索引
复杂情况下的多帧人体姿态估计是一种挑战。尽管最先进的人体关节检测器在静态图像上表现出了显著的效果,但当我们将这些模型应用于视频序列时,它们的表现就显得不足了。普遍存在的缺点包括无法处理运动模糊、视频失焦或姿势遮挡,这是因为无法捕捉到视频帧之间的时间依赖性。另一方面,直接采用传统的递归神经网络在空间背景建模方面存在经验上的困难,特别是在处理姿势遮挡方面。在本文中,我们提出了一个新的多帧人体姿势估计框架,利用视频帧之间丰富的时间线索来促进关键点检测。我们的框架中设计了三个模块化组件。姿势时间合并器对关键点的时空背景进行编码,以产生有效的搜索范围,而姿势残差融合模块则在两个方向计算加权姿势残差。然后通过我们的姿势校正网络处理这些数据,以有效地完善姿势估计。
介绍
在本文中,我们专注于视频序列中的多人姿态估计问题。传统的基于图像的方法忽略了视频帧间的时间依赖性和几何一致性。在处理视频序列中固有的挑战性情况(如运动模糊、视频失焦或姿势遮挡)时,忽略这些额外的线索会导致失败。有效地利用视频序列中的时间信息对于促进姿势估计具有重要意义,并且在检测严重遮挡或模糊的关节方面经常发挥不可或缺的作用。
[39]提出了一个3DHRNet(HRNet[33]的扩展,包括一个时间维度),用于提取跨视频帧的空间和时间特征来估计姿势序列。这个模型显示了出色的结果,特别是对于充分的长时间的单人序列。

图1. 我们的姿势时空合并(PTM)网络的图示。(a): 数据集中的原始视频序列,我们的目标是检测当前帧Fc中的姿势。(b): 原始视频序列中的每个人都被组合成一个裁剪过的片段,单人关节检测器给出了关键点热图的初步估计(右手腕的说明)。©-左。合并的右手腕关键点热图,由我们的PTM网络通过编码关键点的空间背景产生。颜色强度对空间聚集进行编码。©-右。合并的关键点热图的放大视图。
将双时空方向的连续帧纳入视频中,以改善姿势估计。我们的框架被称为姿势估计的双连续网络(DCPose)。首先将空间-时间关键点背景编码为本地化的搜索范围,计算姿势残差,并随后完善关键点热图估计。具体来说,我们在DCPose管道中设计了三个特定任务模块。1)如图1所示,一个姿势时间合并(PTM)网络在一个连续的视频片段(例如,三个连续的帧)上用分组卷积进行关键点聚合,从而定位关键点的搜索范围。2)引入姿势残差融合(PRF)网络,以有效获得当前帧和相邻帧之间的姿势残差。PRF通过明确利用时间距离来计算帧间关键点的偏移。3)最后,提出了一个由五个具有不同扩张率的平行卷积层组成的姿势校正网络(PCN),用于对局部搜索范围内的关键点热图进行重采样。
主要贡献
1)提出了一个新颖的双连续姿态估计框架。DCPose有效地结合了跨帧的双向时间线索,以促进视频中的多人姿势估计任务。2)我们在DCPose中设计了3个模块网络,以有效利用时间背景:i)一个新颖的姿势时间合并网络,用于有效聚合跨帧的关键点并确定搜索范围;ii)一个姿势残差融合网络,用于有效计算跨帧的加权姿势残差;以及iii)一个姿势校正网络,用于用完善的搜索范围和姿势残差信息更新姿势估算。
相关工作
[3]提出通过扭曲机制从稀疏标记的视频中学习一个有效的视频姿势检测器,结果非常成功,在PoseTrack排行榜上长期占据主导地位。[39]用时间卷积扩展了HRNet[33],并提出了3DHRNet,它在处理姿势估计和跟踪方面是成功的。
我们的方法

图2. 我们的DCPose框架的整体管道。我们的目标是定位当前帧Fc的关键点位置。首先,一个人i被组合成一个输入序列Clipi(p,c,n),一个HRNet骨干预测出初始关键点热图hi§,hi©,hi(n)。我们的姿势时间合并(PTM)和姿势残差融合(PRF)网络同时工作,分别获得有效的搜索范围Φi(p,c,n)和姿势残差Ψi(p,c,n)。然后,这些数据被送入我们的姿势校正网络(PCN),该网络完善了Fc中第i个人的关键点估计。
我们提出的DCPose的流水线如图2所示。为了改善当前帧Fc的关键点检测,我们利用了前一帧Fp和未来一帧Fn的额外时间信息。Fp和Fn是在帧窗口[c - T,c + T]内选择的,其中p∈[c - T,c]和n∈(c,c + T)分别表示帧的索引。Fc中单个人的边界框首先由人类探测器获得。每个边界框被放大25%,并进一步用于裁剪Fp和Fn中的同一个人。因此,视频中的个人i将由一个裁剪过的视频片段组成,我们将其表示为Clipi(p,c,n)。Clipi(p,c,n)然后被送入一个骨干网络,用于输出初步的关键点热图估计hi(p,c,n)。姿势热图hi(p,c,n)然后通过两个模块化网络并行处理,即姿势时空合并(PTM)和姿势残差融合(PRF)。PTM输出Φi(p,c,n),编码空间聚合,PRF计算Ψi(p,c,n),捕捉两个方向上的姿势残差。两个特征张量Φi(p,c,n)和Ψi(p,c,n)然后同时输入我们的姿势校正网络(PCN),以完善和改进初始姿势估计。在下文中,我们将详细介绍这三个关键部分。
