Prometheus是一个开源的系统监控和报警工具。它由SoundCloud开发并于2012年发布,后来成为了一个独立的开源项目,并得到了广泛的应用和支持。
Prometheus的主要功能包括采集和存储各种系统和应用程序的监控数据,并提供强大的查询语言PromQL来分析和查询数据。它支持多种数据采集方式,包括主动式推送和被动式拉取。同时,Prometheus还提供了灵活的可视化和报警功能,用于监控系统的性能、负载、可用性等指标,并及时发出警报以便及时处理问题。
Prometheus以其可靠性、可扩展性和易于使用而受到广泛的欢迎和应用,被许多云原生应用和容器化环境所采用。它与其他工具和系统的集成也很方便,例如Grafana用于数据可视化、Alertmanager用于报警管理等。总的来说,Prometheus是一个功能强大的监控工具,适用于各种规模和类型的系统和应用。
下载prometheus
Download | Prometheus
Download | Prometheus
下载prometheus,解压,运行
./prometheus

并访问http://localhost:9090/进入主页
node_exporter
Node Exporter 是一个用于 Prometheus 监控系统的开源项目,用于收集和暴露有关主机操作系统(如 CPU、内存、磁盘、网络等)的相关指标。
Node Exporter 通过运行在受监控主机上的一个独立进程来收集系统资源使用情况。它会访问操作系统的各种接口和文件系统,如 `/proc`、`/sys`、`/procfs` 等,从中收集有关主机的性能指标。
一些 Node Exporter 支持的指标包括:
1. CPU 相关指标:包括 CPU 负载、各个 CPU 核心的使用率、中断次数等。
2. 内存相关指标:包括总内存、可用内存、内存使用率、缓存和缓冲区使用量等。
3. 磁盘相关指标:包括磁盘空间使用率、磁盘 I/O、磁盘队列长度等。
4. 网络相关指标:包括网络流量、连接数、网络错误等。
5. 系统负载和 Uptime 相关指标:包括系统平均负载、开机时间等。
Node Exporter 提供了一个 HTTP 接口,通过该接口可以将收集到的指标以 Prometheus 格式的样式暴露出来,从而使 Prometheus 可以定期抓取和存储这些指标,并进行进一步的分析和可视化。
在实际使用中,通常需要在要监控的主机上部署 Node Exporter,并在 Prometheus 配置文件中添加相应的 job 来监控该主机。这样,Prometheus 就可以通过 Node Exporter 收集并存储主机的指标数据,以供后续查询和监控使用。
服务器安装node_exporter
Exporter是Prometheus的指标数据收集组件。它负责从目标Jobs收集数据,并把收集到的数据转换为Prometheus支持的时序数据格式。 和传统的指标数据收集组件不同的是,他只负责收集,并不向Server端发送数据,而是等待Prometheus Server 主动抓取,node-exporter 默认的抓取url地址:http://ip:9100/metrics
文档:使用节点导出器监控 Linux 主机指标 |普罗 米修斯 (prometheus.io)
在需要监控的服务器上安装node_exporter
GitHub - prometheus/node_exporter: Exporter for machine metrics
Release 1.6.1 / 2023-06-17 · prometheus/node_exporter (github.com)
wget 对应版本的地址
tar xvfz node_exporter-*.*-amd64.tar.gz
cd node_exporter-*.*-amd64
chmod 777 node_exporter
./node_exporter
后台启动
要在Linux系统中以后台方式运行`./node_exporter`,你可以使用以下命令:
nohup ./node_exporter &
在这个命令中,`nohup` 表示忽略掉挂起信号,`&` 表示在后台运行命令。
这样做后,`./node_exporter` 将在后台一直运行,即使你退出当前的终端或者关闭SSH连接,它也会继续运行。你可以通过查看日志文件或进程查看程序的运行状态。

配置Prometheus
1、记事本打开prometheus.yml文件,增加配置
- job_name: 'linux-exporter'
metrics_path: /metrics
static_configs:
targets: ['服务器IP:9100']
重新启动prometheus.exe,访问http://localhost:9090/targets
观察对应服务器State状态为UP即为配置成功。
我这里端口没开,所以状态不对。
点进端点显示,metrics就是记录的服务器数据。

