Elasticsearch环境搭建
大家好我是迷途,一个在互联网行业,摸爬滚打的学子。热爱学习,热爱代码,热爱技术。热爱互联网的一切。再也不怕elasticsearch系列,帅途会慢慢由浅入深,为大家剖析一遍,各位大佬请放心,虽然这个系列帅途有时候更新的有点慢,但是绝对不会烂尾!如果你喜欢本系列的话,就快点赞关注收藏安排一波吧~
什么是Elasticsearch
ElasticSearch简称ES,他是一个开源的搜索引擎基于Lucene是当下最先进、高性能、全功能的搜索引擎库,Java编写。他对Lucene进行了封装,简化了开发者操作
ES的作用
- 全文搜索引擎
- 分布式试试文档存储引擎
- 分布式实时分析搜索引擎
- 可拓展性高,并且支持PB级别数据存储(1PB=1024TB)
ES发家史

简单来说,就是一个程序员为了在泡妞的同时为了方便工作做出来的一个基于Lucene的搜索引擎
ES安装
这里使用winscp工具上传
解压:在你上传的文件目录下解压es
tar -zxvf elasticsearch-7.3.2-no-jdk-linux-x86_64.tar.gz
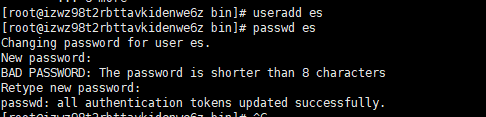
- 新增es启动用户,并授权(注:在es5.0之后,出于考虑,不允许root用户直接启动es,所以我们在这里新增用户)
useradd es #添加一个名为es用户
passwd es #将它的密码设置为es
chown -R es:es /java/elasticsearch-7.3.2/ #给es用户授予文件所在目录权限

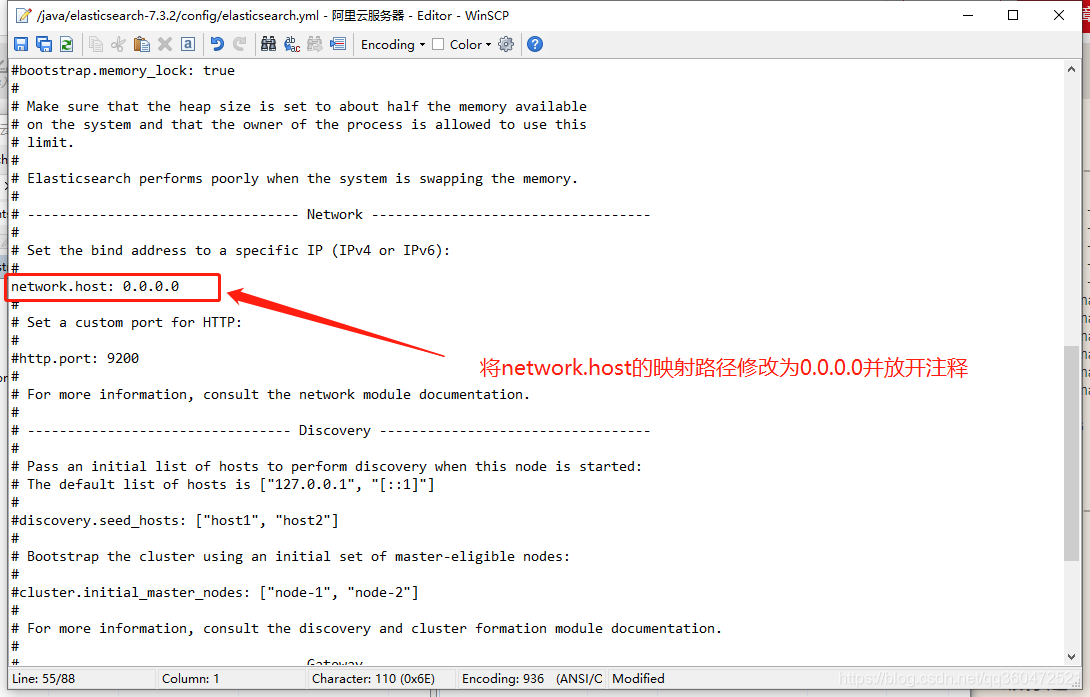