姿势时空合并PTM
姿势时空合并PTM被用来编码基于初始预测(来自骨干网络)的关键点空间环境,提供一个压缩的搜索范围,便于在一个有限的范围内完善和纠正姿势预测。对于第i个人,骨干网络返回初始关键点热图hi§,hi©,hi(n)。直观地说,我们可以通过直接求和来合并它们 Hi(p,c,n) = hi§ + hi© + hi(n) 。然而,我们期望从Fp和Fn中提取的额外信息与它们与当前帧Fc的时间距离成反比。(即将较高的权重分配给在时间上离当前帧较近的帧。)可用以下公式表示

基于卷积操作用于调整(特征)权重的重要事实,我们利用卷积神经网络来实际实现公式1的想法。对于每个关节,我们只包括它自己的特定时间信息来计算其合并的关键点热图。这是通过一个组卷积实现的。我们将关键点热图hi§,hi©,hi(n)按照关节重新组合,并将它们堆积成一个特征张量φi,它可以表示为

其中⊕表示串联操作,上标j索引第j个关节,共N个关节。随后,特征张量φi被送入3×3残差块的堆栈(改编自RSN[4]中的残差步骤块),产生合并的关键点热图Φi(p,c,n)。

这种分组卷积不仅消除了不相关关节的干扰,而且还消除了冗余,缩小了所需的模型参数量。它也比直接对公式1中的关键点热图进行求和有优势,因为分组CNN操作允许在像素级有不同的权重,有利于学习端到端模型。图1显示了按照我们的PTM汇总的关键点热图的视觉结果。
姿势残差融合PRF
我们的姿势残差融合(PRF)分支旨在计算姿势残差,这将作为额外的有利的时间线索。鉴于关键点热图hi§,hi©,hi(n),我们计算姿势残差特征如下。
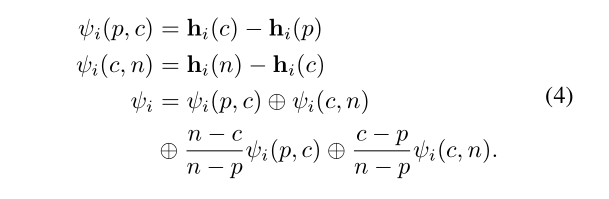
ψi将原始姿势残差ψi(p,c)、ψi(c,n)和它们的加权版本连接起来,其中的权重是根据时间距离得到的。与PTM类似,ψi然后通过3×3残余块的堆叠处理,得到最终的姿势残余特征Ψi(p,c,n)。
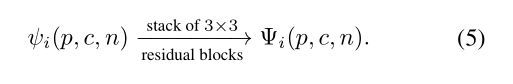
姿势校正网络
鉴于合并的关键点热图Φi(p,c,n)和姿势残余特征张量Ψi(p,c,n),我们的姿势校正网络被用来完善初始关键点热图估计hi©,产生调整后的最终关键点热图。首先,姿势残差特征张量Ψi(p,c,n)被用作五个平行的3×3卷积层的输入,其扩张率d∈{3,6,9,12,15}。这种计算为随后的可变形卷积层的五个内核提供了五组偏移量。从形式上看,这些偏移量的计算方法是:

不同的扩张率对应于改变有效接收场的大小,据此扩大扩张率[45]增加接收场的范围。较小的扩张率专注于局部外观,这对捕捉微妙的运动背景更为敏感。相反,使用大的扩张率可以让我们对全局表征进行编码,捕捉更大空间范围的相关信息。除了偏移计算外,我们还将合并的关键点热图送入类似的卷积层,并获得五套掩码Md,即。

用于计算偏移量O和掩码M的两个扩张卷积结构的参数是独立的。掩码Md可以被认为是卷积核的权重矩阵。
我们通过可变形卷积V 2网络(DCN v2 [49])在不同的扩张率d下实现姿势校正模块。 1) 合并的关键点热图Φi(p,c,n)。
2)内核偏移量Oi,d,和3)掩码Mi,d,并输出扩张率为d的人i的姿势热图。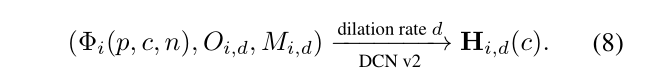
对五个扩张率的输出进行汇总和归一化,以得到人i的最终姿势预测。
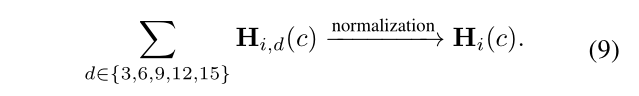
通过有效利用我们的DCPose框架中来自Fp和Fn的额外线索,最终的姿势热图得到增强和改进。
实施细节
我们的网络具有高度的适应性,我们可以无缝地整合任何基于图像的姿势估计架构作为我们的骨干。我们采用最先进的深层高分辨率网络(HRNet-W48[33])作为我们的骨干关节检测器,因为它在单幅图像姿势估计方面的卓越性能将有利于我们的方法。
训练 我们的深度双连续网络是在PyTorch中实现的。在训练过程中,我们使用地面真实的人的边界框来生成人i的Clipi(p,c,n)作为我们模型的输入序列。对于边界情况,我们应用同样的填充。换句话说,如果没有帧可以从Fc向前和向后延伸,Fp或Fn将被Fc所取代。我们利用在PoseTrack数据集上预训练的HRNetW48作为骨干,并在整个训练过程中冻结骨干参数,只通过DCPose中的后续组件进行反向传播。
损失函数 我们采用标准姿势估计损失函数作为我们的成本函数。训练的目的是最小化所有关节的预测和地面真实热图之间的总欧氏或L2距离。成本函数定义为:
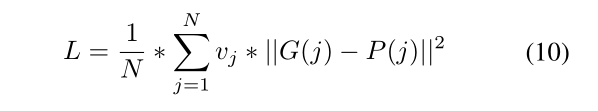
其中G(j)、P(j)和vj分别表示地面真实热图、预测热图和关节j的可见度。在训练期间,关节的总数被设定为N=15。地面真相热图是通过以关节位置为中心的二维高斯生成的
