ShuffleNet v1:http://openaccess.thecvf.com/content_cvpr_2018/html/Zhang_ShuffleNet_An_Extremely_CVPR_2018_paper.html
tensorflow代码:https://github.com/MG2033/ShuffleNet
pytorch代码:https://github.com/jaxony/ShuffleNet/blob/master/model.py
0. 前言
作者主要提出了两个创新性的模块:pointwise group convolution 和 channel shuffle 两个创新性的模块, 来进一步提升轻量级网络的效率。通常,在现有大型网络Xception和ResNet中为了减少计算量,会采用大量的1×1卷积操作,但是如果直接将1×1的卷积运用到小网络中会存在一些问题,像MobileNet 中1×1卷积的计算量占了绝大多数,因此作者提出来pointwise group convolution 来减少计算量。在分组卷积的过程中,当前分组的卷积会只与当前分组的输入有关,各组之间的信息会没有交流,因此作者提出来channel shuffle 操作, 将不同分组的信息在一定程度上进行混合。
1. channel shuffle for group convolution
目前像ResNeXt网络只是在3×3卷积的部分运用到了分组卷积,而当中pointwise convolution占了93.4%的MAdd, 所以一个直观的想法是对pointwise convolution也采用分组卷积。但这样会使但前输出的每一部分只与对应一小部分的输入有关,如图1(a)所示,这种特性会阻止各个分组之间信息流的相互传递,会减弱网络的表达能力。

图 1 channel shuffle 示意
如果我们在进行分组卷积时从不同的输入分组中获得数据,那么上述问题就可减轻,如 图1(b)所示,将卷积通道划分为不同的分组,然后对于下一层的每个分组,从不同的子分组中的数据分别获得。这可以利用图1(c)所示的**channel shuffle** 操作实现,即先将输出通道reshape成(g, m), 然后对后两个维度取转置(m, g),最后flatten成原来的形状,作为下一层的输入。关于对该过程的理解可以参考图2。

图 2 channel shuffle 理解
2. Shuffle Unit

图 3 ShuffleNet 单元
ShuffleNet Unit的结构比较清晰,借鉴ResNet的残差单元,首先参考Xception, 将3×3卷积换成depthwise convolution, 如图3(a). 之后将两个1×1卷积替换成pointwise group convolution, 值得注意的是作者参考Xception, 没有在depthwise convolution 后面加BN层, 如图3(b)。对于步长为2的模块,结构如图3(c), 主要做了两点改变,一是在shortcut分支增加3×3的average pooling, 二是将原来的Add操作替换成Concatenate,用少量计算量的增加扩大channel维度。
采用Shuffle Unit 可以大大减少计算量,例如:给定输入大小
c
×
h
×
w
c \times h \times w
c×h×w,通道数为c。对于的bottleneck通道为m:
- ResNet:
h
w
(
2
c
m
+
9
m
2
)
F
L
O
P
s
h w\left(2 c m+9 m^{2}\right) F L O P s
hw(2cm+9m2)FLOPs
- ResNeXt:
h
w
(
2
c
m
+
9
m
2
/
g
)
F
L
O
P
s
h w\left(2 c m+9 m^{2} / g\right)F L O P s
hw(2cm+9m2/g)FLOPs
- ShuffleNet:
h
w
(
2
c
m
/
g
+
9
m
)
F
L
O
P
s
h w(2 c m / g+9 m)F L O P s
hw(2cm/g+9m)FLOPs 深度分离卷积:m=g
换句话说,在一定的计算量的前提下,ShuffeNet Unit可以拓宽网络的宽度。而这对于提升网络的性能是十分关键的。
3. ShuffleNet v1

- 每个阶段的第一个block的步长为2,下一阶段的通道翻倍
- 每个阶段内的除步长其他超参数保持不变
- 每个ShuffleNet unit的bottleneck通道数为输出的1/4(和ResNet设置一致)
- 为保证模型FLOPs基本一致,当分组g增大时,相应的channel也会增大
- 可以简单的使用放缩因子s控制通道数,ShuffleNet
s
×
s×
s×即表示通道数放缩到s倍。
4. Experiments
Pointwise Group Convolutions
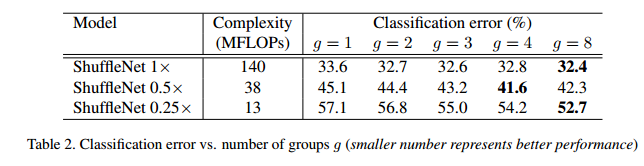
结论:
- 有分组卷积的一致比没有组卷积(g=1)的效果要好。分组卷积可允许获得更多通道的信息,我们假设性能的收益源于更宽的特征映射,这帮助我们编码更多信息。并且,较小的模型的特征映射通道更少,这意味着能多的从特征映射上获取收益。
- 对于一些模型(例如0.5×),随着g增大,性能上有所下降。意味组数增加,每个卷积滤波器的输入通道越来越少,损害了模型表示能力。
- 对于小型的ShuffleNet 0.25×,组数越大性能越好,这表明对于小模型更宽的特征映射更有效。
Channel Shuffle vs. No Shuffle
 在三个不同复杂度下带Shuffle的都表现出更优异的性能.
在三个不同复杂度下带Shuffle的都表现出更优异的性能.
Comparison with Other Structure Units
 可以看到ShuffleNet的表现是比较出色的。有趣的是,我们发现特征映射通道和精度之间是存在直观上的关系,以38MFLOPs为例,VGG-like, ResNet, ResNeXt, Xception-like, ShuffleNet模型在阶段4上的输出通道为50, 192, 192, 288, 576,这是和精度的变化趋势是一致的。我们可以在给定的预算中使用更多的通道,通常可以获得更好的性能。
可以看到ShuffleNet的表现是比较出色的。有趣的是,我们发现特征映射通道和精度之间是存在直观上的关系,以38MFLOPs为例,VGG-like, ResNet, ResNeXt, Xception-like, ShuffleNet模型在阶段4上的输出通道为50, 192, 192, 288, 576,这是和精度的变化趋势是一致的。我们可以在给定的预算中使用更多的通道,通常可以获得更好的性能。
Comparison with MobileNets and Other Frameworks