- 修改es中config目录下的elasticsearch.yml文件
这里博主直接使用winscp工具修改,不习惯的朋友在es的config目录找到elasticlsearch.yml使用vim修改即可。修改这里是因为当我们在服务器配置了es之后,es正常启动却无法访问。
- 测试启动es
ES_JAVA_OPTS="-Xms2g -Xmx2g" ./elasticsearch -d
# ES_JAVA_OPTS="-Xms2g -Xmx2g" 选填,设置es的启动参数,不写则默认读取配置文件中jvm.options中的配置
# -d 选填,后台启动
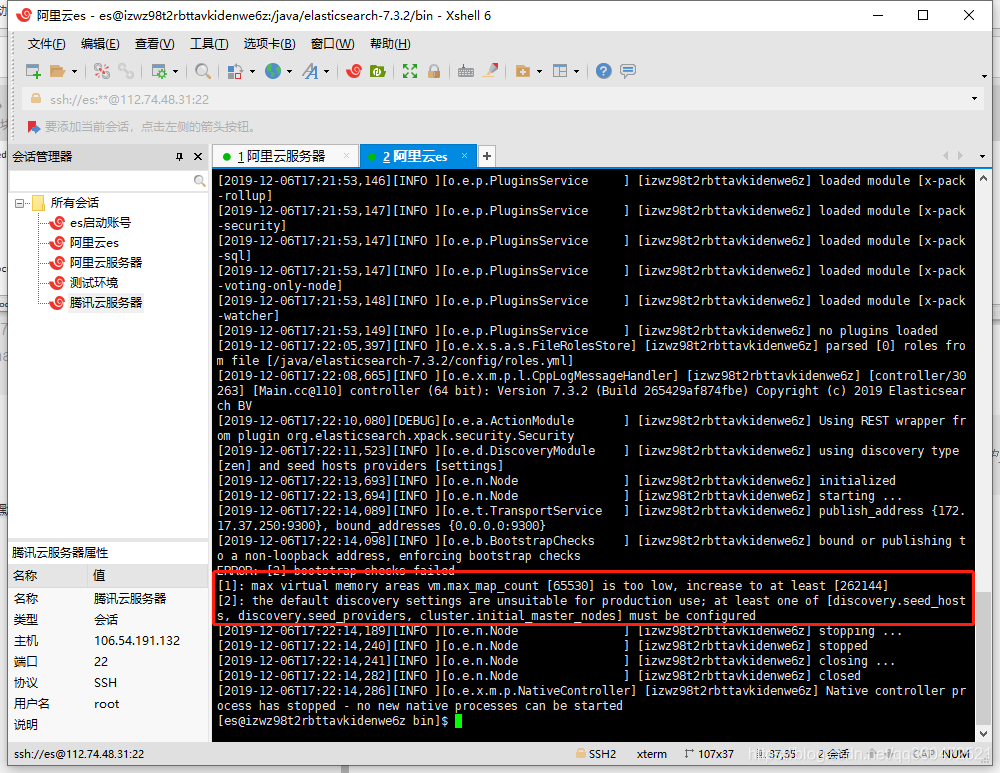
出现两个问题:
1、max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
用户拥有内存权限太小,我们切换root用户修改内存权限即可
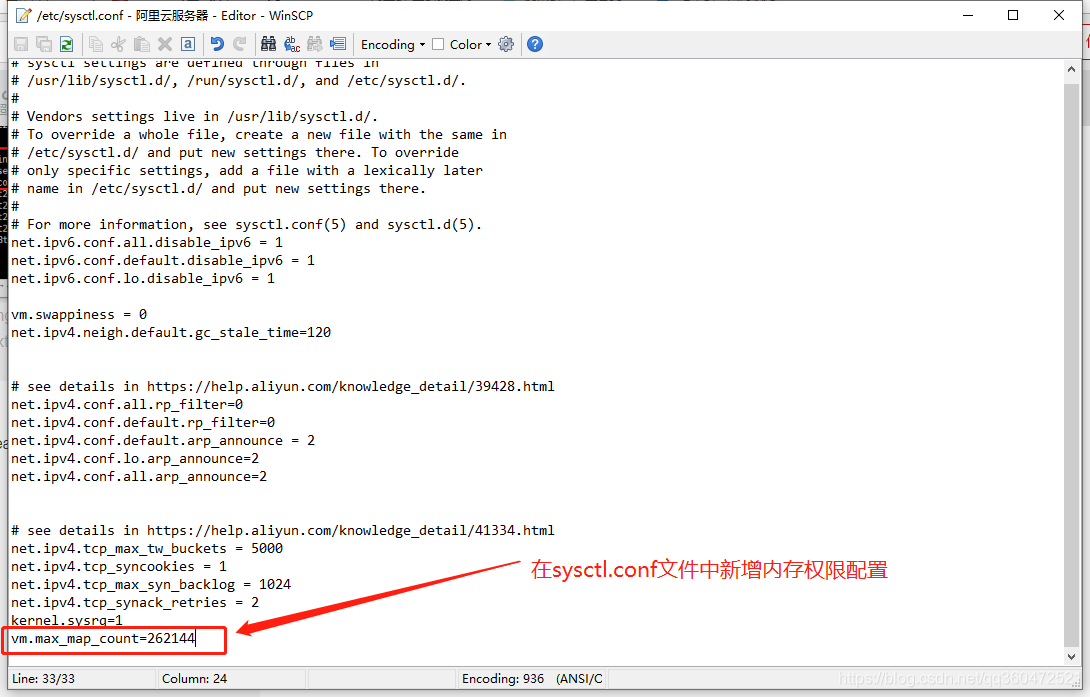
在 /etc/sysctl.conf文件最后添加一行
vm.max_map_count=262144
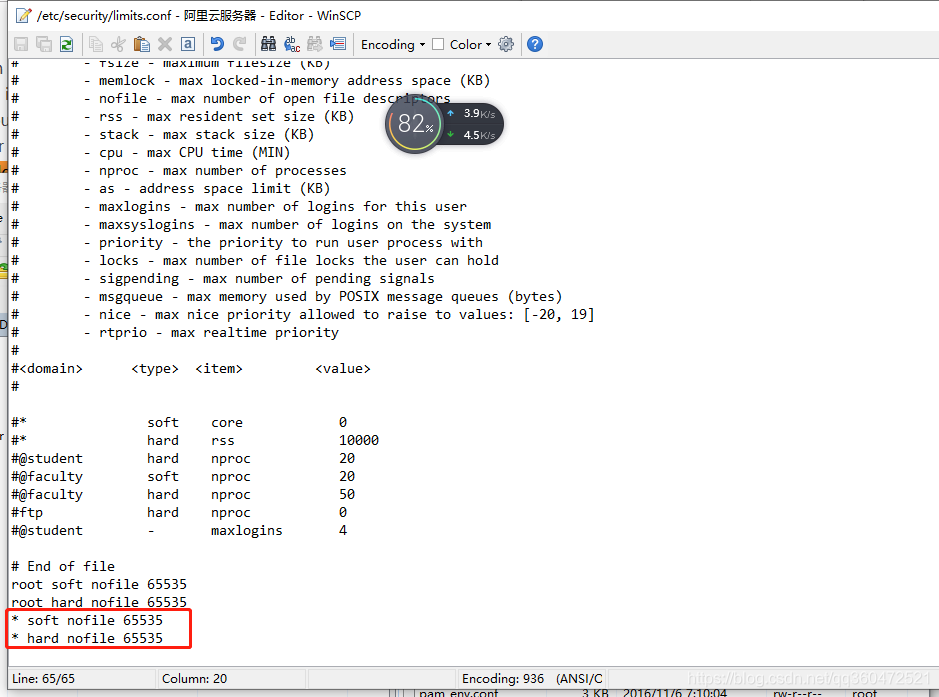
修改/etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
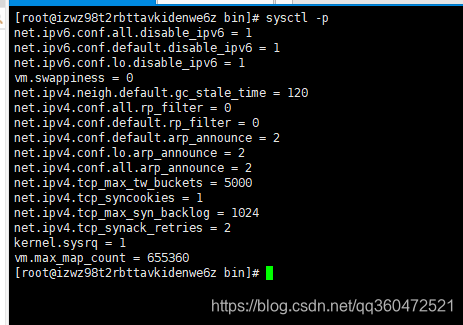
修改并保存后执行
sysctl -p #刷新配置
2、the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
// 简单来说就是叫你配置节点
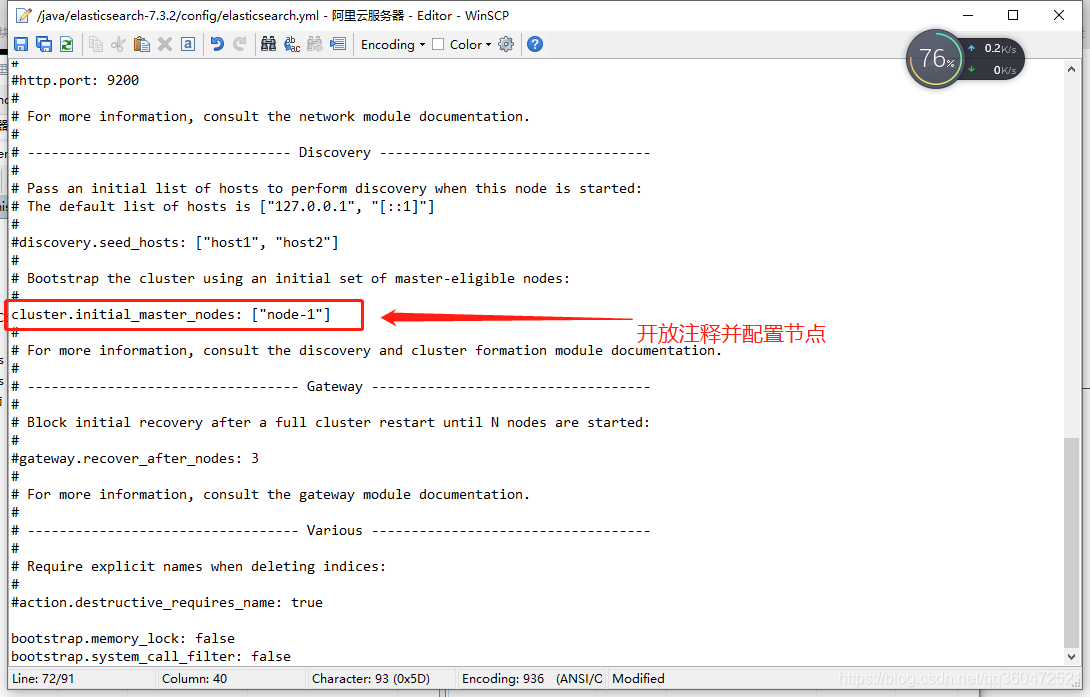
在es的config包中找到elasticsearch.yml取消注释并配置节点
cluster.initial_master_nodes: [“node-1”]
curl 127.0.0.1:9200
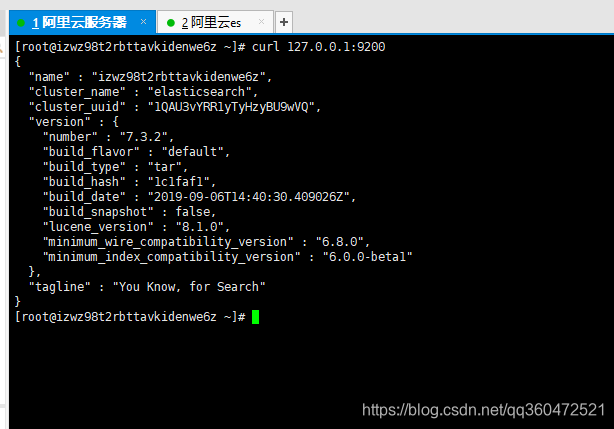
外网访问
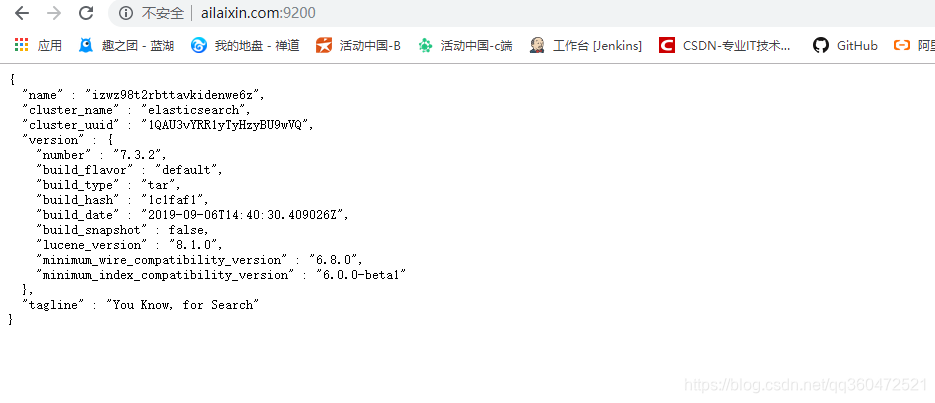
注:有些小可爱,发现外网无法访问,curl却可以成功,请检查你服务器端口是否开放
集群搭建
-
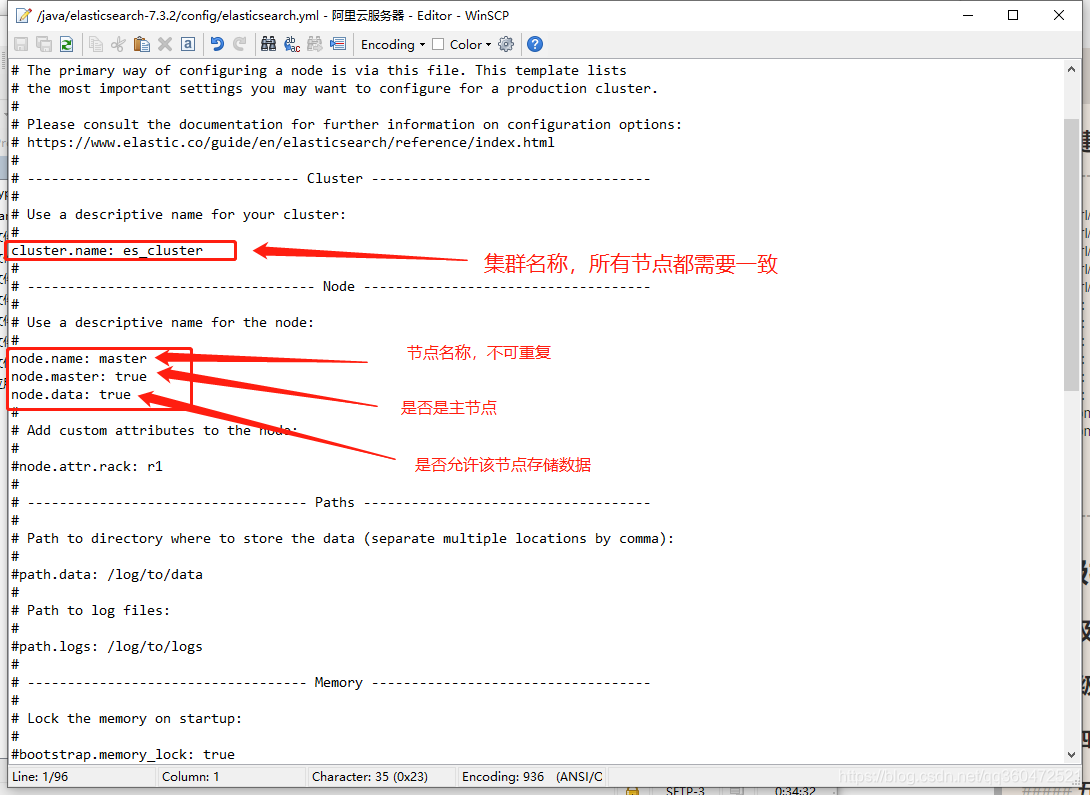
配置主节点:主节点配置中,需要手动配置该节点信息。在我们启动集群之后,es会根据我们的配置信息进行选举
-