实验
介绍了我们在两个大规模基准数据集上的实验结果。Posetrack2017和PoseTrack2018多帧人物姿态估计挑战数据集。
参数设置
在训练过程中,我们加入了数据增强,包括随机旋转、缩放、截断和水平翻转以增加变化。输入图像大小固定为384×288。Fc和Fp或Fn之间的默认间隔被设置为1。骨干参数被固定为预训练的HRNet-W48模型权重。所有后续的权重参数都从高斯分布中初始化,µ=0,σ=0.001,而偏置参数初始化为0。我们采用Adam优化器,基础学习率为0.0001,每4个历时衰减10%。我们用2个Nvidia GeForce Titan X GPU训练我们的模型,批次大小为32,共20个历时
与最先进方法的比较
PoseTrack2017数据集上的结果 我们使用广泛采用的平均精度(AP)指标[43, 44, 11, 47]在PoseTrack2017验证集和完整测试集上评估我们的方法。表1列出了不同方法在PoseTrack2017验证集上的平均精度方面的定量结果。我们将我们的DCPose模型与现有的八种方法[44]、[11]、[47]、[43]、[16]、[33]、[13]、[3]进行比较。在表1中,报告了关键关节的AP,如头部、肩部、膝部和肘部,以及所有关节的mAP(平均AP)。
表2中提供了测试集的结果。这些结果是通过将我们的预测结果上传到PoseTrack评估服务器:https://posetrack. net/leaderboard.php获得的,因为测试集的注释并不公开。我们的DCPose网络在验证集和测试集的多帧人物姿势估计挑战中都取得了最先进的结果。DCPose的性能一直优于现有的方法,并达到了79.2的mAP。对相对困难的关节的性能提升也是令人鼓舞的:我们对手腕的mAP为76.1,对踝关节的mAP为71.2。一些样本结果显示在图3中,这表明了我们的方法在复杂场景中的有效性。更多可视化的结果可以在https://github.com/Pose-Group/DCPose.
PoseTrack2018数据集上的结果 我们还在PoseTrack2018数据集上评估我们的模型。验证和测试集的AP结果分别列在表3和表4中。如表所示,我们的方法再一次提供了最先进的结果。我们在测试集上实现了79.0的mAP,在困难的腕关节上获得了77.2的mAP,在踝关节上获得了72.3。
我们研究了对PCN中的卷积采用不同的扩张率集的效果。这对应于不同的有效接收场。我们实验了四种不同的扩张设置:d=3,d∈{3,6},d∈{3,6,9}和d∈{3,6,9,12},而完整的DCPose框架设置有d∈{3,6,9,12,15}。从表5的结果中,我们观察到mAP随着d的增加而逐渐改善
结论
我们提出了一种用于多帧人物姿势估计的双连续网络,它在基准数据集上的表现明显优于现有的最先进方法。我们设计了一个姿势时间合并模块和一个姿势残差融合模块,允许从相邻的帧中提取丰富的辅助信息,为位置关键点提供一个本地化和姿势残差校正的搜索范围。我们的姿势校正网络采用了多个有效的感受场来完善这个搜索范围内的姿势估计,取得了明显的改进,并且能够处理复杂的场景。
References
[1] Mykhaylo Andriluka, Umar Iqbal, Eldar Insafutdinov, Leonid Pishchulin, Anton Milan, Juergen Gall, and Bernt Schiele. Posetrack: A benchmark for human pose estimation and tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018. 6
[2] Bruno Artacho and Andreas Savakis. Unipose: Unified human pose estimation in single images and videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7035–7044, 2020. 3
[3] Gedas Bertasius, Christoph Feichtenhofer, Du Tran, Jianbo Shi, and Lorenzo Torresani. Learning temporal pose estimation from sparsely-labeled videos. In Advances in Neural Information Processing Systems, pages 3027–3038, 2019. 2, 3, 5, 6, 8
