示例代码:
maven引入:
// maven引入
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.6.5</version>
</dependency>
redisson配置:
// redisson配置
@Bean
public Redisson redisson() {
// 此为单机模式
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379").setDatabase(0);
return (Redisson) Redisson.create(config);
}
模拟减库存代码:
@Autowired
private Redisson redisson;
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Autowired
private RedisTemplate redisTemplate;
@RequestMapping("/deduct_stock")
public String deductStock() {
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if (stock > 0) {
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock", realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
} else {
System.out.println("扣减失败,库存不足");
}
return "end";
}
1、高并发场景下秒杀抢购超卖Bug实战重现
如果是高并发场景下有多个用户来进行库存扣减,那么在示例代码中就会有多个用户同一时间从redis中读取到同一个库存,那么就会产生超卖的问题,这样商家肯定就会产生重大损失,这肯定是不允许的。
2、秒杀抢购场景下实战JVM级别锁与分布式锁
那要怎么解决超卖这个问题呢?首先想到的肯定是加锁,不然多个用户同一时间读取库存。
JVM级别锁
synchronized (this) {
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if (stock > 0) {
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock", realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
} else {
System.out.println("扣减失败,库存不足");
}
}
这样我们就加了一个 synchronized ,这样在单机环境下是没问题了。

但是现在很多项目都是集群部署,这样也会产生问题。synchronized 是一个 JVM 级别的锁,如果同一时刻有多个请求过来,nginx 把请求转发到不同的机器上,那么在集群内其他机器是保证不了产生并发问题的。
我们这里搭建好上图所示的集群后,用 jmeter 来测试一下。
jmeter压测
1)在本地启动8080和8090两个进程

2)配置nginx
upstream redislock{
server 127.0.0.1:8080;
server 127.0.0.1:8090;
}
server {
listen 80;
server_name localhost;
#反向代理 8080、8090 服务器集群
location / {
proxy_pass http://redislock/;
}
}
3)配置 jmeter


4)启动 jmeter 开始压测,并查看结果
8080:

8090:
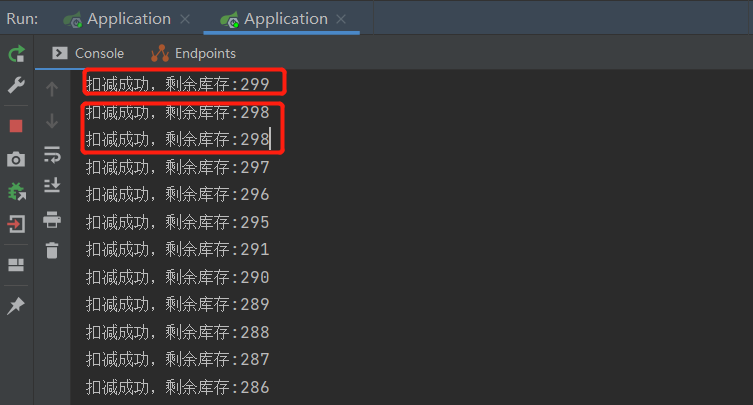
这里加了 synchronized为什么同一个进程下还会有重复的呢?
因为在分布式下高并发会产生各种各样的问题,这里可能就是由于前一个进程读取后,又把redis中的库存给设置回去了,后一个进程又读取到了已经读取过的库存。
从结果图中可以看到在 8080 和 8090 两个进程中都会有库存重复超卖的现象,所以说 JVM 级别的锁是解决不了分布式下的并发问题。
分布式锁
由于很多公司里面都会用到 redis ,那么直接使用 redis 来实现分布式锁肯定是很简单的。
版本一:
用 redis 中的命令 setnx。

可以从命令手册中看到 setnx 这个命令非常适合用于分布式锁。
@RequestMapping("/deduct_stock")
public String deductStock() {
String lockKey = "lock:product_101";
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, "lock", 10, TimeUnit.SECONDS); //jedis.setnx(k,v)
if (!result) {
return "error_code";
}
try {
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if (stock > 0) {
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock", realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
} else {
System.out.println("扣减失败,库存不足");
}
} finally {
stringRedisTemplate.delete(lockKey);
}
return "end";
}
如果是在一些小公司,并发量不太大,可以容忍一些超卖的情况下,这个版本的分布式锁的代码已经可以解决对应的问题了。
缺点
但是在高并发的场景下,这个版本的代码还是会产生超卖的问题。