配置从节点:在从节点的配置中,大体配置都是一样,如果是单机部署集群,那么需要更改端口号。否者会端口号占用启动不成功,在集群中所有节点集群名称必须一致,但节点名称不可重复。集群之间的默认访问端口是9300
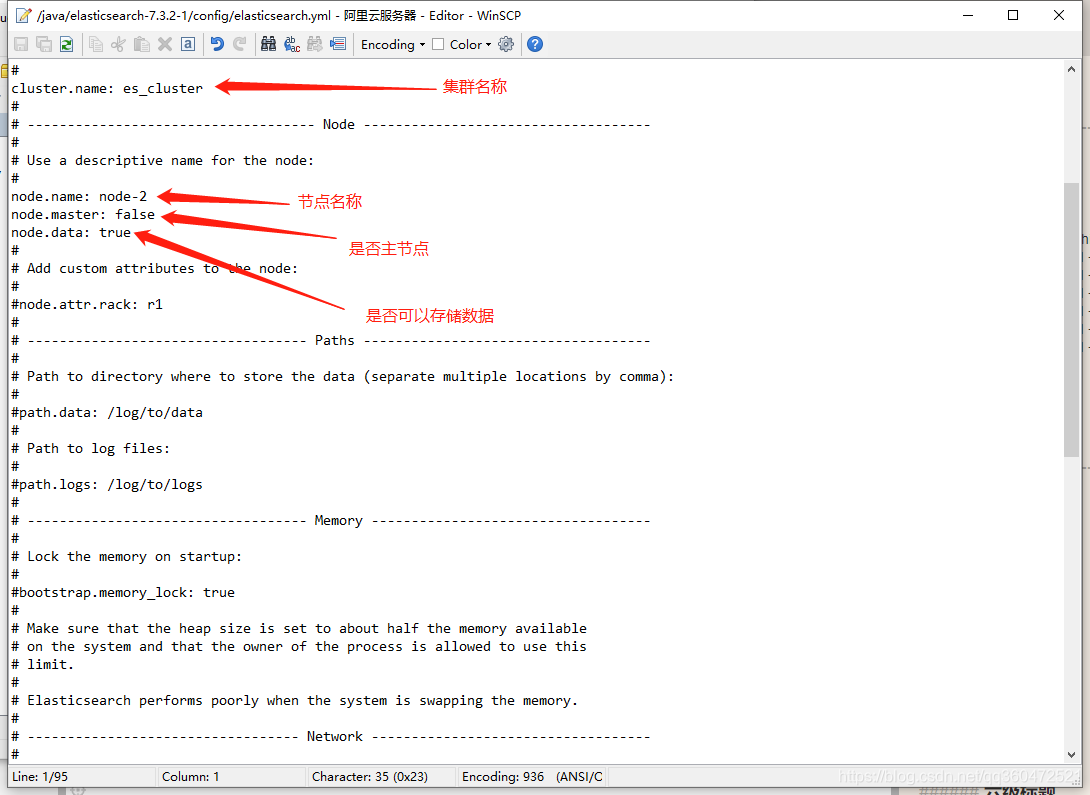
+主节点配置
# 集群名称
cluster.name: "es_cluster"
# 节点名称,这儿我直接取名为 master
node.name: master
# 是否可以成为master节点
node.master: true
# 是否允许该节点存储数据,默认开启
node.data: true
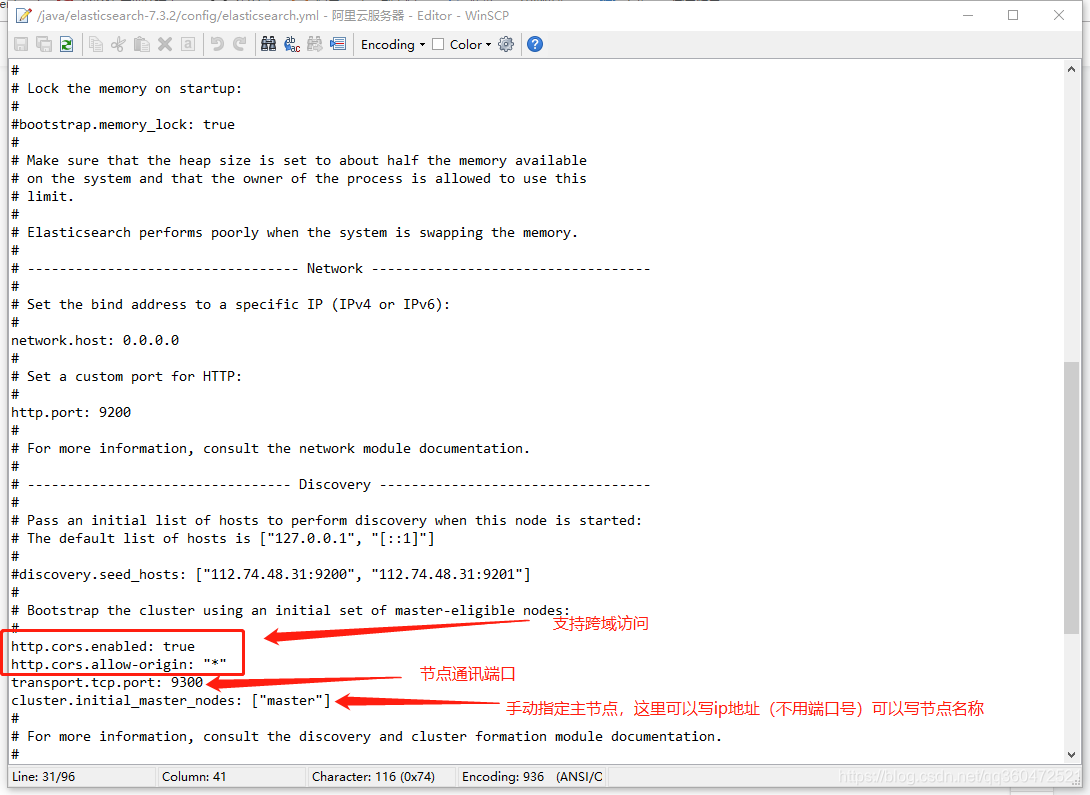
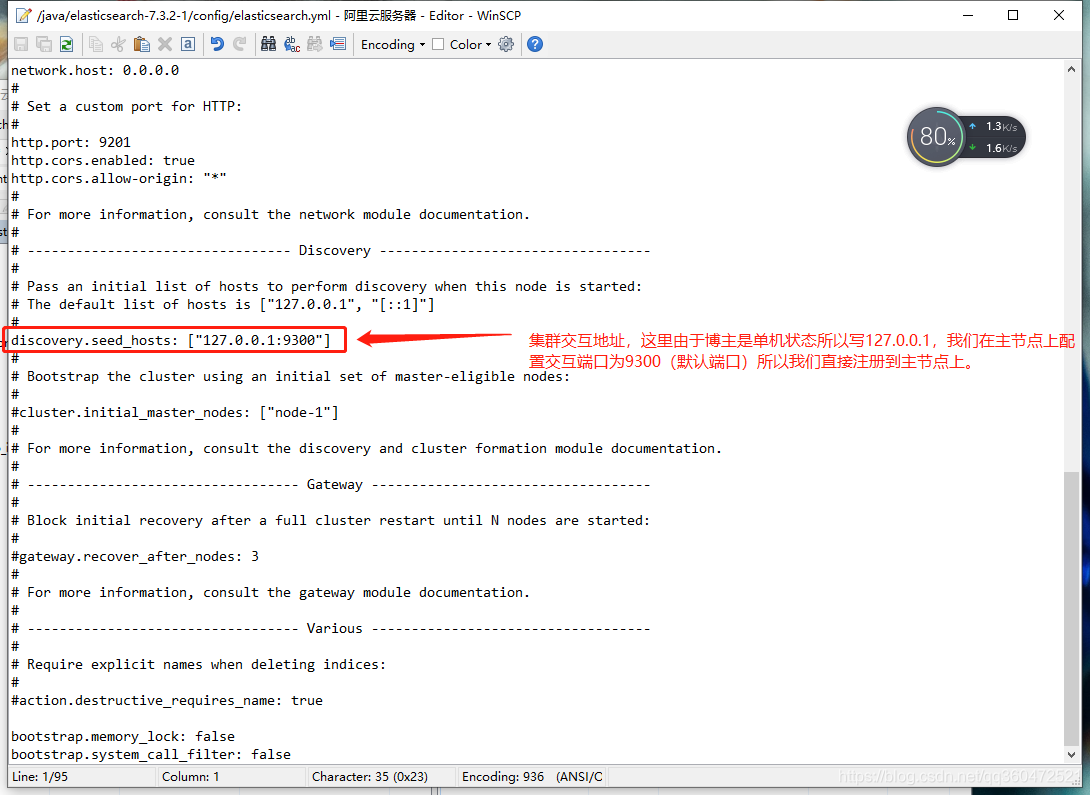