[4] Yuanhao Cai, Zhicheng Wang, Zhengxiong Luo, Binyi Yin, Angang Du, Haoqian Wang, Xinyu Zhou, Erjin Zhou, Xiangyu Zhang, and Jian Sun. Learning delicate local representations for multi-person pose estimation. arXiv preprint arXiv:2003.04030, 2020. 4
[5] Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017. 1, 3
[6] Joao Carreira, Pulkit Agrawal, Katerina Fragkiadaki, and Jitendra Malik. Human pose estimation with iterative error feedback. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4733–4742,
2016. 3
[7] Bowen Cheng, Bin Xiao, Jingdong Wang, Honghui Shi, Thomas S Huang, and Lei Zhang. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5386–5395, 2020. 3
[8] Zhiyong Cheng, Ying Ding, Xiangnan He, Lei Zhu, Xuemeng Song, and Mohan S. Kankanhalli. Aˆ3ncf: An adaptive aspect attention model for rating prediction. In IJCAI, pages 3748–3754, 2018. 3
[9] Xiao Chu, Wei Yang, Wanli Ouyang, Cheng Ma, Alan L Yuille, and Xiaogang Wang. Multi-context attention for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1831– 1840, 2017. 1
[10] Matthias Dantone, Juergen Gall, Christian Leistner, and Luc Van Gool. Human pose estimation using body parts dependent joint regressors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3041– 3048, 2013. 2
[11] Andreas Doering, Umar Iqbal, and Juergen Gall. Joint flow: Temporal flow fields for multi person tracking. arXiv preprint arXiv:1805.04596, 2018. 5, 6
[12] Hao-Shu Fang, Shuqin Xie, Yu-Wing Tai, and Cewu Lu. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Oct 2017. 1, 3, 4, 5, 6
[13] Hengkai Guo, Tang Tang, Guozhong Luo, Riwei Chen, Yongchen Lu, and Linfu Wen. Multi-domain pose network for multi-person pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), pages 0–0, 2018. 5, 6
[14] Junjie Huang, Zheng Zhu, Feng Guo, and Guan Huang. The devil is in the details: Delving into unbiased data processing for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5700–5709, 2020. 3
[15] Umar Iqbal, Anton Milan, and Juergen Gall. Posetrack: Joint multi-person pose estimation and tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017. 6
