使用pyecharts绘制系统依赖关系图
背景介绍
近期梳理了公司内部系统之间的数据关系,得到了多个excel格式的统计文件,每个文件包含了该系统自身数据清单、依赖的其他系统的数据清单、对其他系统供应的数据清单。
各系统之间依赖关系复杂,所以我想使用一些绘图工具,以可视化图形图表的形式展现这些系统之间的数据关系,给观众形成一种非常直观的印象。
一般情况下,应该是有类似于调用链跟踪等工具,比如Java技术栈使用Skywalking或美团CAT等工具,做到调用级别上的跟踪和相互关系的可视化展示。
这种情况下,也许不需要再编写程序来绘制依赖关系了。这两种工具可以很详细的绘制组件或服务之间的调用关系。
不过,本文介绍如何绘制粒度稍微粗一些的关系图,没有细化到具体某个接口调用。主要的工具是pyecharts,百度开源的工具包。在绘制的时候,只使用了依赖表和对外供应两张表。
可视化思路
可视化的方式有很多种,我的需求是以最小成本,最快速度把这个可视化效果达成。不管是使用类似思维导图或draw.io这种工具,或者是编码实现,只要可以实现,任何方式都可以考虑。
我考虑的第一种方式,是使用draw.io。它确实提供了很多模型,但是最终我发现,手动去绘图,会花很多时间,然后效果还一般。
大概花了总共2小时的时间,发现用draw.io来绘制十多个系统之间复杂的连接,还是有点难。
所以,我考虑第二种方式是使用思维导图。确实思维导图很快可以把图建立起来,因为执行一次回车操作就可以生成一个方框,速度非常快。但是我嫌这个图不好看。
还没等我完成全部的系统和系统之间的连线,我就不想再做下去了。
最后,我决定使用编码的方式实现。这样的好处有两点:第一是生成的图形会很好看,效果好,第二是后续的维护会自动化,一劳永逸。
实现可视化
经过调研了几个框架,包括pyecharts,politly,最终我发现pyecharts的关系图其实可以实现我的想法。
我基于https://gallery.pyecharts.org/#/Graph/graph_les_miserables这个案例实现了想要的效果。
效果图如下,使用菱形图表示系统,圆形便是系统的数据:
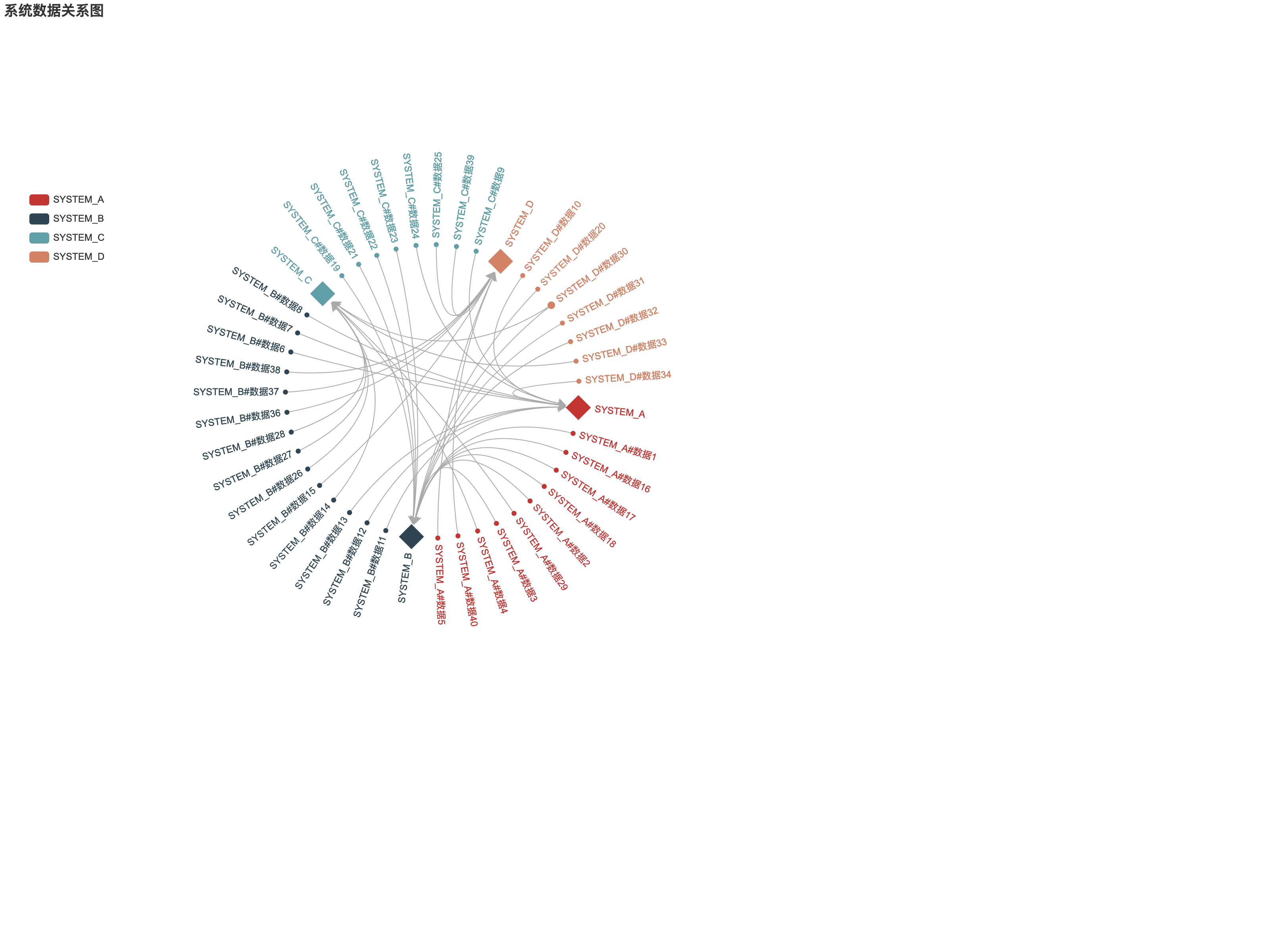
编码实现
相关的代码或文件分三部分,第一部分是包含系统关系的原始文件,放在files_excel目录下,第二部分是用于生成表示图形信息的json文件的python脚本build_json_system_relation.py,第三部分是绘制图形的代码文件generate_relations.py。
代码地址:https://gitee.com/zackli518/charts_system_relations/tree/master
数据关系文件
files_excel目录下的文件,每个文件包含两个sheet(表单),即对外供应数据表清单和所依赖外部系统数据表清单。
对外供应数据表清单表单的格式如下:
| 目的系统 |
数据英文名 |
数据中文名 |
数据交换方式 |
| B |
table1 |
数据1 |
交易线 |
| C |
table2 |
数据2 |
数据线 |
| D |
table3 |
数据3 |
数据线 |
所依赖外部系统数据表清单表单的格式与上面类似,不过第一列是源系统。
上述两个文件就是我们要使用到的系统数据关系文件。如果有工具可以产生上述文件,那所有的步骤都可以自动化完成,包括生成本文讲的这种简单的关系图。如果不能自动生成,那么可能需要人工维护。所以建议还是都能实现自动化。关于如何产生上述关系,不在本文范围内,不过我觉得这种关系在任何一家公司都会维护起来的,比如通过提供一个维护页面维护上述两张表。
生成表示图形中节点和边的JSON文件
现在我们已经有了原始关系文件,这种文件一般是for人类的,就是说给人看和维护的。那么现在我们需要把它们转成给代码使用的json文件。
json文件格式大致如下,可以先了解一下:
{
"categories": [
{
"name": "data node",
"symbol": "circle"
},
{
"name": "system node",
"symbol": "diamond"
}
],
"nodes": [
{
"label": "SYSTEM_A",
"id": "SYSTEM_A",
"category": 0
},
{
"label": "SYSTEM_B",
"id": "SYSTEM_B",
"category": 1
},
{
"label": "SYSTEM_C",
"id": "SYSTEM_C",
"category": 1
},
{
"label": "SYSTEM_A#table1",
"id": "SYSTEM_A#table1",
"category": 0
}
],
"edges": [
{
"sourceID": "SYSTEM_A#table1",
"attributes": {},
"targetID": "SYSTEM_B",
"size": 1
},
{
"sourceID": "SYSTEM_A#table1",
"attributes": {},
"targetID": "SYSTEM_C",
"size": 1
}
]
}
上述文件包含了三部分,第一份是categories,表示分类,可以将节点进行分类,方便区分;第二部分是nodes,表示图中所有节点,第三部分是edges表示图中所有边。
生成上述JSON文件的大概思路或算法是这样的:使用pandas读取excel表的数据,第一列(源或目的系统)作为系统节点,而第三列也就是数据列作为数据节点,对应JSON文件中的nodes中的每个元素。每一行都是一个关系,作为一条边,源节点是数据节点,目的节点是系统节点,对应JSON文件中的edges中的每个元素。通过遍历所有excel文件中的两个表单的每一行(非空),建立节点、边的信息,形成一个大的JSON文件。
关键代码如下:
import json
import pandas as pd
def get_all_node_data(data_dir):
all_node_data = []
import os
for root, dirs, files in os.walk(data_dir):
for file in files:
# get node data
filepath = os.path.join(root, file)
all_node_data.extend(read_data_from_excel(filepath))
return all_node_data
def read_data_from_excel(filename):
"""从excel读取数据,数据项作为一个节点(信息类)"""
out = []
# 系统节点
system_name = get_system_name(filename)
# 读取"对外供应数据表清单"
# 目的系统名称 表英文名 表中文名称 数据供应方式(交易线,数据线)
data = pd.read_excel(filename, sheet_name="对外供应数据表清单", engine="openpyxl")
for i in range(len(data)):
row = data.iloc[i]
info_name = system_name + "#" + trim_node_name(row[2]) # 类似 A#财务数据 这种格式
# 处理以/分隔的多个系统
system_target_list = []
if "/" in row[0]:
systems = str.split(row[0], "/")
for system in systems:
system_target = get_system_name(system)
if system_target not in SYSTEM_IGNORE:
system_target_list.append(system_target)
else:
system_target = get_system_name(row[0])
if system_target not in SYSTEM_IGNORE:
system_target_list.append(system_target)
for system_target in system_target_list:
tmp_node = copy.deepcopy(generate_node_data(info_name, system_target, row[1], row[2], row[3]))
out.append(tmp_node)
# 读取"所依赖外部系统数据表清单"
# 目的系统名称 表英文名 表中文名 数据供应方式(交易线,数据线)
data2 = pd.read_excel(filename, sheet_name="所依赖外部系统数据表清单", engine="openpyxl")
for i in range(len(data2)):
row = data2.iloc[i]
