推荐不错的学习地址 https://jingyan.baidu.com/article/f96699bb168d75894f3c1b5d.html
推荐参考资料 但他写的不太对 利用shell脚本监控linux中CPU、内存和磁盘利用率
k8s学习资料
Kubernetes 文档 | Kubernetes
Kubernetes(k8s)中文文档 名词解释:DaemonSet_Kubernetes中文社区
49. linux(centos)测试带宽
centos测试带宽
1.安装speedtest-cli
speedtest-cli是一个用Python编写的轻量级Linux命令行工具,在Python2.4至3.4版本下均可运行。它基于Speedtest.net的基础架构来测量网络的上/下行速率。安装speedtest-cli很简单——只需要下载其Python脚本文件。
2.下载并授权
wget https://raw.githubusercontent.com/sivel/speedtest-cli/master/speedtest.py
chmod +rx speedtest.py
sudo mv speedtest.py /usr/local/bin/speedtest-cli
sudo chown root:root /usr/local/bin/speedtest-cli
使用speedtest-cli测试网速
使用speedtest-cli命令也很简单,它不需要任何参数即可工作。
speedtest-cli
输入这个命令后,它会自动发现离你最近的Speedtest.net服务器(地理距离),然后打印出测试的网络上/下行速率。
speedtest-cli --bytes以字节计算的方式来测试上下行速度
speedtest-cli --share将速度测试的结果生成一张图片的连接,便于你分享
speedtest-cli --simple只显示ping和上下行速度
speedtest-cli --list 列出speedtest.net所有的服务器距离你的物理距离,单位是千米(km)
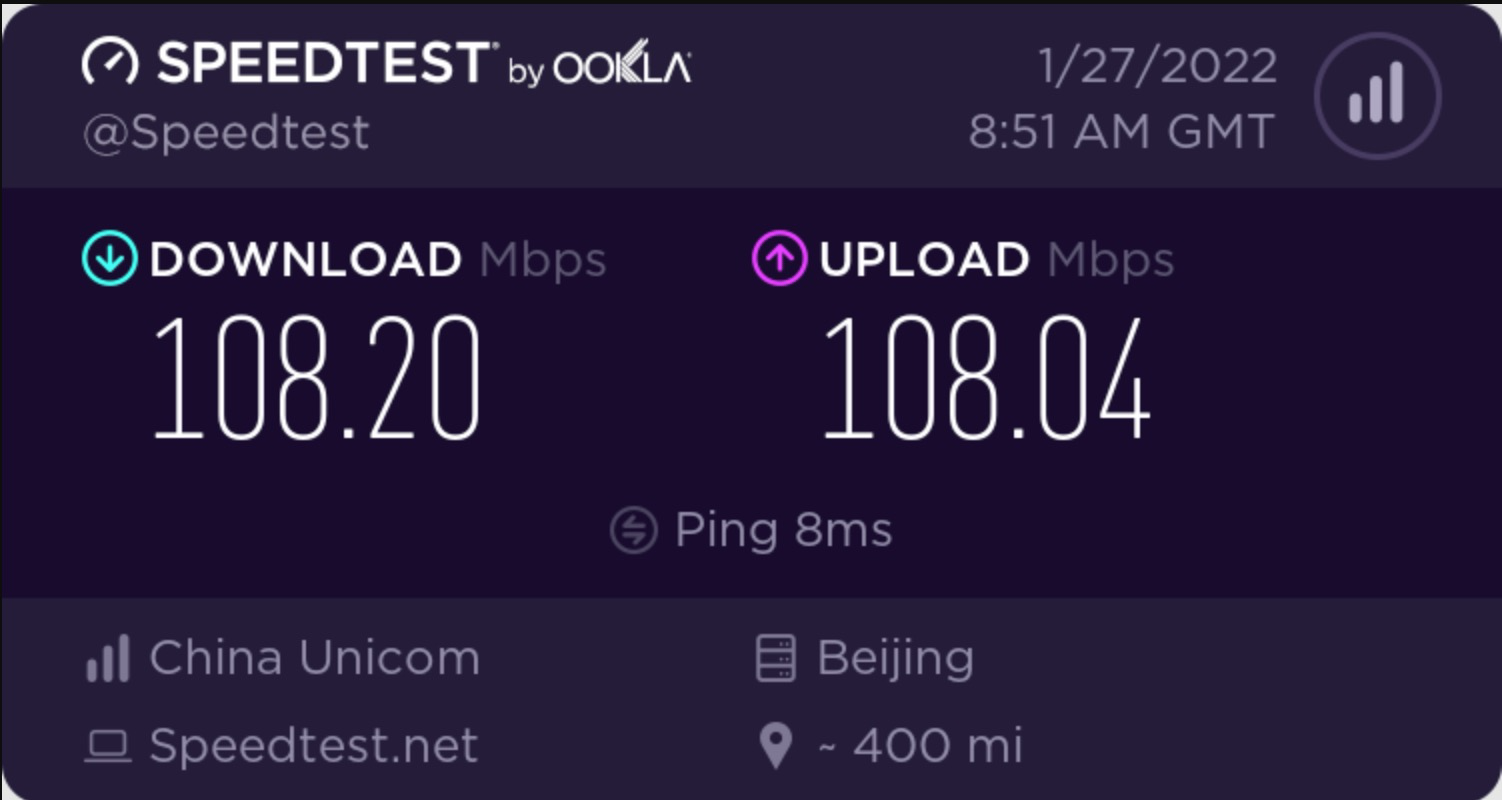
4.执行speedtest-cli --share,在浏览器请求http连接,如下所示
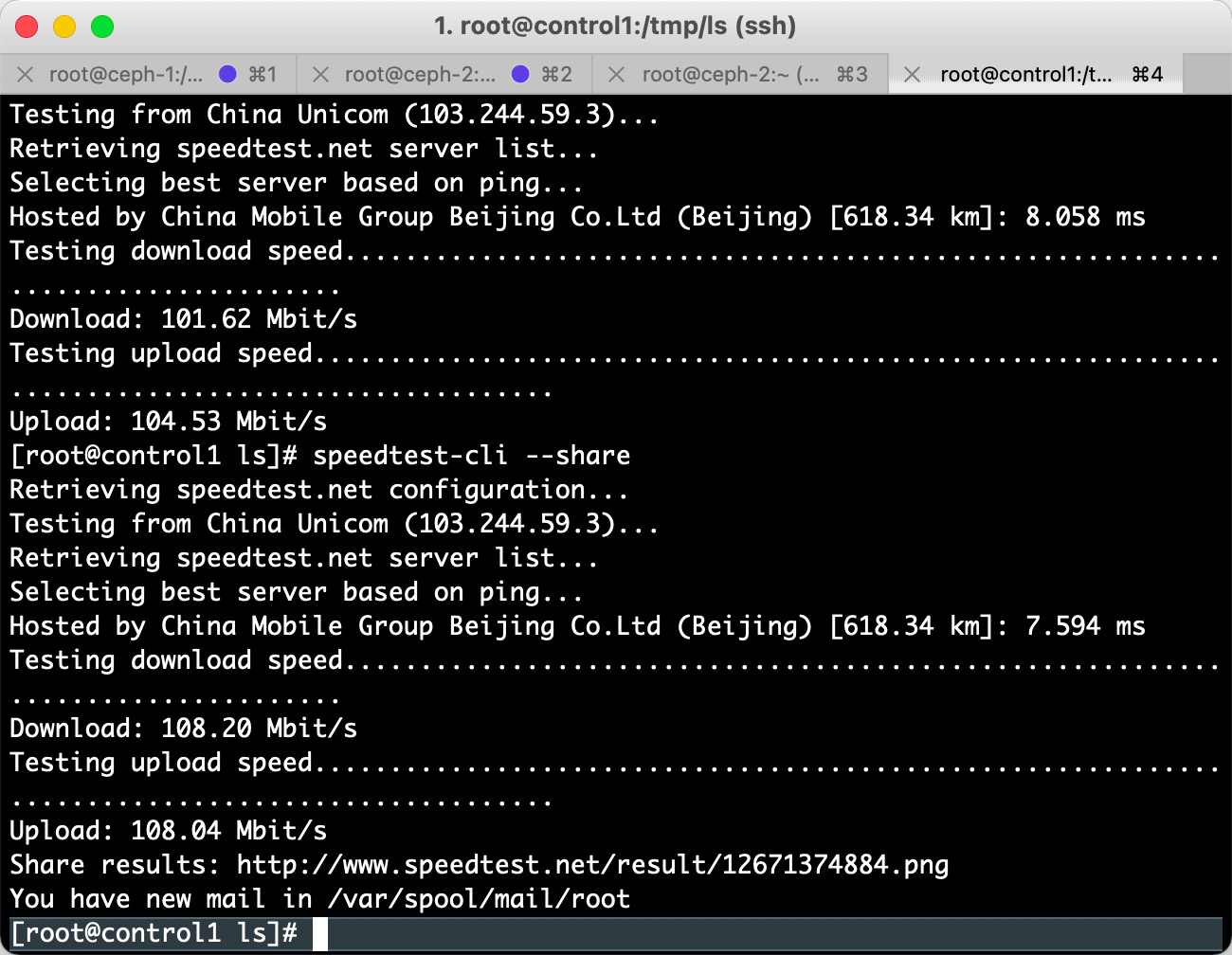
复制share results的链接,在浏览器打开
查看帮助信息:
speedtest-cli -h
48. [root@ceph-0 ~]# ceph osd df /ceph osd dump检查osd利用率
#!/bin/sh
ceph osd tree | gawk '{ print strftime("%b %d %H:%M:%S,control1,ceph-tree,info,bash:"), $0 }'
ceph osd df | gawk '{ print strftime("%b %d %H:%M:%S,contro1,ceph-df,info,bash:"), $0 }'
47. 容器资源 > 存储管理 > 存储类
分布式存储类配置文件
{
"kind": "StorageClass",
"apiVersion": "storage.k8s.io/v1",
"metadata": {
"name": "managed-nfs-storage",
"selfLink": "/apis/storage.k8s.io/v1/storageclasses/managed-nfs-storage",
"uid": "03e54050-9cc4-454d-884d-a902ae25f68c",
"resourceVersion": "1766",
"creationTimestamp": "2021-10-28T08:51:14Z",
"annotations": {
"kubectl.kubernetes.io/last-applied-configuration": "{\"apiVersion\":\"storage.k8s.io/v1\",\"kind\":\"StorageClass\",\"metadata\":{\"annotations\":{},\"name\":\"managed-nfs-storage\"},\"parameters\":{\"archiveOnDelete\":\"false\"},\"provisioner\":\"fuseim.pri/ifs\"}\n",
"storageclass.kubernetes.io/is-default-class": "true"
}
},
"provisioner": "fuseim.pri/ifs",
"parameters": {
"archiveOnDelete": "false"
},
"reclaimPolicy": "Delete",
"volumeBindingMode": "Immediate"
}
本地存储卷yaml配置文件
{
"kind": "StorageClass",
"apiVersion": "storage.k8s.io/v1",
"metadata": {
"name": "local-storage",
"selfLink": "/apis/storage.k8s.io/v1/storageclasses/local-storage",
"uid": "051f99cb-eb0a-4ca0-b0e4-761f0fc07059",
"resourceVersion": "2612708",
"creationTimestamp": "2021-11-03T06:00:05Z",
"annotations": {
"kubectl.kubernetes.io/last-applied-configuration": "{\"apiVersion\":\"storage.k8s.io/v1\",\"kind\":\"StorageClass\",\"metadata\":{\"annotations\":{},\"name\":\"local-storage\"},\"provisioner\":\"kubernetes.io/no-provisioner\",\"reclaimPolicy\":\"Delete\",\"volumeBindingMode\":\"WaitForFirstConsumer\"}\n"
}
},
"provisioner": "kubernetes.io/no-provisioner",
"reclaimPolicy": "Delete",
"volumeBindingMode": "WaitForFirstConsumer"
}
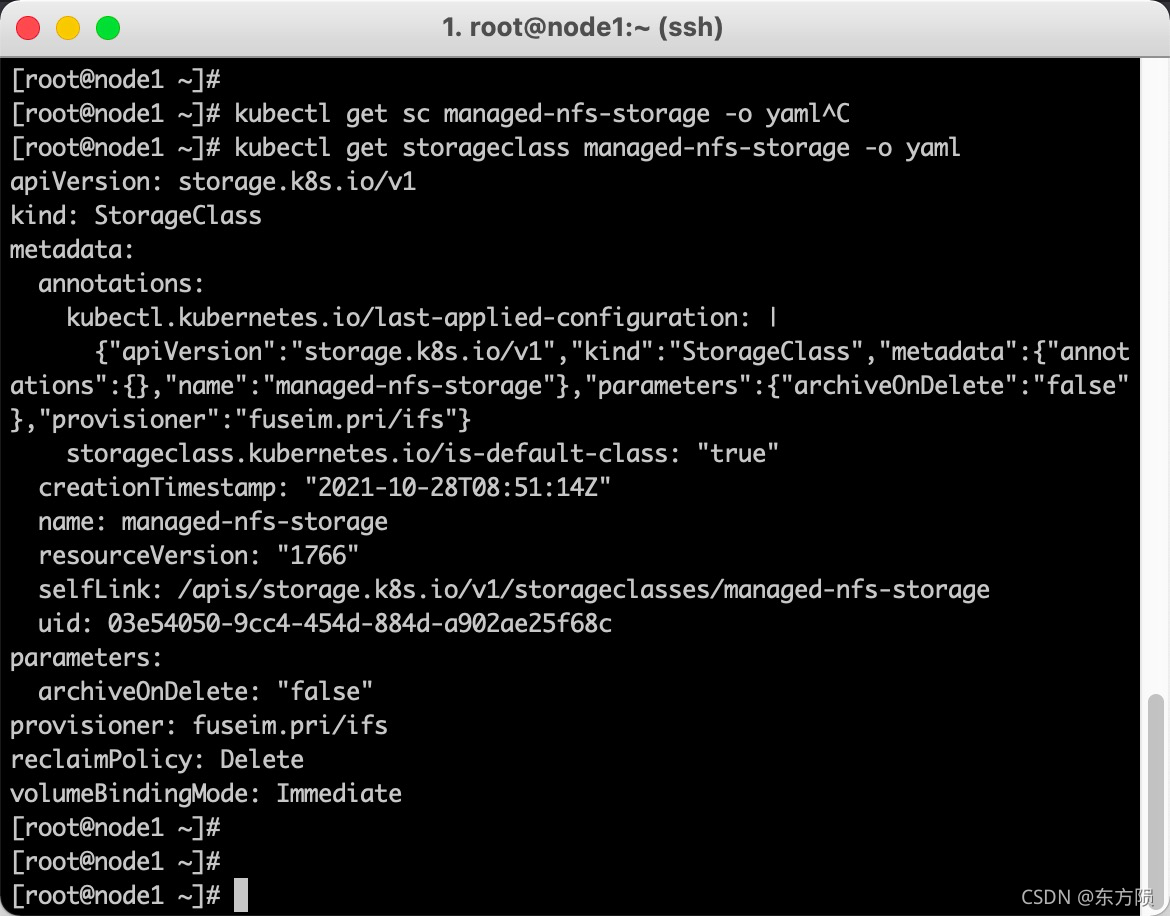
查看服务器存储类
[root@node1 ~]# kubectl get sc managed-nfs-storage -o yaml
或者
[root@node1 ~]# kubectl get storageclass managed-nfs-storage -o yaml
[root@node3 ~]# kubectl get storageclass managed-nfs-storage -o yaml 查看配置文件
[root@node1 ~]# kubectl edit storageclass managed-nfs-storage 编辑配置文件
46. 智能运维-日志中心 查找某段时间内的日志
host
[root@control3 log]# sed -n '/^Oct 29 19:26:01/,/^Oct 29 19:26:52/p' /var/log/messages | grep 'argument'
[root@control3 log]# sed -n '/^Oct 29 19:46:10/,/^Oct 29 19:47:01/p' /var/log/messages
统计字符出现的次数
:%s/Oct 29 19:50:22//gn
k3s
[root@k3sserver-1 ~]# grep '2021-10-29T20:24:38.' /var/lib/rancher/k3s/agent/containerd/containerd.log |wc -l
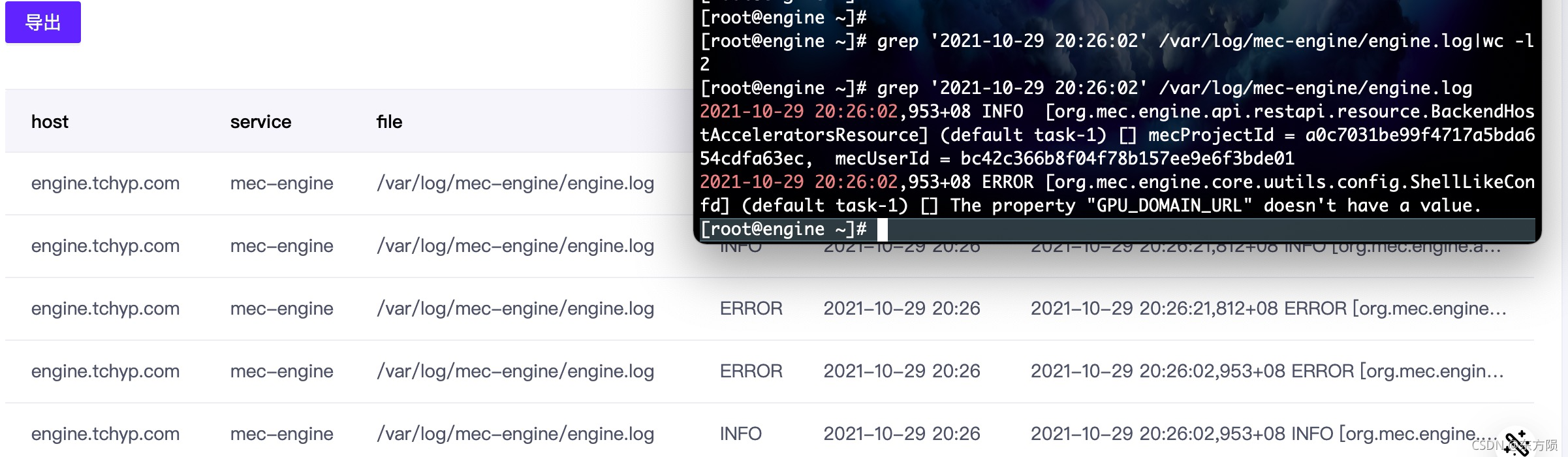
mec-engine
[root@engine ~]# grep '2021-10-29 20:26:02' /var/log/mec-engine/engine.log|wc -l
[root@engine ~]# grep '2021-10-29 20:26:02' /var/log/mec-engine/engine.log
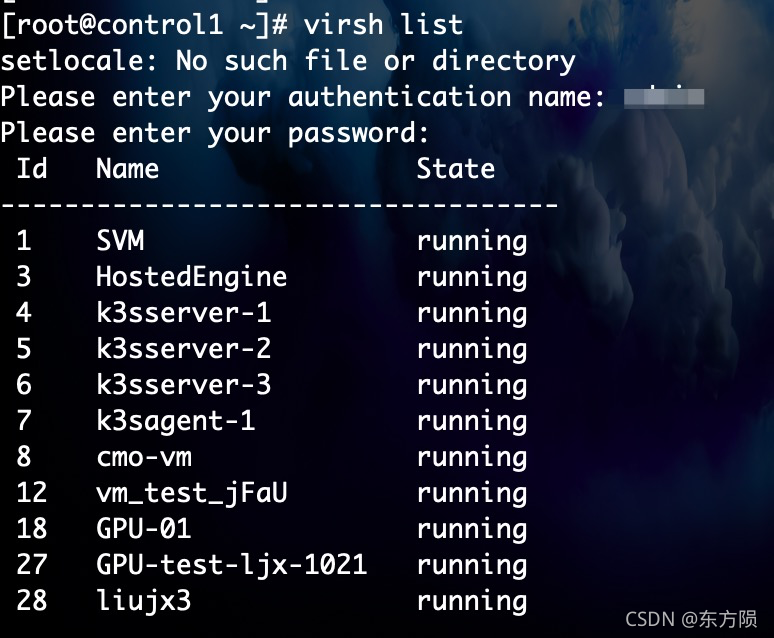
45. 边缘端资源管理 > 虚拟机资源 > 存储管理 > 磁盘
1> ssh 10.121.xx.xx 登录到k3s的物理节点
物理机显示虚拟机列表
virsh list
2> mount -> 172.xx:/ on /rhev/data-center/mnt/172.xx.xx:_ type ceph (rw,relatime,name=xx,secret=<hidden>,acl,mds_namespace=cephfs)
3> ssh 172.xx.xx 不需要密码
4> ceph osd pool ls 一个ceph集群可以有多个pool,查看ceph池子列表
fs_date
fs_date1
volumes 很多服务在volumes上面
images
backups
vms
kubernetes
5> 查看磁盘列表
rbd -p volumes ls
6> 查看磁盘详情
rbd -p volumes info volume-81229f81-27fa-4fb0-86d0-e43d1aaa59fa
44. 前端公钥加密,后端私钥解密
1 客户端输入口令点击登录,触发获取加密公钥
2 后端调用API返回公钥
3 客户终端使用公钥加密明文密码
4 后端调用API解密密文
java AES实现
43. # 查看所有 pod 列表, -n 后跟 namespace, 查看指定的命名空间
kubectl get pod
kubectl get pod -n kube
kubectl get pod -o wide
kubectl get pod -n logging
查看elasticsearch 前端方法:
1. 登陆MEPM/CMO后端
2. 找到对应的域名: kubectl get ingress -A|grep logging
3. 找到对应的端口: kubectl get svc -A|grep elastic
4. 拼接前端: <域名>:<端口>
[root@node1 ~]# kubectl get ingress -A|grep logging 找到对应的域名
logging elasticsearch-ingress elasticsearch.xx.xx.com ip 80 3h57m
[root@node1 ~]# kubectl get svc -A|grep elastic 找到对应的端口
logging elasticsearch-logging ClusterIP ip <none> 9200/TCP,9300/TCP 3h57m
logging elasticsearch-logging-outer NodePort ip <none> 9200:30200/TCP 3h57m
[root@node1 ~]# kubectl get pod -n logging
NAME READY STATUS RESTARTS AGE
elasticsearch-logging-0 1/1 Running 0 3h55m
elasticsearch-logging-1 1/1 Running 0 3h57m
elasticsearch-logging-2 1/1 Running 0 3h57m
fluentd-logging-es-2.8.0-99zcw 2/2 Running 1 3h52m
fluentd-logging-es-2.8.0-wdclz 2/2 Running 1 3h52m
fluentd-logging-es-2.8.0-zgd52 2/2 Running 1 3h52m
log-init-job-8j8dp 0/1 Completed 0 3h49m
logservice-logging-b4ff66654-fl9xt 1/1 Running 0 3h50m
logservice-logging-b4ff66654-qnc64 1/1 Running 0 3h50m
logservice-logging-b4ff66654-qzxw7 1/1 Running 0 3h50m
[root@node1 ~]# kubectl get cm -n logging 查看配置文件
NAME DATA AGE
elasticsearch-logging-config 6 3h57m
fluentd-logging-config 7 3h57m
log-init-logging-config 5 3h57m
logservice-logging-config 5 3h57m
[root@node1 ~]# kubectl edit cm logservice-logging-config -n logging 编辑配置文件
Edit cancelled, no changes made.
查看 ConfigMap
kubectl get cm <ConfigMap Name>
修改 ConfigMap
kubectl edit cm <ConfigMap Name>
42. 比如一个虚拟机 磁盘是100G 预估的分析是10天的数据,每天按照10G消耗,呈现线型上升,则通过前几天的数据 预估后几天的走势。如果是陡坡趋势 则预估的趋势同理。待RD提供相关的API文档,数据表,测试方法,相关算法 模型(线性模型,prometheus、arima)等
算法模块参考文档
时间序列模型(ARIMA)
时间序列模型Prophet使用详细讲解
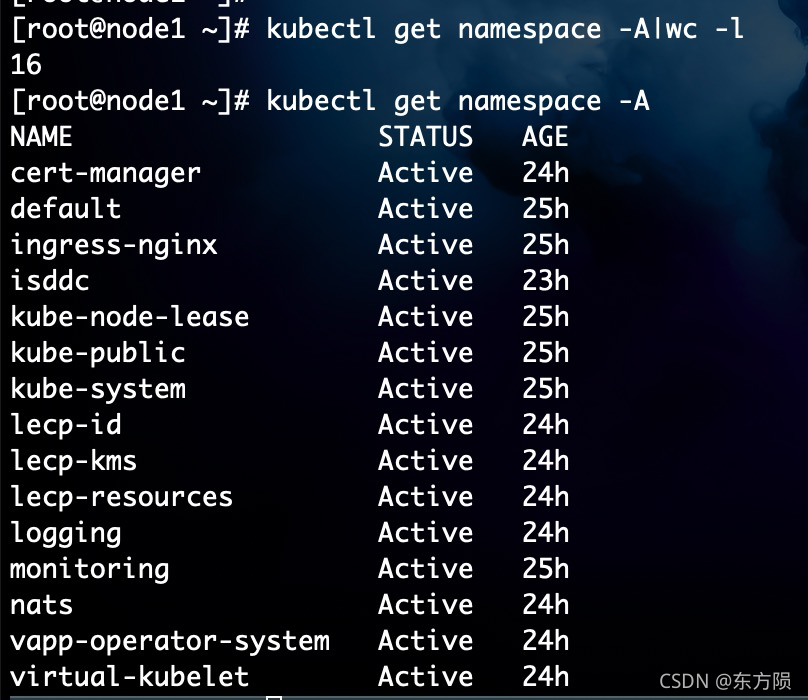
41. 容器资源 > 命名空间管理
[root@node1 ~]# kubectl get namespace -A|wc -l
16
[root@node1 ~]# kubectl get namespace -A
NAME STATUS AGE
cert-manager Active 24h
default Active 25h
ingress-nginx Active 25h
isddc Active 23h
kube-node-lease Active 25h
kube-public Active 25h
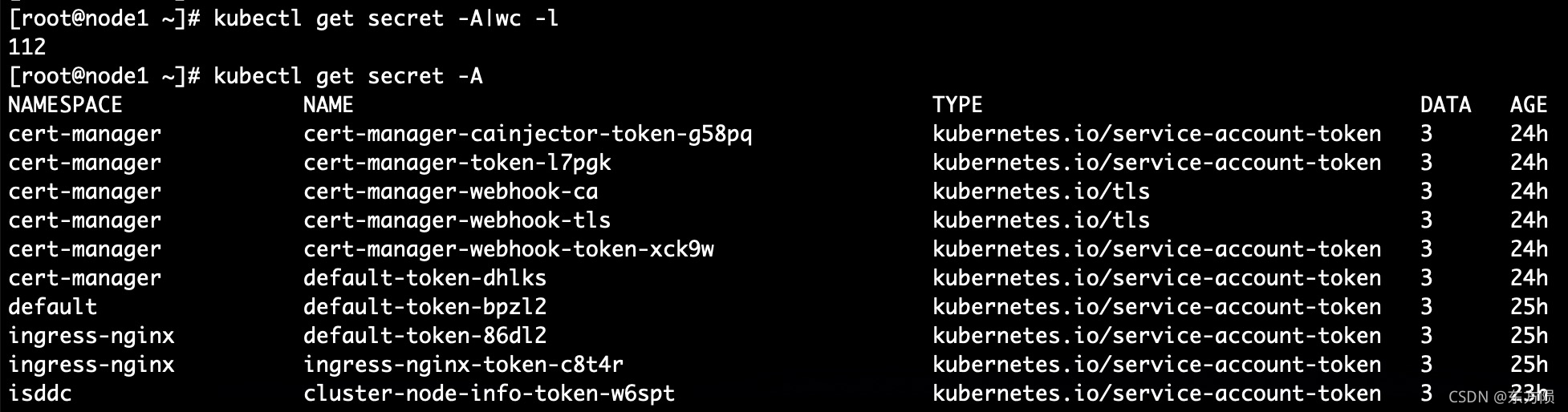
40. 容器资源 > 配置 > 秘钥
[root@node1 ~]# kubectl get secret -A|wc -l
112
[root@node1 ~]# kubectl get secret -A
NAMESPACE NAME TYPE DATA AGE
cert-manager cert-manager-cainjector-token-g58pq kubernetes.io/service-account-token 3 24h
default default-token-bpzl2 kubernetes.io/service-account-token 3 25h
ingress-nginx default-token-86dl2 kubernetes.io/service-account-token 3 25h
查看秘钥详情 kubectl describe secret {{secretname}} -n {{secretnamespace}}
[root@node1 ~]# kubectl describe secret cert-manager-cainjector-token-xhq4d -n cert-manager
39. 容器资源 > 配置 > 配置项
[root@node1 ~]# kubectl get configmap -A
NAMESPACE NAME DATA AGE
default blueprint-tpl-ftvpcy 1 21h
default input-tomcat1739-mowhcc 1 20h
ingress-nginx ingress-nginx 0 25h
ingress-nginx tcp-services 3 25h
ingress-nginx udp-services 0 25h
38. 容器资源 > 服务和负载均衡 > 服务入口
[root@node1 ~]# kubectl get ingress -A|wc -l
7
[root@node1 ~]# kubectl get ingress -A
NAMESPACE NAME HOSTS ADDRESS PORTS AGE
isddc isddc-grafana grafana.xx.com 172.xx 80, 443 20h
kube-system fileserver-ingress fileserver.xx.com 172.xx 80, 443 22h

37. 容器资源 > 服务和负载均衡 > 服务
[root@node1 ~]# kubectl get service -A|wc -l
78
[root@node1 ~]# kubectl get service -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
cert-manager cert-manager ClusterIP 10.xx <none> 9402/TCP
37. 容器资源 > 工作负载 > 容器组
[root@node1 ~]# kubectl get pod -A|wc -l
145
[root@node1 ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
cert-manager cert-manager-85c5f85645-z4684 1/1 Running 0 22h
cert-manager cert-manager-cainjector-7c4fdd9744-2ms8k 1/1 Running 5 22h
36. 容器资源 > 工作负载 > 定时任务
[root@node1 ~]# kubectl get cronjob -A
No resources found.
35. 容器资源 > 工作负载 > 任务
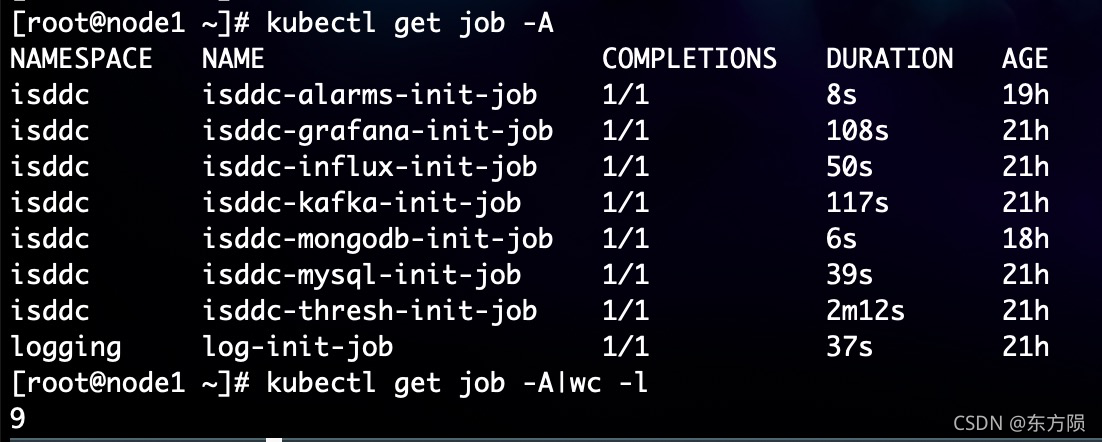
[root@node1 ~]# kubectl get job -A|wc -l
9
[root@node1 ~]# kubectl get job -A
NAMESPACE NAME COMPLETIONS DURATION AGE
isddc isddc-alarms-init-job 1/1 8s 19h
isddc isddc-grafana-init-job 1/1 108s 21h
34. 容器资源 > 工作负载 > 守护进程服务
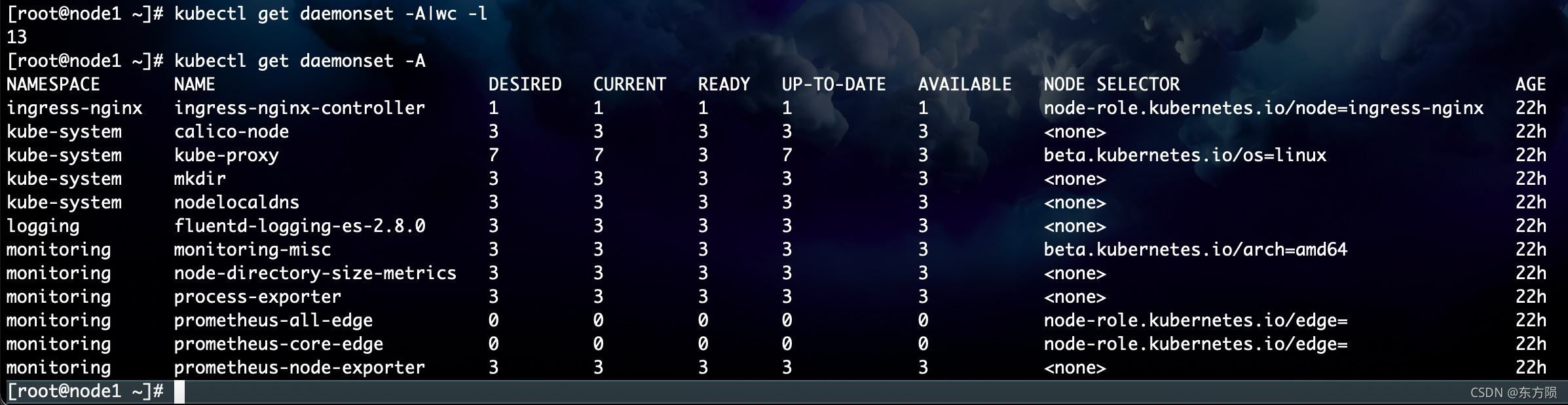
[root@node1 ~]# kubectl get daemonset -A|wc -l
13
[root@node1 ~]# kubectl get daemonset -A
NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE ingress-nginx ingress-nginx-controller 1 1 1 1 1 node-role.kubernetes.io/node=ingress-nginx 22h
kube-system calico-node 3 3 3 3 3 <none> 22h
kube-system kube-proxy 7 7 3 7 3 beta.kubernetes.io/os=linux 22h
kube-system mkdir 3 3 3 3 3 <none> 22h
查看服务进程daemonset某个服务的yaml文件
kubectl get daemonset {{daemonsetname}} -n {{namespace}} -o yaml
如[root@node3 ~]# kubectl get daemonset ingress-nginx-controller -n ingress-nginx -o yaml
编辑服务进程daemonset的yaml文件
kubectl edit daemonset {{daemonsetname}} -n {{namespace}}
33. 容器资源 > 工作负载 > 有状态服务
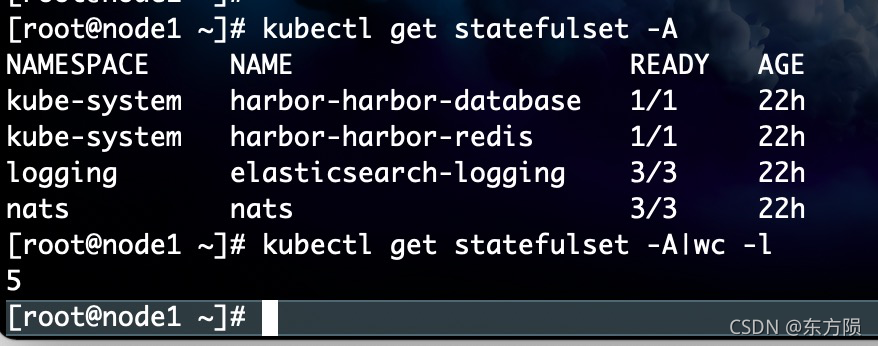
[root@node1 ~]# kubectl get statefulset -A
NAMESPACE NAME READY AGE
kube-system harbor-harbor-database 1/1 22h
kube-system harbor-harbor-redis 1/1 22h
logging elasticsearch-logging 3/3 22h
nats nats 3/3 22h
[root@node1 ~]# kubectl get statefulset -A|wc -l
5
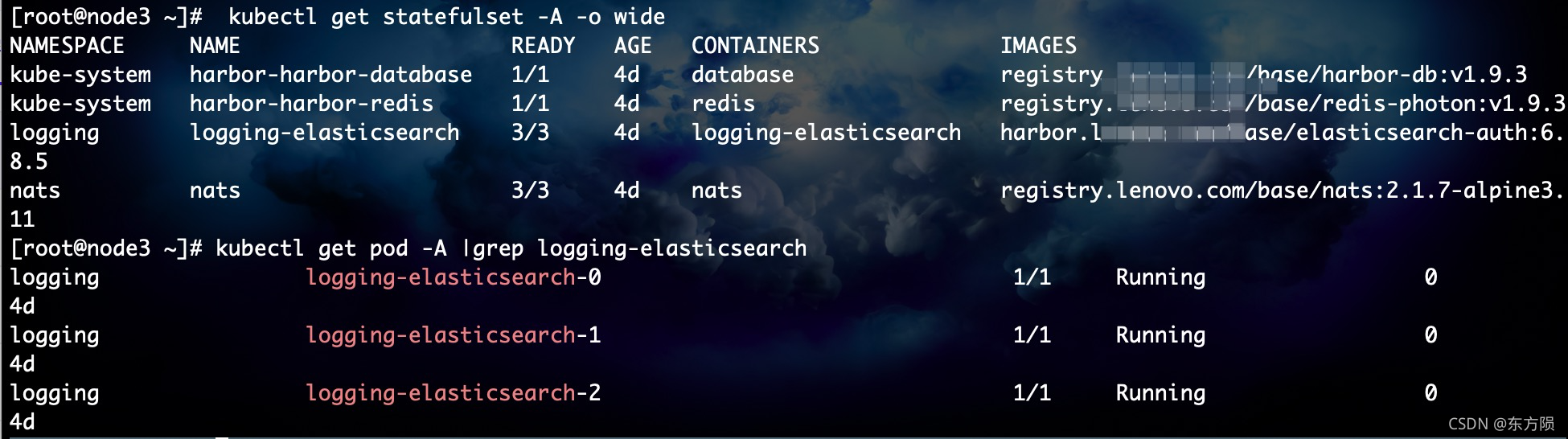
[root@node1 ~]# kubectl get pod -A -o wide|grep logging-elasticsearch 查看容器组详细信息

32. 容器资源 > 工作负载 > 无状态服务
[root@node1 ~]# kubectl get deployment -A|wc -l
84
[root@node1 ~]# kubectl get deployment -A
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
cert-manager cert-manager 1/1 1 1 22h
cert-manager cert-manager-cainjector 1/1 1 1 22h
cert-manager cert-manager-webhook 1/1 1 1 22h
default depoly1731 1/1 1 1 18h
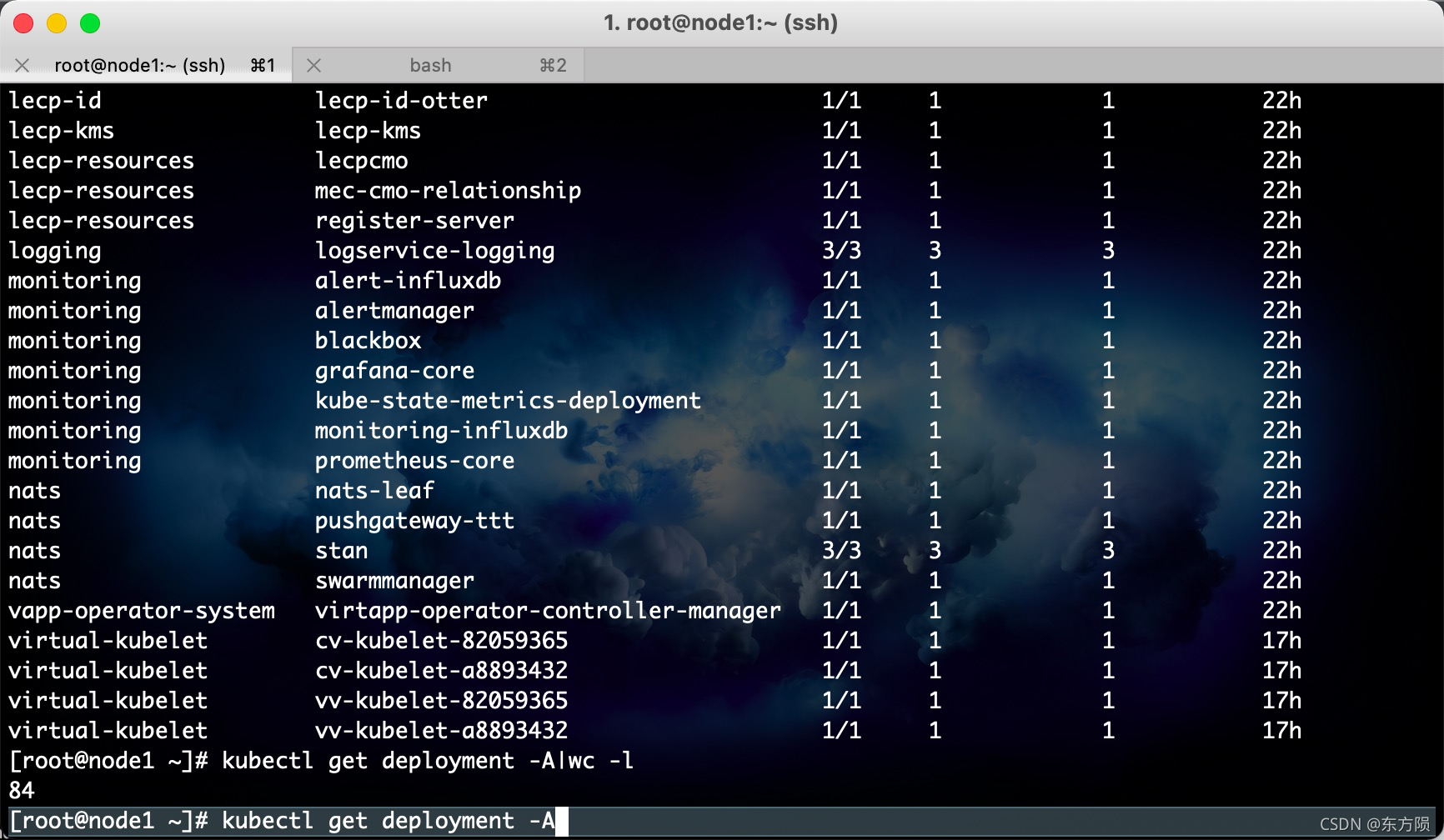
[root@node1 ~]# kubectl get deployment -A -o wide -o wide 查看详细信息
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
命名空间 服务名称 状态 是否可用 运行时长
CONTAINERS IMAGES
容器 镜像
SELECTOR
服务选择
cert-manager cert-manager 1/1 1 1 45h
cert-manager registry.xx.com/base/cert-manager-controller:v0.14.0 app.kubernetes.io/component=controller,app.kubernetes.io/instance=cert-manager,app.kubernetes.io/name=cert-manager

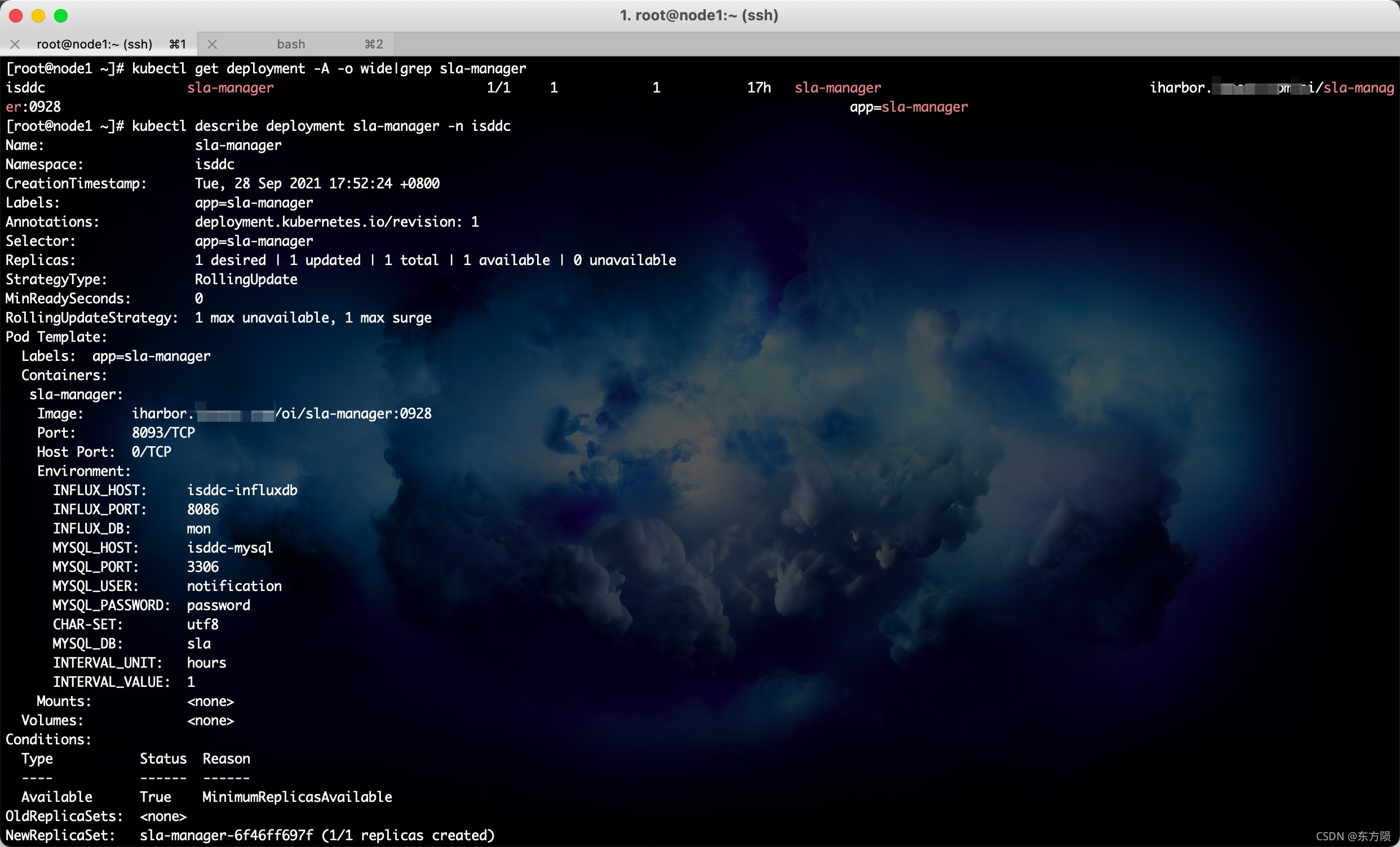
查看服务详情
kubectl describe 服务类型 name -n namespace命名空间
kubectl describe deployment sla-manager -n isddc
31. 存储类storageclass
本地存储local-storage:
先创建pv再创建pvc(pvc用pv),创建完pvc,pv的name namespace会自动绑定pvc的信息
再去服务器创建pod 修改namespace为default 修改deployment的namespace
删除pvc的时候保证没有pod在使用 删pv保证没有pvc再用
删除storgeclass的时候保证没有pv再用
状态:avaliable release 绑定后才是bound
如何关联绑定pv pvc?在页面操作:
在存储卷声明pv编辑yaml文件:
在
"storageClassName": "local-storage",
"volumeMode": "Filesystem"
前新增/插入/添加 这么记录是为了以后搜索关键字方便。。。。
"volumeName": "pv的name",

完整pv配置文件yaml
{
"kind": "PersistentVolume",
"apiVersion": "v1",
"metadata": {
"name": "pv1015ls1838",
"selfLink": "/api/v1/persistentvolumes/pv1015ls1838",
"uid": "93e08254-94b1-44e6-9ce5-93119b657eda",
"resourceVersion": "5989164",
"creationTimestamp": "2021-10-15T10:38:30Z",
"annotations": {
"pv.kubernetes.io/bound-by-controller": "yes"
},
"finalizers": [
"kubernetes.io/pv-protection"
]
},
"spec": {
"capacity": {
"storage": "10Gi"
},
"local": {
"path": "/var/localpv/lili"
},
"accessModes": [
"ReadWriteOnce"
],
"claimRef": {
"kind": "PersistentVolumeClaim",
"namespace": "default",
"name": "pvc1015ls1838",
"uid": "8788d7ff-3e45-477d-8cae-65aef7547693",
"apiVersion": "v1",
"resourceVersion": "5989161"
},
"persistentVolumeReclaimPolicy": "Retain",
"storageClassName": "local-storage",
"volumeMode": "Filesystem",
"nodeAffinity": {
"required": {
"nodeSelectorTerms": [
{
"matchExpressions": [
{
"key": "kubernetes.io/hostname",
"operator": "In",
"values": [
"node1"
]
}
]
}
]
}
}
},
"status": {
"phase": "Bound"
}
}
完整pvc配置文件yaml
{
"kind": "PersistentVolumeClaim",
"apiVersion": "v1",
"metadata": {
"name": "pvc1015ls1838",
"namespace": "default",
"selfLink": "/api/v1/namespaces/default/persistentvolumeclaims/pvc1015ls1838",
"uid": "8788d7ff-3e45-477d-8cae-65aef7547693",
"resourceVersion": "5989166",
"creationTimestamp": "2021-10-15T10:38:54Z",
"annotations": {
"pv.kubernetes.io/bind-completed": "yes"
},
"finalizers": [
"kubernetes.io/pvc-protection"
]
},
"spec": {
"accessModes": [
"ReadWriteOnce"
],
"resources": {
"requests": {
"storage": "10Gi"
}
},
"volumeName": "pv1015ls1838",
"storageClassName": "local-storage",
"volumeMode": "Filesystem"
},
"status": {
"phase": "Bound",
"accessModes": [
"ReadWriteOnce"
],
"capacity": {
"storage": "10Gi"
}
}
}
目标是要建立一pod:
1 创建盘:kubectl create -f pvc-test1.yml
2 创建pod: kubectl create -f deployment1.yaml
查看pvc : kubectl get pvc -A |grep <pvc-log1>
查看pod : kubectl get pod -A|grep <ssh-storage-test1>
删除pvc的时候保证没有pod在使用 删pv保证没有pvc再用
删除storgeclass的时候保证没有pv再用
状态:avaliable release 绑定后才是bound
创建pvc填写的路径会在/var/localpv添加新的文件夹
登录A机器(144.62) 拷贝文件夹到测试服务器
scp -r /mnt/xx/sdk/daystar/storage/beijing/ root@10.xx/mnt/xx/sdk/daystar/storage
分布式存储:
只需要创建pvc 不需要创建pv
pvc不需要绑定 创建完成状态就是bound
创建StorageClass资源(yaml方式)
$ kubectl create -f storageclass_test.yaml
查看StorageClass资源
$ kubectl get storageclass -n ns1
我们也可以通过缩写进行查看kubectl get sc
查看某个StorageClass资源详情
$ kubectl describe sc sc_name
其中,sc_name为StorageClass资源的名称
删除StorageClass资源
$ kubectl delete sc sc_name
其中,sc_name为StorageClass资源的名称
列出/查看集群中的 storageclass
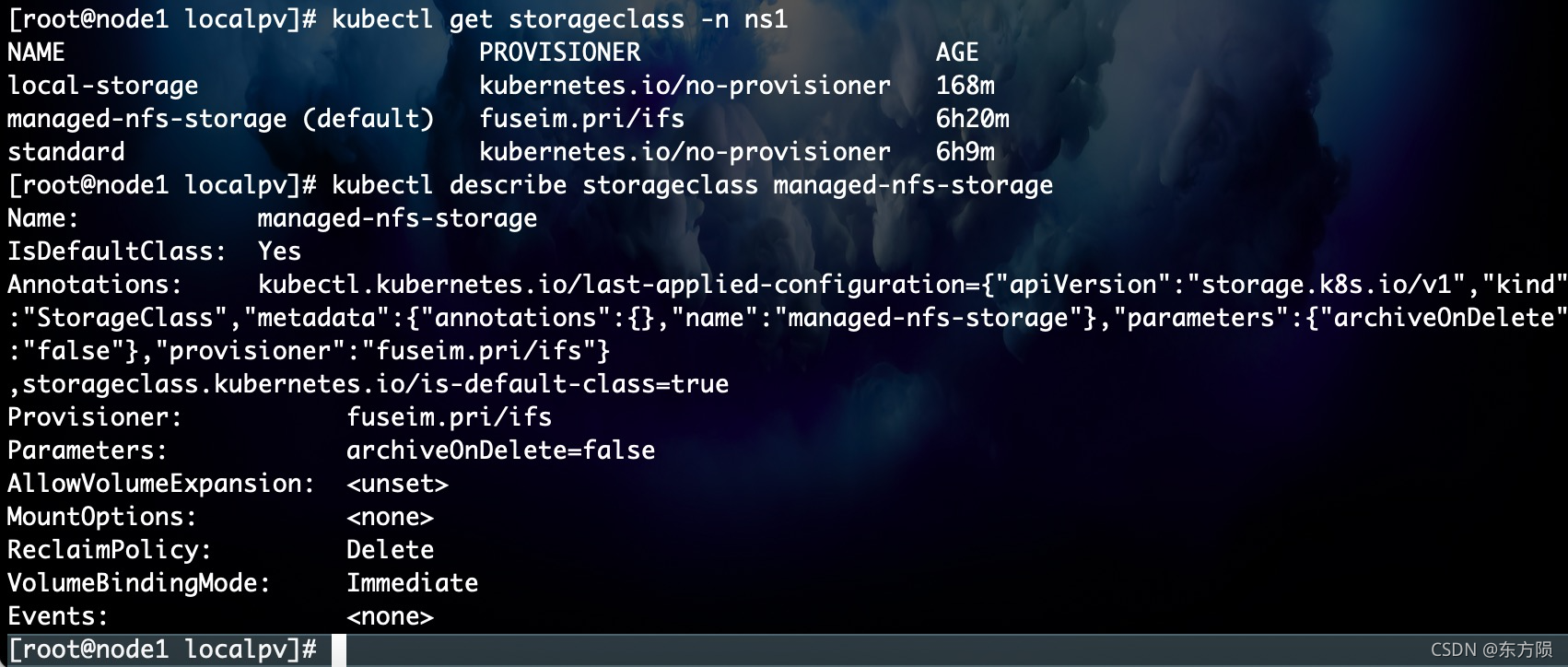
kubectl get storageclass -A
kubectl get storageclass -n ns1
或者 kubectl get storageclasses.storage.k8s.io
[root@node1 home]# kubectl get storageclass
NAME PROVISIONER AGE
managed-nfs-storage (default) fuseim.pri/ifs 3h25m
standard kubernetes.io/no-provisioner 3h13m
显示local 和 standard类型
kubectl get storageclass standard 查看standard类型
统计storageclass个数
kubectl get storageclass -A|wc -l
kubectl describe storageclass managed-nfs-storage
查看storageclass详情 kubectl describe storageclass storageclass的name
查看默认存储类 输出yaml文件
kubectl get storageclass standard -o yaml

查看服务yaml配置文件
kubectl get storageclass managed-nfs-storage -o yaml

pv和pvc的使用
存储工程师把分布式存储系统上的总空间划分成一个一个小的存储块
k8s管理员根据存储块创建与之一一对应的pv资源
pv属于集群级别资源 不属于任何名称空间 定义的时候不能指定名称空间
用户在创建pod的时候同时创建与pv一一对应的pvc资源
创建Pod的时候,系统里并没有合适的PV跟它定义的PVC绑定 也就是说此时容器想要使用的Volume不存在。这时候Pod的启动就会报错
创建小的存储块
创建pv资源
创建pod和pvc资源
演示结果
30. 存储卷声明pvc
参考博客 k8s 搭建nginx实例(service、configmap和deployment组合)
创建与搭建好的44.62服务器一样的环境
mkdir -p /mnt/xx/sdk/daystar/storage
拷贝远程服务器文件到本机
[root@master1 ~]# scp -r root@xx.xx.144.62://mnt/xx/sdk/daystar/storage/* /mnt/xx/sdk/daystar/storage
启动盘需要依赖镜像
需要把image(镜像)提前加载到对应的node上 如果先创建的pvc和pod再加载镜像
cd /mnt/xx/sdk/daystar/storage
加载镜像
docker load -i centos_v3.tar.gz
目标是要建立一pod:
1 创建pvc盘:kubectl create -f pvc-test1.yml
2 创建pod: kubectl create -f deployment1.yml
查看pvc : kubectl get pvc -A |grep <pvc.yml的name>
查看pod : kubectl get pod -A|grep <deployment.yml的name>
查看pod详情, kubectl describe pod pod服务名称 -n pod的namespace命名空间
[root@node1 tmp]# kubectl describe pod ssh-storage-podxx -n kube-system
删除盘和pod
kubectl delete -f <pvc.yaml>
kubectl delete -f <deployment.yml>


创建的pvc.yml为
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-log1
namespace: kube-system
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 20Gi
storageClassName: managed-nfs-storage
volumeMode: Filesystem
status:
accessModes:
- ReadWriteMany
capacity:
storage: 20Gi
phase: Bound
创建的deployment.yml为
apiVersion: apps/v1
kind: Deployment
metadata:
name: ssh-storage-test1
namespace: kube-system
spec:
selector:
matchLabels:
name: ssh-storage-test1
replicas: 1
template:
metadata:
labels:
name: ssh-storage-test1
spec:
nodeSelector:
kubernetes.io/hostname: node5
containers:
- name: ssh-storage-test1
image: centos:3
imagePullPolicy: IfNotPresent
securityContext:
privileged: true
resources:
limits:
memory: "1Gi"
cpu: "0.1"
requests:
memory: "1Gi"
cpu: "0.1"
ports:
- containerPort: 22
volumeMounts:
- mountPath: "/logs"
name: pvc-log
volumes:
- name: pvc-log
persistentVolumeClaim:
claimName: pvc-log
---
apiVersion: v1
kind: Service
metadata:
name: ssh-storage-test1
spec:
selector:
name: ssh-storage-test1
ports:
- port: 10000
targetPort: 22
29. 查看存储卷声明pvc
统计pvc个数
kubectl get pvc -A | wc -l
[root@node1 ~]# kubectl get pvc -A -o wide
NAMESPACE NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE VOLUMEMODE
isddc isddc-arangodb Bound isddc-arangodb 50Gi RWO
standard 10d Filesystem
isddc isddc-influxdb Bound isddc-influxdb 100Gi RWO standard 10d Filesystem
isddc isddc-kafka Bound isddc-kafka 100Gi RWO standard 10d Filesystem

查看某个存储类,grep 存储类名
[root@node1 ~]# kubectl get pvc -A -o wide|grep managed-nfs-storage

查看存储某个服务的yaml文件
kubectl get pvc {{pvcname}} -n {{namespace}} -o yaml
如 [root@node3 ~]# kubectl get pvc isddc-influxdb -n isddc -o yaml
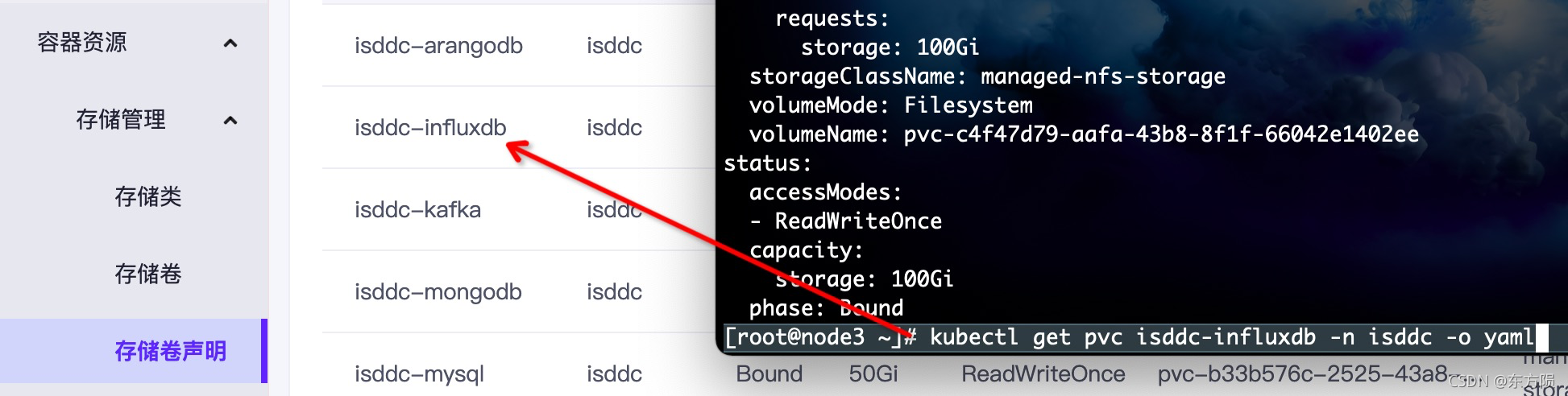
编辑存储某个服务的yaml文件
kubectl edit pvc {{pvcname}} -n {{namespace}}
如[root@node3 ~]# kubectl get pvc isddc-influxdb -n isddc -o yaml

容器资源 > 存储管理 > 存储卷pv
kubectl get pv -A -o wide
统计存储卷pv个数
kubectl get pv -A | wc -l
查看存储卷pv某个服务的yaml文件
kubectl get pv {{pvname}} -n {{namespace}} -o yaml
如[root@node3 ~]# kubectl get pv pvc-0f402491-84bc-4c8d-a585-3c1f72d0d005 -n isddc -o yaml
编辑存储卷pv某个服务的yaml文件
kubectl edit pv {{pvname}} -n {{namespace}}
如[root@node3 ~]# kubectl edit pv pvc-0f402491-84bc-4c8d-a585-3c1f72d0d005 -n isddc

28. cat显示指定的行
【一】从第3000行开始,显示1000行。即显示3000~3999行
cat filename | tail -n +3000 | head -n 1000
【二】显示1000行到3000行
cat filename| head -n 3000 | tail -n +1000
*注意两种方法的顺序
分解:
tail -n 1000:显示最后1000行
tail -n +1000:从1000行开始显示,显示1000行以后的
head -n 1000:显示前面1000行
【三】用sed命令
sed -n '5,10p' filename 这样你就可以只查看文件的第5行到第10行
[root@node1 ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
ceph-csi-plugin hcp-ceph-csi-rbd-nodeplugin-9r9gd 3/3 Running 0 28d
ceph-csi-plugin hcp-ceph-csi-rbd-nodeplugin-lf2l8 3/3 Running 0 28d
[root@node1 ~]# kubectl get pod -A|awk '{print $2"|||"$4","}' > k8spod.txt
[root@node1 ~]# cat k8spod.txt |wc -l
172
[root@node1 ~]# cat k8spod.txt|tail -n +150|head -n 50

27. k8s查看集群下的各节点
查看cluster下全部pod
kubectl get pod -A -o wide
展示字段:NAMESPACE NAME READY STATUS RESTARTS AGE IP
查看cluster下某个pod
[root@node1 ~]# kubectl get pod -A|grep hcp-ceph-csi-rbd-provisioner-xx-p8nl7
ceph-csi-plugin hcp-ceph-csi-rbd-provisioner-xx-p8nl7 6/6 Running 0 20d
登录到某个pod
kubectl exec isddc-api-xx-ptmkv -n isddc -it sh
查看pod的id,2个变量分别为kubectl get pod -A -o wide 的第一二列
kubectl get pods -n <namespace> <pod-name> -o jsonpath='{.metadata.uid}'

查看全部node
边缘端资源管理 > 主机资源 > 查看容器主机
kubectl get node -A -o wide
kubectl get node -A
查看某个node的id
kubectl get node node2 -o jsonpath='{.metadata.uid}'
kubectl get node <node-name> -o jsonpath='{.metadata.uid}'

查看ingress
kubectl get ingress -A
字段:NAMESPACE NAME HOSTS ADDRESS PORTS AGE
[root@node1 ~]# kubectl get ingress -A -o wide|grep hydra-login-consent-node
kube-system hydra-login-consent-node login.xx.xx.cloud 10.121.xx.xx,10.121.xxx.xxx9 80, 443 21d

查看某个ingress的id
[root@node1 ~]# kubectl get ingress -n isddc isddc-grafana -o jsonpath='{.metadata.uid}'
kubectl get ingress -n <namespace> <ingress-name> -o jsonpath='{.metadata.uid}'

把每个service的name写到文件
kubectl get svc -A -o wide|awk '{print $2}'>service.txt
用shell处理文本在每行后面追加|||active
sed 's/$/|||active,/g' service.txt

查看service
[root@node1 ~]# kubectl get svc -A -o wide|grep appmanager
kube-system appmanager ClusterIP 10.xx.xx.xxx <none> 80/TCP
查看某个service的id
[root@node1 ~]# kubectl get svc -n kube-system appmanager -o jsonpath='{.metadata.uid}'
kubectl get svc -n <namespace> <svc-name> -o jsonpath='{.metadata.uid}'

26. 查看此集群下的所有域名
kubectl get ingress -A

25. 磁盘读写测试 disk read disk write 磁盘利用率 服务器不支持rz sz
修改机器yum源为阿里的源
如果机器没有wget 先安装 yum install wget -y
1. 备份源文件
[root@node1 ~]# mv /etc/yum.repos.d/base.repo /etc/yum.repos.d/CentOS-Base.repo_bak
命名不同而已
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo_bak
2. 获取源文件
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
3.重新设置缓存
yum clean all
清除缓存
yum makecache
重新生成缓存,加速访问和下载
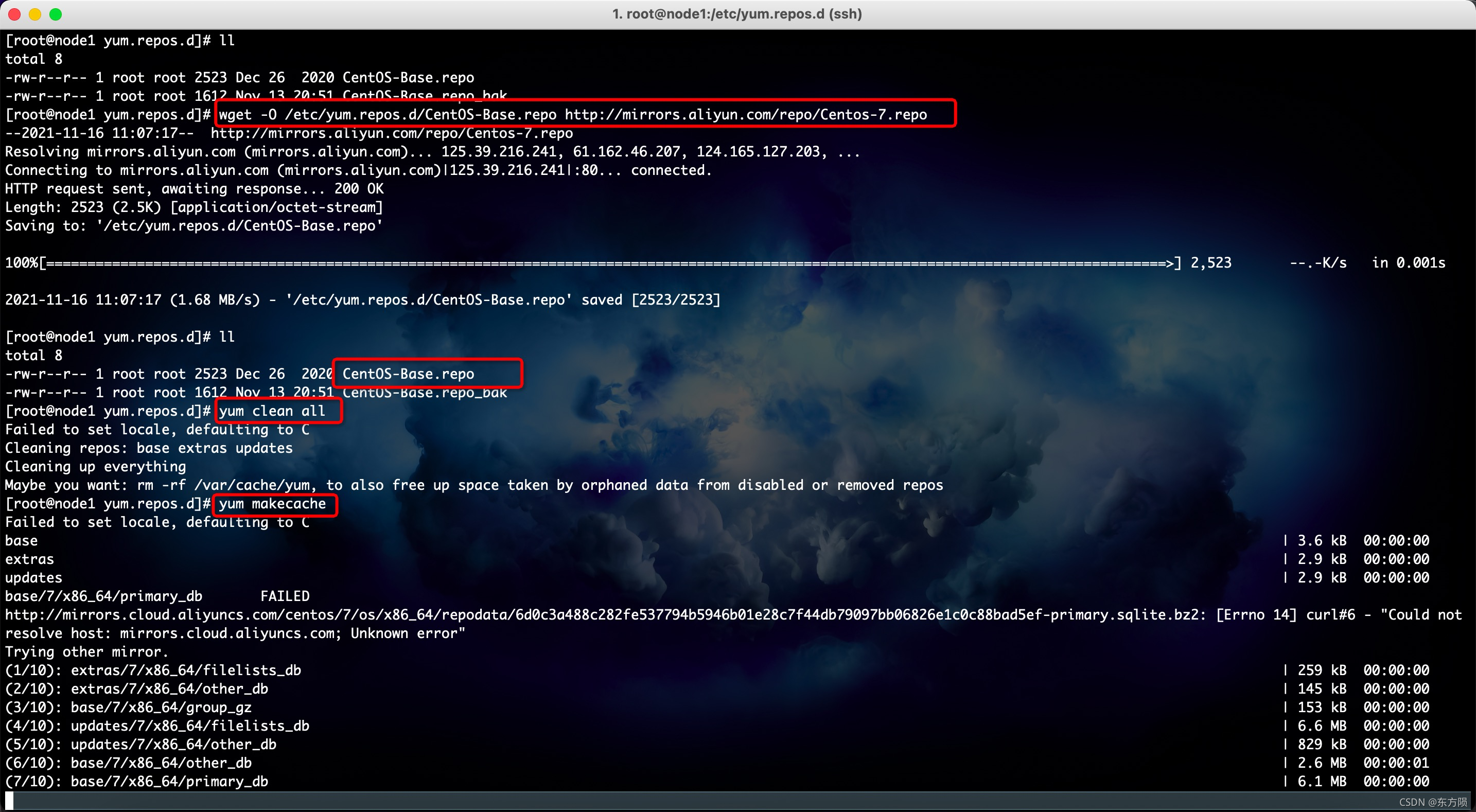
比如安装rzsz
[root@node1 yum.repos.d]# yum install -y lrzsz

4. iostat是I/O statistics(输入/输出统计)的缩写,iostat工具将对系统的磁盘操作活动进行监视。它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况。iostat也有一个弱点,就是它不能对某个进程进行深入分析,仅对系统的整体情况进行分析
iostat属于sysstat软件包。可以直接安装
yum install sysstat -y
iostat -d /dev/sda -d:仅显示设备利用率;
iostat 2 每2秒读取一次数据
dd if=/dev/zero of=/disk/data.log bs=1KB count=3076
每次写入数据大小为1KB,写3076个
在/根目录下创建文件/disk/data.log
执行
顺序读 MBps
fio -runtime=3000 -filename=/disk/data.log -direct=1 -thread -rw=read -bs=4k -size=30G -iodepth=64 -ioengine=libaio -name=mytest>>/read.log
顺序写 MBps
fio -runtime=3000 -filename=/disk/data.log -direct=1 -thread -rw=write -bs=4k -size=30G -iodepth=64 -ioengine=libaio -name=mytest>>/write.log
随机写 IOps
fio -runtime=3000 -filename=/disk/data.log -direct=1 -thread -rw=randwrite -bs=4k -size=30G -iodepth=64 -ioengine=libaio -name=mytest>>/randwrite.log
随机读 IOps
fio -runtime=3000 -filename=
测试完毕把/disk/data.log删除
24. kubectl edit cm -n kube-system xxversion
编辑配置文件
23. kubectl get configmap -n kube-system configmap
查看所有的configmap
# 查看所有 pod 列表, -n 后跟 namespace, 查看指定的命名空间
kubectl get pod kubectl get pod -n kube kubectl get pod -o wide
# 查看 RC 和 service 列表, -o wide 查看详细信息
kubectl get rc,svc kubectl get pod,svc -o wide kubectl get pod <pod-name> -o yaml
参考kubectl 常用命令总结 - klvchen - 博客园
22. kubectl get ingress -A
可以看到前端对应的URL
[root@node1 ~]# kubectl get ingress -A
NAMESPACE NAME HOSTS ADDRESS PORTS AGE
isddc grafana-ingress xx.xx.cloud 10.xx.xx.xx,10.xx.xx.xx 80, 443 20d
kube-system fileserver-ingress xx.xx.cloud 10.xx.xx.xx,10.xx.xx.xx 80, 443 132d
21. Centos7 终端报Message from syslogd :kernel:unregister_netdevice
kernel:unregister_netdevice: waiting for eth0 to become free. Usage count = 3
https://www.jianshu.com/p/96d7e2cd9e99
好像是 kernel和k8s的bug 一直没有解决
解决办法
systemctl stop rsyslog
systemctl disable rsyslog
20. 修改机器yum源为阿里的源
1 备份源文件
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo_bak
2 获取源文件
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
3 刷新cache
yum makecache
19. Linux有如下的关机和重启命令:shutdown, reboot, halt, poweroff,那么它们有什么区别呢?
shutdown - 建议使用的命令
shutdown是最常用也是最安全的关机和重启命令,它会在关机之前调用fsck检查磁盘,其中-h和-r是最常用的参数:
-h:停止系统服务并关机
-r: 停止系统服务后重启
下面看几个例子:
shutdown -h now --立即关机
shutdown -h 10:53 --到10:53关机,如果该时间小于当前时间,则到隔天
shutdown -h +10 --10分钟后自动关机
shutdown -r now --立即重启
shutdown -r +30 'The System Will Reboot in 30 Mins' --30分钟后重启并并发送通知给其它在线用户
reboot
reboot表示立即重启,效果等同于shutdown -r now
poweroff
poweroff表示立即关机,效果等同于shutdown -h now,在多用户模式下(Run Level 3)不建议使用
18. Systemctl是一个systemd工具,主要负责控制systemd系统和服务管理器。
Systemd是一个系统管理守护进程、工具和库的集合,用于取代System V初始进程。Systemd的功能是用于集中管理和配置类UNIX系统。
在Linux生态系统中,Systemd被部署到了大多数的标准Linux发行版中,只有为数不多的几个发行版尚未部署。Systemd通常是所有其它守护进程的父进程,但并非总是如此。
列举已经启动的unit
systemctl list-units (或者直接 sudo systemctl)

command 主要有:
start:立刻启动后面接的 unit。
stop:立刻关闭后面接的 unit。
restart:立刻关闭后启动后面接的 unit,亦即执行 stop 再 start 的意思。
reload:不关闭 unit 的情况下,重新载入配置文件,让设置生效。
status:目前后面接的这个 unit 的状态,会列出有没有正在执行、开机时是否启动等信息。
is-active:目前有没有正在运行中。
kill :不要被 kill 这个名字吓着了,它其实是向运行 unit 的进程发送信号。
17. GB和GiB的区别
Gibibyte(giga binary byte的缩写)是信息或计算机硬盘存储的一个单位,简称GiB。由来“GiB”、“KiB”、“MiB”等是于1999年由国际电工协会(IEC)拟定了"KiB"、“MiB”、“GiB"的二进制单位,专用来标示“1024进位”的数据大小。具体的来说,1GiB=1024MiB,1MiB=1024KiB。他们与GB、MB、KB是不一样的,GB等则是1000进位的数据单位。
GB(gigabyte)是十进制的容量单位,1GB等于1,000,000,000 Bytes。而二进制的容量单位则是用GiB(Gibibyte)就是Giga Binary Byte,相等于1,073,741,824 Bytes。
所以一个160GB的硬盘其实只有149.0116119 GiB,厂商并没有欺骗顾客,更由于无法精确控制盘面的容量,大多数时候都会提供多余的空间以确保品质。
以下示范如何换算成GiB:
1GiB=(1024*1024*1024)B=1073741824B
1GB=(1000*1000*1000)B=1000000000B
1GiB/1GB=1073741824/1000000000=1.073741824
看到的磁盘为436468MB=426GB=426*1.074Gib=457GiB
例如:
8TiB=8192GiB=8192*1.073741824=8796.093022208GB
8796.093022208GB/1.073741824=8192GiB
16. 查看本机ip
ifconfig|grep inet
ip route
列出路由
linux的ip命令和ifconfig类似,但前者功能更强大,并旨在取代后者。使用ip命令,只需一个命令,你就能很轻松地执行一些网络管理任务
15. 网卡利用率 (百分比)
强大的性能监测工具dstat
安装
yum install --downloadonly dstat
yum install --downloadonly --downloaddir=./ dstat
在2台服务器直接发起网络请求
在发起 iperf3 -c 192.168.xx.xx -t 1800 的服务器查看网卡信息
[ 5] 25.00-26.00 sec 75.5 MBytes 633 Mbits/sec 0 576 KBytes
被测项目设置的网卡为1000mbps = 125MBytes
拓展:
1GB=1073741824字节
1KB=1024字节
1M=1024KB
1G=1024MB
数据的存储是以“字节”(Byte)为单位,数据传输大多是以“位”(bit,又名“比特”)为单位,一个位就代表一个0或1(即二进制),每8个位(bit,简写为b)组成一个字节(Byte,简写为B),是最小一级的信息单位。
B与iB
1KiB(Kibibyte)=1024byte
1KB(Kilobyte)=1000byte
1MiB(Mebibyte)=1048576byte
1MB(Megabyte)=1000000byte
首先是“Mbps”,其全称为Million bits per second,意为每秒传输百万位(比特)数量的数据,而这里的bit(比特,1比特等于1个位)是表示数字信号数据的最小单位
而Mb/s中的Mb与Mbps中的Mb意义相同,均表示百万位(比特)数据数量,所以Mbps=Mb/s
那么bit(比特)与Byte(字节)之间有什么关系吗?
1Byte(字节)=8bit(比特/位),在计算机中每8位为1字节,也就是1Byte=8bit,当在用Bytes/s和bits/s来表示网速时,于是就有1MB/s=8Mbps=8Mb/s

dstat命令查看recv为85-90

Transfer 为70-90,网卡利用率 (百分比)
已用 = 90/125*100=72
剩余 =(125-90)/125*100=28
一直动态变化则正确

14. IO 带宽
13. 每秒 IO 吞吐量
12. systemctl list-units --type=service
列出所有service类型的unit
systemctl list-units --type=service --all
systemctl 列出所有的系统服务
systemctl list-units 列出所有启动unit
systemctl list-unit-files 列出所有启动文件
systemctl list-units –type=service –all 列出所有service类型的unit
systemctl list-units –type=service –all grep cpu 列出 cpu电源管理机制的服务
systemctl list-units –type=target –all 列出所有target
systemctl list-dependencies #查看当前运行级别target(mult-user)启动了哪些服务

11. 查看网卡硬件信息
lspci|grep Ethernet

10. kdump 捕获崩溃
Kdump详解 参考博客Kdump详解_Eloim_Ct的博客-CSDN博客
Kdump是在系统崩溃、死锁或死机时用来转储内存运行参数的一个工具和服务,是一种新的crash dump捕获机制,用来捕获kernel crash(内核崩溃)的时候产生的crash dump。kdump需要配置两个不同目的的kernel,其中一个我们在这里称作standard(标准的)(production)kernel;另一个称之为Crash(崩溃的)(capture)kernel。打个比方,如果系统一旦崩溃,那么正常的内核就没有办法工作了,在这个时候将由kdump产生一个用于(capture)捕获当前运行信息的内核,该内核会将此时的内存中的所有运行状态和数据信息收集到一个dump core文件中以便于Ret Hat工程师分析崩溃的原因,一旦内存信息收集完成,系统将会自动重启这和以前的diskdump、netdump同理,只不过kdump是RHEL6特有的
standard(production)kernel,指的是我正在使用的kernel,当standard kernel在使用时出现crash时,kdump会切换到crash kernel,简单来说,standard kernel会正运行时发生crash,而crash(capture)kernel会被用来捕获production kernel在crash时产生的crash dump
捕获crash dump是在新的crash(capture)kernel的上下文中来捕获的,而不是在standard kernel上下文进行
具体是当standard kernel方式crash的时候,kdump通过kexec自动启动进入到crash kernel当中。如果启动了kdump服务,standard kernel会预留一部分内存,这部分内存用来启动crash kernel。
kdump机制主要包括两个组件:kdump和kexec
什么是kexec
kexec是一个快速启动kernel的机制,它运行在某一正在运行的kernel中,启动一个新的kernel(crash kernel),而且不用重新经过BIOS就可以完成启动。因为一般BIOS都会花费很长的时间,尤其是在大型并且同时连接许多外部设备的server上的环境下,BIOS会花费更多的时间
查看Linux系统是否开启打开kdump:
[root@localhost ~]# ulimit -c #如果输出为0,就是关闭,为unlimited则是打开,我的是关闭的
0
1
临时打开/关闭kdump:
[root@localhost ~]# ulimit -c unlimited #临时打开 比如之前测试推荐业务,后端是C++代码写的,尤其跑自动化/压测时会开启crash捕获,测试完在/tmp/dump查看是否有core
[root@localhost ~]# ulimit -c
unlimited #验证为开启了
[root@localhost ~]# ulimit -c 0 #临时关闭
[root@localhost ~]# ulimit -c
0 #验证为关闭了
9. 查看系统磁盘
linux中df命令的功能是用来检查linux服务器的文件系统的磁盘空间占用情况。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息
df -h 查看磁盘使用情况 实际创建虚拟机时的虚拟空间是40G对应磁盘显示38G多
-h 方便阅读方式显示
fdisk -l |grep Disk 查看磁盘分区情况
lsblk 查看硬盘和分区分布
fdisk -l 查看硬盘和分区的详细信息
Disk /dev/vda: 42.9 GB, 429496772960 bytes, 83886000 sectors // 扇区个数
Units = sectors of 1 * 512 = 512 bytes // 柱面单元大小 (一个扇区作为一个柱面)
Sector size (logical/physical): 512 bytes / 512 bytes // 扇区大小
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x000b97c2
Device Boot Start End Blocks Id System
/dev/vda1 * 2048 2099199 1048576 83 Linux
/dev/vda2 2099200 83886079 40893448 8e Linux LVM

8. 创建虚拟机,使用vnc或者remote viewer连接虚拟机,安装系统如centos7
mac无remote viewer 。需要下载vnc
Windows下载地址 Remote Utilities Viewer v7.0.0中文破解版下载(附破解补丁) - 艾薇下载站 或者安装virt-viewer-x86-8.0.msi

把系统生成的vv文件(协议 虚拟机ip port passwd等信息)拖到rv软件然后安装虚拟机
按步骤安装 设置用户名 密码 重启虚拟机 登录虚拟机 修改虚拟网络

修改虚拟网络
vi /etc/sysconfig/network-scripts/ifcfg-eth0

修改最后一行为yes
添加DNS=8.8.8.8

配置如下
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=eno1
UUID=d1969ca3-fae4-477d-xx-xx
DEVICE=eno1
ONBOOT=yes
IPADDR=xx.xx.xx.xx
PREFIX=23
GATEWAY=xx.xx.xx.xx
DNS1=xx.xx.xx.xx
保存后记得重启网络 systemctl restart network
再查看ip a |grep inet
inet地址变了,分配了ip

inet为ipv4 inet6为ipv6
如果想在虚拟机(192.168开头)上传东西(虚拟机不支持scp rz 等命令),比如测试CPU平均利用率的shell脚本,则需要给虚拟机绑定浮动ip(创建浮动ip地址,绑定虚拟机。解释:浮动ip地址相当于外网ip 10.121开头,可以从edge-node(172.16开头) scp到浮动ip的机器)
7. 内存利用率
计算方法
used+buff(cache) / total
目前来看集群的内存利用率是在19~22%
free -m|sed -n '2p'|awk '{printf("%.2f%%\n",($3+$6)/$2*100)}'
37.56%

2022年1月28测试
差值在于针对内存的buffer、cache的计算,当前监控系统的内存利用率的计算是将buffer和cache的值算在了可用内存范围,而测试所用脚本是将buffer和cache算了已用内存范围,实际上当一个程序需要申请较大的内存时,如果free的内存不够,内核会把部分cached的内存回收,回收的内存再分配给应用程序。所以对于linux系统,可用于分配的内存不只是free的内存,还包括cached和buffers的内存
内存利用率计算方法
- record: oi_node_memory_utilization
expr: 100 * (1 - ((node_memory_MemFree_bytes{host_uuid!=""} + node_memory_Cached_bytes{host_uuid!=""} + node_memory_Buffers_bytes{host_uuid!=""}) / node_memory_MemTotal_bytes{host_uuid!=""}))
内存利用率脚本
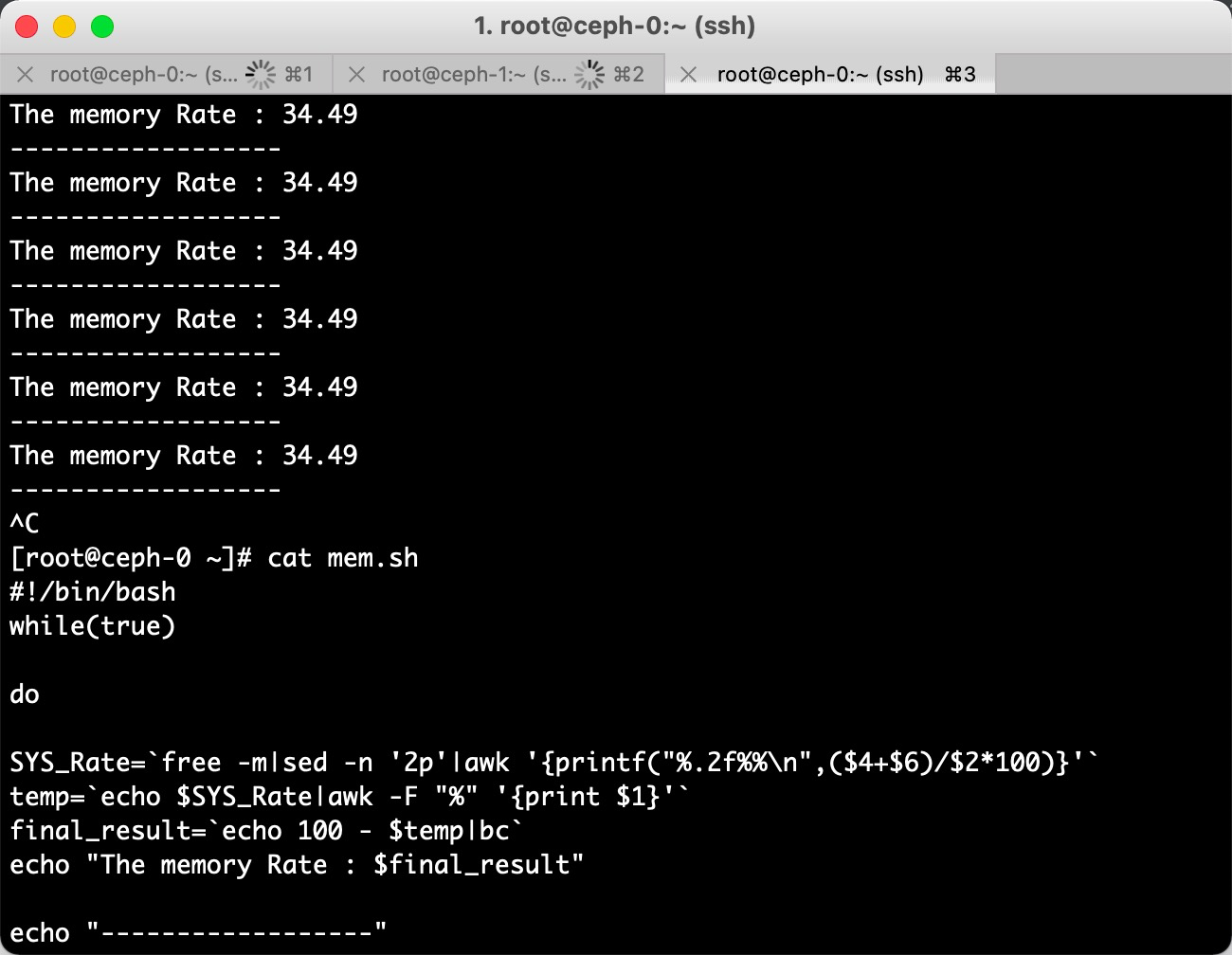
#!/bin/bash
while(true)
do
SYS_Rate=`free -m|sed -n '2p'|awk '{printf("%.2f%%\n",($4+$6)/$2*100)}'`
temp=`echo $SYS_Rate|awk -F "%" '{print $1}'`
final_result=`echo 100 - $temp|bc`
echo "The memory Rate : $final_result"
echo "------------------"
done
[root@edge-node2 ~]# free -lh
total used free shared buff/cache available
Mem: 755G 106G 561G 4.1G 87G 640G
Low: 755G 194G 561G
High: 0B 0B 0B
Swap: 4.0G 0B 4.0G
6. CPU利用率
在Linux下,CPU利用率分为用户态,系统态和空闲态,分别表示CPU处于用户态执行的时间,系统内核执行的时间,和空闲系统进程执行的时间,三者之和就是CPU的总时间,当没有用户进程、系统进程等需要执行的时候,CPU就执行系统缺省的空闲进程。从平常的思维方式理解的话,CPU的利用率就是非空闲进程占用时间的比例,即CPU执行非空闲进程的时间/ CPU总的执行时间
CPU的使用率是使用CPU的处理能力基准计算实时CPU占用率
CPU时间=user+system+nice+idle+iowait+irq+softirq
除idle外,cpu均被有效利用,取两个采样点,于是有:
cpuusage=[(user_2+sys_2+nice_2+iowait_2+irq_2+softirq_2)-(user_1+sys_1+nice_1+iowait_1+irq_1+softirq_2)]/(total_2-total_1)*100%
或者:
cpu usage=(idle2-idle1)/(total_2-total_1)*100%

%Cpu(s): 0.3 us, 0.2 sy, 0.0 ni, 98.0 id, 1.5 wa, 0.0 hi, 0.0 si, 0.0 st
第三行:cpu状态
6.7% us — 用户空间占用CPU的百分比
0.4% sy — 内核空间占用CPU的百分比
0.0% ni — 改变过优先级的进程占用CPU的百分比
92.9% id — 空闲CPU百分比
0.0% wa — IO等待占用CPU的百分比
0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.0% si — 软中断(Software Interrupts)占用CPU的百分比
第一行的数值表示的是CPU总的使用情况,所以我们只要用第一行的数字计算就可以了。下表解析第一行各数值的含义:
| 参数 |
解析(单位:jiffies) |
| user (2032004) |
从系统启动开始累计到当前时刻,用户态的CPU时间,不包含 nice值为负进程。 |
| nice (102648) |
从系统启动开始累计到当前时刻,nice值为负的进程所占用的CPU时间 |
| system (238344) |
从系统启动开始累计到当前时刻,核心时间 |
| idle (167130733) |
从系统启动开始累计到当前时刻,除IO等待时间以外其它等待时间 |
| iowait (758440) |
从系统启动开始累计到当前时刻,IO等待时间 |
| irq (15159) |
从系统启动开始累计到当前时刻,硬中断时间 |
| softirq (17878) |
从系统启动开始累计到当前时刻,软中断时间 |
计算cpu利用率的shell脚本
[root@edge-node1 tmp]# cat /proc/stat 查看CPU
cpu 125094388 160 19646788 3863197092 1316929 22008021 20012906 0 105025966 0
cpu0 2300773 0 316963 59961223 28218 350919 322074 0 1989117 0
cpu1 1885273 2 1076616 59629637 19424 345949 333747 0 261688 0
cpu2 1777766 2 382328 60422289 24439 351985 339369 0 1086476 0
cpu3 1591870 11 367656 60620419 20955 352620 342047 0 1049030 0
cpu4 1573398 0 352758 60652301 21908 352368 340665 0 1072780 0
各个参数的具体解释:
第一排是cpu总计,下面是2个4核cpu的参数,故有8行数据。
user (494881706) 从系统启动开始累计到当前时刻,用户态的CPU时间(单位:jiffies) ,不包含 nice值为负进程。1jiffies=0.01秒
nice (19) 从系统启动开始累计到当前时刻,nice值为负的进程所占用的CPU时间(单位:jiffies)
system (67370877) 从系统启动开始累计到当前时刻,核心时间(单位:jiffies)
idle (876689477) 从系统启动开始累计到当前时刻,除硬盘IO等待时间以外其它等待时间(单位:jiffies)
iowait (17202366) 从系统启动开始累计到当前时刻,硬盘IO等待时间(单位:jiffies) ,
irq (200116) 从系统启动开始累计到当前时刻,硬中断时间(单位:jiffies)
softirq (0) 从系统启动开始累计到当前时刻,软中断时间(单位:jiffies)
CPU利用率技术脚本:本脚本持续显示cpu的利用率
知道了/proc文件的内容之后就可以计算cpu的利用率了,具体方法是:先在t1时刻读取文件内容,获得此时cpu的运行情况,然后等待一段时间在t2时刻再次读取文件内容,获取cpu的运行情况,然后根据两个时刻的数据通过以下方式计算cpu的利用率:100 – (idle2 – idle1)*100/(total2 – total1) 其中total = user + system + nice + idle + iowait + irq + softirq
#!/bin/bash
while(true)
do
# $1 $2 $3 $4 $5 $6 $7
CPU_1=$(cat /proc/stat | grep 'cpu ' | awk '{print $2" "$3" "$4" "$5" "$6" "$7" "$8}') #打印第一行cpu每列,user nice system4 idle iowait irq softirq
SYS_IDLE_1=$(echo $CPU_1 | awk '{print $4}') #打印第4列idle,从系统启动开始累计到当前时刻,除硬盘IO等待时间以外其它等待时间
Total_1=$(echo $CPU_1 | awk '{printf "%.f",$1+$2+$3+$4+$5+$6+$7}') #打印cpu全部列之和
sleep 2 #等待2秒
CPU_2=$(cat /proc/stat | grep 'cpu ' | awk '{print $2" "$3" "$4" "$5" "$6" "$7" "$8}') #再次取最新的列
SYS_IDLE_2=$(echo $CPU_2 | awk '{print $4}') #再次打印第4列idle,从系统启动开始累计到当前时刻,除硬盘IO等待时间以外其它等待时间
Total_2=$(echo $CPU_2 | awk '{printf "%.f",$1+$2+$3+$4+$5+$6+$7}') #第二次打印cpu全部列之和
SYS_IDLE=`expr $SYS_IDLE_2 - $SYS_IDLE_1` #expr命令是一个手工命令行计数器,用于求表达式变量的值,一般用于整数值,也可用于字符串 > expr length “this is a test” 为14(算上空格了)
Total=`expr $Total_2 - $Total_1` #2次cpu总和的差值
TT=`expr $SYS_IDLE \* 100` # (idle2 – idle1)*100
SYS_USAGE=`expr $TT / $Total` # (idle2 – idle1)*100/(total2 – total1)
SYS_Rate=`expr 100 - $SYS_USAGE` #cpu利用率为100 – (idle2 – idle1)*100/(total2 – total1)
echo "The CPU Rate : $SYS_Rate%"
echo "------------------"
done
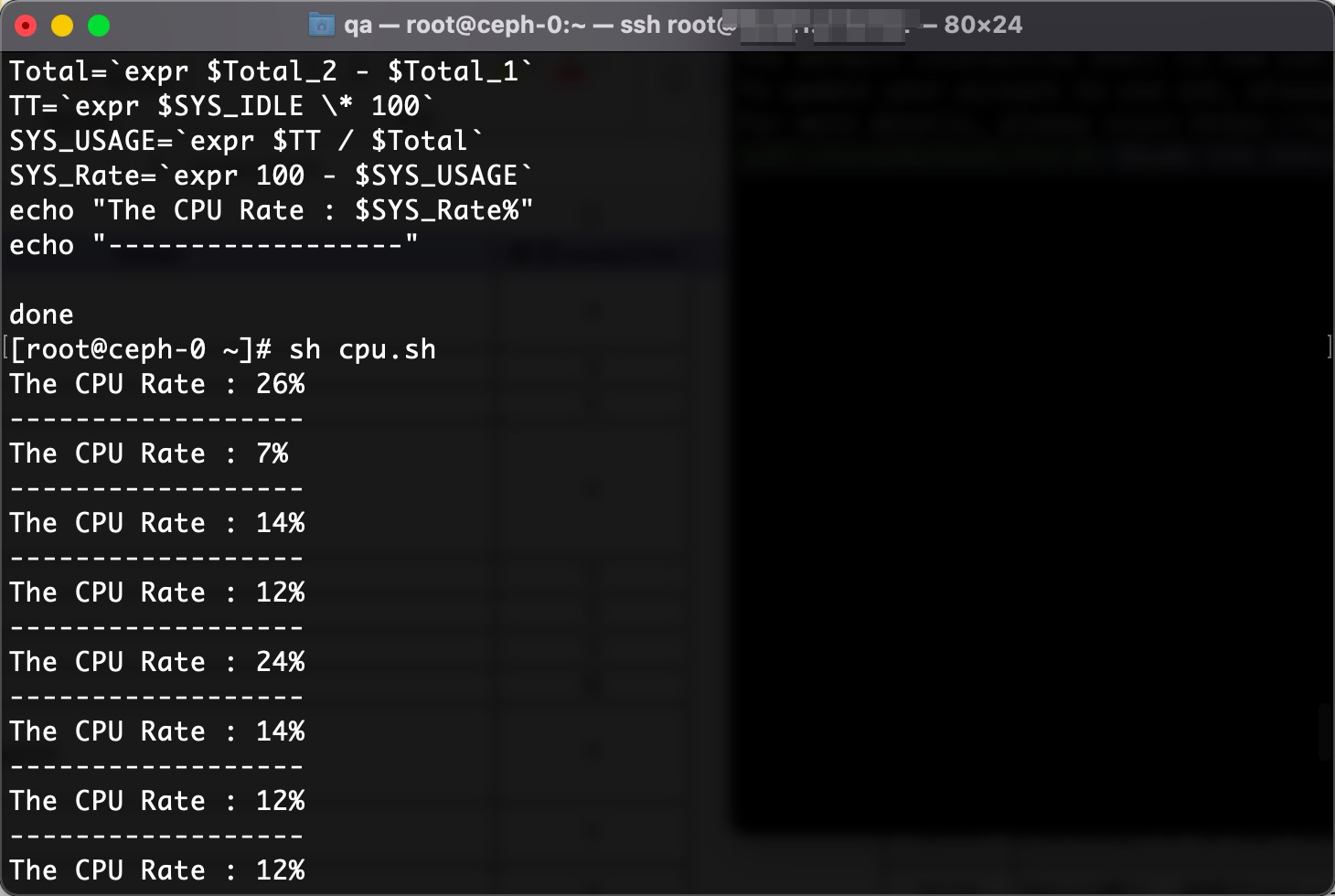
2022年1月28测试
测试脚本与当前CPU利用率指标采集的计算方式不同,监控系统的CPU利用率的计算方式是将总的CPU减去idle的,从当前系统的运行数据与监控图进行对比来看,基本上是吻合的
无注释版:把以下脚本放到cpu.sh文件,在sh cpu.sh
#!/bin/bash
while(true)
do
CPU_1=$(cat /proc/stat | grep 'cpu ' | awk '{print $2" "$3" "$4" "$5" "$6" "$7" "$8}')
SYS_IDLE_1=$(echo $CPU_1 | awk '{print $4}')
Total_1=$(echo $CPU_1 | awk '{printf "%.f",$1+$2+$3+$4+$5+$6+$7}')
CPU_2=$(cat /proc/stat | grep 'cpu ' | awk '{print $2" "$3" "$4" "$5" "$6" "$7" "$8}')
SYS_IDLE_2=$(echo $CPU_2 | awk '{print $4}')
Total_2=$(echo $CPU_2 | awk '{printf "%.f",$1+$2+$3+$4+$5+$6+$7}')
SYS_IDLE=`expr $SYS_IDLE_2 - $SYS_IDLE_1`
Total=`expr $Total_2 - $Total_1`
TT=`expr $SYS_IDLE \* 100`
SYS_USAGE=`expr $TT / $Total`
SYS_Rate=`expr 100 - $SYS_USAGE`
echo "The CPU Rate : $SYS_Rate%"
echo "------------------"
done

5. inux下dmidecode命令获取硬件信息
dmidecode在 Linux 系统下获取有关硬件方面的信息。dmidecode 遵循 SMBIOS/DMI 标准,以一种可读的方式dump出机器的DMI(Desktop Management Interface)信息, 其输出的信息包括 BIOS、系统、主板、处理器、内存、缓存等等, 既可以得到当前的配置,也可以得到系统支持的最大配置,比如说支持的最大内存数等。
aptitude install dmidecode # Debian/Ubuntu
yum install dmidecode # Fedora
pacman -S dmidecode # Arch Linux
emerge -av dmidecode # Gentoo
1、查看内存槽数、那个槽位插了内存,大小是多少
dmidecode|grep -P -A5 "Memory\s+Device"|grep Size|grep -v Range
2、查看最大支持内存数
dmidecode|grep -P 'Maximum\s+Capacity'
3、查看槽位上内存的速率,没插就是unknown。
dmidecode|grep -A16 "Memory Device"|grep 'Speed'
dmidecode的输出格式一般如下:
Handle 0×0002
DMI type 2, 8 bytes
Base Board Information
Manufacturer:Intel
Product Name: C440GX+
Version: 727281-0001
Serial Number: INCY92700942
其中的前三行都称为记录头(recoce Header), 其中包括了:
1、recode id(handle): DMI表中的记录标识符,这是唯一的,比如上例中的Handle 0×0002。
2、dmi type id: 记录的类型,譬如说:BIOS,Memory,上例是type 2,即”Base Board Information”
3、recode size: DMI表中对应记录的大小,上例为8 bytes.(不包括文本信息,所有实际输出的内容比这个size要更大。)
记录头之后就是记录的值:
4、decoded values: 记录值可以是多行的,比如上例显示了主板的制造商(manufacturer)、model、version以及serial Number。
dmidecode的使用方法
1. 最简单的的显示全部dmi信息:dmidecode
这样将输出所有的dmi信息,你可能会被一大堆的信息吓坏,通常可以使用下面的方法。
2.更精简的信息显示: dmidecode -q
-q(–quite) 只显示必要的信息,这个很管用哦。
3.显示指定类型的信息:
通常我只想查看某类型,比如CPU,内存或者磁盘的信息而不是全部的。这可以使用-t(–type TYPE)来指定信息类型:
4. 服务器操作系统信息
hostnamectl
[root@edge-xx ~]# hostnamectl
Static hostname: edge-node2
Pretty hostname: [edge-node2]
Icon name: computer-server
Chassis: server
Machine ID: 499aa536dxxe5e
Boot ID: fe03xxxxe1
Operating System: MEC Node 4.2.0
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 4.19.104
Architecture: x86-64
uname -a
[root@edge-xx ~]# uname -a
Linux edge-xx 4.19.104 #1 SMP Mon Feb 24 19:19:24 CST 2020 x86_64 x86_64 x86_64 GNU/Linux

3. 查看服务器内存使用情况
free指令会显示内存的使用情况,包括实体内存,虚拟的交换文件内存,共享内存区段,以及系统核心使用的缓冲区等
B = bytes
K = kilos
M = megas
G = gigas
T = teras
物理内存
free
free -lh 按照适合显示的单位去显示 最完美的命令
free 单位:kb
free -m 单位:M
free -g 单位:G

发现在创建虚拟机的时候 分配的内存是4048M 也就是3.953个G 但是实际free显示的total内存是3.7G
free命令显示的内容,第一行的数据是以系统视角看的,第二行的数据是以应用程序的视角看的。
第一行的used一项,其数据不单包含程序使用的内存,还包含buffers跟cached的内存,因此看上去可用的内存很少。
第二行的数据,分别是used-buffers-cached,跟free+buffers+cached,算了一下程序总的内存使用率是(total - free - buffers - cached) / total = 0.038 左右,因此top显示一列0.0也没什么问题。

2. 云计算测试项
hugepage是在linux2.6内核被引入的,主要提供4k的page和比较大的page的选择
cat /proc/meminfo 查看Hugepagesize大小 数量

[root@edge-node2 jumpserver]# cat /proc/meminfo |grep Hugepagesize
Hugepagesize: 1048576 kB
测试点(centos7)
1 逻辑CPU内核:64
2 Huge Pages(size:amount):[HugePage:{sizeKB='1048576', amount='18'}]
3 设备透传:true
4 物理内存:755.64GB
5 Kdump状态:disabled
6 生产商:xx
产品系列:ThinkSystem
版本:07
产品名称:ThinkSystem SR650 -[7X06CTO1WW]-
UUID:66DEA72E-xx-11EA-xx-xx
序列号: J301N7C4
CPU类型:Intel Westmere Family
7 CPU型号:Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz
8 存储利用率:1.48%
测试命令行
1 less /proc/cpuinfo |grep 'processor'|wc -l
2 less /proc/meminfo|grep Hugepagesize
3 less /proc/meminfo|grep HugePages_Free
4 free -lh
5 [root@edge-node2 ~]# ulimit -c #如果输出为0,就是关闭,为unlimited则是打开,我的是关闭的
0
[root@edge-node2 ~]# ulimit -c unlimited #临时打开
[root@edge-node2 ~]# ulimit -c
unlimited
[root@edge-node2 ~]# ulimit -c 0 #临时关闭
[root@edge-node2 ~]# ulimit -c
0

6 dmidecode |grep -A16 "System Information$" 查看服务器硬件信息、主板信息

dmidecode -s system-uuid 查看服务器uuid
dmidecode -s system-uuid |tr 'a-z' 'A-Z' 小写转换为大写

7 查看CPU型号
cat /proc/cpuinfo | grep "model name" | cut -d ':' -f 2 |sort -u

8 ceph df 查看集群容量状态

在Linux中,内存都是以页的形式划分的,默认情况下每页是4K,这就意味着如果物理内存很大,则映射表的条目将会非常多,会影响CPU的检索效率。因为内存大小是固定的,为了减少映射表的条目,可采取的办法只有增加页的尺寸
vim /etc/security/limits.conf

1. 物理内存 逻辑内存
服务器 8C16G为8核16G
查看CPU核数 more /proc/cpuinfo |grep "physical id"|grep "0"|wc -l
或者查看核数 more /proc/stat 第一排是cpu总计,下面是2个32核cpu的参数,故有64行数据

查看内存 free -g

参考博客linux查询服务器cpu核数_linux 下查看机器是cpu是几核的_weixin_39628256的博客-CSDN博客
# cat /proc/cpuinfo 查看物理cpu
有多少physical id 就有多少个cpu,我们的服务器是8个
有多少个core id就有多少核 --8个物理内核
总核数(指的是总的CPU物理内核数) = 物理CPU个数 X 每个物理CPU的核数 = 4 * 16 = 64
总逻辑CPU数(processor) = 物理CPU个数(physical) X 每个物理CPU的核数(cpu cores的值) X 超线程数( 2-如果支持并开启ht)
= 4 *16 * 2=132
=cat /proc/cpuinfo |grep "processor"|wc -l
= cat /proc/cpuinfo |grep "physical id"|uniq|wc -l * cat /proc/cpuinfo | grep "cores" | uniq * 2

是否开启intel的超线程技术(HT)
如果有两个逻辑CPU具有相同的"core id",那么超线程是打开的。可以根据以下原则,来判断是否支持HT技术
如果"siblings"和"cpu cores"一致,则说明不支持超线程,或者超线程未打开
如果"siblings"是"cpu cores"的两倍,则说明支持超线程,并且超线程已打开
cat /proc/cpuinfo |grep "sibling"|uniq
执行结果:siblings : 32
cat /proc/cpuinfo | grep "cpu cores"|uniq
执行结果:cpu cores : 16

cat /proc/cpuinfo |grep "physical id"|grep "0"|wc -l 查看物理CPU个数
32
cat /proc/cpuinfo| grep "cpu cores"| uniq 查看每个物理CPU中core的个数(即核数)
cpu cores : 16
grep "physical id" /proc/cpuinfo|sort -u|wc -l
2
cat /proc/cpuinfo| grep "processor"| wc -l 查看逻辑CPU个数 逻辑CPU内核
64
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c 查看CPU型号
64 Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz
cat /proc/cpuinfo| grep "cpu cores"| uniq 查看每个物理CPU中core的个数(即核数)
cpu cores : 16
cat /proc/cpuinfo |grep MHz|uniq 查看CPU的主频
cpu MHz : 999.995
cpu MHz : 2276.509
cpu MHz : 1000.007
cpu MHz : 1000.004

查看Linux上存在的处理器数量的最简单和最短的方法,因为它是coreutils 的一部分而被广泛扩展
lscpu | grep 'CPU(s)'
查看cpu参数的命令
lscpu


[root@edge-node1 ~]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 64 逻辑CPU个数
On-line CPU(s) list: 0-63
Thread(s) per core: 2 每核超线程数
Core(s) per socket: 16 每核CPU数
Socket(s): 2 物理CPU个数
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz
Stepping: 7
CPU MHz: 1000.003
BogoMIPS: 4600.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 22528K
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi
待续。。。