ElasticSearch概述
ElasticSearch,简称es,es是一个开源的高扩展式全文检索引擎,它可以近乎实时的存储,检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
ElasticSearch安装
声明:jdk1.8,最低要求!ElasticSearch客户端,界面工具!
window下安装
解压即可
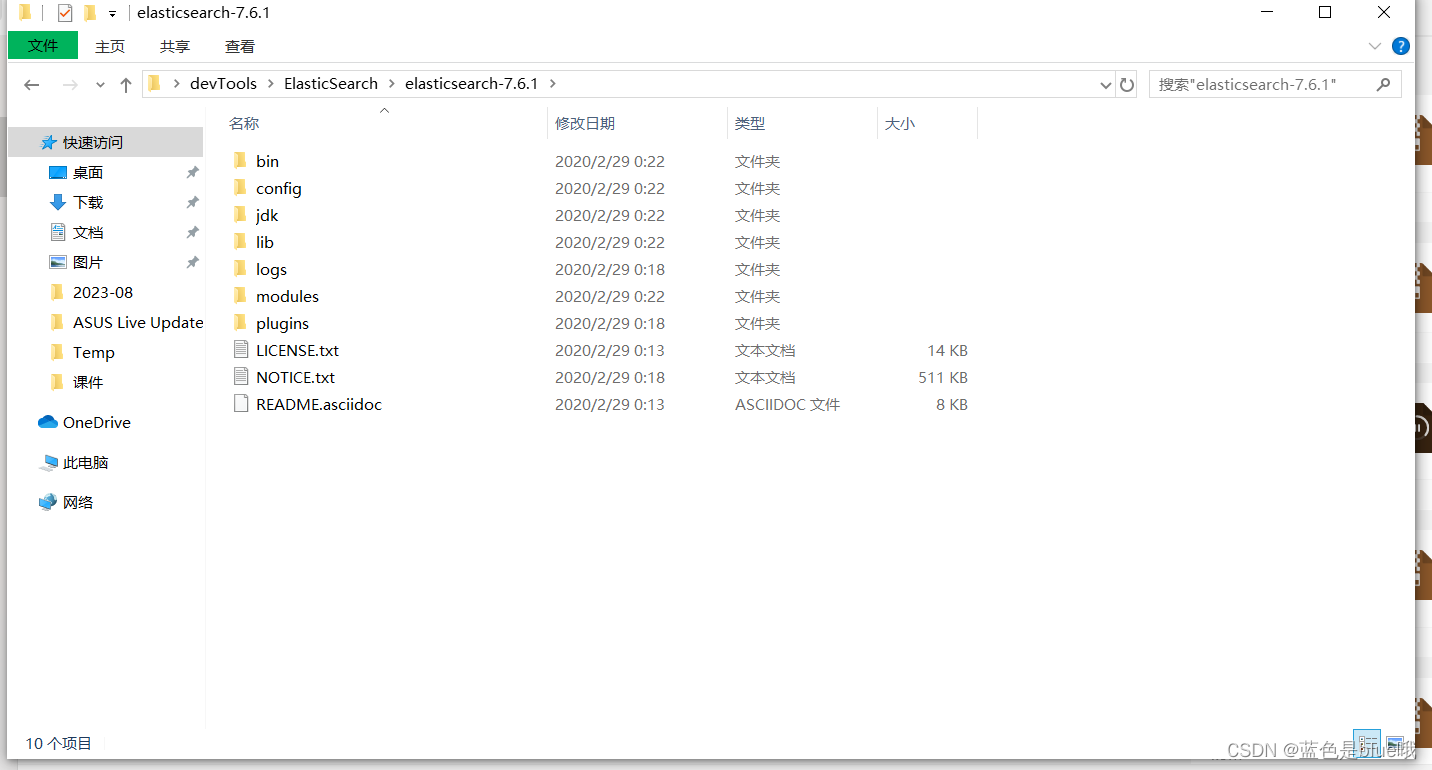
熟悉目录
bin 启动文件
config 配置文件
log4j2 日志配置文件
jvm.options java虚拟机相关配置
elasticsearch.yml elasticsearch的配置文件!默认9200端口
lib 相关依赖jar包
logs 日志
modules 功能模块
plugins 插件
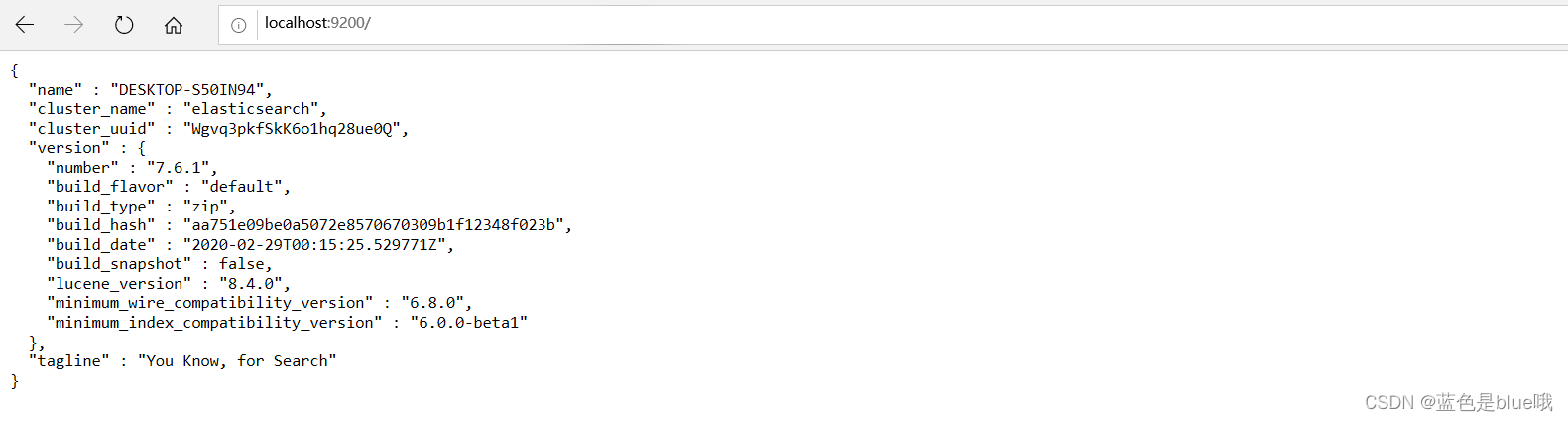
启动访问9200
安装可视化插件
解压即可

安装依赖后启动

访问地址并连接,发现跨域问题

配置ElasticSearch跨域支持(ElasticSearch config下的配置文件)

再尝试连接

初学就把es当成数据库(跨域建立索引,文档(库中的数据))
安装Kibana
kibana是一个针对ElasticSearch的开源分析及可视化平台,查看交互存储在ElasticSearch索引中的数据,使用Kibana可以通过各种图标进行数据高级分析及展示。Kibana让海量数据更容易理解,它操作简单,基于浏览器的用户界面可以快速创建仪表盘实时显示ElasticSearch查询动态。
注意:Kibana要和ElasticSearch版本一致。
解压即可
启动bin(kibana.bat)

访问测试

汉化
ES核心概念
elasticsearch是面向文档的,一切都是json
物理设计:
elasticsearch在后台把索引分成多个分片,每个分片可以在集群中的不同服务器之间迁移。
一个人就是一个集群!集群默认名称就是elasticsearch
| Relational DB |
Elasticsearch |
| 数据库(database) |
索引(indices) |
| 表(tables) |
types |
| 行(rows) |
documents |
| 字段(columns) |
fields |
文档
就是我们的一条条数据,之前说elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档。
类型
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。
索引
就是数据库!索引是映射类型的容器,elasticsearch中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。
倒排索引
通过文章,获取里面的单词,此谓正向索引。
我们希望能够输入一个单词,找到含有这个单词,或者和这个单词有关系的文章,就是倒排索引。
IK分词器
分词:把一段文字划分成一个个关键字,我们在搜索的时候会对自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作。
IK提供了两个分词算法ik_smart 和 ik_max_word:ik_smart:为最少切分,ik_max_word:为最细粒度划分。
安装解压即可(解压放在elasticsearch插件目录下)
重启elasticsearch

查看elasticsearch的插件目录

测试


如上,如果不想刘亦菲三个字被拆分,可以在ik分词器里面配置。

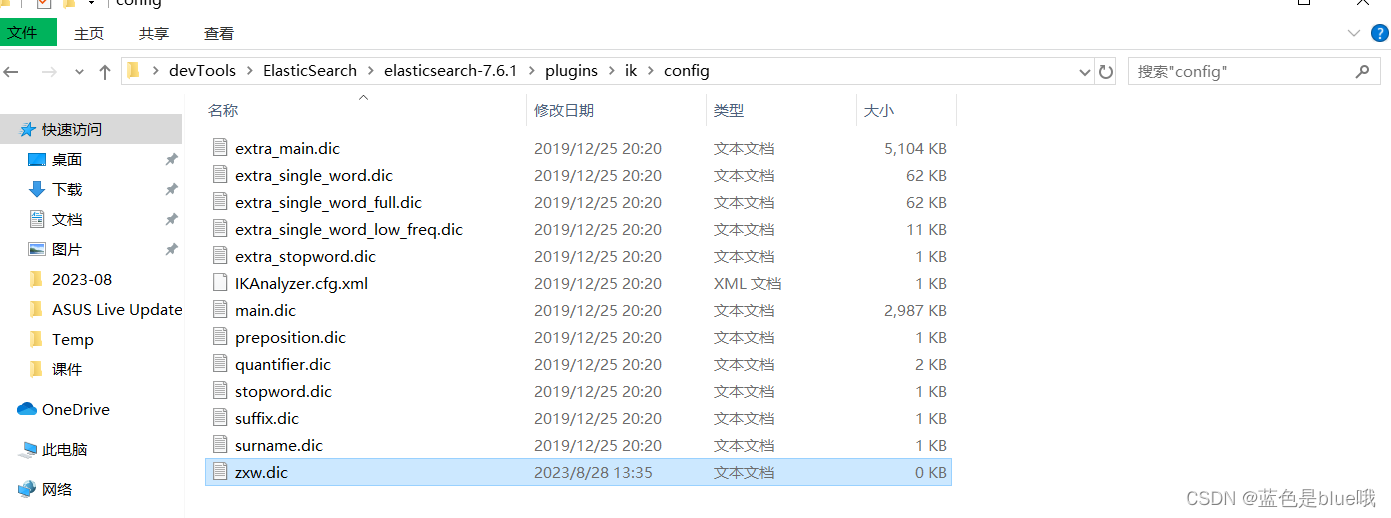
重启测试

Rest风格说明

基础测试
1.创建一个索引

数据查看/新增

数据类型
字符串类型
text、keyword
数值类型
long、integer、short、byte、double、float、
日期类型
data
设置数据类型

获取索引信息

默认匹配类型

如果自己的文档字段类型没有指定,那么es会默认给我们指定
扩展:
GET _cat/health 查看健康值
GET _cat/indices 查看索引库
GET _cat/ 可以查看很多系统值
数据修改
旧方法,put旧值,缺陷当更新操作忘掉某一字段值,改字段值就会置空

现在方法


数据删除
删除索引

删除文档
关于文档的数据操作
基本操作(crud)

简单的条件查询

复杂操作
查询:select(排序、分页、高亮、模糊查询、精准查询)

此处“刘亦菲”已放入lk分词器中当做一个词来处理,此外score的分数越高代表越匹配;
结果过滤

排序
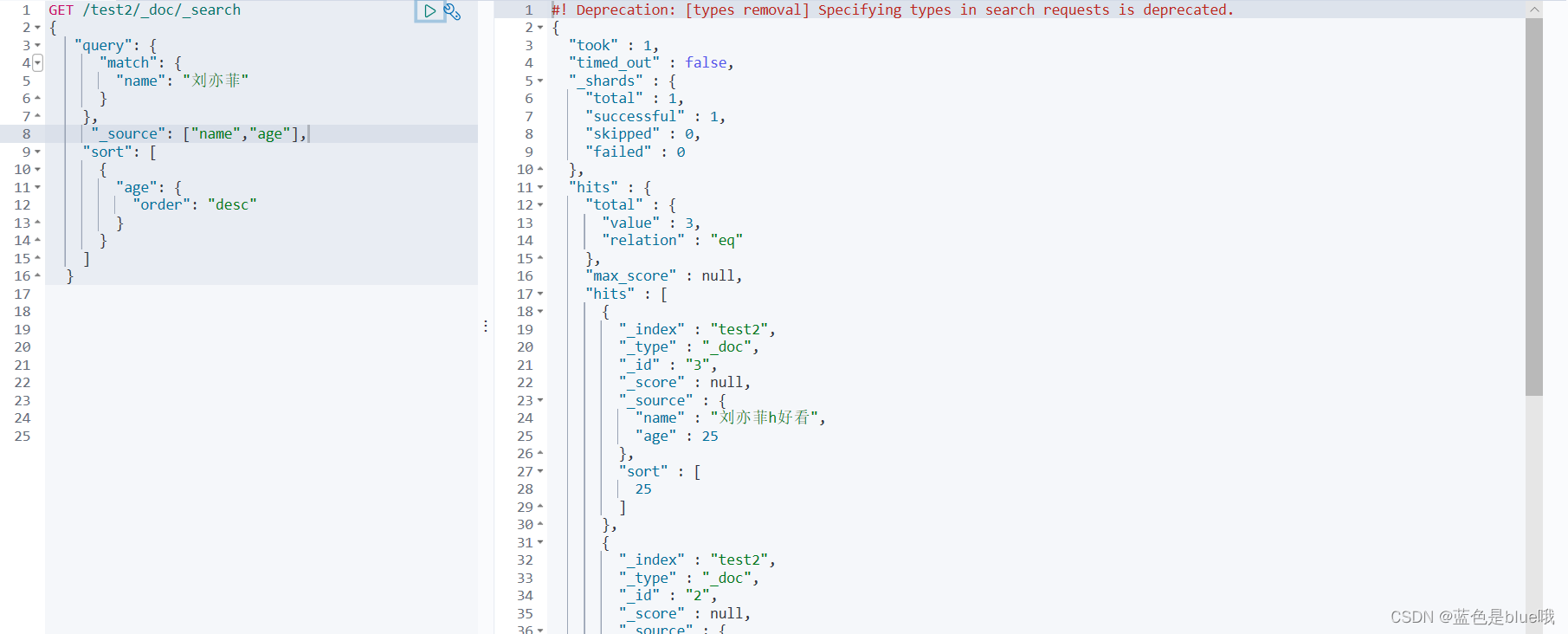
分页
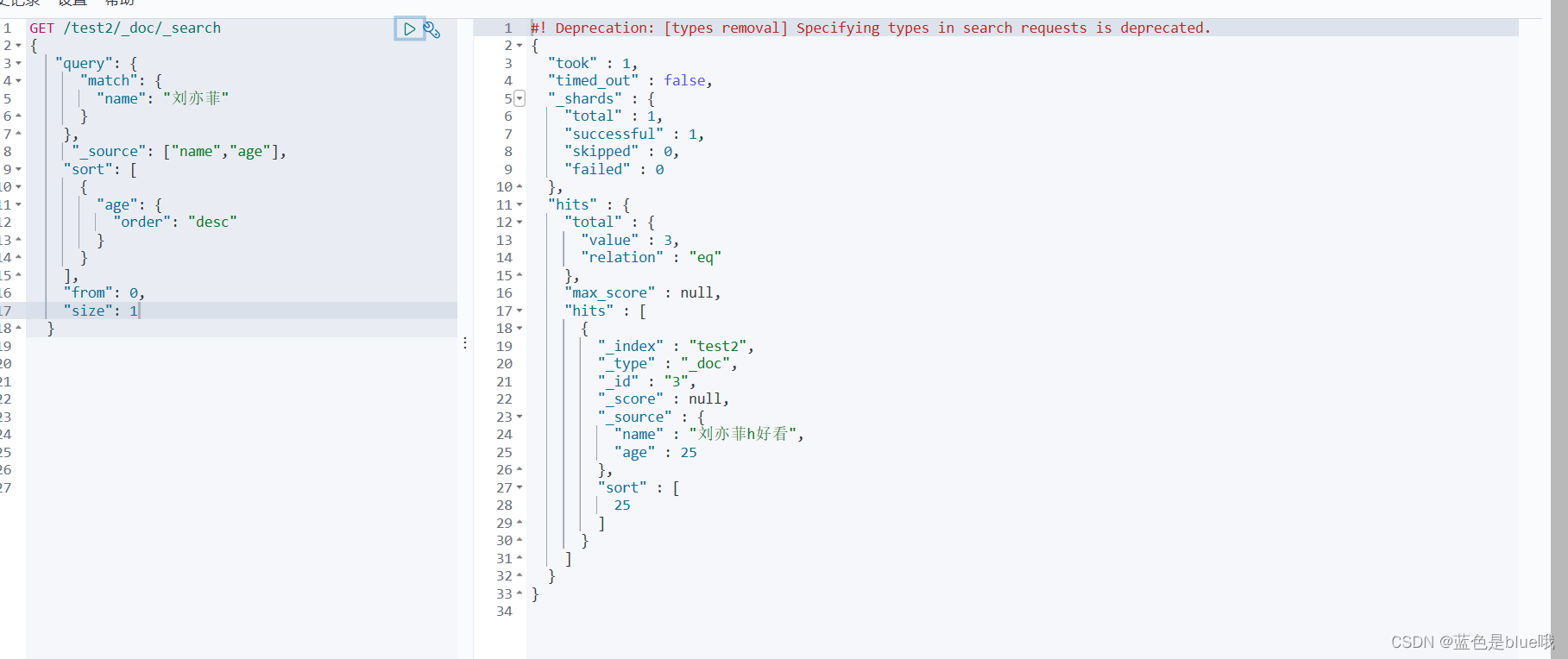
布尔值查询(多条件查询)must相当于and

should相当于or

must_not 相当于not(年龄不是25的数据)

过滤器

匹配多个条件
空格隔开匹配条件相当于or

关于分词
term 直接精确查询
match 会用分词器解析!(先分析文档,然后再通过分析的文档进行查询)
text会被分词解析器解析,而keyword不会

高亮查询

集成SpringBoot
把连接对象交由spring管理

创建索引

索引是否存在

删除索引

测试创建文档

获取文档判断是否存在

获取文档信息

更新文档

删除文档

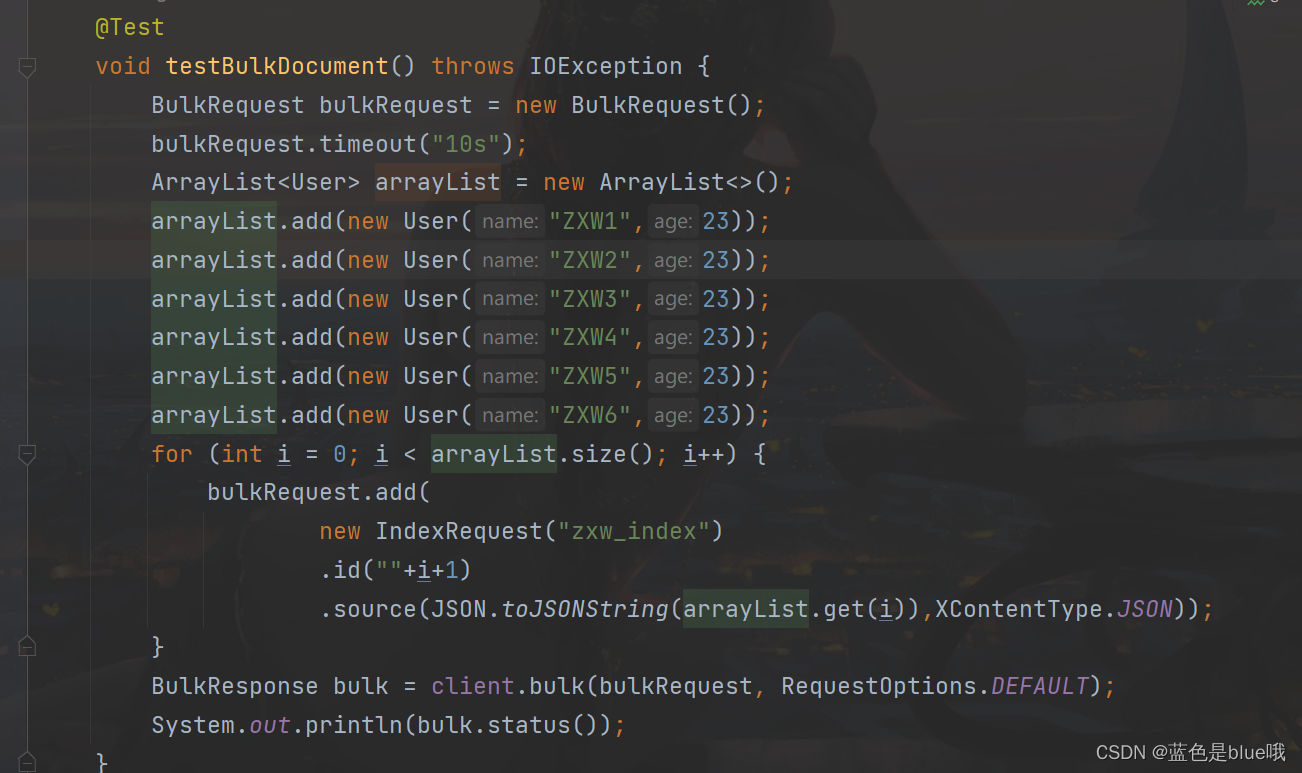
批量插入数据(不存在索引会自动创建)
精确查找
