前言
本文要讲的是Self-Supervised Learning自监督学习,首先列举了Self-Supervised Learning的模型有哪些,再通过与Supervised Learning对比讲解了什么是 Self-Supervised Learning,通过四个例子具体讲了BERT怎么用以及为什么BERT有用,最后讲了自监督学习的另外一个模型GPT。
Self-Supervised Learning
模型介绍:
ELMo(Embeddings from Language Models)
BERT(Bidirectional Encoder Representations from Transformers)
ERNIE (Enhanced Representation through Knowledge Integration)
Big Bird(Transformers for Longer Sequences)
什么是Self-Supervised Learning
Supervised Learning就是有一个model,输入是x,输出是y,要有label(标签)才可以训练Supervised Learning,比如让机器看一篇文章,决定文章是正面的还是负面的,得先找一大堆文章,标注文章是正面的还是负面的,正面负面就是label。Self-Supervised Learning就是机器自己在没有label的情况下,想办法做Supervised Learning。比如把没有标注的资料分成两部分,一部分作为模型的输入,一部分作为模型的输出,模型的输出和label越接近越好。
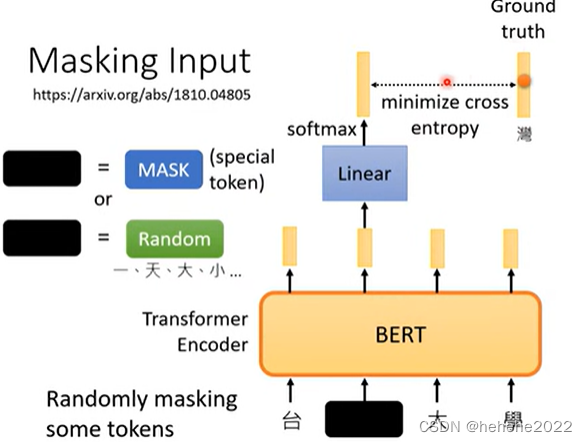
Masking Input
“完形填空”
BERT的架构和Transformer 的Encoder 一样,一般用在自然语言处理上。BERT的输入是一串文字,将文字的一些部分随机盖住,所谓的盖住具体有两种方法,一种就是将句子中的某个字换成一个特殊的符号mask或者另一种做法就是随机把某一个字换成另外一个字,盖住部分的输出乘一个矩阵,做softmax得到一个输出,BERT学习的目标就是输出和湾字越接近越好。
Next Sentence Prediction
拿出两个句子,句子中加一个特殊的符号代表分隔,如下图,当做BERT的输入,只取CLS的输出乘上一个矩阵,做二元分类问题,两个句子相接则为yes,否则no;但是这个方法不是很有用,可能是太简单了。
我们现在训练的BERT模型其实只会做2件事情:Masked token prediction:预测盖住的词是什么。Next sentence prediction:预测两个句子是不是前后接起来的。
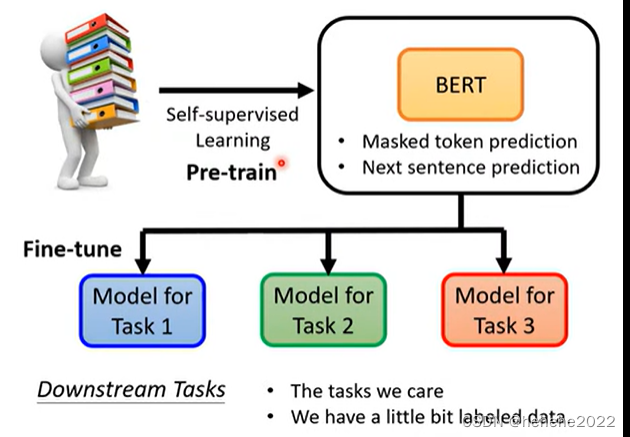
BERT不止做填空和句子连接,也可以被用在Downstream Tasks(一些我们真正在意的任务,需要一些标注资料)下游任务,BERT可以分化成各式各样的任务,这件事叫做fine-tune,产生BERT的过程叫做pre-train预训练。
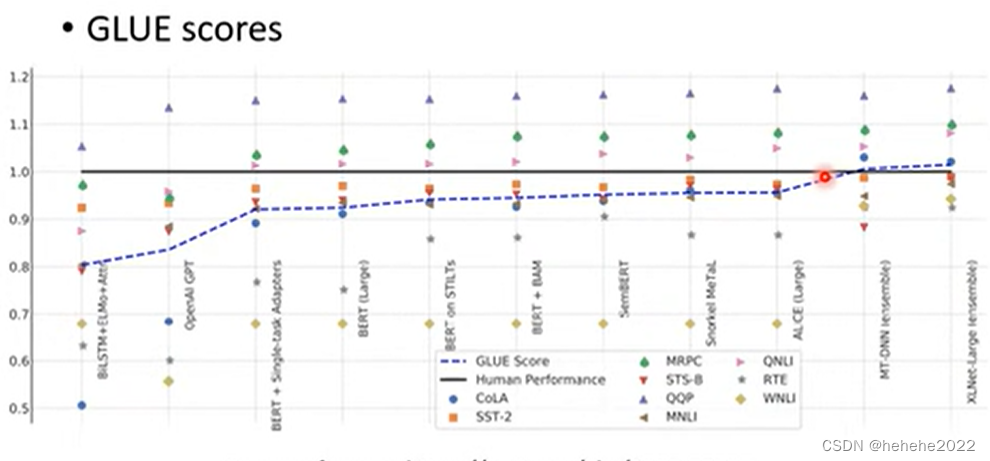
想测试Self-Supervised Learning模型的能力,会把它测试在多个任务上,最知名的任务集叫做GLUE(具体如下图,有九个任务)想知道BERT训练出来的模型好不好,把它作用在九个任务上,看平均正确率是多少,代表了Self-Supervised Learning模型好坏。

黑线代表人类在这个任务上的正确率为1,每个点代表了一个任务,蓝色的虚线代表GLUE分数的平均。可以看到在某些任务上BERT及其改良模型已经超过的人类。
BERT如何使用
例一
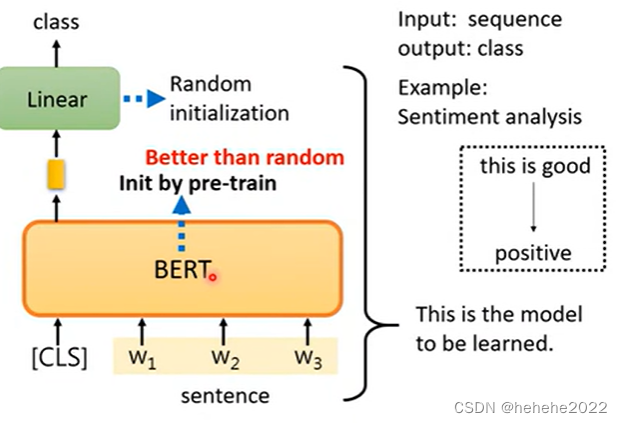
比如,输入一个句子,输出类别,判断一个句子是正面还是负面问题。
BERT没法凭空解决句子分析的问题,还需要提供一些标注资料(提供大量句子,每个句子是正面还是负面)才能够训练BERT的模型。linear部分的参数是随机初始化的,BERT的初始参数是把可以做填空题的BERT的参数拿来当做初始化的参数。
例二
输入一个序列,输出同样长的序列,比如POS tagging词性标注。
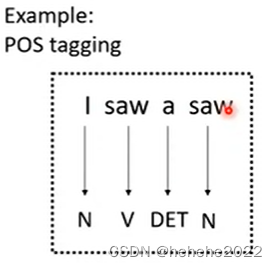
BERT处理词性标注的问题,输入三个字,每个字对应一个输出向量,把三个输出向量分别做linear transformer乘上一个矩阵,在做softmax判断属于哪一个类别,BERT本体的参数不是随机初始化的参数。
例三
输入两个句子,输出一个类别,在这里举自然语言处理的例子,机器要做的事情就是判断前提和假设是否矛盾。
BERT对这个问题的处理,给它两个句子,句子中间用SEP分隔开,只取CLS的输出,丢到linear transformer(乘一个矩阵)里面,决定输出类别(判断两个句子是否矛盾)
例四
做一个问答系统(QA),即给机器一篇文章,问一个问题,机器会给你答案。
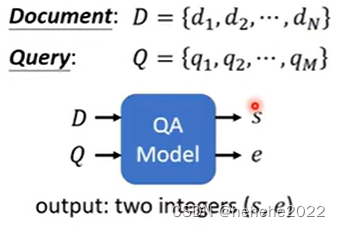
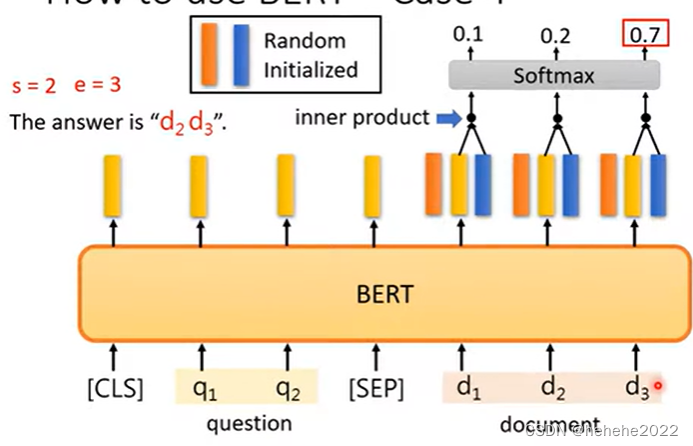
输入有文章和问题,把输入丢到QA模型里面,如上图,输出两个正整数s,e,表示从文章的第S个字到第e个字串起来就是正确答案。把文章和问题用SEP隔开作为BERT输入,如下图,需要从头开始训练的东西只有两个向量,两个向量的输出和BERT的输出长度是一样的,把橙色的向量和文章的输出向量做inner product,算出三个数值,做softmax得到三个数,d2对应的向量得到的分数最高,那么s=2,起始位置为2。
蓝色部分代表答案结束的位置,蓝色向量和对应的每个黄色向量做inner product,算出三个数值,做softmax得到三个数,d3对应的向量得到的分数最高,那么e=3,结束位置为3。正确答案就是d2 d3。
BERT 一般pre-trainingEncoder ,也有办法pre-training decoder。
给encoder的输入故意做一些扰动弄坏,decoder的输入希望跟弄坏前的结果一样。弄坏的方法有mass(把一些地方盖起来)、把词汇的顺序弄乱等等。
为什么BERT 有用呢?
输入一串文字,对应的输出向量我们叫它embedding,这些向量代表了输入的字的意思。
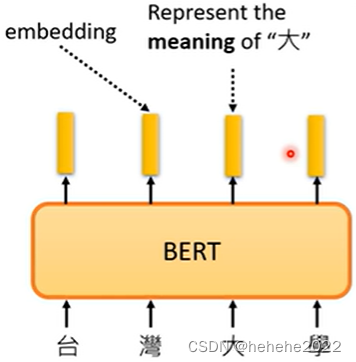
上面说的代表字的意思就是假设把向量划出来,发现意思越相近的字,他们的向量就越接近。很多语言都有一字多义的问题,BERT可以考虑上下文,同一个字,上下文不同,它的向量embedding也不同。
假设考虑果这个字,比如喝苹果汁,苹果电脑都就到BERT里面,计算每个“果”所对应的embedding,计算两个果之间的相似度。
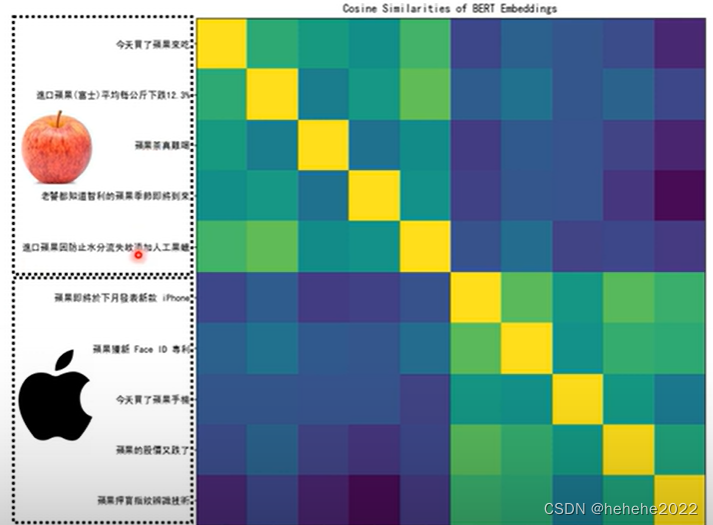
值偏黄色算出来的值越大,所以自己和自己的相似度最高,对角线为黄色的,前五个果的相似度比较高,后五个果的相似度比较高,前五个果和后五个果的相似度就比较低。
一个词汇的意思可以从它的上下文中看出来,BERT可以从上下文中抽取资讯来预测W2,如下图,像这样的想法在BERT之前就已经有了,叫Word embedding,所以BERT抽出的向量又叫contextualized word embedding。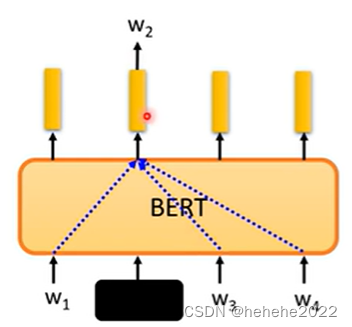
Multi-lingual BERT 多语言BERT
神奇之处在于拿英文的QA的资料去做训练,它自动就会学做中文的QA的问题。
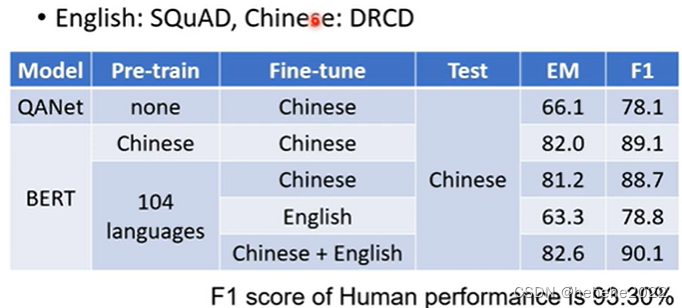
在没有BERT之前,最强的问答模型叫QANet,正确率只有78.1,如果用BERT在中文上学会做填空题,在中文的QA资料上做fine-tune ,测试在中文的问题上,正确率只有89.1,如果是多语言的BERT,fine-tune在英文上,测试在中文上也有78.8的正确率。
GPT
Self-Supervised Learning除了BERT还有GPT系列的模型,BERT做的是填空题,GPT做的是预测接下来的token是什么。
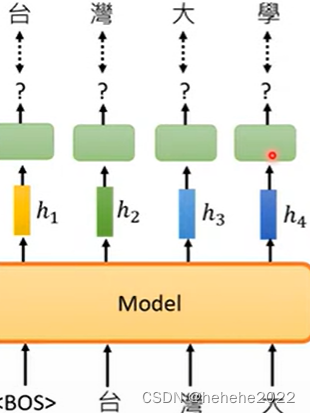
举例,训练资料的句子是台湾大学,输入begin of sentence,GPT输出一个embedding,预测下一个出现的token“台”,详细来看就是有一个embedding(h1表示)通过一个linear transform,再通过softmax,得到一个结果。
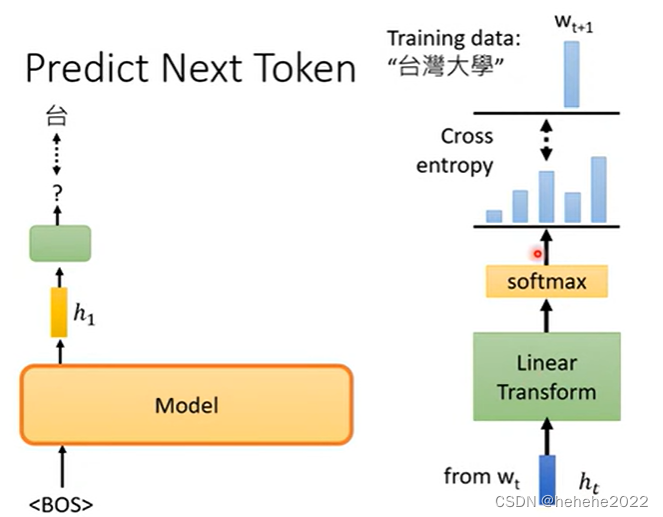
后面是一样的,给“台”,预测出“湾”,“湾”预测出“大”
假设要GPT模型做翻译
给它一段描述,告诉他要做翻译,给出几个例子,让他直接翻译出结果,这个叫做“Few-shot” Learning,但它和一般的“Few-shot” Learning不一样,完全没有调参数的意思,所以叫“In-context” Learning,不做gradient descent;只看一个例子就知道要做翻译这件事叫“one-shot” Learning,直接叙述说要做翻译就看懂的叫“Zero-shot”Learning。

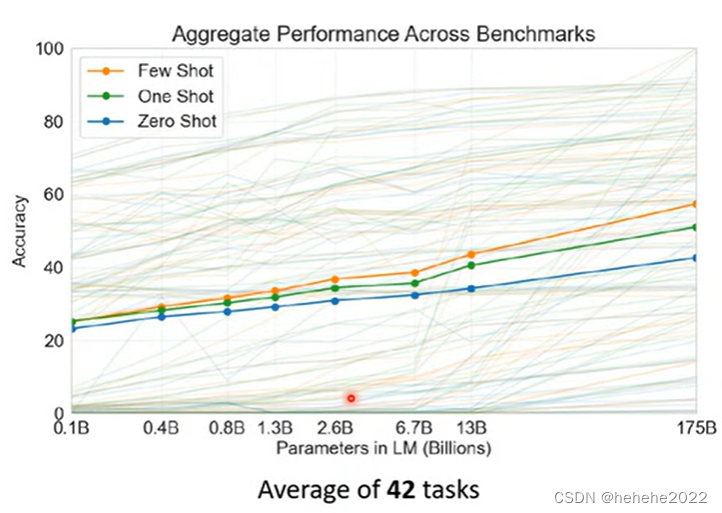
测试了42个任务,纵轴是正确率,三条实线是42个任务的平均正确率,分别代表了Few-shot、one-shot、Zero-shot,横轴代表了模型的大小。
Self-Supervised Learning不只可以用在文字上,在图像上、语音上也可以使用。
总结
通过学习了解了什么是自监督学习,是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务 (Downstream Tasks)。 其主要的方式就是通过自己监督自己。对于BERT来讲,其自监督训练的部分就是训练 BERT 做简单的填空题,训练好之后的BERT具有了 Word Embedding 的能力,且这里的 Word Embedding 是可以自动地考虑上下文的。这样的预训练好的 BERT 模型,只需要少量的带标签数据集,就可以在无数下游任务 (Downstream Tasks) 中完成微调 (Fine-tune),得到一个个不同的适用于下游任务的性能卓著的model。