一、摘要
对于一个基于CTR预估的推荐系统,最重要的是学习到用户点击行为背后隐含的特征组合。在不同的推荐场景中,低阶组合特征或者高阶组合特征可能都会对最终的CTR产生影响。但是现存的方法总是忽视了高阶或低阶组合特征的联系,或者要求专门的特征工程,因此作者建立了DeepFM模型,将FM与DNN结合起来(这点跟wide&deep的结合有异曲同工之妙,后面会讲到)。
二、模型演变和各模型间的对比
1、CTR的任务要求
1、CTR的数据特点:
1、输入中包含类别型和连续型数据。类别型数据需要one-hot,连续型数据可以先离散化再one-hot,也可以直接保留原值
2、维度非常高且数据非常稀疏
3、引入FFM后特征按照Field分组
2、CTR的预估重点:
CTR预估重点在于学习组合特征。
其中,组合特征包括二阶、三阶甚至更高阶的,阶数越高越复杂,越不容易学习。Google的论文研究得出结论:高阶和低阶的组合特征都非常重要,同时学习到这两种组合特征的性能要比只考虑其中一种的性能要好。
那么关键问题转化成:如何高效的提取这些组合特征。
一种办法就是引入领域知识人工进行特征工程。这样做的弊端是高阶组合特征非常难提取,会耗费极大的人力。而且,有些组合特征是隐藏在数据中的,即使是专家也不一定能提取出来,比如著名的“尿布与啤酒”问题。
2、DeepFM模型的引入
为了解决上文提到的提取组合特征的问题,该论文作者借鉴了Google的wide & deep的做法提出了DeepFM模型。
DeepFM模型本质是
1、将Wide & Deep 部分的wide部分由 人工特征工程+LR 转换为FM模型,避开了人工特征工程;
2、FM模型与deep part共享feature embedding。
Q1、为什么要用FM代替线性部分(wide)呢?
因为线性模型有个致命的缺点:无法提取高阶的组合特征。
FM通过隐向量latent vector做内积来表示组合特征,从理论上解决了低阶和高阶组合特征提取的问题。但是实际应用中受限于计算复杂度,一般也就只考虑到2阶交叉特征。
3、各模型间的对比
1、随着DNN在图像、语音、NLP等领域取得突破,人们意识到DNN在特征表示上的天然优势。相继提出了使用CNN或RNN来做CTR预估的模型。
但是,CNN模型的缺点是:偏向于学习相邻特征的组合特征。
RNN模型的缺点是:比较适用于有序列(时序)关系的数据。
2、FNN (Factorization-machine supported Neural Network) 的提出,应该算是一次非常不错的尝试:先使用预先训练好的FM,得到隐向量,然后作为DNN的输入来训练模型。缺点在于:受限于FM预训练的效果。
3、PNN (Product-based Neural Network),PNN为了捕获高阶组合特征,在embedding layer和first hidden layer之间增加了一个product layer。根据product layer使用内积、外积、混合分别衍生出IPNN, OPNN, PNN*三种类型。
无论是FNN还是PNN,他们都有一个绕不过去的缺点:**对于低阶的组合特征,学习到的比较少。**而前面我们说过,低阶特征对于CTR也是非常重要的。
4、为了同时学习低阶和高阶组合特征,Google提出了Wide&Deep模型。它混合了一个线性模型(Wide part)和Deep模型(Deep part)。这两部分模型需要不同的输入,而Wide part部分的输入,依旧依赖人工特征工程。
4、DeepFM优势
3中的这些模型普遍都存在两个问题:
偏向于提取低阶或者高阶的组合特征。不能同时提取这两种类型的特征。
需要专业的领域知识来做特征工程。
DeepFM在Wide&Deep的基础上进行改进,成功解决了这两个问题,并做了一些改进,其优势如下:
1.不需要预训练FM得到隐向量
2.不需要人工特征工程
3.能同时学习低阶和高阶的组合特征
4.FM模块和Deep模块共享Feature Embedding部分,可以更快的训练,以及更精确的训练学习
三、DeepFM模型介绍
deepFM原论文可点击这里下载

如上图所示整体结构为FM Component + Deep Component。
FM提取低阶组合特征,Deep提取高阶组合特征。但是和Wide&Deep不同的是,DeepFM是端到端的训练,不需要人工特征工程。
另外FM和Deep部分共享feature embedding。FM和Deep共享输入和feature embedding不但使得训练更快,而且使得训练更加准确。相比之下,Wide&Deep中,input vector非常大,里面包含了大量的人工设计的pairwise组合特征,增加了他的计算复杂度。
1、FM部分

FM部分的输出由两部分组成:一个Addition Unit,多个内积单元。
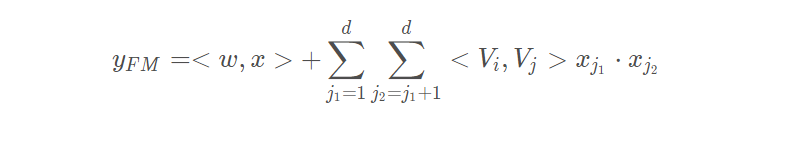
Addition Unit 反映的是1阶的特征。内积单元反映的是2阶的组合特征对于预测结果的影响。
FM部分的特点:
FM模块实现了对于1阶和2阶组合特征的建模;
没有使用预训练;
没有人工特征工程;
embedding矩阵的大小是:特征数量 * 嵌入维度。 然后用一个index表示选择了哪个特征。
FM需要训练的两部分:
input_vector和Addition Unit相连的全连接层,也就是1阶的Embedding矩阵。
Sparse Feature到Dense Embedding的Embedding矩阵,中间也是全连接的,要训练的是中间的权重矩阵,这个权重矩阵也就是隐向量V。
2、Deep部分

Deep Component是用来学习高阶组合特征的。网络里面黑色的线是全连接层,参数需要神经网络去学习。
由于CTR或推荐系统的数据one-hot之后特别稀疏,如果直接放入到DNN中,参数非常多,我们没有这么多的数据去训练这样一个网络。所以增加了一个Embedding层,用于降低纬度。
Embedding层,两个特点:
尽管输入的长度不同,但是映射后长度都是相同的.embedding_size(k)
embedding层的参数其实是全连接的Weights,是通过神经网络自己学习到的。
代码实现部分可以参考这篇文章
https://www.jianshu.com/p/6f1c2643d31b
FM部分的一些细节介绍和模型比较可参考这篇文章
https://blog.csdn.net/Dby_freedom/article/details/85263694
参考:
https://blog.csdn.net/qq_35564813/article/details/86022277
https://blog.csdn.net/Dby_freedom/article/details/85263694
https://www.jianshu.com/p/6f1c2643d31b