提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
新手上路,有不好的地方欢迎评论区指正。
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有。
一、实施步骤
(1) 数据爬取:使用requests请求为基础获取数据源。(没安装的老哥自行安装
(2) UA伪装:模拟浏览器访问网址。
(3) 数据解析:使用xpath语法处理数据。
(4) 数据存储:获取需求数据后使用MongoDB进行存储。
二、目标网站
https://haikou.baixing.com/chongwujiaoyi/
先分析目标网站
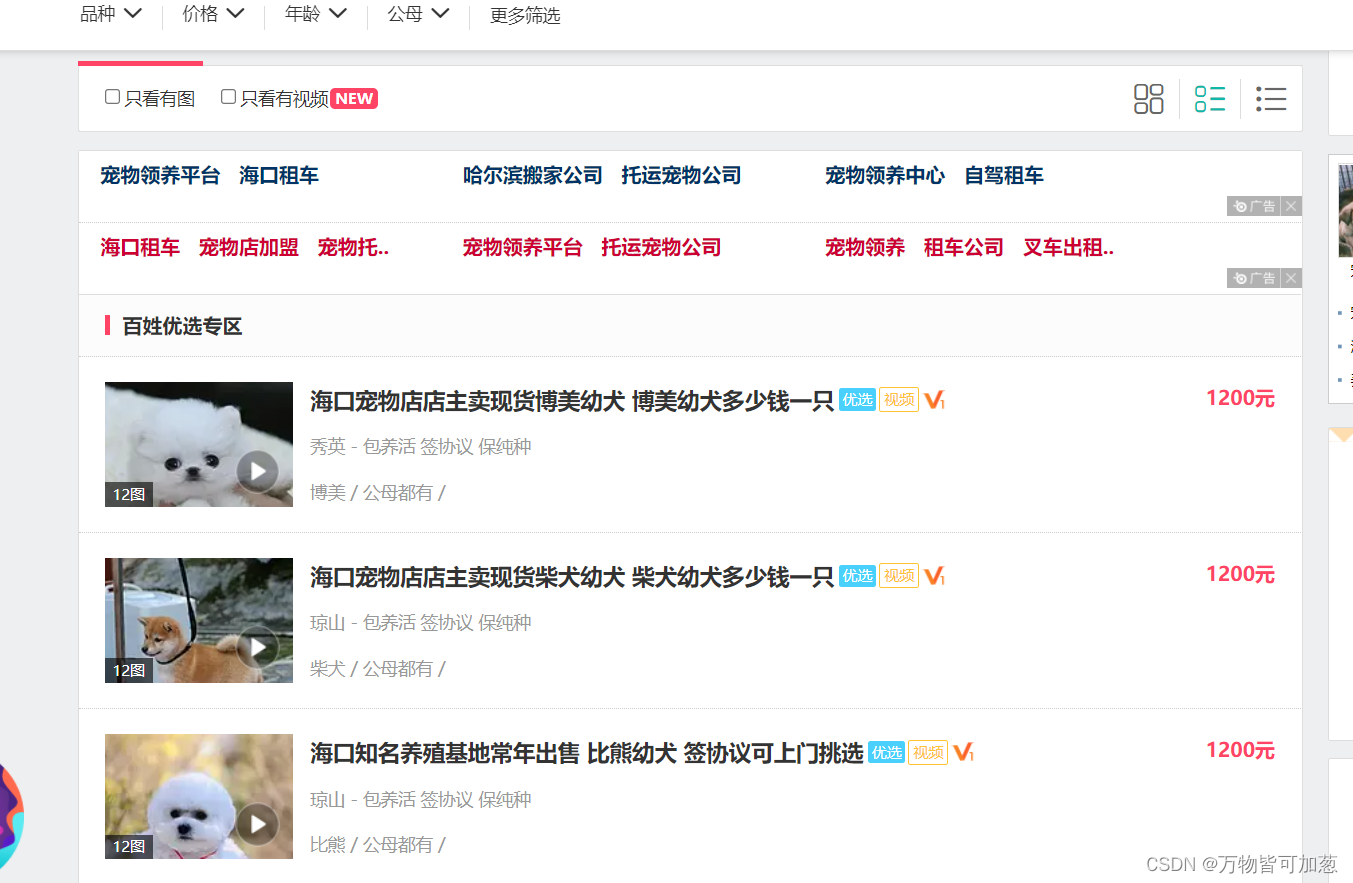
点击链接进去之后可以看到我们需要抓取的数据
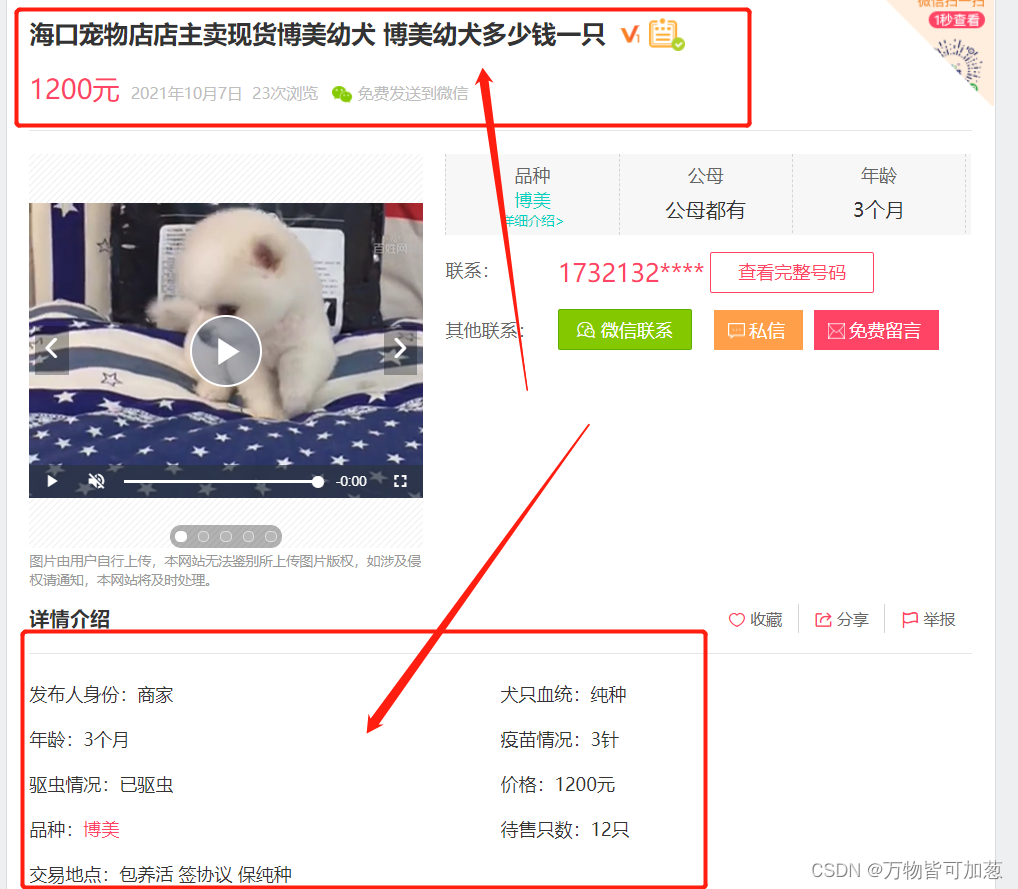
Ctrl+U打开网页源代码后,可以发现我们想要的数据直接就在网页上,然后开始吧!
三、获取数据
1. 引入库
import requests #请求网页
from lxml import html # 导入xpath
import pymongo # 用于连接mongoDB数据库
由于版本原因,etree模块不能直接从lxml包中导入,需要多一步操作
etree = html.etree
2.请求数据
url = 'https://haikou.baixing.com/chongwujiaoyi/'
respsone = requests.get(url,headers=headers).content.decode('utf-8')
# print(respsone)
2.1 获取第一层链接
首先拿到每一只宠物的链接,进去之后才能拿到宠物的信息,f12打开开发者工具,然后审查元素看到每一条宠物的链接就在<ul>下的<li>里面

list = []
html = etree.HTML(response)
lis = html.xpath('/html/body/section[2]/div[3]/ul/li')
for li in lis:
fir_url = li.xpath('./a/@href') # 拿到每只宠物的url地址
list.append(fir_url)
for i in list:
if i == []:
list.remove([]) # 稍微做一些数据处理
这是拿到的链接

3.抓取数据
3.1 分析页面

可以看到想要的数据全部一一对应在每一个div里面了,可以直接Ctrl cv复制xpath路径一个个拿下。
3.2 抓取数据
接下来才开始获取我们想要的数据了,用for循环请求每一个链接,然后根据xpath的规则拿到我们想要的数据
for url in list:
url = url[0] # 去掉列表
content = requests.get(url,headers=headers).content.decode('utf-8') # 编码
info = [] #创建一个列表来存放我们的数据
html = etree.HTML(content)
divs = html.xpath('/html/body/div[1]/div[1]/div[1]/div[4]/div[2]')
# print(len(divs))
for div in divs:
blood = div.xpath('./div[2]/label[2]/text()')[0]
age = div.xpath('./div[3]/label[2]/text()')[0]
yimiao = div.xpath('./div[4]/label[2]/text()')[0]
quchong = div.xpath('./div[5]/label[2]/text()')[0]
price = div.xpath('./div[6]/label[2]/text()')[0]
type = div.xpath('./div[7]/a/text()')[0]
num = div.xpath('./div[8]/label[2]/text()')[0]
phone = html.xpath('//*[@id="mobileNumber"]/strong/text()')[0]
list = {
'品种': type,
'犬只血统':blood,
'年龄':age,
'疫苗情况':yimiao,
'驱虫情况':quchong,
'价格':price,
'代售只数':num,
'联系方式':phone
}
info.append(list)
需要抓取多页的朋友可以分析一下接口的页码参数,写个循环即可。
四、保存数据(MongoDB)
最后就只剩下把数据存入数据库了
client = pymongo.MongoClient('Localhost', 27017) # 端口号
db = client['demo'] # 数据库名
data = db['petInfo'] # 表名
data.insert_one(list) # 插入数据操作

五、完整代码
# _*_ coding:UTF-8 _*_
import requests
from lxml import html
import pymongo
etree = html.etree
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
'referer': 'https: // haikou.baixing.com / chongwujiaoyi / m177986 /'
# 这里需要加入防盗链,第一次请求没加获取不到页面信息
}
def get_res():
url = 'https://haikou.baixing.com/chongwujiaoyi/'
respsone = requests.get(url,headers=headers).content.decode('utf-8')
# print(respsone)
return respsone
def get_url(response):
list = []
html = etree.HTML(response)
lis = html.xpath('/html/body/section[2]/div[3]/ul/li')
for li in lis:
fir_url = li.xpath('./a/@href') # 拿到每只宠物的url地址
list.append(fir_url)
for i in list:
if i == []:
list.remove([]) # 稍微做一些数据处理
print(list)
return list
def get_pet_info(list):
for url in list:
url = url[0]
content = requests.get(url,headers=headers).content.decode('utf-8')
parse_data(content)
def parse_data(content):
info = [] #创建一个列表来存放我们的数据
html = etree.HTML(content)
divs = html.xpath('/html/body/div[1]/div[1]/div[1]/div[4]/div[2]')
# print(len(divs))
for div in divs:
blood = div.xpath('./div[2]/label[2]/text()')[0]
age = div.xpath('./div[3]/label[2]/text()')[0]
yimiao = div.xpath('./div[4]/label[2]/text()')[0]
quchong = div.xpath('./div[5]/label[2]/text()')[0]
price = div.xpath('./div[6]/label[2]/text()')[0]
type = div.xpath('./div[7]/a/text()')[0]
num = div.xpath('./div[8]/label[2]/text()')[0]
phone = html.xpath('//*[@id="mobileNumber"]/strong/text()')[0]
list = {
'品种': type,
'犬只血统':blood,
'年龄':age,
'疫苗情况':yimiao,
'驱虫情况':quchong,
'价格':price,
'代售只数':num,
'联系方式':phone
}
info.append(list)
sava_mongodb(list)
print(info)
def sava_mongodb(list):
client = pymongo.MongoClient('Localhost', 27017)
db = client['demo']
data = db['petInfo']
data.insert_one(list)
def main():
response = get_res()
list = get_url(response)
# get_pet_info(list)
if __name__ == '__main__':
main()
总结
摘抄Jack-Cui大佬的一句话:我们要做一个友好的爬虫。写爬虫,要谨慎,勿给服务器增加过多的压力,满足我们的获取数据的需求,这就够了。
你好,我也好,大家好才是真的好。
PS:如果觉得本篇本章对您有所帮助,欢迎关注、评论、点赞,谢谢!