None
# sys.argv # 获取命令行传递的参数 返回一个列表 列表中的每个元素就是终端的一个参数
print(sys.argv) # ['run.py', 'f=woniusaleskdt.xls', 'rows=[3,4,5]', 'm=登录']
for argv in sys.argv[1:]: # 循环遍历每个参数 # 'f=woniusaleskdt.xls', 'rows=[3,4,5]' 'm=登录'
detailargv = argv.split("=") # ["f","woniusaleskdt.xls"] ["rows","[3,4,5]"]
if detailargv[0]=="f":# 说明用户要设置指定执行的用例文件
filename=detailargv[1]
elif detailargv[0]=="m": # 说明用户要设置指定的模块
module=detailargv[1]
elif detailargv[0]=="rows": # 说明用户要设置指定执行的用例
rows=eval(detailargv[1])
else:
raise Exception(f"不支持该参数 {detailargv[0]}") # 如果用户参数输入不正确直接提示用户
# rows = eval(input("请输入你要执行的caseid的行号 :")) # [3,4] a="[3,4,5]" # --->[3,4,5]
# module = input("请输入你想执行的模块 :") # [3,4] a="[3,4,5]" # --->[3,4,5]
# #据用户的输入的文件名,要执行的caseid或者模块去执行对应的case步骤
# print(filename,rows,module)
start(filename,rows,module)
pyautogui相关用法
pyautogui是一个使用python的跨平台的操作鼠标和键盘的模块,非常方便使用。还支持一些简单的图像识别相关操作
安装
pip install pyautogui
提示 ModuleNotFoundError: No module named 'win32api' 需要安装pip install pypiwin32
提示import win32api, win32con ImportError: DLL load failed: 找不到指定的程序。
需要 pip install pywin32==227 不行就 pip install pywin32==223
安装如果出现缺少模块 pyHook https://zhuanlan.zhihu.com/p/143676206
使用
import pyautogui
pyautogui.PAUSE = 1 # 调用在执行动作后暂停的秒数,只能在执行一些pyautogui动作后才能使用,建议用time.sleep
pyautogui.FAILSAFE = True # 启用自动防故障功能,左上角的坐标为(0,0),将鼠标移到屏幕的左上角,来抛出failSafeException异常
width, height = pyautogui.size() # 屏幕的宽度和高度
print(width, height)
##鼠标相关操作
currentMouseX, currentMouseY = pyautogui.position() # 鼠标当前位置
print(currentMouseX, currentMouseY)
pyautogui.moveTo(100, 100, duration=0.25) # 移动到 (100,100)
pyautogui.moveRel(50, 0, duration=0.25) # 从当前位置右移100像素
# pyautogui.click(x=moveToX, y=moveToY, clicks=num_of_clicks, interval=secs_between_clicks, button='left')
# 其中,button属性可以设置成left,middle和right。
pyautogui.click(10, 20, 2, 0.25, button='left')
pyautogui.click(x=100, y=200, duration=2) # 先移动到(100, 200)再单击
pyautogui.click() # 鼠标当前位置点击一下
pyautogui.doubleClick() # 鼠标当前位置左击两下
pyautogui.doubleClick(x=100, y=150, button="left") # 鼠标在(100,150)位置左击两下
pyautogui.tripleClick() # 鼠标当前位置左击三下
pyautogui.rightClick(10,10) # 指定位置,双击右键
pyautogui.middleClick(10,10) # 指定位置,双击中键
# scroll函数控制鼠标滚轮的滚动,amount_to_scroll参数表示滚动的格数。正数则页面向上滚动,负数则向下滚动
# pyautogui.scroll(clicks=amount_to_scroll, x=moveToX, y=moveToY)
pyautogui.scroll(5, 20, 2)
pyautogui.scroll(10) # 向上滚动10格
pyautogui.scroll(-10) # 向下滚动10格
pyautogui.scroll(10, x=100, y=100) # 移动到(100, 100)位置再向上滚动10格
##键盘相关操作
pyautogui.typewrite('Hello world!') # 输入Hello world!字符串
pyautogui.typewrite('Hello world!', interval=0.25) # 每次输入间隔0.25秒,输入Hello world!
pyautogui.press('enter') # 按下并松开(轻敲)回车键
pyautogui.press(['left', 'left', 'left', 'left']) # 按下并松开(轻敲)四下左方向键
pyautogui.keyDown('shift') # 按下`shift`键
pyautogui.keyUp('shift') # 松开`shift`键
pyautogui.hotkey('ctrl', 'v') # 组合按键(Ctrl+V),粘贴功能,按下并松开'ctrl'和'v'按键
##图像操作
im = pyautogui.screenshot(r'C:\Users\ZDH\Desktop\PY\my_screenshot.png') # 截全屏并设置保存图片的位置和名称
print(im) # 打印图片的属性
# 不截全屏,截取区域图片。截取区域region参数为:左上角XY坐标值、宽度和高度
pyautogui.screenshot(r'C:\Users\ZDH\Desktop\PY\region_screenshot.png', region=(0, 0, 300, 400))
# 获得文件图片在现在的屏幕上面的坐标,返回的是一个元组(top, left, width, height)
# 如果截图没找到,pyautogui.locateOnScreen()函数返回None
a = pyautogui.locateOnScreen(r'C:\Users\ZDH\Desktop\PY\region_screenshot.png')
print(a) # 打印结果为Box(left=0, top=0, width=300, height=400)
x, y = pyautogui.center(a) # 获得文件图片在现在的屏幕上面的中心坐标
print(x, y) # 打印结果为150 200
x, y = pyautogui.locateCenterOnScreen(r'C:\Users\ZDH\Desktop\PY\region_screenshot.png') # 这步与上面的四行代码作用一样
print(x, y) # 打印结果为150 200
# 匹配屏幕所有与目标图片的对象,可以用for循环和list()输出
pyautogui.locateAllOnScreen(r'C:\Users\ZDH\Desktop\PY\region_screenshot.png')
pyautogui 相关文档
https://blog.csdn.net/weixin_38640052/article/details/112387653
ateOnScreen(r’C:\Users\ZDH\Desktop\PY\region_screenshot.png’)
print(a) # 打印结果为Box(left=0, top=0, width=300, height=400)
x, y = pyautogui.center(a) # 获得文件图片在现在的屏幕上面的中心坐标
print(x, y) # 打印结果为150 200
x, y = pyautogui.locateCenterOnScreen(r’C:\Users\ZDH\Desktop\PY\region_screenshot.png’) # 这步与上面的四行代码作用一样
print(x, y) # 打印结果为150 200
匹配屏幕所有与目标图片的对象,可以用for循环和list()输出
pyautogui.locateAllOnScreen(r’C:\Users\ZDH\Desktop\PY\region_screenshot.png’)
pyautogui 相关文档
https://blog.csdn.net/weixin_38640052/article/details/112387653
https://blog.csdn.net/qingfengxd1/article/details/108270159