在编译程序的过程中,需要考虑两个问题,一个是使用的代码够不够快,另一个是编译的代码够不够小,下面汇集一些解决方法,主要针对Keil ARMCC编译器:
1,让代码够小
如图 1,未进行任何优化时,keil编译生成的文件大小为:9668字节。

第一步:project >> Option for Target “**” 打开如图 2界面。选择“target”,勾选上“Use MicroLIB”再编译。
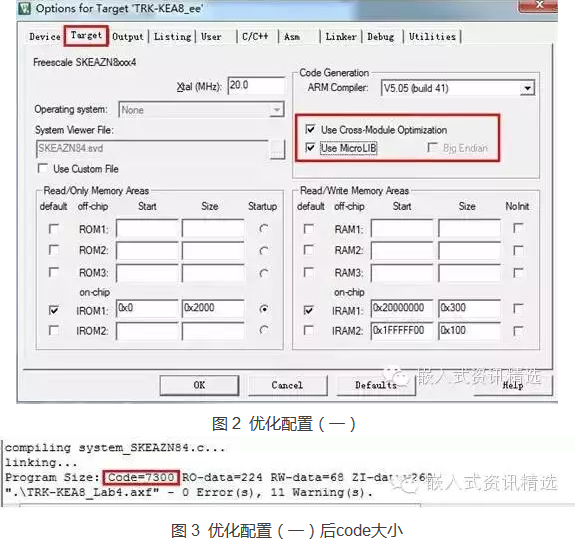
分析:microLIB是缺省的C库,而且microLIB进行了高度优化。如果不勾选“Use MicroLIB”,keil会连接标准C库。所以勾选“Use MicroLIB”会减小code大小。
第二步:project >> Option for Target “**” 打开如界面。选择“C/C++”,勾选上“One ELF Section per Functin”再编译。
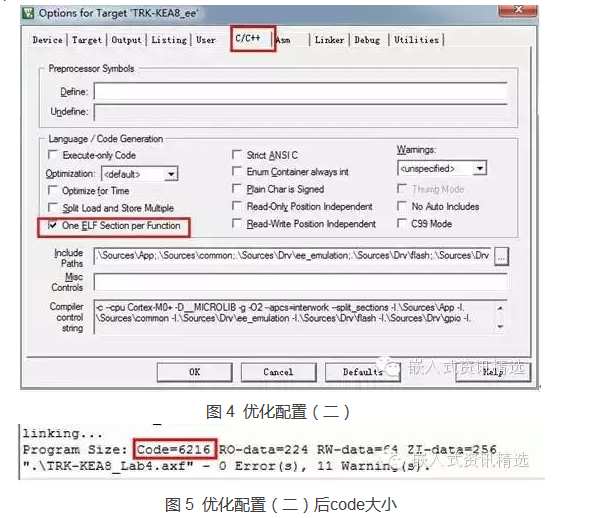
分析:“One ELF Section per Functin”就是将每个函数都生成一个ELF文件,最会将需要的函数链接成一个大的ELF文件。但是如果没有勾选“One ELF Section per Functin”。Keil将每个文件编译成一个ELF文件(即使文件中用未被使用的函数),最会链接成一个ELF文件。所以勾选“One ELF Section per Functin”会使code变小。
2,让代码够快
注意使用的库函数,在使用memcpy的时候要注意,这里已经碰到了一些坑,C库函数提供的memcpy性能有待提高,所以如果代码中有大量的数据拷贝的情况,需要注意下这里的性能问题,可以自己实现这块的代码,目前找了集中memcpy的替代方案,有待验证:
(1)普通标准库的方法
void *memcpy(void *dest, const void *src, size_t count)
{
char *tmp = dest;
const char *s = src;
while (count--)
*tmp++ = *s++ ;
return dest;
}
(2)考虑到重叠的实现方法
void *memcpy(void *dest, const void *src, size_t count)
{
char *d;
const char *s;
if (dest > (src+size)) || (dest < src))
{
d = dest;
s = src;
while (count--)
*d++ = *s++;
}
else /* overlap */
{
d = (char *)(dest + count - 1); /* offset of pointer is from 0 */
s = (char *)(src + count -1);
while (count --)
*d-- = *s--;
}
return dest;
}
(3)另外还看到一种更高效的方法,可以尝试,参考如下链接:
http://blog.163.com/lzh_327/blog/static/7219480201110184108805/
void duff_memcpy( char* to, char* from, int count ) {
size_t n = (count+7)/8;
switch( count%8 ) {
case 7: *to++ = *from++;
case 6: *to++ = *from++;
case 5: *to++ = *from++;
case 4: *to++ = *from++;
case 3: *to++ = *from++;
case 2: *to++ = *from++;
case 1: *to++ = *from++;
case 0: do{ *to++ = *from++;
}while(--n>0);
}
}