# 网络绑定,这里我绑定 0.0.0.0,支持外网访问
network.host: 0.0.0.0
# 设置对外服务的http端口,默认为9200
http.port: 9200
# 支持跨域访问
http.cors.enabled: true
http.cors.allow-origin: "*"
# 设置节点间交互的tcp端口,默认是9300
transport.tcp.port: 9300
# 手动指定可以成为 mater 的所有节点的 name 或者 ip,这些配置将会在第一次选举中进行计算
cluster.initial_master_nodes: ["127.0.0.1"]
# 集群名称,处于同一个集群所有节点,该名称必须相同
cluster.name: "es_cluster"
# 节点名称
node.name: slave1
# 是否可以成为主节点
node.master: false
# 是否允许该节点存储数据,默认开启
node.data: true
# 支持所有ip访问
network.host: 0.0.0.0
# 设置对外服务的http端口,默认为9200,这里我们修改为 9201,不然会有端口冲突
http.port: 9201
# 支持跨域访问
http.cors.enabled: true
http.cors.allow-origin: "*"
# 集群发现
discovery.seed_hosts: ["127.0.0.1:9300"]
- 使用head查看集群状态
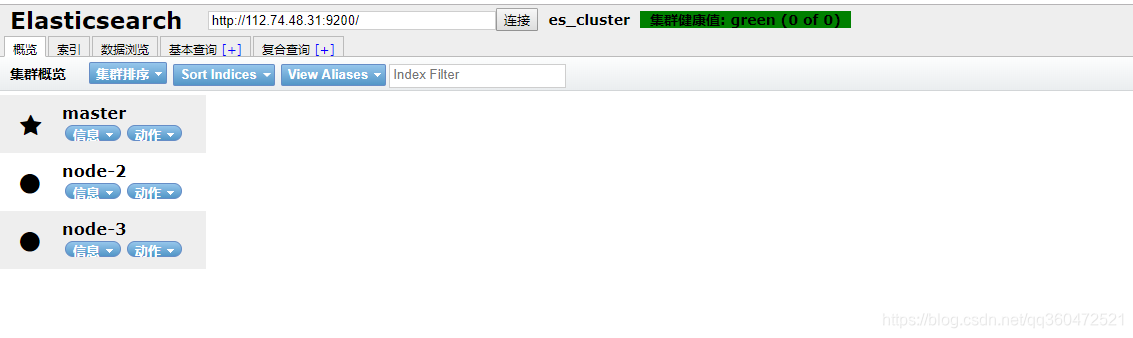
注意:es5.0版本与7.0版本在配置文件上有些许不同,小伙伴们在搭建环境的时候需要注意使用es的版本