提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
卷积神经网络是一种多层的监督学习神经网络,隐含层的卷积层和池采样层是实现卷积神经网络特征提取功能的核心模块。该网络模型通过采用梯度下降法最小化损失函数对网络中的权重参数逐层反向调节,通过频繁的迭代训练提高网络的精度。
提示:以下是本篇文章正文内容,下面案例可供参考
一、任务要求
数字识别是计算机从纸质文档、照片或其他来源接收、理解并识别可读的数字的能力,目前比较受关注的是手写数字识别。手写数字识别是一个典型的图像分类问题,已经被广泛应用于汇款单号识别、手写邮政编码识别,大大缩短了业务处理时间,提升了工作效率和质量。
在处理如 图1 所示的手写邮政编码的简单图像分类任务时,可以使用基于MNIST数据集的手写数字识别模型。MNIST是深度学习领域标准、易用的成熟数据集,包含60000条训练样本和10000条测试样本。

- 任务输入:一系列手写数字图片,其中每张图片都是28x28的像素矩阵。
- 任务输出:经过了大小归一化和居中处理,输出对应的0~9数字标签。
二、模型搭建
1.卷积层

torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
参数:
- in_channels:输入通道
- out_channels:输出通道
- kernel_size:卷积核大小
- stride:步长
- padding:填充
激活层
激活层使用ReLU激活函数。
线性整流函数(Rectified Linear Unit, ReLU),又称修正线性单元,是一种人工神经网络中常用的激活函数(activation function),通常指代以斜坡函数及其变种为代表的非线性函数。
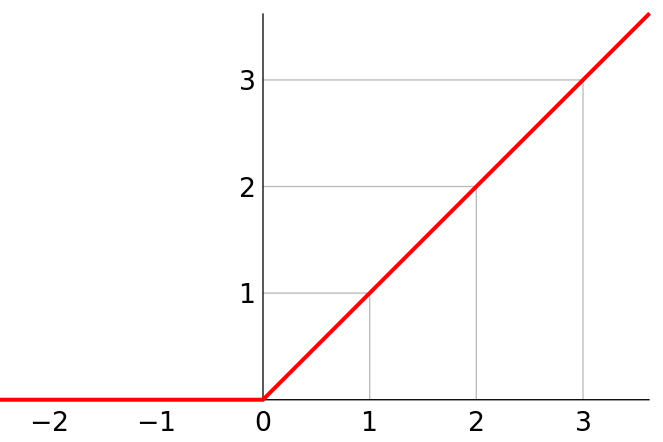
torch.nn.ReLU()
池化层
池化层采用最大池化。
池化(pooling)后,C(C.hannels)不变,W(width)和H(Height)变。
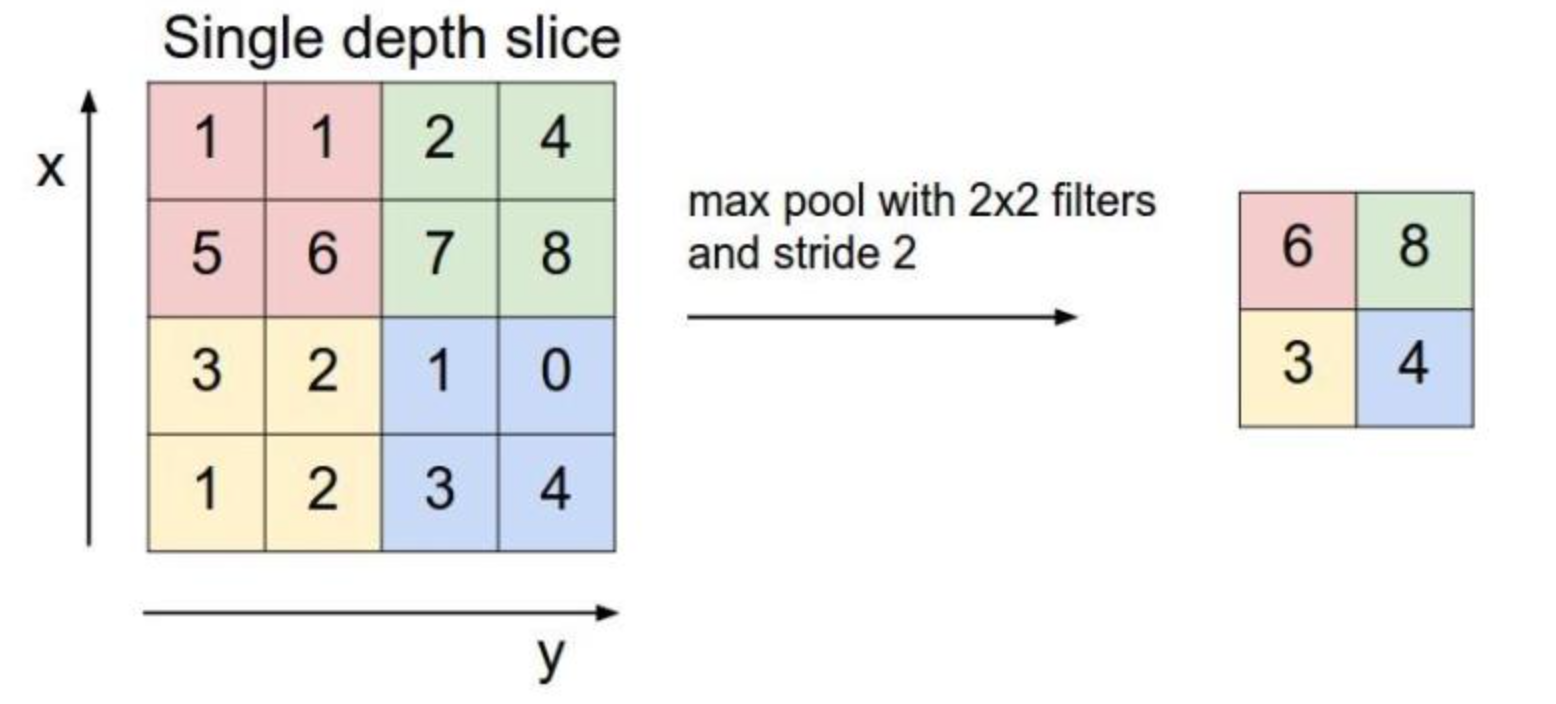
torch.nn.MaxPool2d(input, kernel_size, stride, padding)
参数:
- input:输入
- kernel_size:卷积核大小
- stride:步长
- padding:填充
全连接层
之前卷积层要求输入输出是四维张量(B,C,W,H),而全连接层的输入与输出都是二维张量(B,Input_feature),经过卷积、激活、池化后,使用view打平,进入全连接层。
LeNet5模型
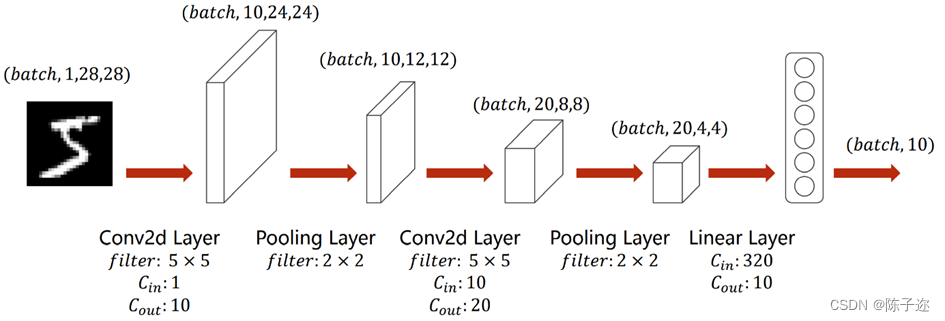
比如输入一个手写数字“5”的图像,它的维度为(batch,1,28,28)即单通道高宽分别为28像素。
首先通过一个卷积核为5×5的卷积层,其通道数从1变为10,高宽分别为24像素;
然后通过一个卷积核为2×2的最大池化层,通道数不变,高宽变为一半,即维度变成(batch,10,12,12);
然后再通过一个卷积核为5×5的卷积层,其通道数从10变为20,高宽分别为8像素;
再通过一个卷积核为2×2的最大池化层,通道数不变,高宽变为一半,即维度变成(batch,20,4,4);
之后将其view展平,使其维度变为320(2044)之后进入全连接层,用线性函数将其输出为10类,即“0-9”10个数字。
模型代码:
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(1, 10, kernel_size=5),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2),
)
self.conv2 = torch.nn.Sequential(
torch.nn.Conv2d(10, 20, kernel_size=5),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2),
)
self.fc = torch.nn.Sequential(
torch.nn.Linear(320, 100),
torch.nn.Linear(100, 50),
torch.nn.Linear(50, 10)
)
def forward(self, x):
batch_size = x.size(0)
x = self.conv1(x) # 一层卷积层,一层池化层,一层激活层(图是先卷积后激活再池化,差别不大)
x = self.conv2(x) # 再来一次
x = x.view(batch_size, -1) # flatten 变成全连接网络需要的输入 (batch, 20,4,4) ==> (batch,320), -1 此处自动算出的是320
x = self.fc(x)
return x # 最后输出的是维度为10的,也就是(对应数学符号的0~9)
2.读入数据
1.引入库
import torch
import numpy as np
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import torch.nn.functional as F
2.装载数据集
compose的作用是组合打包,这边需要将数据转化为Tensor同时进行标准化
dataset用来下载数据集 下载前把download设置为ture 下载完设为false
dataloader用来装载数据集 shuffle用来打乱数据集,防止数据存放顺序影响特征提取
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='./data/mnist', train=True, download=False, transform=transform)
test_dataset = datasets.MNIST(root='./data/mnist', train=False, download=False, transform=transform) # train=True训练集,=False测试集
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
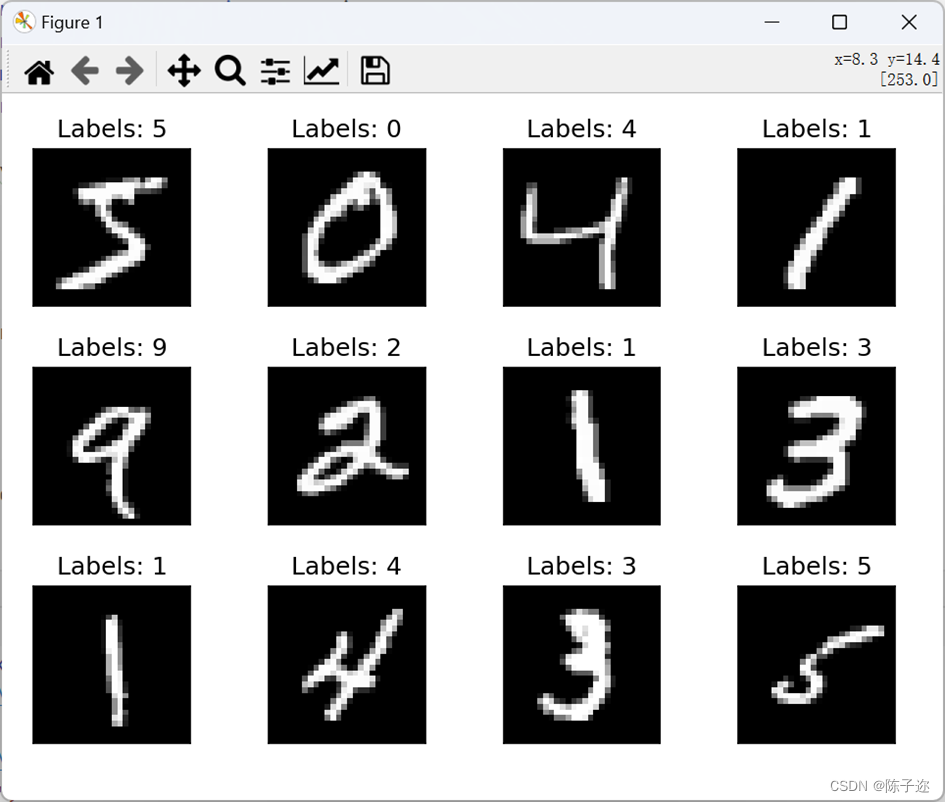
3.展示数据集内容
fig = plt.figure()
for i in range(12):
plt.subplot(3, 4, i+1)
plt.tight_layout()
plt.imshow(train_dataset.train_data[i], cmap='gray', interpolation='none')
plt.title("Labels: {}".format(train_dataset.train_labels[i]))
plt.xticks([])
plt.yticks([])
plt.show()
4.加载优化器和参数
model = Net()
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum) # lr学习率,momentum冲量
.参数设置
batch_size = 64
learning_rate = 0.01
momentum = 0.5
EPOCH = 5
5.训练轮
def train(epoch):
running_loss = 0.0 # 这整个epoch的loss清零
running_total = 0
running_correct = 0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
# 把运行中的loss累加起来,为了下面300次一除
running_loss += loss.item()
# 把运行中的准确率acc算出来
_, predicted = torch.max(outputs.data, dim=1)
running_total += inputs.shape[0]
running_correct += (predicted == target).sum().item()
if batch_idx % 300 == 299: # 不想要每一次都出loss,浪费时间,选择每300次出一个平均损失,和准确率
print('[%d, %5d]: loss: %.3f , acc: %.2f %%'
% (epoch + 1, batch_idx + 1, running_loss / 300, 100 * running_correct / running_total))
running_loss = 0.0 # 这小批300的loss清零
running_total = 0
running_correct = 0 # 这小批300的acc清零
6.测试轮
def test():
correct = 0
total = 0
with torch.no_grad(): # 测试集不用算梯度
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度,沿着行(第1个维度)去找1.最大值和2.最大值的下标
total += labels.size(0) # 张量之间的比较运算
correct += (predicted == labels).sum().item()
acc = correct / total
print('[%d / %d]: Accuracy on test set: %.1f %% ' % (epoch+1, EPOCH, 100 * acc)) # 求测试的准确率,正确数/总数
return acc
7.主代码
if __name__ == '__main__':
acc_list_test = []
for epoch in range(EPOCH):
train(epoch)
# if epoch % 10 == 9: #每训练10轮 测试1次
acc_test = test()
acc_list_test.append(acc_test)
plt.plot(acc_list_test)
plt.xlabel('Epoch')
plt.ylabel('Accuracy On TestSet')
plt.show()


mymodel自建模型
设计思路参考了vgg16网络和BN网络
采用每两层卷积叠加一层池化的方式丰富参数量,同时引入BN网络的思想,在每层的输入前增加一次归一化,增强非线性,加快模型收敛速度。最后引入drop正则机制,防止系统过拟合。
模型使用为(32*32*1)
class mymodel(nn.Module):
def __init__(self):
super(mymodel,self).__init__()
self.cov1_1 = nn.Conv2d(1, 6,kernel_size=(3,3), stride=(1, 1),padding="same")
self.bn1_1 = nn.BatchNorm2d(6)
self.cov1_2 = nn.Conv2d(6, 12,kernel_size=(3,3), stride=(1, 1),padding="same")
self.bn1_2 = nn.BatchNorm2d(12)
self.maxpool1 = nn.MaxPool2d((2,2),stride=2)
self.cov2_1 = nn.Conv2d(12, 24, kernel_size=(3, 3), stride=(1, 1), padding="same")
self.bn2_1 = nn.BatchNorm2d(24)
self.cov2_2 = nn.Conv2d(24, 48, kernel_size=(3, 3), stride=(1, 1), padding="same")
self.bn2_2 = nn.BatchNorm2d(48)
self.maxpool2 = nn.MaxPool2d((2, 2), stride=2)
self.cov3_1 = nn.Conv2d(48,96, kernel_size=(3, 3), stride=(1, 1), padding="same")
self.bn3_1 = nn.BatchNorm2d(96)
self.cov3_2 = nn.Conv2d(96, 192, kernel_size=(3, 3), stride=(1, 1), padding="same")
self.bn3_2 = nn.BatchNorm2d(192)
self.maxpool3 = nn.MaxPool2d((2, 2), stride=2)
self.cov4_1 = nn.Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1))
self.bn4_1 = nn.BatchNorm2d(384)
self.flatten = nn.Flatten()
self.do = nn.Dropout(0.5)
self.fc = nn.Linear(384*2*2, 10)
def forward(self, x):
x = self.cov1_1(x)
x = self.bn1_1(x)
x = F.relu(x)
x = self.cov1_2(x)
x = self.bn1_2(x)
x = F.relu(x)
x = self.maxpool1(x)
x = self.cov2_1(x)
x = self.bn2_1(x)
x = F.relu(x)
x = self.cov2_2(x)
x = self.bn2_2(x)
x = F.relu(x)
x = self.maxpool2(x)
x = self.cov3_1(x)
x = self.bn3_1(x)
x = F.relu(x)
x = self.cov3_2(x)
x = self.bn3_2(x)
x = F.relu(x)
x = self.maxpool3(x)
x = self.cov4_1(x)
x = self.bn4_1(x)
x = F.relu(x)
x = self.flatten(x)
x = self.do(x)
x = self.fc(x)
x = F.relu(x)
return x


(11层的模型)
上述代码是32*32,数据集是28*28,前面需要加一步尺寸变换
可以看出自建模型的收敛速度明显更快,准确度也明显提高。
总结
总代码就不展示了 按顺序复制粘贴就可以了,有不清楚的评论区可以提问