[16] Sheng Jin, Wentao Liu, Wanli Ouyang, and Chen Qian. Multi-person articulated tracking with spatial and temporal embeddings. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5664– 5673, 2019. 5, 6
[17] Muhammed Kocabas, Salih Karagoz, and Emre Akbas. Multiposenet: Fast multi-person pose estimation using pose residual network. In Proceedings of the European conference on computer vision (ECCV), pages 417–433, 2018. 3
[18] Sven Kreiss, Lorenzo Bertoni, and Alexandre Alahi. Pifpaf: Composite fields for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 11977–11986, 2019. 3
[19] Jiefeng Li, Can Wang, Hao Zhu, Yihuan Mao, Hao-Shu Fang, and Cewu Lu. Crowdpose: Efficient crowded scenes pose estimation and a new benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 10863–10872, 2019. 3
[20] Kyaw Zaw Lin, Weipeng Xu, Qianru Sun, Christian Theobalt, and Tat-Seng Chua. Learning a disentangled embedding for monocular 3d shape retrieval and pose estimation. arXiv preprint arXiv:1812.09899, 2018. 3
[21] Anan Liu, Zhongyang Wang, Weizhi Nie, and Yuting Su. Graph-based characteristic view set extraction and matching for 3d model retrieval. Information Sciences, 320:429–442, 2015. 3
[22] An-An Liu, Yu-Ting Su, Wei-Zhi Nie, and Mohan Kankanhalli. Hierarchical clustering multi-task learning for joint human action grouping and recognition. IEEE transactions on pattern analysis and machine intelligence, 39(1):102–114,
2016. 1
[23] Zhenguang Liu, Kedi Lyu, Shuang Wu, Haipeng Chen, Yanbin Hao, and Shouling Ji. Aggregated multi-gans for controlled 3d human motion prediction. 2021. 1
[24] Zhenguang Liu, Shuang Wu, Shuyuan Jin, Qi Liu, Shijian Lu, Roger Zimmermann, and Li Cheng. Towards natural and accurate future motion prediction of humans and animals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10004–10012, 2019. 1
[25] Yue Luo, Jimmy Ren, Zhouxia Wang, Wenxiu Sun, Jinshan Pan, Jianbo Liu, Jiahao Pang, and Liang Lin. Lstm pose machines. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5207–5215, 2018. 1, 3
[26] Gyeongsik Moon, Ju Yong Chang, and Kyoung Mu Lee.
Posefix: Model-agnostic general human pose refinement network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7773–7781, 2019. 3
[27] Alejandro Newell, Kaiyu Yang, and Jia Deng. Stacked hourglass networks for human pose estimation. In European conference on computer vision, pages 483–499. Springer, 2016. 1, 3
[28] Tomas Pfister, James Charles, and Andrew Zisserman. Flowing convnets for human pose estimation in videos. In Proceedings of the IEEE International Conference on Computer Vision, pages 1913–1921, 2015. 2, 3
[29] Benjamin Sapp, Alexander Toshev, and Ben Taskar. Cascaded models for articulated pose estimation. In European conference on computer vision, pages 406–420. Springer, 2010. 1, 2
[30] Michael Snower, Asim Kadav, Farley Lai, and Hans Peter Graf. 15 keypoints is all you need. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6738–6748, 2020. 5
[31] Jie Song, Limin Wang, Luc Van Gool, and Otmar Hilliges. Thin-slicing network: A deep structured model for pose estimation in videos. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4220–4229, 2017. 2, 3
[32] Kai Su, Dongdong Yu, Zhenqi Xu, Xin Geng, and Changhu Wang. Multi-person pose estimation with enhanced channelwise and spatial information. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5674–5682, 2019. 3
[33] Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5693–5703, 2019. 2, 3, 4, 5, 6, 8
[34] Min Sun, Pushmeet Kohli, and Jamie Shotton. Conditional regression forests for human pose estimation. In 2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 3394–3401. IEEE, 2012. 2
[35] Kaihua Tang, Hanwang Zhang, Baoyuan Wu, Wenhan Luo, and Wei Liu. Learning to compose dynamic tree structures for visual contexts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6619– 6628, 2019. 3
[36] Alexander Toshev and Christian Szegedy. Deeppose: Human pose estimation via deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2014. 1
[37] Ali Varamesh and Tinne Tuytelaars. Mixture dense regression for object detection and human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13086–13095, 2020. 3
[38] Fang Wang and Yi Li. Beyond physical connections: Tree models in human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 596–603, 2013. 1, 2
[39] Manchen Wang, Joseph Tighe, and Davide Modolo. Combining detection and tracking for human pose estimation in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11088– 11096, 2020. 2, 4, 5, 6
[40] Yang Wang and Greg Mori. Multiple tree models for occlusion and spatial constraints in human pose estimation. In European Conference on Computer Vision, pages 710–724. Springer, 2008. 1, 2
[41] Shih-En Wei, Varun Ramakrishna, Takeo Kanade, and Yaser Sheikh. Convolutional pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016. 1, 3
[42] Philippe Weinzaepfel, Jerome Revaud, Zaid Harchaoui, and Cordelia Schmid. Deepflow: Large displacement optical flow with deep matching. In Proceedings of the IEEE international conference on computer vision, pages 1385–1392, 2013. 3
[20] Kyaw Zaw Lin, Weipeng Xu, Qianru Sun, Christian Theobalt, and Tat-Seng Chua. Learning a disentangled embedding for monocular 3d shape retrieval and pose estimation. arXiv preprint arXiv:1812.09899, 2018. 3
[21] Anan Liu, Zhongyang Wang, Weizhi Nie, and Yuting Su. Graph-based characteristic view set extraction and matching for 3d model retrieval. Information Sciences, 320:429–442, 2015. 3
[22] An-An Liu, Yu-Ting Su, Wei-Zhi Nie, and Mohan Kankanhalli. Hierarchical clustering multi-task learning for joint human action grouping and recognition. IEEE transactions on pattern analysis and machine intelligence, 39(1):102–114,
2016. 1
[23] Zhenguang Liu, Kedi Lyu, Shuang Wu, Haipeng Chen, Yanbin Hao, and Shouling Ji. Aggregated multi-gans for controlled 3d human motion prediction. 2021. 1
[24] Zhenguang Liu, Shuang Wu, Shuyuan Jin, Qi Liu, Shijian Lu, Roger Zimmermann, and Li Cheng. Towards natural and accurate future motion prediction of humans and animals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10004–10012, 2019. 1
[25] Yue Luo, Jimmy Ren, Zhouxia Wang, Wenxiu Sun, Jinshan Pan, Jianbo Liu, Jiahao Pang, and Liang Lin. Lstm pose machines. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5207–5215, 2018. 1, 3
[26] Gyeongsik Moon, Ju Yong Chang, and Kyoung Mu Lee.
Posefix: Model-agnostic general human pose refinement network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7773–7781, 2019. 3
[27] Alejandro Newell, Kaiyu Yang, and Jia Deng. Stacked hourglass networks for human pose estimation. In European conference on computer vision, pages 483–499. Springer, 2016. 1, 3
[28] Tomas Pfister, James Charles, and Andrew Zisserman. Flowing convnets for human pose estimation in videos. In Proceedings of the IEEE International Conference on Computer Vision, pages 1913–1921, 2015. 2, 3
[29] Benjamin Sapp, Alexander Toshev, and Ben Taskar. Cascaded models for articulated pose estimation. In European conference on computer vision, pages 406–420. Springer, 2010. 1, 2
[30] Michael Snower, Asim Kadav, Farley Lai, and Hans Peter Graf. 15 keypoints is all you need. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6738–6748, 2020. 5
[31] Jie Song, Limin Wang, Luc Van Gool, and Otmar Hilliges. Thin-slicing network: A deep structured model for pose estimation in videos. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4220–4229, 2017. 2, 3
[32] Kai Su, Dongdong Yu, Zhenqi Xu, Xin Geng, and Changhu Wang. Multi-person pose estimation with enhanced channelwise and spatial information. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5674–5682, 2019. 3
[33] Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5693–5703, 2019. 2, 3, 4, 5, 6, 8
[34] Min Sun, Pushmeet Kohli, and Jamie Shotton. Conditional regression forests for human pose estimation. In 2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 3394–3401. IEEE, 2012. 2
[35] Kaihua Tang, Hanwang Zhang, Baoyuan Wu, Wenhan Luo, and Wei Liu. Learning to compose dynamic tree structures for visual contexts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6619– 6628, 2019. 3
[36] Alexander Toshev and Christian Szegedy. Deeppose: Human pose estimation via deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2014. 1
[37] Ali Varamesh and Tinne Tuytelaars. Mixture dense regression for object detection and human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13086–13095, 2020. 3
[38] Fang Wang and Yi Li. Beyond physical connections: Tree models in human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 596–603, 2013. 1, 2
[39] Manchen Wang, Joseph Tighe, and Davide Modolo. Combining detection and tracking for human pose estimation in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11088– 11096, 2020. 2, 4, 5, 6
[40] Yang Wang and Greg Mori. Multiple tree models for occlusion and spatial constraints in human pose estimation. In European Conference on Computer Vision, pages 710–724. Springer, 2008. 1, 2
[41] Shih-En Wei, Varun Ramakrishna, Takeo Kanade, and Yaser Sheikh. Convolutional pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016. 1, 3
[42] Philippe Weinzaepfel, Jerome Revaud, Zaid Harchaoui, and Cordelia Schmid. Deepflow: Large displacement optical flow with deep matching. In Proceedings of the IEEE international conference on computer vision, pages 1385–1392, 2013. 3