# 处理以/分隔的多个系统
system_src_list = []
if "/" in row[0]:
systems_src = str.split(row[0], "/")
for system in systems_src:
system_src_list.append(system)
else:
system_src_list.append(row[0])
system_target = system_name
for system in system_src_list:
system_name_src = get_system_name(system)
if system_name_src not in SYSTEM_IGNORE:
info_name = system_name_src + "#" + trim_node_name(row[2])
tmp_node = copy.deepcopy(generate_node_data(info_name, system_target, row[1], row[2], row[3]))
out.append(tmp_node)
return out
使用pyecharts绘制图形
现在已经有JSON文件了,工作完成了大部分。接下来就是编写代码绘制关系图,生成一个html文件。这个html文件是可交互的,可以移动鼠标或缩放。如果未来在这个页面增加其他一些检索或表格生成功能就更好了。可以作为未来继续尝试的点。这块没有什么算法逻辑。
关键代码如下:
json_file = "all_node_data.json"
with open(json_file, 'r') as f:
data_local = f.read()
data = json.loads(data_local)
nodes = [
{
# "x": node["x"],
# "y": node["y"],
"id": node["id"],
"name": node["label"],
"symbolSize": node["size"],
"symbol": node["symbol"],
# "itemStyle": {"normal": {"color": node["color"]}},
"category": node["category"]
}
for node in data["nodes"]
]
edges = [
{"source": edge["sourceID"], "target": edge["targetID"], "value": edge["value"],
"linestyle_opts": opts.LineStyleOpts(type_=edge["type_"]),
} for
edge in data["edges"]
]
categories = data["categories"]
(
Graph(init_opts=opts.InitOpts(width="1600px", height="1200px"))
.add(
series_name="",
nodes=nodes,
links=edges,
categories=categories,
layout="circular", # circular , force, none
is_roam=True,
is_focusnode=True,
repulsion=100,
is_rotate_label=True,
label_opts=opts.LabelOpts(is_show=True, position="right"),
linestyle_opts=opts.LineStyleOpts(width=1, curve=0.3, opacity=1.0), # type_="solid"
edge_symbol=["", "arrow"], # 单向箭头
edge_label=opts.LabelOpts(
is_show=False, position="middle", formatter="{b}: {c} " # 设置关系说明
)
)
.set_global_opts(title_opts=opts.TitleOpts(title="系统数据关系图"),
legend_opts=opts.LegendOpts(orient="vertical", pos_left="2%", pos_top="20%"), )
.render("relations-systems.html")
)
参考
参考: