ASD是一种以大脑为基础的疾病,其特征是社会缺陷和重复行为。根据美国疾病控制中心最近的数据,美国68名儿童中就可能有1名患有自闭症。本研究的目的是基于深度学习算法从大型脑成像数据集中识别自闭症谱系障碍(ASD)患者。本文调查了一个ASD患者的大脑成像数据,该数据来自一个名为EXVIDE(自闭症大脑成像数据交换)的全球多站点数据库。
本文主要从功能性脑成像数据中客观识别ASD参与者的功能连接模式,并试图揭示在分类中有意义的神经模式。本文对ASD患者的分类正确率可以达到70%,这一结果提高了使用深度学习方法对ASD患者识别的最新水平。分类结果显示,大脑前部和后部区域之间的大脑功能存在负相关;这种负相关性证实了目前ASD患者大脑连接在前顶叶中断的经验证据。本文为使用深度学习方法来获取ASD疾病的生物标记物做出了进一步的贡献。本文发表在NeuroImage: Clinical杂志。
引言
神经影像学研究的主要目标是识别客观的生物标记物,这些生物标记物可能为脑疾病的诊断和治疗提供信息。数据密集型的机器学习方法有望成为一种很有前景的工具,可用于研究大脑功能模式在更大、更异构的数据集上的可重复性。本研究的第一个目标是利用静息状态功能磁共振成像(rs-fMRI)数据,根据自闭症谱系障碍(ASD)和对照组各自的神经功能连接模式对其进行分类。本文使用了一种结合有监督和无监督机器学习(ML)方法的深度学习方法。该方法被应用于一个大样本人群的大脑成像数据,即ABIDE数据库。第二个目标是研究与ASD相关的神经模式,确定哪些连接模式对分类贡献最大;这些结果是根据大脑各区域的网络来解释的,可以将ASD与对照组和以前的ASD脑功能研究区分开来。
已有研究表明,ASD与一系列表型相关,这些表型在社会表现、交流和感觉运动缺陷的严重程度上各不相同。ASD诊断工具仅能用来评估特征性社会行为和语言技能。然而,神经科学研究有助于弥补自闭症行为改变的复杂性及其神经模式之间的鸿沟。无创脑成像研究促进了对脑疾病及其相关行为的神经基础的理解,如自闭症及其社交和沟通缺陷。ASD激活模式的识别以及模式与神经和心理的相关性有助于理解精神障碍的病因。
大脑疾病的脑成像研究面临的挑战之一是在更大、更具人口统计学异质性的数据集中可重复性研究结果,以反映临床人群的异质性。最近,ML算法已被应用于脑成像数据,以提取可重复的脑功能模式。这些算法可以从精神障碍患者的脑成像数据中提取可复制、鲁棒的神经模式特征。
机器学习和疾病状态预测:理解大脑和精神疾病的下一个前沿
机器学习方法与大脑成像数据的结合允许对与语义类别和情绪表示相关的心理状态进行分类和学习。在精神疾病状态的情况下,研究已经确定了与精神分裂症、自闭症和抑郁症相关的脑激活模式。将ML算法应用于ASD脑成像数据的研究,从功能磁共振成像(fMRI)脑激活的数据中可以将个体分为自闭症患者或对照组,识别准确率高达97%。他们还发现了与心理因素(自我表征)相关的大脑激活模式。对照组患者存在这种模式,自闭症患者几乎没有这种模式。另一项ASD参与者分类研究中,在178名ASD和IQD人群样本中,获得76.67%的分类准确率。将监督ML应用于大脑成像数据的研究的一个挑战是,参与者数量相对较少。Arbabshirani等人表明,ML研究的可靠分类准确度是通过少于100名参与者的群体样本获得的,也就是说,获得90%以上的分类准确率是只有在对几十名参与者进行研究的情况下获得的。如果数据来自不同地点,在较大的总体样本中,分类准确率会显著下降。
大多数结合大脑成像和机器学习的研究都应用了监督学习方法,如支持向量机(SVM)或高斯朴素贝叶斯(GNB)分类器。有监督机器学习方法的特征选择的主观性可能是研究的局限性。在有监督方法中,类标签被分配给用作训练数据集的一组数据;其他数据点(测试数据集)根据训练数据中发现的模式进行分类(使用给定的标签)。换句话说,该算法用于对预先建立的标签进行分类(即,它们依赖于特征选择)。这些标签和特征的选择取决于先验假设;因此,它们取决于一定程度的主观性。例如,在探索100、200、400和更多体素集合并确定最适合分类的集合大小的基础上,根据经验选择了适合脑成像数据分类的体素数量。
在本研究中,作者们通过使用大数据集和无监督机器学习方法对精神障碍进行分类,来解决普遍性和主观偏倚性的问题。减少特征提取中的主观性可能会提供一个了解大脑功能的新发现,该研究较少依赖于实验者的主观性,更多地由数据驱动。
ABIDE数据库分类
Nielsen等人曾使用这些数据根据大脑连接性测量对自闭症和对照组受试者进行分类。作者复制了Anderson等人的研究方法,并对其进行了修改,包括来自多个站点的数据集。对于本文使用的964名受试者,计算了由至少相隔5mm的体素形成的非重叠灰质ROI(SPM8 mask grey.nii)的BOLD信号。基于7266个生成的ROI数据,Nielsen 等通过计算每个ROI之间的成对相关性,得到了大小为7266×7266的连通矩阵。采用留一的方法,对每组(ASD和对照组)建立一个通用线性模型,将连通矩阵与受试者相关变量(年龄、性别和惯用手)相关联。然后使用一个点连接的平均值与另一个点相同连接的平均值之间的差值对其进行调整。该步骤缓解了可能导致结果偏差的站点之间的差异,例如不同的扫描仪以及扫描参数和协议的变化。
作者试图适应多站点数据和数据中存在的差异来源。对于被忽略的受试者,从自闭症模型和对照模型获得的估计值中减去每个连接的实际值。计算所有7266个ROI的平均值,并将ROI的平均值相加,阳性值分作为ASD,阴性值作为对照。Nielsen等人(2013年)获得了与对照组相比高达60%的ASD分类准确率。最近,Abraham等人(2017年)获得了截至本论文的最高分类准确率。通过构建特定于参与者的功能连接矩阵(连接组),作者在完整数据集中实现了67%的准确率。本研究中旨在提高当前已获得的最高精确度。
神经影像学和深度学习算法
Koyamada等人(2015年)利用深度神经网络(DNN)从可测量的大脑活动中研究了大脑状态。他们训练了一个具有两个隐藏层和一个softmax输出层的人工神经网络,将499名受试者的基于任务的功能磁共振成像数据分为七类:情绪、赌博、语言、运动、关系、社会和工作记忆。与线性回归和支持向量机等监督学习方法(平均准确度47.97%)相比,深度学习模型可以获得更好的结果(平均准确度50.74%)。Plis等人(2014年)使用来自四个不同地点的数据,利用深度学习和结构T1加权图像对精神分裂症患者与匹配的健康对照组进行分类;作者还使用PREDICT-HD项目(www.PREDICT http://HD.net)结合的数据将亨廷顿病患者与健康对照组进行了分类。首先,他们试图从约翰霍普金斯大学(JHU)、马里兰精神病研究中心(MPRC)、精神病研究所、英国伦敦(IOP)和匹兹堡大学(WPIC)的西方精神病研究所和诊所进行的四个不同的研究对198名精神分裂症患者和191名对照者进行分类。Plis等人训练了一个具有3个深度的深度信念网络(DBMs,深度信念网络是一个概率生成模型,与传统的判别模型的神经网络相对,生成模型是建立一个观察数据和标签之间的联合分布,对P(Observation|Label)和 P(Label|Observation)都做了评估,而判别模型仅仅而已评估了后者)(第一层50个隐藏单位,第二层50个,顶层100个)。他们使用从三个DBMs中提取的特征实现了90%的分类准确率,而使用支持向量机中的原始数据仅实现了68%的分类准确率。作者得出结论,深度学习在临床脑成像应用中具有巨大潜力。
第二部分工作使用了从PREDICT-HD项目的健康对照组和亨廷顿病患者收集的数据。这项研究的目的是利用深度学习技术识别疾病,并评估疾病的严重程度(低、中、高)。这项研究使用了来自不同国家32个站点的T1加权结构扫描数据集。这组包括来自患者的2641张图像和来自健康对照组的859张图像。作者在第一层、第二层和顶层分别应用了一个深度为50-50-100个隐藏单元的深度信念网络(DBM)。采用t分布随机邻域嵌入(t-SNE)(Maaten等人,2008年)技术将结果数据简化为二维平面;结果显示,患者和对照组之间存在线性分离边界。
深度学习算法使大脑成像数据的分类比严格监督的方法更进一步。算法在学习模型中使用复杂的数据表示。深度学习算法通过使用无监督学习方法,依靠最少的人为干预来提取相关特征。使用无监督方法对临床人群进行分类,可以探索性地搜索精神疾病的神经模式,而不太依赖于特征选择的假设;因此,它可能不太容易受到类别错误的影响。在有监督的方法中,假定的标签用于训练分类器,并找到与标签相关的大脑激活或连接模式(例如,临床人群和对照人群样本)。在无监督的方法中,分类器探索人群样本中可能与临床人群相关的大脑模式;同样,避免了标签选择的主观性(Plis等人,2014)。有研究者认为,主观程度较低且可能更自由的深度学习算法有望将机器学习应用于多站点存储库中的大数据集。
材料和方法
参与者
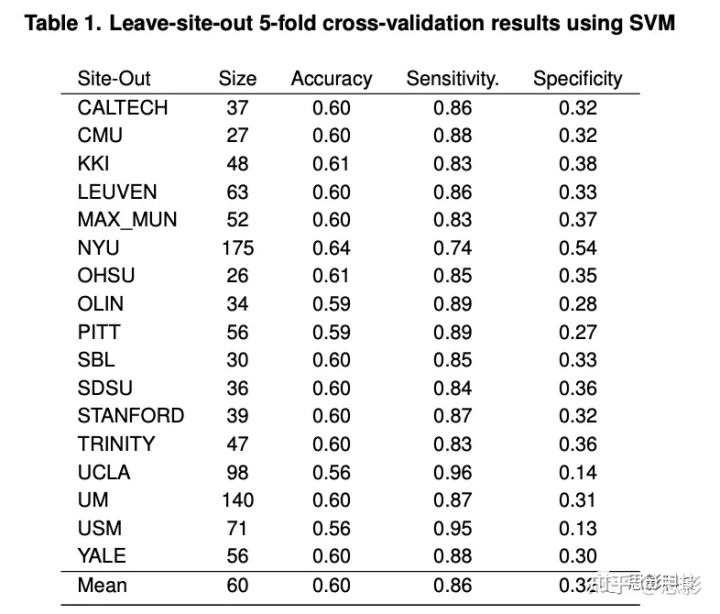
本研究采用自闭症影像数据交换数据库(ADVICE I)中的rs-fMRI数据进行。ABIDE是一个公开共享数据集,提供先前收集的ASD和匹配的对照组rs-fMRI数据。我们纳入了505名ASD患者和530名匹配对照的数据。数据集收集于17个不同的成像中心,包括rs-fMRI、T1结构脑图像和每位患者的表型信息,总结见表1。表1包含关键的表型信息,包括ASD和TC的性别和年龄分布,ASD受试者的ADOS量表评分,以及平均帧向位移(FD)的头动测量。
静息态与特征选择
静息状态功能磁共振成像提供大脑各区域之间功能关系的神经测量。静息态功能磁共振成像数据对于临床人群的调查特别有用。它允许在不增加与任务相关的大脑激活相关的变异复杂性的情况下调查大脑网络的损坏。它可以应用于精神状态、记忆和事件回忆、临床人群等的调查。静息态功能磁共振成像已被证明具有高度的可重复性,并提供了易于跨研究进行比较的数据集(Franco等人,2013年;Shehzad等人,2009年)。静息状态功能磁共振成像上低频波动的相关性源于血液氧合的波动。这是大脑功能连通性的表现(Biswal等人,1995年)。为了研究大脑连接性,可以计算感兴趣区域时间序列平均值的相关性来构建连通性矩阵。
数据处理
对fMRI数据进行切片时间校正、运动校正,并对体素强度进行归一化。使用24个运动参数、具有5个分量的CompCor(Behzadi等人,2007)、低频漂移(线性和二次趋势)以及全局信号作为协变量,去除干扰信号。功能数据进行带通滤波(0.01–0.1 Hz),并使用非线性方法在模板空间(MNI152)进行空间配准。
提取每个受试者感兴趣区域的平均时间序列。使用CC200大脑功能分区图谱(Craddock和James,2012)选择特征向量(见下文)。该图谱是通过数据驱动的将整个大脑划分为空间上相近的同质功能活动区域生成的,共分为200个区域。
特征选择:功能连接的感兴趣区
功能连通性用于区分ASD和TC。功能连接性根据静息态功能磁共振脑成像数据的时间序列提供了大脑区域之间的共同激活水平。连通矩阵中的每个单元都包含一个皮尔逊相关系数。该系数是大脑两个区域之间相关性的指数,范围从1到−1:接近1的值表示时间序列高度相关;接近于−1表示时间序列是负相关的。
为了将相关矩阵中的值用作特征,删除了上三角值和对角线。之后,将其转为一维向量,以检索特征向量,目的是将其用于分类。合成特征的数量由以下等式定义:
S=(N−1)N/2
其中N是相关体素或区域的数量。使用了CC200 ROI图谱,该程序产生了19900个特征。
分类方法
基于降噪自动编码器训练预测模型,使其具有更好的泛化能力,可以对初始参与者之外的新的测试组进行准确分类。降噪自动编码器为了防止过拟合问题而对输入的数据(网络的输入层)加入噪音,使学习得到的编码器W具有较强的鲁棒性,从而增强模型的泛化能力。(Denoising Auto-encoder是Bengio在08年提出的,具体内容可参考其论文:Extracting and composing robust features with denoising autoencoders.)
在本研究中,我们在无监督的预训练阶段使用两个叠加降噪自动编码器从数据中提取低维信息。将正确率作为在验证集评估模型优劣的指标;在训练集做 K折交叉验证。输入层和输出层具有19900个单元,完全连接到隐藏层1000个单元。第一个自动编码器的数据学习率设置为20%(符合二项分布:n=1,p=0.8)。第二个自动编码器通过600个单元的隐藏层将前一个自动编码器输出的1000个输入映射到输出。第二个自动编码器被参数化,以30%的学习率概率提取特征(符合二项分布:n=1,p=0.7)。
自动编码器的无监督训练一次进行一层。为了利用自动编码器提取特征,我们将编码器权重配置为19900-1000-600-2的多层感知器(MLP)。换句话说,MLP假设输入空间为19900个特征,输出空间为2个数字,如下所述。在输入层和输出层之间,网络有两个隐藏层,分别为1000和600个单元。该过程在图1和2中表示:蓝色和绿色权重包含无监督训练编码器;图2包含使用来自自动编码器训练的先验知识的监督训练的多层感知器。MLP包含基于自动编码器的调整权重;因此,它的监督训练被称为微调。微调的目标是调整MLP权重以输出预期类,并最小化监督任务的预测误差。输出层包含两个输出单元:每个单元表示输入来自ASD或TC的概率。这种类型的输出称为一独热输出:在微调过程中,预计只有一个输出的激活值为1(其他为0);应用softmax函数获得输出。Softmax函数规范化了输出分布,因此输出表示一类的互补概率(即ASD或TC概率之和;例如,ASD概率为80%,TC概率为20%)。
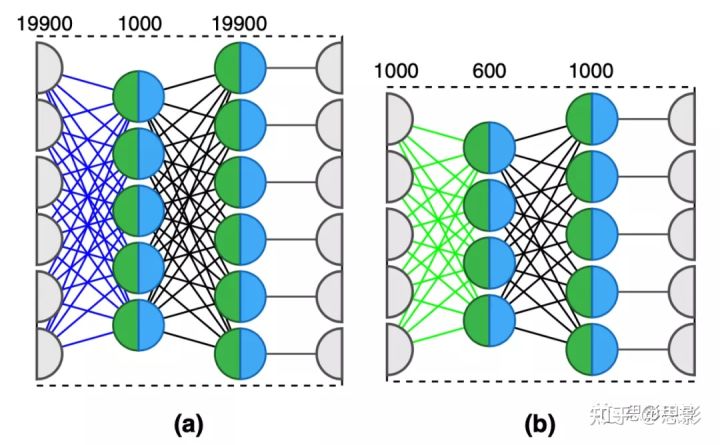
图1,两个自动编码器结构。为了简化结构的可视化,我们减少了单元的数量。(a) :19900-1000-19900;(b) :1000-600-1000

图2,将学习从自动编码器AE1和AE2转移到神经网络分类器。
5.6 分类评估
为了评估通过深度学习获得的结果,将该模型的性能与使用支持向量机(SVM)(Vapnik,1998)和随机森林(RF)训练的分类器的结果进行比较。所有模型的评估都基于10折交叉验证,该方法混合了所有17个站点的数据,同时保持不同站点之间的比例。使用预训练、无监督过程的编码器实现数据降维。表2总结了我们在下面描述的结果。
我们报告了所有分类器的准确性、敏感性和特异性,以及训练每个模型所需的总时间。
表2,在整个数据集上比较使用10折交叉验证训练的深度神经网络(DNN)、随机森林(RF)和支持向量机(SVM)分类器的性能。

6. 结果和讨论
深度神经网络在所有折交叉验证中的平均分类准确率为70%(敏感性74%,特异性63%),在单个折中的准确率范围为66%至71%。根据文献,这是迄今为止实现的最高的分类正确率。SVM分类器的平均准确率为65%(从62%到72%,敏感性68%,特异性62%);而随机森林分类器的平均准确率为63%(敏感性69%,特异性58%)。结果表明,深度学习算法在多站点数据中对ASD和典型参与者的分类高于偶然性。结果还表明,该算法优于用于比较的其他监督方法。但缺点是训练时间很长。尽管使用了专用的GPU来加速训练,训练的模型具有更高的精确度,但训练时间却付出了巨大的代价。使用两个Intel Xeon E5-2620处理器(24核运行频率为2 GHz,内存为48 GB)和一个特斯拉K40 GPU(2880 CUDA核,内存为12 GB),整个型号的训练耗时超过32小时。
结果表明,该算法的应用优于以往自闭症谱系障碍多部位静息状态脑激活患者识别研究的结果。补充材料中显示了使用其他脑分区的结果。通过使用自动编码器降低数据维数,SVM分类的结果没有变化。我们将支持向量机应用于使用自动编码器学习的降维上,而无需微调过程。降维产生了较低的SVM分类结果(使用第一个自动编码器进行数据转换的准确率为61%,使用第一个和第二个自动编码器进行数据转换的准确率为63%)。降维后的模式可能过于复杂,无法通过SVM和自动编码器方法进行泛化,以识别数据集中的ASD和TC。与支持向量机相比,深度学习分类方法的分类精度平均提高了5%。深度学习方法也显示,与之前尝试使用多站点数据对ASD进行分类的研究相比,分类准确率提高了10%。
与试图用较小的参与者样本对ASD进行分类的研究相比,目前的分类缺乏特异性和敏感性。有研究已经实现了80%甚至90%以上的分类准确率。为了评估我们的模型在实际临床应用中的前景,我们计算了两个指标:正面预测值和负面预测值(Altman和Bland,1994)(分别为PPV和NPV)。这些指标提供了对模型泛化能力的评估(Castellanos等人,2013年)。该计算基于ASD的敏感性、特异性和患病率之间的关系。
本模型的PPV为4.3%,NPV为99%。PPV和NPV的计算考虑到美国ASD的患病率为2.24%。根据疾病控制和预防中心(CDC)2014年的监测估计(Zablotsky等人,2015年)。
NPV值是可以预期的,因为大多数人都不是自闭症患者。PPV值表明机器学习方法在脑成像数据中的应用并非出于诊断目的,相反,它是一种数据驱动的方法,用于告知最有可能与该疾病相关的神经模式。
较少的站点变化或数据集中没有太大变化往往有利于分类准确性;但是,一旦监督的方法应用在多中心数据上,分类的准确率就会下降。不同数据集维数的增加是脑成像ML研究面临的一个挑战。这些维度可能代表了为理解精神障碍增加临床相关信息的可变性,例如来自不同人口统计学的信息。
自闭症谱系数据库包含影响站点间一致性的敏感变化。深度学习方法包含了这些变化,并且比浅层方法产生更好的结果。分类的改进可以解释为自动编码器处理原始数据复杂结构中潜在因素的潜力,以及神经网络编码数据变化以指导分类过程的能力。有人建议,深度学习算法比支持向量机等更好地处理多中心、大型脑成像数据集的复杂性。
为了进一步评估结果,我们对每种分类方法进行了Wilcoxon符号秩相关组测试。具体而言,我们将每种分类方法的标签与基本事实进行了比较。对于SVM分类器,结果显示有统计学意义的标记(Z=12.08,p<0.001)。RF显示分类准确率略有提高(Z=2.33,p=0.020);标签之间的统计差异仍然显著。使用DNN分类器时,标签之间没有显示出统计上的显著差异(Z=0.49,p=0.624)。DNN是唯一一种表明分类标签与基本事实之间没有统计差异的分类方法。
本研究中获得的70%的准确率提高了技术水平。迄今为止的文献表明,监督方法有效地在较小的总体样本中对高维空间进行分类是可行的;深度神经网络允许学习者表示更复杂的函数,尤其是与自动编码器一起使用时。这些网络有效地降低了问题的维数,具有非常大的特征空间。然而,通过使用相同超参数和5折交叉验证的站点内数据训练我们的模型,我们获得了52%的平均准确率。模型综合中的可用数据量;站点可变性有助于避免站点之间的过度拟合。
6.1 留一站点分类
为了评估不同站点的分类器性能,我们执行了留一站点的交叉验证过程。该过程将一个站点的数据排除在训练过程之外,并将该数据用作测试集来评估模型。其基本原理是测试该模型对新的不同场地的适用性。这些进一步分析的结果见表3。
表3,基于深度神经网络的留一站点五折交叉验证结果。

补充材料中的表1和表2中分别显示了SVM和RF的结果:
补充表1:基于SVM的留一站点五折交叉验证结果。
补充表2:基于随机森林的留一站点五折交叉验证结果。

五个站点的准确率明显低于综合数据结果:SBL、MAX_MUN、斯坦福、加州理工学院和OHSU。结果表明,这些站点的数据具有其他站点不存在的可变性。将准确度得分与头部运动质量指标进行比较,并没有显示头部运动对分类准确度的影响。
7. 神经模式:自闭症患者大脑的连通性
大脑区域的静息态功能磁共振成像数据之间的相关性结果显示,在ASD 静息态功能磁共振成像数据中,有两组不同的区域不连通(负相关)或高度连接(正相关):
(1) 一个分布的大脑前后区网络,其在rs-fMRI期间的激活呈负相关;(2)一个后区域网络,其在rs-fMRI期间的激活呈高度相关。这些结果的假定解释与自闭症患者大脑前后连接的现有数据驱动理论有关。
ASD受试者显示出最高负相关的大脑区域是:扣带回(图3a)、边缘上回(图3b)和颞中回(图3c)。这些区域的负相关模式是我们深度学习分类研究的最相关特征。表4总结了负相关区域。图4显示了ASD受试者大脑中相关性最高的区域。相关性最高的区域都位于大脑后部:枕部(图4a)和枕外侧皮质;上部(图4b)。这些区域的相关模式是继负相关区域之后与深度学习分类最相关的特征。表5总结了相关区域。

图3,ASD受试者的负相关(未连接)脑区。
表4,负相关脑区


图4,ASD受试者的高度相关(连接)脑区。
表5,高度相关脑区

在ASD患者的任务相关和静息功能磁共振成像研究(Cherkasky等人,2006)中显示了前后连接中断(激活时间序列之间的相关性)。在先前的研究中,自闭症患者大脑功能的特征是前后连接减少,与正常人大脑中的连接相比,后部区域之间的局部连接增加。这些研究是大脑成像数据驱动的自闭症欠连接理论的基础(Just,2004)。前后欠连接理论也与大脑结构指数有关,更具体地说,是胼胝体形态计量学(Just等人,2006年)。
先前对ASD脑功能的研究表明,ASD患者的前后脑连接中断,同时后部或局部连接增加。本研究的结果表明,前部(扣带回旁)和更多后部区域(边缘上回)的功能与额叶-颞叶区域(如颞中区和额下区;梭形回和眶皮质)的功能存在负相关(描述见表4)。我们提出的解释是,负相关反映了ASD大脑前部和后部区域之间的欠连接,这对目前的分类贡献最大。分析表明,表4和表5中的网络与ADOS分数不相关。
总结:
本文研究结果表明,深度学习方法可以可靠地对大型多站点数据集进行分类。与单点数据集相比,多点分类必须考虑受试者、扫描序列和设备的额外差异来源(Nielsen等人,2013年)。这种差异性给大脑成像数据增加了噪声,这使得从大脑激活中提取特征,对疾病状态进行分类更具挑战性;然而,尽管不同的设备和人口统计学产生了噪声,但仍能实现可靠的分类准确性,这表明机器学习应用于临床数据集以及机器学习在帮助识别精神障碍方面的未来应用前景广阔。Plitt等指出迄今为止,使用静息状态功能磁共振成像数据对自闭症分类的总体评估尚不符合生物标志物标准;本研究未能克服这一障碍,但也已经朝着更可靠的结果方向迈出了一步。