该篇内容基于之前写过的一篇<>,上一篇文章其实主要重点是结合logstash的实际应用。近期业务方提出了新的需求,增加了些业务逻辑,同时数据量也成倍增加,要求每日产出指标结果,这里再回顾下上篇的数据情况和技术方案同时对比下新调整后的数据量
端
调整前数据量
调整后数据量
生产端
每日20亿左右
每日500亿左右
输出端
减半,10亿左右
每日50亿+
考虑到投入产出比,该需求仍然采用来原来老的技术方案设计,只是做了些优化手段。具体使用到的技术:Java,Kafka,MLSQL,Logstash,Ruby,Hive,ES,SparkSQL,Datax「注意:这里均是实际的业务场景和实际的数据量,本文以分享为目的,如果读者有更好的方案,欢迎一起交流」
「1.数据流向」 「2.技术方案」 「这里设置的是每3秒一个批次,这里做了一次批内去重」 )并将数据再次写回kafka中「考虑数据接口更新频率和数据量,这里每小时调用一次,另存入环境变量其实就是一个缓存,之所以没有存入文件,是因为logstash每次处理event都要对文件进行操作,效率较低」 ),然后进行获取,最后otut端将数据写入hdfs中「3.问题引入」 「别问我怎么知道的,因为这是踩过的坑」 )。所以接下来需要对该部分任务进行优化,尽量做到占用最小的资源以最快的时间产出。
「1.消费优化,其目标:即做到消费不延迟」 「这里涉及到频繁的文件打开关闭和同步问题」 ),后采用环境变量的方式进行存储,每次处理event的时候读取环境变量字段即可。具体使用方式如下:
if not ENV["app_list"].nil?「2.批处理优化,其目标:占用最少的资源花最小的时间产出」 「相对于lz4压缩,snappy是属于不可切分的,那么这也对mapper数量进行了控制」 )。
create table if not exists tableA(3.改用执行引擎「这里只是过滤对于该次需求无用的数据,不做每小时聚合的操作,即业务场景需要对全天的数据进行聚合处理」 ),为了尽可能使用较少时间执行,需要将小时处理的任务执行引擎由hive调整为sparksql执行,同时调整了以下几个参数
--开启动态分区
基于以上的几种优化手段,目前已经解决了前面提到的占用资源过多和产出时间过长的问题。
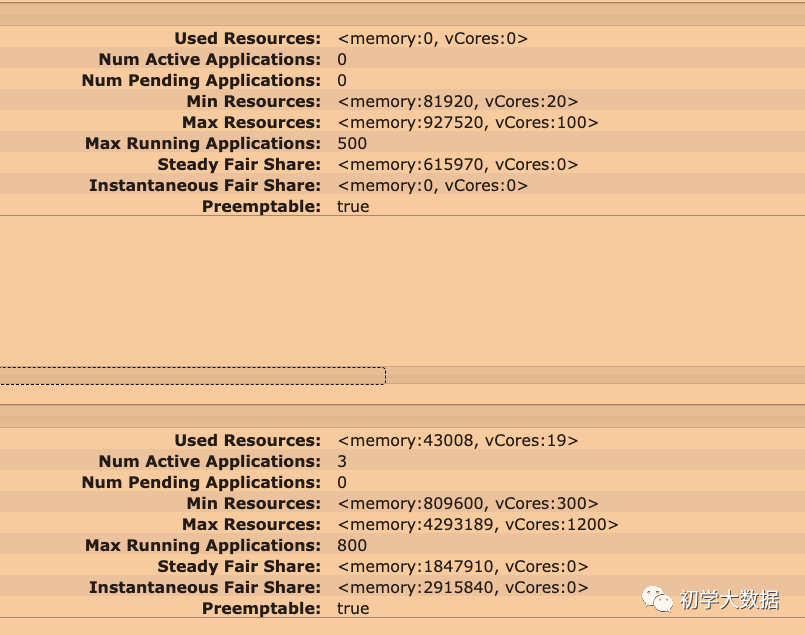
资源使用(队列最大资源使用量)
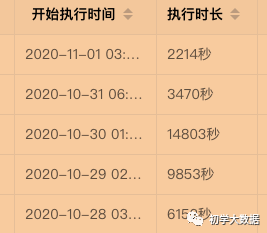
产出时间
优化前
1200Cores+4293189M+Fair Scheduler
14803秒
优化后
100Cores+92752M+Fair Scheduler
3470秒
yarn队列资源配置
调度任务执行情况
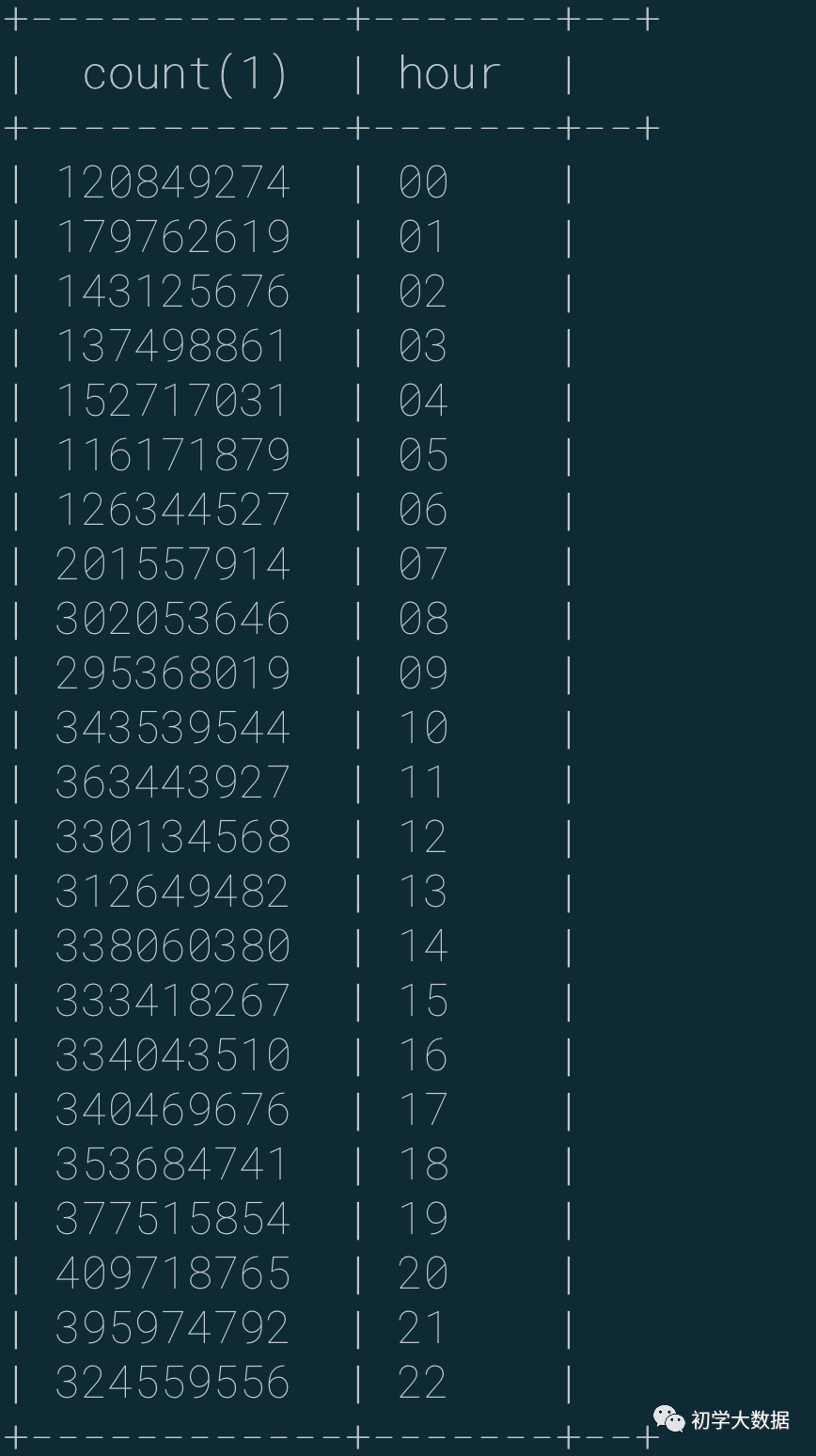
最终要聚合统计的数据量
虽然已经解决掉了占用资源多,产出时间长的问题,但是稳定性也是亟需要解决的问题。由于logstash消费端部署的机器配置各有差异,所以在写入hdfs的时候及其不稳定,也容易导致延迟产生。后续消费这块逻辑可能会迁移至flink来改造实现,目前这块仍在集成开发阶段中,待完善后会再次分享给读者们。另如果读者们如果有更好的解决方案,欢迎一起沟通讨论
往期推荐
Flink从入门到放弃之-入门篇(一)
教你如何使用正确姿势关闭SparkStreaming
数据开发必经之路-数据倾斜
元数据管理-技术元数据解决方案
2020年大厂面试题-数据仓库篇
一万字完整总结Flume
SparkStreaming完整学习教程
数据同步神器-Datax源码重构
zookeeper源码解读之-源码编译
zookeeper源码解读之-服务端启动流程
zookeeper源码解读之-DataTree模型构建+Leader选举
实战:如何实时采集上亿级别数据?
Spark数据倾斜之骚操作解决方案
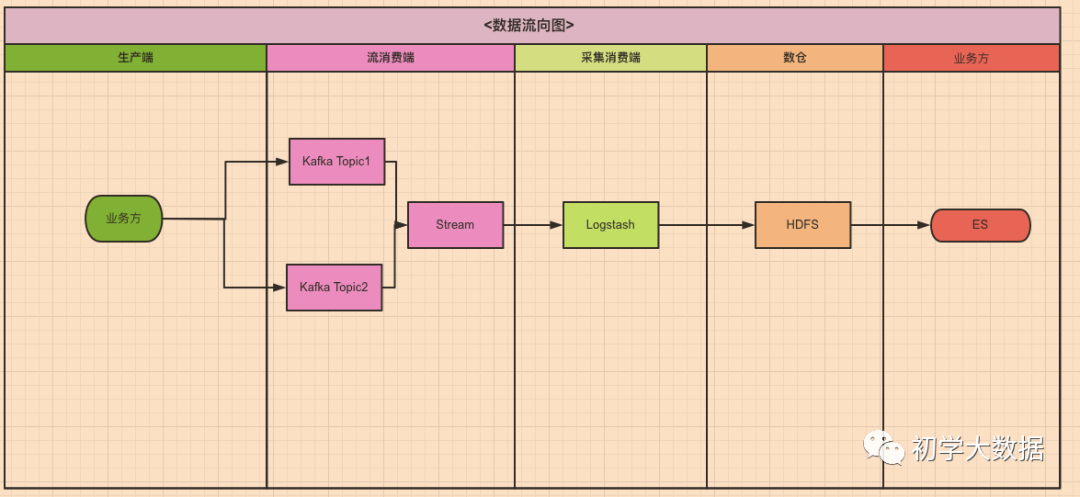 流程:
流程: 流程:
流程: