说明
随着现代社会互联网不断发展壮大的趋势,越来越多的专题网站、论坛也趁着东风连续高速发展。广大互联网用户身处这个“信息爆炸”的时代,怎样才能选出令自己感兴趣的优质内容,已成了大多数互联网用户最为关注的目的。也正是如此,对于网站运营来讲,如何持续保持高产出、高质量、高用户、高活跃,从而给网站带来流量和收益这一核心目标,是一个长期不断进行优化、迭代网站数据分析运营的过程。《人人都是产品经理》网站正是在这样的背景下快速成长起来的,如今发展成为比较全面的互联网产品等领域的学习平台。本文选取该网站所有发布的专题文章进行分析,主要进行以下方向的分析:
- 分析网站总体内容运营方向和用户活跃程度,比如文章分类偏好、作者活跃程度、用户阅读/评论文章趋势;
- 通过全部文章内容分析运营主题,提取关键词了解网站运营侧重方向;根据文章城市提及情况,分析各大中城市互联网产业的发展态势;
- 通过用户阅读、点赞、评论等维度量化用户对文章的喜好程度,将文章分为几类用户的喜好类型,用以指导文章发布、网站内容运营。
本文借鉴了专栏作者苏格兰折耳喵的文章,并自己梳理思路独立完成了这篇分析报告。
数据处理
数据获取
使用python爬虫技术获取《人人都是产品经理》对外公开的所有发布的文章信息,时间段为2012.05.17-2018.04.05,总共41000多篇文章,包括文章id、文章标题、正文链接、正文内容、发布日期、作者姓名、作者角色、文章分类、阅读量、点赞量、收藏量、评论量等信息。
数据预处理
获取的数据比较杂乱,而且部分字段暂时不需要用到,因此做一下处理:
- 文章id、正文链接、作者角色、正文内容等信息对总体分析过程没有太大意义,因此过滤掉;
- 爬取的文章分类字段带有<a></a>标签,需要用正则表达式匹配实际分类;
- 阅读量等指标上万、上百万级的数据通过类似于1.2w、2.2m的字符来表示的,需要转化成数据。
经过处理后的数据:

总体运营分析
总体分析
将所有文章进行分类,并统计总发文数量,做成如下数量统计图。以及饼图展示了不同分类所属的文章占总文章数量的比重。
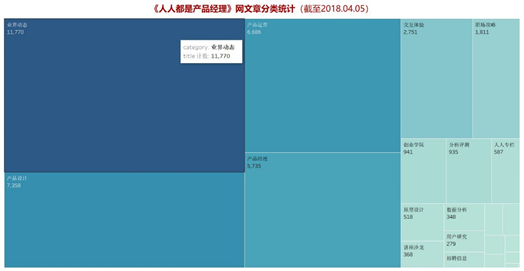
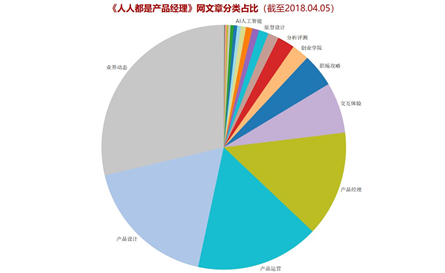
上图展示了业界动态、产品设计、产品运营等分类文章的总数量和占比情况。由此可看出,业界动态、产品设计、产品运营、产品经理四类文章是网站文章运营主流,占了14个分类中近75%的比例,也契合了该网站以产品学习为主的运营思路。从数量上看,这四类文章的数量都超过了5000,而且与排名第五的交互体验(数量2751)拉开了很大的差距,甚至排名第一的业界动态数量达到了11770篇,说明更多优质的内容更有可能从这几类文章中产出。根据“二八原则”,确实是更少的领域贡献了更多的内容,也体现了网站的运营方向更关注业界资讯和产品指导,对创业指导、数据分析、AI关注度较少。
趋势分析
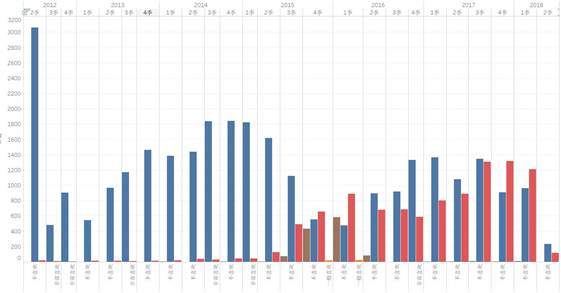
通过观察发文数量的历史趋势,可以总体探知网站的运营情况;文章的阅读量、点赞/评论量可以反映用户的活跃程度,也是体现网站发展情况的重要指标。
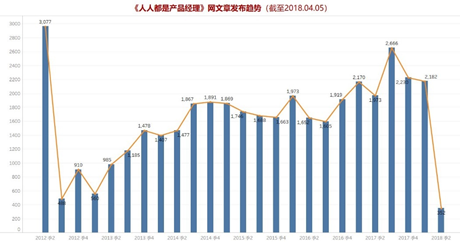
首先关注两个异常节点——一首一尾,2012年2季度为开始发布文章时间,这个时期发文数量巨大,分析可能原因是:网站开始起步,为了吸引流量网站大量原创,也或者转载了很多文章到自己的平台,目的是引起用户的关注,让用户知道有这样一个平台。至于2018年2季度就很好解释了,因为到目前这个时期还没有结束,粗略估算一下,这个时间段的文章数量会持平。
总体来看,整个平台文章数量是保持增长的,尤其是2012-2014三年时间整体处于稳步上升阶段,运营得不错。
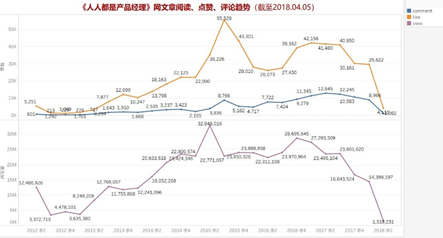
除开上述分析的两个异常节点,用户阅读量、点赞/评论数量整体呈现出初期阶段高增长,到达2015年2季度最大值,然后趋于稳定,说明网站收获了一批忠实用户,一直伴随着网站成长。根据趋势,网站发展过程中应该是淘汰了一部分非目标用户,最后留下了忠实的核心用户支撑平台的运营发展。
作者分析
将文章作者单独列出来分析,可以了解这些作者对网站发展的贡献程度,通过用户对作者文章的关注度,也能反映作者给平台带来流量排名。
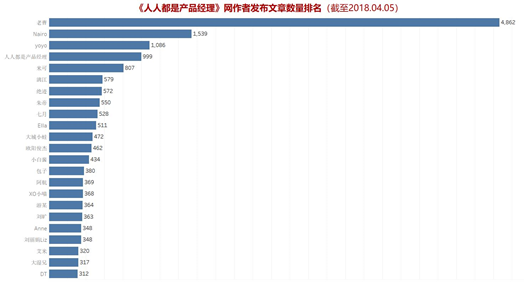
上图是作者发文总量排名,我只选取了发文300篇以上的作者。老曹作为网站的站长,发文数量真是其他作者远远不能比的,近5k的文章量,比第2-5名4位作者的总量还要多。而人人都是产品经理这个作者作为网站官方运营账号,也贡献了较大比例的文章。因此,为了吸引更多的用户,老曹和人人都是产品经理这两个“自己人”花费了很多的精力,值得点赞!
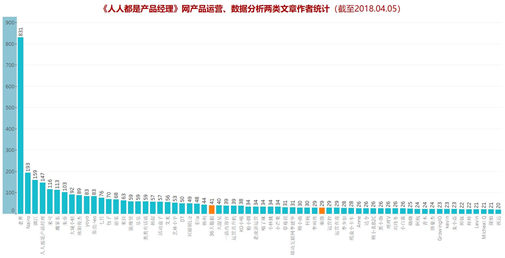
单从数据运营(蓝色)、数据分析(橙色)来看,整体与上述分析保持一致,更多作者的文章是倾向于产品相关,而且也是主要几位作者:诸如老曹、Nairo、米可等,给平台提供了绝大部分内容。值得一提的是,关于数据分析的文章主要是由36大数据和秦路提供的,秦路作为数据分析领域的大牛,同时也是知乎和天善的大 V。
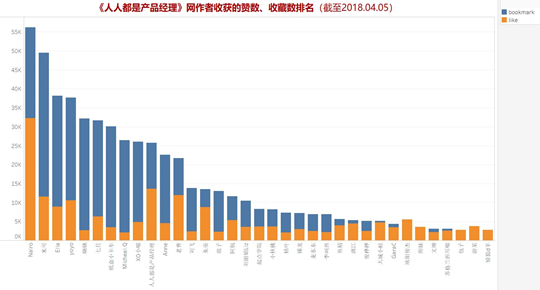
这张图展示了收获赞和收藏数量靠前的作者排名。首先反映出主要几位作者更容易获得用户的青睐,这跟他们发布的优质内容有很大关系,说明这些作者在这些领域的专业性。再从赞和收藏来讲,赞的数量要比收藏要少,说明用户不轻易用点赞“这个技能”,对一篇文章的认可更愿意点赞;从前几位排名来看,Nairo、老曹等作者赞数与收藏量的比值比其他要大很多,也侧面反应他们的文章的受认可程度更高。最后说一个作者苏格兰折耳喵,本文的参考文章出自于他,可以看到,虽然他的文章数量很少,但是能够收获高赞和收藏,非常厉害。
对比分析
对分类文章的点赞评论分析,可以了解用户群体对某几类文章的关注程度,根据用户的兴趣点再去进行内容优化。
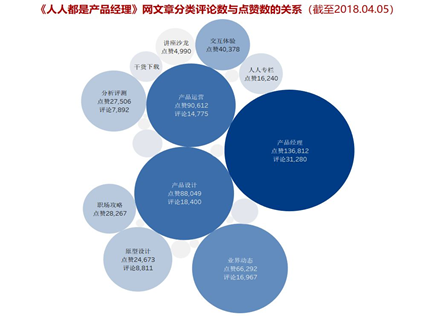
上图是各分类文章收到的点赞数和评论数,颜色越深点赞数越多,圆越大评论数越多。很容易看出产品经理、产品运营、产品设计、业界动态类的文章更受用户关注,而且点赞数和评论数有一定的相关性,也就是随着点赞数的增多,评论数也在增多,说明优质的文章在平台能体现出其价值。
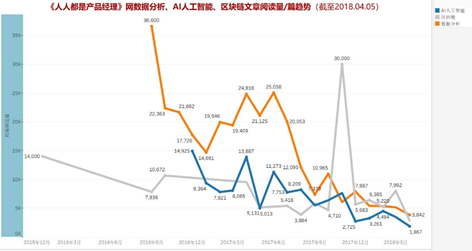
我选取了自己感兴趣:数据分析、AI、区块链这三类文章来研究它们的篇均阅读量。总体来看,用户刚开始比较关注,然后逐渐趋于减少的趋势,分析一下可能原因:
- 平台是主要是涉及的是互联网产品体系,诸如AI类的文章的专业性、可读性不如其它平台;
- 正是由于平台的用户特征,非主领域的用户粘度不高,容易流失。
我建议为了拓展平台,可以选择某个非主领域进行研究,发展优质内容吸引用户群体。至于2017.11月区块链篇均阅读量突然出现了一个高点,应该是那段时间比特币持续增值带来的结果,而能够引爆这个点正是那段时间比特币持续走高,连续破$8000,破$10000,各新闻平台竞相报道,引起了互联网用户强烈的关注度。
周期分析
我通过选取一段时间内的文章发布量,并对发布的时间进行对比分析,可以看出文章发布时间是有明确的周期性的。
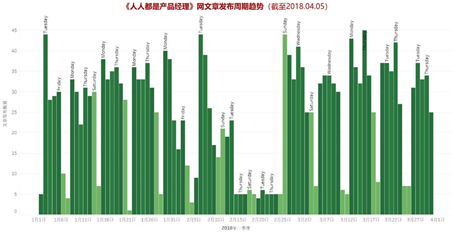
图中展示了2018年1季度文章发布数量与时间的关系,柱状图中浅色表示周六和周日,中间数量较少对应的时间是春节期间。因此很容易看出,绝大多数文章是在工作日发布的。
运营内容分析
关键词提取
可以根据关键词,单独分析文章内容,作为对平台的运营方向的补充。使用Python分词工具,通过tf-idf算法给每个词赋上权重,权重越高,说明这个词的重要性越高,可以通过这些词对文章的重要程度来判断所有文章的主题倾向性。
主题分析
将所有的词按照重要程度做可视化,可以非常直观地呈现平台的主题。

可以看到,“用户”、“产品”、“设计”等跟互联网产品相关的词的重要性非常高,这些词在绝大部分文章出现的概率也很高。这样从发文内容也展示了平台运营主题,再去分析这些词,发现这些词都是近几年互联网高速发展带来的热频词汇,跟传统行业相比一眼就可以辨别。

再将这些词与我自己做的互联网公司词表做匹配,做出词云给我们展示了平台所提及到的互联网公司的热度。诸如腾讯、阿里旗下的公司依旧显眼,因为无论是技术、产品、创新、战略,它们的产品仍然是行业标杆,总是各专业人士的分析对象。后起之秀例如抖音、滴滴、摩拜、快手等,它们是近几年在BAT等大厂的市场夹缝中通过商业模式创新快速成长起来的代表,因此也非常值得作为商业案例、产品案例来分析。
城市热度分析
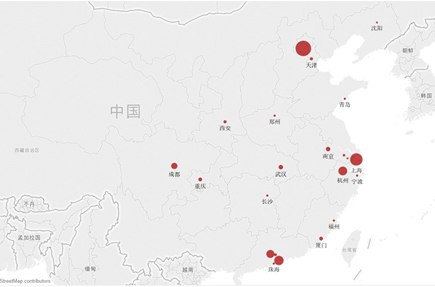
同样,通过城市词表将平台所提及的城市做热度分析。可以看到,北京、上海、深圳、广州、杭州这五个城市是平台提到最多的城市,这正表明了中国互联网发展的现状——目前几乎所有的互联网大厂都分布在这五个城市,而且处于快速发展期的中小互联网公司,甚至独角兽公司也几乎分布在这几个城市,因此要谈中国的互联网,要谈中国的互联网产品、互联网创新,必定提及北上广深杭。再进一步分析,上述城市因为互联网布局和政策支持,已然处于第一梯队,但随着城市居住、生活成本的升高,更多的从业人员选择逃离,加上地方政府支持,像成都、武汉等城市已经在快速追赶,拥有了一批优质有潜力的互联网公司,也是这些专栏作者喜欢分析的对象。
深挖数据价值
数据潜在价值
本次一共分析了4w多篇文章,每篇文章都有相应的阅读数量、评论数量等可以量化,并且有价值的数据。一篇文章的阅读数量可以说明受众量有多大,点赞和收藏数量可以反应文章的受欢迎程度,也能够反应出文章的质量好坏。并且通过这些文章再去分析文章作者,就可以了解到那些作者能够产出优质的内容,从而指导网站的运营思路。
本次分析深入挖掘这些数值型数据,将数据挖掘的方法在实际场景应用,可以给文章做个性化的划分,并以此为基础取长补短,重点发掘高价值文章,淘汰低价值文章。
分析思路
我选用聚类算法,将4w多篇文章聚集为几类,并根据每个类别用户在阅读量等数据上的表现,给每个类别贴上标签表明用户对文章的喜好程度。然后再分析不同喜好程度文章分类的分布,以及探寻哪些作者更能产出优质内容,受到用户喜爱。
每篇文章对应有价值、可量化的数据为:阅读量、点赞量、收藏量、评论量,于是在聚类的过程中可以选择这四个特征,也称之为四个维度。但是我在实现过程中发现选取四个特征,由于绝大部分数据很集中,因此聚类效果总不理想。上面分析过程曾提过点赞量和评论量有一定的相关性,因此就做了二选一,最终选择三个特征进行聚类。经过多次参数调整以及结果观察,最终我将全部文章聚集为4个分类。
文章分类
这4个文章的用户喜好程度分类类别为:
- 非常喜欢:高阅读量、高点赞量、高收藏量
- 一般喜欢:低阅读量、中点赞量、中收藏量
- 不太喜欢:低阅读量、低点赞量、高收藏量
- 不喜欢:中阅读量、低点赞量、低收藏量
首先我观测了所有数据,根据数据表现将这些数据分别做了等级划分,将数据大致在某个范围设定为高、中、低频,因此这里出现了中点赞量和中收藏量。
价值分析
于是每篇文章有一个用户喜好程度的标签,通过分析用户对文章的接受程度,可以对网站的运营成果进行分析。
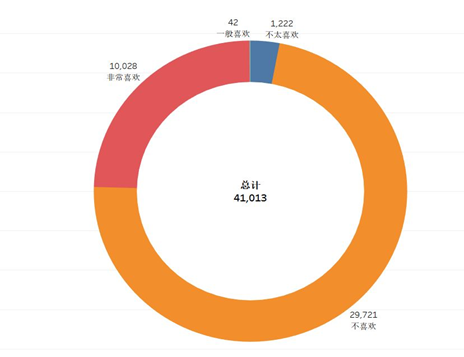
总体来看,自从网站运营以来,大多数的文章用户不怎么关注喜欢,同时有1/4的文章为用户非常喜欢。再结合历史趋势就一目了然了,网站刚开始运营时,几乎所有的文章都是不喜欢这一类别,分析原因是:网站成立发布文章,并没有多少用户积累,因此也许部分“优质”历史文章就被无视了,自2015年3季度开始,成果慢慢就有所展现了。这个时间节点之后,被用户所喜欢的文章增长趋势特别快,而且比例也越来越高,并一直持续。因此我认为整个网站的运营成果非常显著,而且后续还有更大的发展空间。
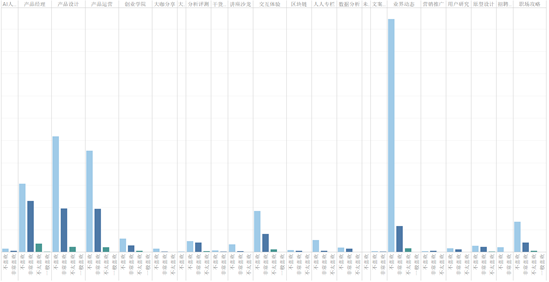
本图展示了各领域文章被用户的接受情况,浅蓝色为不喜欢,深蓝色为喜欢。可以看到,产品经理、产品运营、产品设计等领域数量最多;分析评测、原型设计、数据分析、用户研究几个领域用户喜欢文章占比更大,说明这些非主领域能够产出优质的内容。平台可以与这些文章作者经常联系,并保持约更多的文章,就像前面提过,再选择一个领域拓展平台 。
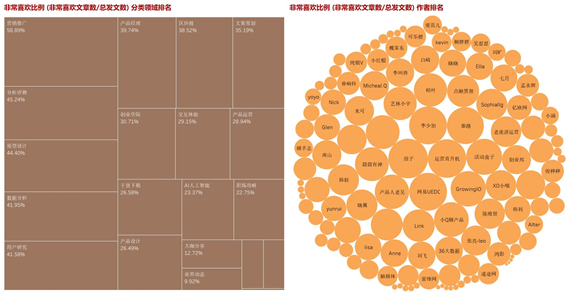
上图展示了用户非常喜欢的文章领域以及文章作者(发文数多于40篇)的分布情况。由左图可知,营销推广类文章用户非常喜欢的总体占比接近60%,说明这一领域的文章质量特别高,同样分析评测、原型设计、数据分析、用户研究领域用户非常喜欢占比都超过了40%,也体现出相关内容具有高价值。那么可以这样考虑:营销推广、数据分析、用户研究这几类并不是该网站重点关注的领域,随着更多科技新知识的发展,在以后的运营过程中,可以倾向性在这一两个领域发布数量更多,内容也更优质的文章,可以吸引更多的用户到平台,这样形成一个良性循环——优质的内容吸引更多的稳定、忠实的优质用户。
要实现这个目标最关键就在于文章作者了,因为文章是人写出来的,因此发掘并留住能带来高流量的作者至关重要。图中的信息告诉我们,网易UEDC、运营直升机、秦路等作者发布了很多受到用户喜欢,对网站来说有较高价值的文章,也正是他们的文章给网站带来了部分人气和流量,所以在网站接下来的运营过程中,要想办法更多地和这些作者互动接触,想方设法留住他们并且鼓励他们产出更多好的内容,这需要网站的运营人员去做一些线上线下鼓励活动。
接下来再分析一下用户不太关注、不太喜欢的文章分布。像大咖视频、讲座沙龙、人人专栏超过90%的内容用户都不喜欢,可以从两个方面考虑:
- 这几个领域本身内容比较劣质,对用户来讲确实帮助不大;
- 这几个领域非常小众,关注的群体本来就少。
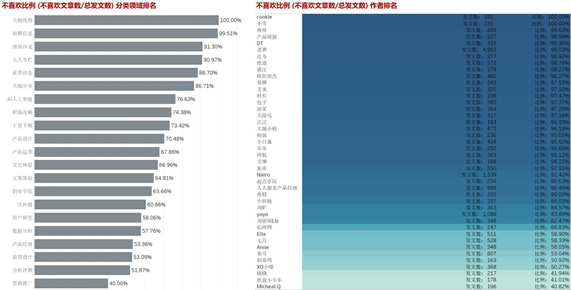
根据前面各领域的对比分析,我更倾向认为第二点是主要原因,那么针对这样的情况,我认为大可不必花费太多资源在这些不太容易出成绩的分类领域。但是对于产品经理、原型设计、营销推广这类网站主要针对的领域,它们总体不喜欢的比例在50%左右(营销推广表现好一些),应该来讲表现可圈可点,需要保持这种态势,争取把内容做得更好。而产品设计、产品运营等领域也是网站主要针对的领域,但是表现一般,总体不喜欢率为70%左右,需要采用一定的手段将比例降下来。
针对用户不喜欢的文章,我选取了发布文章超过150篇的作者,除开老曹(前文分析过网站初期发过大量文章)可能比较特殊,其他比如DT、绝迹、欧阳俊杰、漓江等作者,发文数量很大——超过300篇,同时用户的认可度并不是很高。可能是文章内容并没有讲出什么有用的东西,也可能是由于他们的领域小众,阅读群体不高或者不感兴趣,那么是否可以建议这部分作者将发布文章的频率降下来,更多思考在文章风格,文章质量上做优化改进。如果专栏作者的文章一直不温不火,很容易导致作者没有成就感,最终离开而去其他平台,也许会带走一批常驻用户,最终影响到平台流量、平台运营。
因此,通过将数据潜在的价值用数据、图表的方式呈现出来,更容易使网站的运营人员认识自己的平台优势在哪、劣势在哪,从而扬长避短,拓展运营思路。
总结
要让杂乱无章的数据体现出其价值,用数据量化并做成各种总体对比图,或者趋势对比图是一套行之有效的流程化方法,本文就是在这种思维的指导下进行的分析,并总结出以下简要结论:
- 诸如大数据、区块链领域用户的关注度(阅读量)在增加,但是活跃度(赞、评论和收藏量)不够,需要注意调整这几个领域的运营方式;
- 部分作者发布的文章受用户不喜欢的比例很高,需要作者注意提升文章的质量。
我很热爱数据行业,并以极大的兴趣去学习、实践,这是我第一次写一份比较全面、专业的分析报告,不足之处还请多指教!