如图中所示,T1和T2同一时刻进入抢占锁,T1加锁成功,T2加锁失败,但是由于某个原因导致T1加锁到解锁之间需要执行15s,在T1执行到10s的时候,T1的锁已经失效,这时等待的T2也加锁成功,这时候的锁就是锁的T2。继续执行5s,T1开始执行释放锁的逻辑,这时T1释放的就是T2的锁。T3也在这时刻进入,因为T2的锁已经释放,T3也会加锁成功。
这个其实是一种小概率时间,这样无限循环下去其实就跟没加锁的效果是一样的了,根本解决不了超卖的问题。
版本二:
其实版本一的根本性问题是:自己加的锁被别的线程给释放掉了。
这里只需要在释放锁的时候判断一下,只有自己才能释放自己加的锁。
@RequestMapping("/deduct_stock")
public String deductStock() {
String lockKey = "lock:product_101";
String clientId = UUID.randomUUID().toString();
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, "clientId", 30, TimeUnit.SECONDS); //jedis.setnx(k,v)
if (!result) {
return "error_code";
}
try {
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if (stock > 0) {
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock", realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
} else {
System.out.println("扣减失败,库存不足");
}
} finally {
if (clientId.equals(stringRedisTemplate.opsForValue().get(lockKey))) {
stringRedisTemplate.delete(lockKey);
}
}
return "end";
}
缺点
if (clientId.equals(stringRedisTemplate.opsForValue().get(lockKey))) {
stringRedisTemplate.delete(lockKey);
}
高并发场景下在这段代码里面也会产生版本一的问题,比如在判断clientId成功后,释放锁之前产生卡顿,这时候锁过期,这时有其他的线程抢占锁成功,接着当前线程释放锁,这时也是释放的其他的线程锁,又出现了版本一的缺点。
这里根本性的原因是:判断释放锁这里不是原子性的。
版本三
其实这里锁的过期时间的设定是不好判断的,代码执行可能由于各种的原因导致卡顿的情况,导致锁失效。
如果要把分布式锁实现的比较完美的话有一个锁续命的方案。
当有一个主线程抢到锁后,然后有一个分线程搞一个定时任务每过一段时间(要小于锁的过期时间)执行判断主线程是否已经结束,如果没有结束,把这个锁的超时时间重新设置过过期时间。
这里我们直接就引入 Redisson 框架进行实现分布式锁。
3、分布式锁 Redisson 框架实战
Redisson中文文档:目录 · redisson/redisson Wiki · GitHub
他的引入已经在最上面讲到了,这里就不过多的赘述。
@RequestMapping("/deduct_stock")
public String deductStock() {
String lockKey = "lock:product_101";
//获取锁对象
RLock redissonLock = redisson.getLock(lockKey);
//加分布式锁
redissonLock.lock(); // .setIfAbsent(lockKey, clientId, 30, TimeUnit.SECONDS); {
try {
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if (stock > 0) {
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock", realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
} else {
System.out.println("扣减失败,库存不足");
}
} finally {
//解锁
redissonLock.unlock();
}
return "end";
}
redisson用起来就是如此的简单。
4、Redisson 分布式锁源码剖析
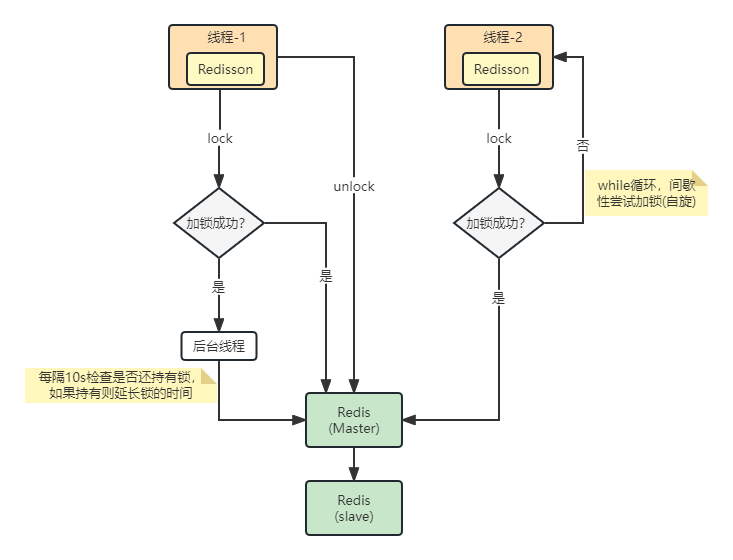
加锁
redissonLock.lock() --> lockInterruptibly() --> lockInterruptibly(-1, null) --> tryAcquire --> tryAcquireAsync --> tryLockInnerAsync 。
这里的调用链路就行清晰,进到 tryLockInnerAsync 内部其实就是执行的一段 lua (redis是单线程执行命令,会把lua脚本里面的语句看成一条命令来执行,不会被打断)脚本就行加锁。

internalLockLeaseTime这里过期时间默认的是30s。
其实这个看门狗(过期时间)时间是可以修改的:
@Bean
public Redisson redisson() {
// 此为单机模式
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379").setDatabase(0);
// config.setLockWatchdogTimeout(10000); // 设置分布式锁 watch dog 超时时间
return (Redisson) Redisson.create(config);
}
看门狗(锁续命)

ttlRemainingFuture.addListener会监听 tryLockInnerAsync执行的返回结果,然后就行执行 operationComplete方法,如果加锁失败直接返回,如果加锁成功就会继续执行后续的方法。
future.getNow()这段代码会拿到 lua 脚本里面返回的值,如果加锁成功这里就会返回 null(lua 脚本中的 nil 就对应 java 中的 null)。
接着会执行 scheduleExpirationRenewal
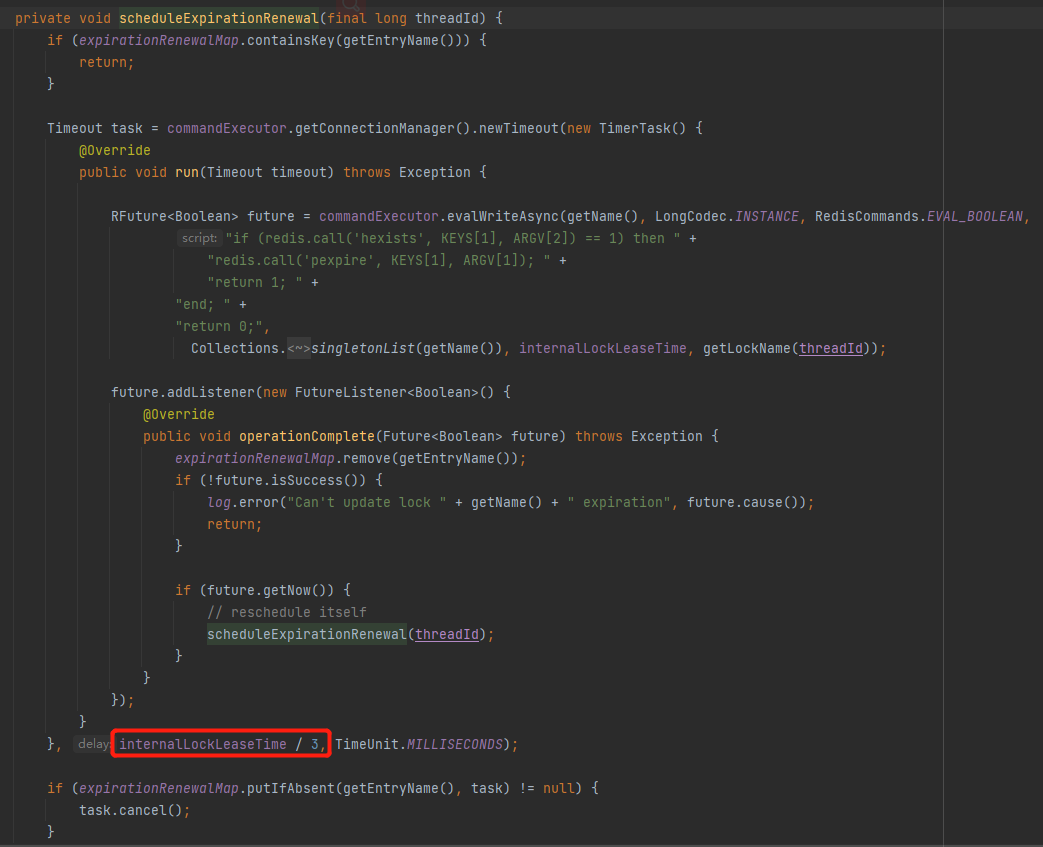
根据 internalLockLeaseTime / 3 算出来的时间,会在进入这个方法 10s 后执行 run() 方法。
先会判断主线程中加的锁是否还存在,还存在的话就会把主线程的超时时间重新设置为 30s ,接着又会调用下面 listener 的回调方法 operationComplete ,如果续命成功接着就会循环执行 scheduleExpirationRenewal。
加锁失败

还是加锁时的那段 lua 脚本,另外的线程加锁失败的话就会返回当前加锁成功线程的锁剩余超时时间。

然后返回主线逻辑中,接着就会执行下面的逻辑,因为加锁失败返回的 ttl 肯定是不为 null 的,往下就会执行 while 中的逻辑。
第一步:ttl = tryAcquire(leaseTime, unit, threadId);这一步是刷新 ttl 剩余时间;
第二步:getEntry(threadId).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);这里就会阻塞 ttl 这么长的时间,然后再回到 while 循环中再次尝试加锁(这里的阻塞不会占用CPU,会释放CPU,不会消耗性能)。
这里会有一个问题就是:如果在其余线程等待 ttl 时间内,锁已经释放了,不可能让这些线程傻傻的在这里一直等待把。
这里有等待,那么肯定还有其它地方要唤醒。
唤醒抢锁实败阻塞的线程

抢锁失败的线程在这里会订阅 prefixName("redisson_lock__channel", getName())这个channel。
唤醒的逻辑肯定在解锁的时候进行唤醒了。
redissonLock.unlock() --> unlockInnerAsync 。
然后里面还是一段 lua 脚本。

redis.call('publish', KEYS[2], ARGV[1]); lua 脚本这段就是往 prefixName("redisson_lock__channel", getName()) 里发布一个消息,说明锁已经释放。
再来看到加锁逻辑里面的 LockPubSub#onMessage,就是对上面订阅的channel,有消息来的时候进行执行的方法。

释放的核心逻辑就是 value.getLatch().release(); 对 Semaphore 进行释放。
5、Redis 主从架构锁失效问题解析
在企业中一般 redis 都是主从、哨兵或者集群架构的嘛,以防止单点故障问题。master 和 slave 之间同步和 redisson到mater lock之间,这两个步骤之间是异步的。如果在线程从master获取到锁后,接着master 和 slave 之间数据同步的时候,master 突然宕机了,这时候数据还没有同步完成,slave中是没有线程的锁的,这时候slave变成了master 节点,新来的线程也能加锁成功了。这就会造成redis主从架构锁失效。
用redis实现的分布式锁在解决这个问题上并没有那么容易。
6、从 CAP 角度剖析 Redis 与 Zookeeper 分布式锁区别
从CAP角度来说,redis的集群架构师满足AP,可用性这块是满足的多一点。而ZK是满足CP的,一致性这块满足的多一点。
因为在ZK中,也是leader节点进行写数据,它并不会在leader节点写数据成功后马上告诉加锁的线程获取锁成功了,而是先会把数据给集群中的follower节点进行同步,follower节点同步成功过后会把同步成功的结果返回给leader节点,leader节点会计算同步成功到follower节点个数大于等于过半节点个数后,才会返回给客户端说明本次加锁成功。如果这个时候leader挂了,那么ZK会把同步最多数据的那个follower节点选举成为master节点,这样就不会丢失数据(这是由于ZK内部的ZAB机制实现的)。
在性能方面:ZK的性能肯定是不如redis的。
从分布式锁设计语义角度来说:ZK可能更加合适。
7、Redlock 分布式锁原理与存在问题分析
在网上很多文章说用 redlock(红锁) 能解决redis主从切换过程中锁失效的问题。我们就具体分析一下,redlock到底能不能解决这个问题呢?
其实redlock和ZK的写入方式很像,都是要半数加锁成功以后才返回客户端加锁成功。

redlock原理:
如图所示,有三个redis节点都是互相独立的,这时来了一个线程1,他要在redis1,redis2,redis3其中两个节点加锁成功,才会返回给客户端加锁成功。这里比如就在redis1,redis2上加锁成功了。此时线程2也来加锁,线程2只能在redis3上才能加锁成功,因为不足半数2个节点,那么线程2是加锁失败的。
问题1:
因为在我们持久化redis的时候一般不会每一条命令都持久化一次,一般会设置1s持久化一次。如果redis1加锁成功,redis2锁刚刚加成功,这时返回给客户端加锁成功了,但是这个时候redis2加锁成功还不足1s,这时redis2挂了,这时redis2刚刚加的锁没有持久化到磁盘,重启过后这个锁肯定丢失了。这时来一个线程2,在redis2和redis3都能加锁成功,还是会造成上述问题。
问题2:

如果在redis1,redis2,redis3后面都挂一个slave节点,还是和上面一样redis1,redis2已经加锁成功,返回给客户端加锁完成,但是redis2还没有同步到slave2是就挂了,主从切换的时候slave2编程redis2,这时是没有刚刚加锁成功的key的。线程2再次来加锁的话,还是能在redis2和redis3上加锁成功,这时就又出现问题了。
8、大促场景下如何将分布式锁性能提升100倍
分布式锁的设计语义其实是:把多个并行执行的请求串行化了。
它其实是和高并发相违背的,如果遇到特别高并发场景下是需要大于分布式锁进行优化的。
- 锁粒度越小越好(加锁的代码越小越好);
- 分段锁;
分段锁:
比如有一个product_1这个产品库存有1000个,就会把这个产品进行拆分为product_1_100,product_1_200,.....,product_1_1000,用100个库存来拆分存储到不同的redi节点,到时候请求就根据相应的算法分配到不同的redis节点中,那么分布式锁的性能又有了提升。