目录
数据挖掘
一、数据挖掘理解
二、数据准备
1、缺失值处理
2、异常值处理
3、数据偏差的处理
4、数据的标准化
5、特征选择
三、数据建模
1、分类问题
2、聚类问题
3、回归问题
4、关联问题
四、评估模型
1、混淆矩阵与准确率指标
2、评估数据的处理

业务理解、数据理解、数据准备、构建模型、评估模型、模型部署。
一、数据挖掘理解
业务理解和数据理解
思考问题
数据挖掘只能在有限的资源与条件下去提供最大化的解决方案
把握数据
主要是看是否有数据、有多少数据、是什么样的数据、数据标签
二、数据准备
找到数据
数据探索
数据清洗
1、缺失值处理
删掉有缺失值的数据;补充缺失值;不做处理。
2、异常值处理
不同情况的异常值有不同的处理办法:
- 数据本身的错误,需要对数据进行修正,或者直接丢弃;
- 数据是正确的,需要根据你的业务需求进行处理。如果你的目标就是发现异常情况,那么这种异常值就需要保留下来,甚至需要特别关照。
- 如果你的目标跟这些异常值没有关系,那么可以对这些异常值做一些修正,比如限定最大值和最小值的标准等,从而防止这些数据影响你后面模型的效果。
3、数据偏差的处理
如果你需要比较均衡的样本,那么通常可以考虑丢弃较多的数据,或者补充较少的数据。
在补充较少的数据时,又可以考虑使用现有数据去合成一些数据,或者直接复制一些数据从而增加样本数量。当然了,每一种方案都有它的优点和缺点,具体的情况还是要根据目标来决定,哪个对目标结果的影响较小就采取哪种方案。
4、数据的标准化
http://t.csdn.cn/pz63Y
可以看我之前总结的文章。
5、特征选择
维度越多,数据就会越稀疏,模型的可解释性就会变 差、可信度降低。
这个时候就需要用到特征选择的技巧,比如自然语言处理里的关键词提取,或者去掉屏蔽词,以减少不 必要的数据维度。
构建训练集和测试集
在数据进入模型之前,你还需要对其进行数据采样处理。如果说前面的部分是为了给模型提供一个好的 学习内容,那么数据采样环节则是为了评估模型的学习效果。 在训练之前,你要把数据分成训练集和测试集,有些还会有验证集。
- 如果是均衡的数据,即各个分类的数据量基本一致,可以直接随机抽取一定比例的数据作为训练样 本,另外一部分作为测试样本。
- 如果是非均衡的数据,比如在风控型挖掘项目中,风险类数据一般远远少于普通型数据,这时候使 用分层抽样以保障每种类型的数据都可以出现在训练集和测试集中。
当然,训练集和测试集的构建也是有方法的,比如:
- 留出法,就是直接把整个数据集划分为两个互斥的部分,使得训练集和测试集互不干扰,这个是最 简单的方法,适合大多数场景;
- 交叉验证法,先把数据集划分成 n 个小的数据集,每次使用 n-1 个数据集作为训练集,剩下的作 为测试集进行 n 次训练,这种方法主要是为了训练多个模型以降低单个模型的随机性;
- 自助法,通过重复抽样构建数据集,通常在小数据集的情况下非常适用。
三、数据建模
1、分类问题
分类是有监督的学习过程。
分类问题中包括以下 3 种情况:
- 二分类。 这是分类问题里最简单的一种,因为要回答的问题只有 “是” 或“否”。比如我在处理用户 内容时,首先要做一个较大的分类判断,即一条内容是否属于旅游相关内容,这就是二分类问题, 得出的结论是这条内容要么是旅游相关,要么不是旅游相关。
- 多分类。 在二分类的基础上,将标签可选范围扩大。要给一条内容标注它的玩法,那种类就多 了,比如冲浪、滑雪、自驾、徒步、看展等,其种类甚至多达成百上千个标签。
- 多标签分类。 是在多分类基础上再升级的方法。对于二分类和多分类,一条内容最后的结果只有 一个,标签之间是互斥的关系。但是多标签分类下的一条数据可以被标注上多个标签。比如一个人 在游记里既可以写玩法,也可以写美食,这两者并不冲突。
由于分类问题众多,所以用来解决分类问题的算法也非常多,像 KNN 算法、决策树算法、随机森林、SVM 等都是为解决分类问题设计的。
2、聚类问题
聚类是无监督的。
既然是要划分小组,就要先看看小组之间可能存在的 4 种情况。
- 互斥:小组和小组之间是没有交集的,也就是说一个用户只存在于一个小组中。
- 相交:小组和小组之间有交集,那么一条数据可能既存在于 A 组,也存在于 B 组之中,如一个用 户既可以爱滑雪,也可以爱爬山。
- 层次:一个大组还可以细分成若干个小组,比如将高消费用户继续细分,可以有累积高消费用户和 单次高消费用户。
- 模糊:一个用户并不绝对属于某个小组,只是用概率来表示他和某个小组的关系。假设有五个小 组,那么他属于这五个小组的模糊关系就是 [0.5,0.5,0.4,0.2,0.7]。
所以,对应上面 4 种不同的小组情况,也有 4 种不同的聚类方法。
- 第一种:基于划分的聚类,通常用于互斥的小组。 划分的方法就好像在数据之间画几条线,把数 据分成几个小组。想象你的数据散落在一个二维平面上,你要把数据划分成三个类,那么在划分完 之后,所有数据都会属于一个类别。
- 第二种:基于密度的聚类,可以用来解决数据形状不均匀的情况。 有些数据集分布并不均匀,而 是呈现不规则的形状,而且组和组之间有一片空白区域,这个时候用划分的方法就很难处理,但是 基于密度的聚类不会受到分布形状的影响,只是根据数据的紧密程度去聚类。
- 第三种:基于层级的聚类,适用于需要对数据细分的情况。 就像前面说的要把数据按照层次进行 分组,可以使用自顶向下的方法,使得全部数据只有一个组,然后再分裂成更小的组,直到满足你 的要求。如有从属关系,需要细分的数据,就非常适合这种方法。同样,也可以使用自底向上的方 法,最开始每一条数据都是一个组,然后把离得近的组合并起来,直到满足条件。
- 最后一种:基于模型的聚类。 这种聚类方法首先假设我们的数据符合某种概率分布模型,比如说 高斯分布或者正态分布, 那么对于每一种类别都会有一个分布曲线,然后按照这个概率分布对数 据进行聚类,从而获得模糊聚类的关系。
3、回归问题
与分类问题十分相似,都是根据已知的数据去学习,然后为新的数据进行预测。但是不同的是,分类方 法输出的是离散的标签,回归方法输出的结果是连续值。
4、关联问题
关联问题对应的方法就是关联分析。这是一种无监督学习,它的目标是挖掘隐藏在数据中的关联模式并 加以利用。与分类和回归不同,关联分析是要在已有的数据中寻找出数据的相关关系,以期望能够使用 这些规则去提升效率和业绩。
四、评估模型
1、混淆矩阵与准确率指标
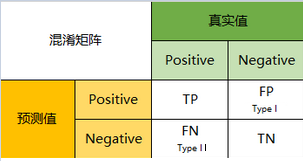
一级指标:
- 真实值是positive,模型认为是positive的数量(True Positive=TP)
- 真实值是positive,模型认为是negative的数量(False Negative=FN):这就是统计学上的第二类错误(Type II Error)
- 真实值是negative,模型认为是positive的数量(False Positive=FP):这就是统计学上的第一类错误(Type I Error)
- 真实值是negative,模型认为是negative的数量(True Negative=TN)
二级指标:
- 准确率(Accuracy):是指所有预测正确的占全部样本的概率,即小猪图被预测成小猪,以及不 是小猪被预测成不是小猪的结果,与所有图片的比值,公式为 (TP+TN)/(TP+FP+FN+TN),在本案 例中为 (745+175)/(745+175+25+55)=0.92。
- 精确率(Precision):指的是预测正确的结果占所有预测成 “是” 的概率,即 TP/(TP+FP)。精确率 按照类别来计算,比如说对于 “是小猪图” 这个类别的精确率是 745/(745+25)≈ 0.9675。
- 召回率(Recall):按照类别来区分,某个类别结果的召回率即该类别下预测正确的结果占该类别 所有数据的概率,即 TP/(TP+FN),在本案例中 “是” 类别召回率 745/(745+55)≈0.93。
- F 值(F Score):基于精确率和召回率的一个综合指标,是精确率和召回率的调和平均值。一般 的计算方法是 2(PrecisionRecall)/(Precision+Recall)。如果一个模型的准确率为 0,召回率 为 1,那么 F 值仍然为 0。
- ROC 曲线和 AUC 值:这个略微有点复杂,但也是一个非常常用的指标。仍然是基于混淆矩阵,但 不同的是这个对指标进行了细化,构建了很多组混淆矩阵。
其他评估指标
除了上述的两大类指标,还可以从以下几个方面来对模型进行评估。
- 模型速度:主要评估模型在处理数据上的开销和时间。这个主要是基于在实际生产中的考虑,由于模型 的应用在不同的平台、不同的机器会有不同的响应速度,这直接影响了模型是否可以直接上线使用,关 于更多模型速度相关的问题,我们将在下一课时模型应用中介绍。
- 鲁棒性:主要考虑在出现错误数据或者异常数据甚至~是~数据缺失时,模型是否可以给出正确的结果, 甚至是否可以给出结果,会不会导致模型运算的崩溃。
- 可解释性:随着机器 学习算法越来越复杂,尤其是在深度学习中,模型的可解释性越来越成为一个问 题。由于在很多场景下(比如金融风控),需要给出一个让人信服的理由,所以可解释性也是算法研究 的一大重点。
2、评估数据的处理
关于数据集的处理,重点目标在于消减评估时可能出现的随机误差。在前面准备数据的课时内容中已经 提过,这里我们再对一些方案详细介绍一下。
- 随机抽样:即最简单的一次性处理,把数据分成训练集与测试集,使用测试集对模型进行测试,得 到各种准确率指标。
- 随机多次抽样:在随机抽样的基础上,进行 n 次随机抽样,这样可以得到 n 组测试集,使用 n 组 测试集分别对模型进行测试,那么可以得到 n 组准确率指标,使用这 n 组的平均值作为最终结 果。
- 交叉验证:交叉验证与随机抽样的区别是,交叉验证需要训练多个模型。譬如,k 折交叉验证,即 把原始数据分为 k 份,每次选取其中的一份作为测试集,其他的作为训练集训练一个模型,这样 会得到 k 个模型,计算这 k 个模型结果作为整体获得的准确率。
- 自助法:自助法也借助了随机抽样和交叉验证的思想,先随机有放回地抽取样本,构建一个训练 集,对比原始样本集和该训练集,把训练集中未出现的内容整理成为测试集。重复这个过程 k次、构建出 k 组数据、训练 k 个模型,计算这 k 个模型结果作为整体获得的准确率,该方法比较 适用于样本较少的情况。