Few-shot 3D Point Cloud Semantic Segmentation
公众号:EDPJ
目录
0. 摘要
0.1 关键词和名词解释
1. 简介
2. 相关工作
3. 方法论
3.1 问题定义
3.2 基于attention的多原型转导推断
3.2.1 Embedding Network
3.2.2 多原型生成(Multi-prototype Generation)
3.2.3 转导推断(Transductive Inference)
3.2.4 Loss Function
4. Experiment
4.1 Dataset and Setup
4.2 实现细节
4.3 Baselines
4.4 结果和分析
4.5 量化结果
5. 参考
0. 摘要
为了缓和难以获取的labelled data的限制以及提升泛化性能,本文提出基于attention的多原型直推式few-shot点云语义分割(attention-aware multi-prototype transductive few-shot point cloud semantic segmentation)。特别地,每一个类别由多个原型(multi-prototype)表示,从而建模labeled points的复杂分布。然后使用label propagation来探索labeled多原型与unlabeled点的关系,以及unlabeled点之间的关系。然后,设计了一个基于attention的多层特征学习网络,用于学习鉴别特征。这些特征包含了点之间的几何依赖性以及语义相关性。

0.1 关键词和名词解释
- embedding network:学习suppory和query点云的鉴别特征
- 多原型生成(multi-prototype):为所有的N+1个类别(N个语义类别和一个背景类别)生成多个原型。原型相当于聚类的中心点。
- k-NN图构建:在embedding space内编码集合间(suppory-query)和集合内(support-support、query-query)的关系。基于原型与点云距离构建的关系图。
- 标签传播(label propagation):沿着由unlabeled query points生成的高密度区域把标签扩散到整个图
- cross-entropy loss function:计算预测标签与所有query points真实标签之间的loss
1. 简介
点云语义分割(Point cloud semantic segmentation)是计算机视觉的基础问题,目的是估计一个场景的3D点云表示中每一个点所属的物体类别。然而由于点云的无结构、无序的特性,点云语义分割是一个挑战。目前的3D语义分割技术的良好性能依赖于大量的labeled data,而这些data的收集是费时且困难的。此外,这些方法遵从闭集(close set)假设:训练数据和测试数据是从同一个label space中获取的。然而这个假设并不符合实际:训练时未看过的新类别很多。因此,监督方法获得的model在仅有少量样本的新类别上泛化性能并不好。
虽然一些研究(self-supervised、weakly-supervised、semi-supervised)想要缓解labeled data的限制,但他们依然遵从闭集假设,从而泛化能力并不好。而Few-shot learning,只用少量的样本,就能让model完成新类别的task。本文采用常用的meta-learning策略episodic training:在相似few-shot task的分布上学习,而不是只在一个segmentation task上学习。每一个few-shot task由一些label samples(support set)和一些unlabeled samples(query set)组成,model用从support学来的知识对query进行分割。由于训练few-shot task和测试task的一致性,model有良好的泛化能力且不容易对数量稀少的suppory samples过拟合。
本文的方法是对support set的点云中的点的复杂分布进行建模,基于在few-shot限制下提取的鉴别特征,通过转导推断(transductive inference)进行分割。本文还使用了原型网络(prototypical network):用一个原型表示一个类别,该原型是support中的该类别所有labelled samples的embeddings的平均。这种单模态(uni-modal)的方法并不好,因为真实的数据分布往往是很复杂的。此外,在一个语义类别内,点的空间结构也是很复杂的。因此,本文建议每个类别使用多个原型,从而更好地建模复杂分布。本文使用attention来获取点之间的空间依赖性和语义相关性。然后以一种直推的(transductive)方式,用学到的特征空间中的多个原型进行分割。传统的原型网络通过计算欧式距离来匹配unlabeled实例与类别原型,本文使用transductive inference:不止考虑unlabeled query points和多原型之间的关系,还探索unlabeled query points的关系。
2. 相关工作
3D语义分割。大多数基于深度学习的研究使用的是有监督的方式。
PointNet第一个设计端到端神经网络对未经处理的点云进行分割,而不是对它们的变形表示(例如:voxel grids、多视角图像)进行分割。虽然简单有效,但是PointNet忽视了临近点的重要的局部信息。
- 点云是三维空间(xyz坐标)点的集合。
- 体素是3D空间的像素。量化的,大小固定的点云。每个单元都是固定大小和离散坐标。
- mesh是面片的集合。
- 多视图表示是从不同模拟视点渲染的2D图像集合。
DGCNN设计了可以捕捉局部结构的EdgeConv模块。本文使用DGCNN为骨干网络,作为特征提取器提取局部几何特征和语义特征。
Few-shot learning。基于度量的方法可以直接推断未看过类别样本的标签。核心思想是学一个好的度量函数,基于unlabeled data和labeled data的相似性进行分类。Matching Network和Prototypical Network是两个代表性的基于度量的方法,它们使用深度网络把support set和query set映射成embedding space。Matching Network用所有的suppory samples表示一个类别,Prototypical Network使用suppory samples的均值表示一个类别。这是两种极端。
Few-shot图像分割。现存的大多数方法用基于度量的方法处理support和query之间一到多的匹配问题,support中的每一个类别被表示为一个全局向量。
与此相反,Zhang把这个task考虑成多对多匹配的问题:support被表示成一个图,图中的每一个元素是一个节点。然而,该方法基于CNN结构,并不适用于点云。因为点云的结构是无规律的。此外,点云和图像的embedding space的性质是不一样的。
3. 方法论
3.1 问题定义
每一个few-shot task(一个episode)是一个N-way K-shot点云分语义分割任务。在每一个episode,给定suppory set,表示为 ,共有N个类别,每个类别中有K个有标签的support点云
,共有N个类别,每个类别中有K个有标签的support点云 及其相应的二进制掩模(Mask)
及其相应的二进制掩模(Mask) 。每一个点云
。每一个点云 包含M个点:坐标信息
包含M个点:坐标信息 ,附加特征
,附加特征 (例如:颜色)。还有一个query set,表示为
(例如:颜色)。还有一个query set,表示为 ,包含T个query点云
,包含T个query点云 及其相应标签
及其相应标签 。
。
N-way K-shot点云语义分割的目标:对于任意的基于S的点云 ,学习一个模型
,学习一个模型 ,预测标签分布
,预测标签分布 。
。

其中, 是 的最优参数。
是 的最优参数。 表示训练集,包含所有从训练类别集合
表示训练集,包含所有从训练类别集合 中采样的episodes。
中采样的episodes。 表示loss function(将在3.2.4定义)。
表示loss function(将在3.2.4定义)。
3.2 基于attention的多原型转导推断

上图是本文的基于attention的多原型转导推断。它包含五个元素:
- embedding network:学习suppory和query点云的鉴别特征
- 多原型生成:为所有的N+1个类别(N个语义类别和一个背景类别)生成多个原型
- k-NN图构建:在embedding space内编码集合间(suppory-query)和集合内(support-support、query-query)的关系
- 标签传播:沿着由unlabeled query points生成的高密度区域把标签扩散到整个图
- cross-entropy loss function:计算预测标签与所有query points真实标签之间的loss
3.2.1 Embedding Network
本网络是本模型最重要的一部分,因为多原型生成和k-NN图的构建都依赖于学到的embedding space。该空间应有如下特性:
- 基于局部语境编码点的几何结构
- 基于全局语境编码点的语义信息及其语义相关性
- 可以快速地自适应到不同的few-shot task
作者设计了一个基于attention的多级特征学习网络来学习三级特征:局部几何特征、全局语义特征、度量自适应特征。特别地,embedding network包含三个模块:特征提取器、attention学习器、度量学习器。
本文使用dynamic graph CNN结构的DGCNN作为特征提取器的骨干,用于生成局部几何特征(第一个EdgeConv层的输出)和语义特征(特征提取器的输出)。
为进一步探索全局语境中点的语义相关性,作者对生成的语义特征使用了self-attention network(SAN)。SAN以一种灵活、自适应的方式把点的特征聚合为相应点云的全局语境信息。下图是SAN的结构。
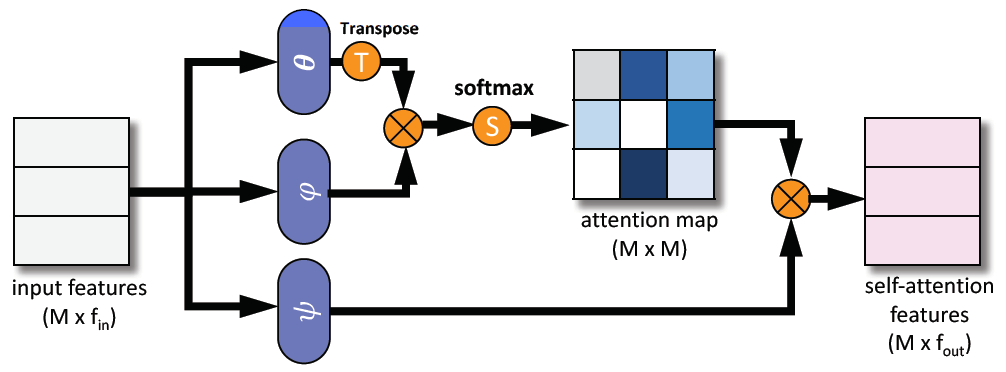
作者还引入了度量学习器:许多的多层感知器层,可以使embedding space可以更快地向不同的few-shot task自适应。度量学习器把所有support和query set点的特征映射为一个流形空间(mainfold space),在其中,一般的距离函数(例如:欧氏距离或者余弦距离)都可以直接使用用于度量点的相似性。
最终,串联三层学到的特征作为embedding network的输出。
3.2.2 多原型生成(Multi-prototype Generation)
对于support set中的N+1个类别中的每一个,根据episode中少量labeled samples生成n个原型建模复杂的数据分布。作者把生成过程看作是聚类问题。虽然有很多方法可以把support points聚合为多原型,本文选择最简单的策略:基于学到的embedding space,采样seed points以及point-to-seed的分配。特别地,基于embedding sapce,使用最远点采样法从一个类别的support points中采样n个点作为seed point。直观地,如果embedding space学得好,那么这个space中的最远点可以表示该类别的不同方面。令 分别表示采样的seeds以及属于类别c的所有
分别表示采样的seeds以及属于类别c的所有 个support points。作者计算了point-to-seed的距离,然后把距离每个点最近的seed的索引分配给该点。类别c的多原型表示为:
个support points。作者计算了point-to-seed的距离,然后把距离每个点最近的seed的索引分配给该点。类别c的多原型表示为:

其中, 被分成n个集合
被分成n个集合 。点
。点 被分配给seed
被分配给seed 。
。
3.2.3 转导推断(Transductive Inference)
作者使用转导标签传播(transductive label propagation)构建了一个graph,然后在graph中随机路径的传播label。
k-NN图构建。为了计算有效性,作者使用k近邻(Nearest Neighbor,NN)图而不是全连接图。特别地, 个多原型和
个多原型和 个query points作为图的节点,图的大小为
个query points作为图的节点,图的大小为 。通过计算embedding space中每一个节点及与其最接近的k个相邻节点的高斯相似性,作者构建了一个稀疏的关系矩阵
。通过计算embedding space中每一个节点及与其最接近的k个相邻节点的高斯相似性,作者构建了一个稀疏的关系矩阵 。
。

其中, 表示节点特征,
表示节点特征, 表示两个节点距离的方差。令
表示两个节点距离的方差。令 ,这保证矩阵是非负对称的。标准化W获得
,这保证矩阵是非负对称的。标准化W获得 ,其中D是对角度矩阵(diagonal degree matrix),其对角线的值是W相应行的值之和。 此外,定义标签矩阵
,其中D是对角度矩阵(diagonal degree matrix),其对角线的值是W相应行的值之和。 此外,定义标签矩阵 ,其中,与labeled原型对应的行是one-hot的真是标签,剩余的是0。
,其中,与labeled原型对应的行是one-hot的真是标签,剩余的是0。
标签传播。给定S和Y,基于如下公式,标签传播在图中迭代地扩散标签。

其中, 表示迭代t中预测的标签分布。
表示迭代t中预测的标签分布。 是一个参数,控制从相邻节点和原始标签传递的信息的量。该序列收敛于一个闭合形式的结果:
是一个参数,控制从相邻节点和原始标签传递的信息的量。该序列收敛于一个闭合形式的结果:

3.2.4 Loss Function
一旦 确定,首先获得对应于T个query点云的预测,表示为
确定,首先获得对应于T个query点云的预测,表示为 。然后用softmax归一化:
。然后用softmax归一化:

最后,计算 与真实标签
与真实标签 之间的cross-entropy loss:
之间的cross-entropy loss:

其中,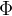 是模型的参数。更确切的说,
是模型的参数。更确切的说, 是embedding network
是embedding network 与多原型生成和转导推断操作
与多原型生成和转导推断操作 的复合函数。
的复合函数。
4. Experiment
4.1 Dataset and Setup
Dataset。在两个数据集上进行评估:S3DIS、ScanNet。
Setup。基于类别名首字母,把每一个数据集均分成两个子集。对两个子集使用交叉验证的方法:其中一个作为training set,另一个作为validation set。因为原始房间点的数目十分巨大,所以在xy平面,用一个 1m*1m 的滑动窗把房间分割成不重叠的小块,每一个小块中随机采样M=2048个点。
4.2 实现细节
4.3 Baselines
本文设置了四个baseline作为对比。
Fine-tune(FT)。把预训练的分割网络作为baseline的骨干。从support set中采样进行fine-tune,然后再query set上测试。为避免过拟合,只fine-tune最后三个MLP层。
原型网络(ProtoNet)。整体与本文使用的embedding network相同,区别在于SAN被替换成一个线性映射,且每个类别只有一个原型。
添加attention的原型网络(AttProtoNet)。与本文使用的embedding network相同。
多原型转导推断(MPTI)。整体与本文使用的network相同,区别在于SAN被替换成一个线性映射。
4.4 结果和分析

使用的度量方法:mean Interaction over Union (mean-IoU)。
与Baselines的对比。本文研究有更好的性能。
多层特征的消融实验。

上图表示不同特征对性能的贡献程度。显然,相比于局部几何特征,全局语义特征和度量自适应特征对性能的影响更大。
超参数的影响。
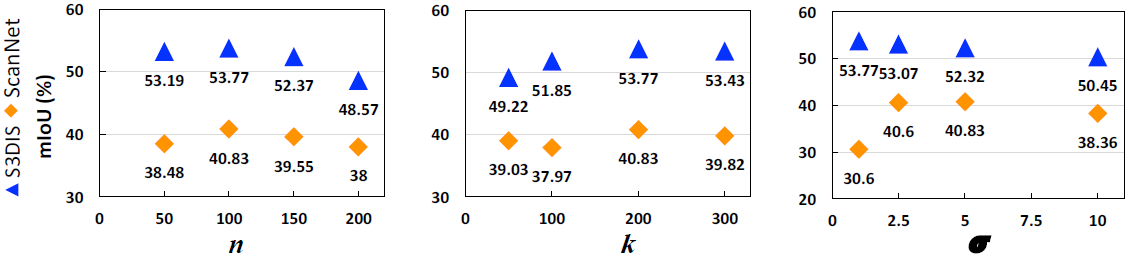
如上图所示,增加每个类别中原型的数量 n 可以提升性能,但是过多的原型却会因为overfitting影响性能。
k用于kNN图的构建,最合适的 k 应取值200。
第三个参数在高斯相似性中,用于构建关系矩阵。对于不同的数据集有不同的最优值。
4.5 量化结果

上图是在数据集S3DIS上,在2-way 1-shot点云语义分割task上,本文方法与真实标签和ProtoNet上结果的对比。图例在最上方,不同的颜色对应不同的物体。

上图是在数据集ScanNet上,在2-way 1-shot点云语义分割task上,本文方法与真实标签和ProtoNet上结果的对比。图例在最上方,不同的颜色对应不同的物体。
5. 参考
Zhao, N., Chua, T. S., & Lee, G. H. (2021). Few-shot 3d point cloud semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 8873-8882).