expression browser
在graph输入表达式,点击Execute可以看到结果
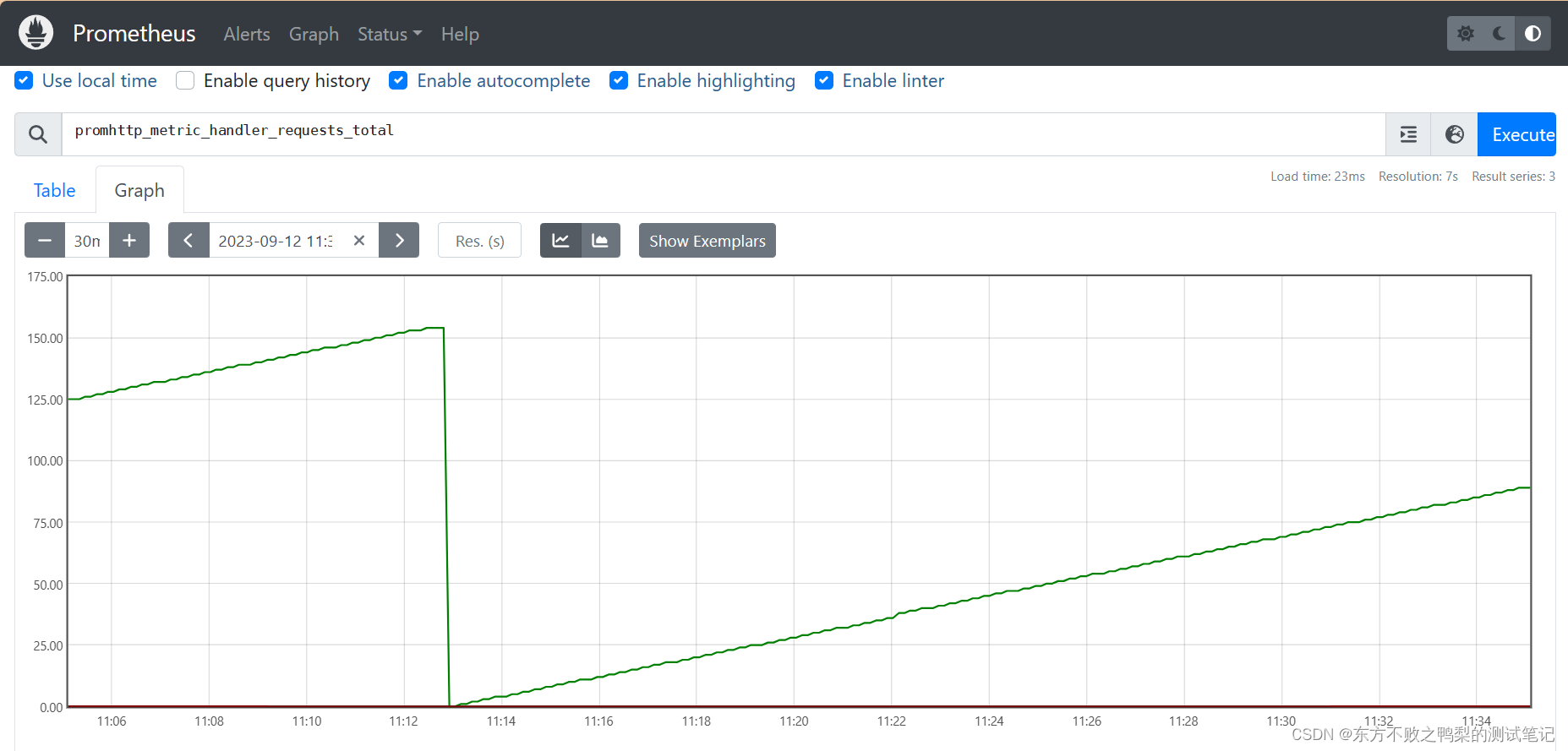
Prometheus 提供了一种名为 PromQL (Prometheus Query ) 的函数式查询语言 语言),允许用户实际选择和聚合时间序列数据 时间。表达式的结果可以显示为图形,查看为 普罗米修斯表达式浏览器中的表格数据,或外部使用的表格数据 系统通过 HTTP API
查询基础知识 |普罗 米修斯 (prometheus.io)
配置grafana并添加数据源
Grafana | Prometheus
1、进入grafana左侧工具栏点击Data Sources添加数据源
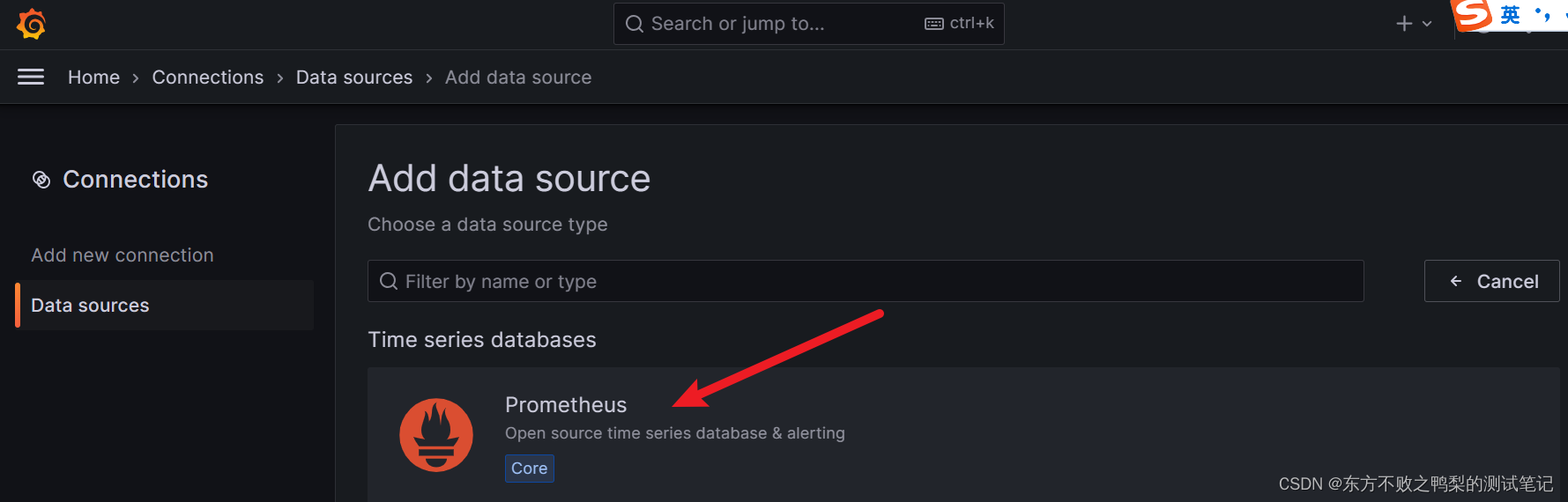


导入模板
模板资源:Dashboards | Grafana Labs
Grafana | Prometheus
模板ID号:12633,选择prometheus数据源。

因项目经常变更服务器,采用grafana及Prometheus本地安装。更换服务器只需在服务器安装node_exporter并配置Prometheus.yml即可实现对服务器的监控。
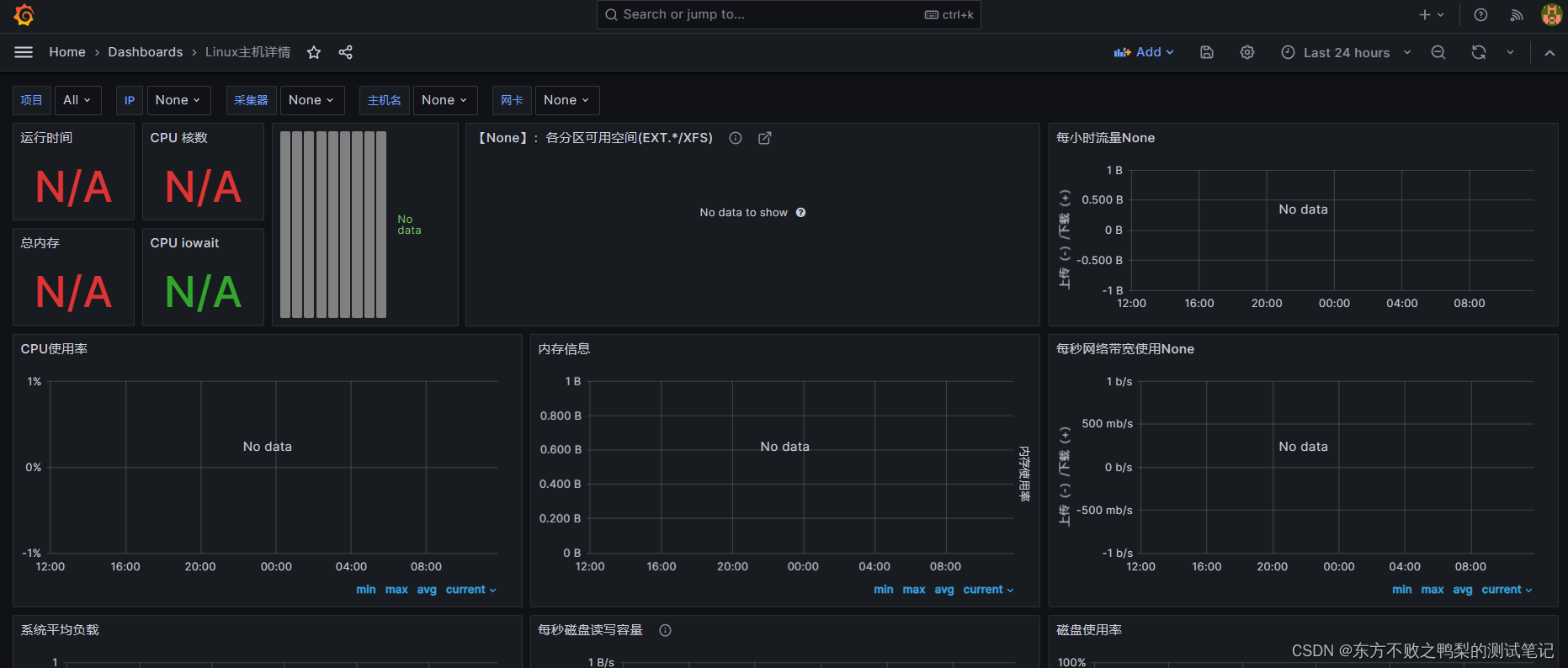
但是导入模板后,这里并没有显示数据。--后来发现是自己把prometheus里端口写错了,应该写node_Exporter的9100,写成了9090。
修改后数据可以看到了。
