文章目录
一、前期工作
- 导入库
- 图片生成函数
- 导入数据
- 生成数据集函数
二、CNN模型建立
三、训练模型函数
四、训练模型与结果
五、验证
大家好,我是微学AI,今天给大家带来一个利用卷积神经网络(CNN)进行中文OCR识别,实现自己的一个OCR识别工具。
一个OCR识别系统,其目的很简单,只是要把影像作一个转换,使影像内的图形继续保存、有表格则表格内资料及影像内的文字,一律变成计算机文字,使能达到影像资料的储存量减少、识别出的文字可再使用及分析,这样可节省人力打字的时间。
中文OCR识别的注意流程图:
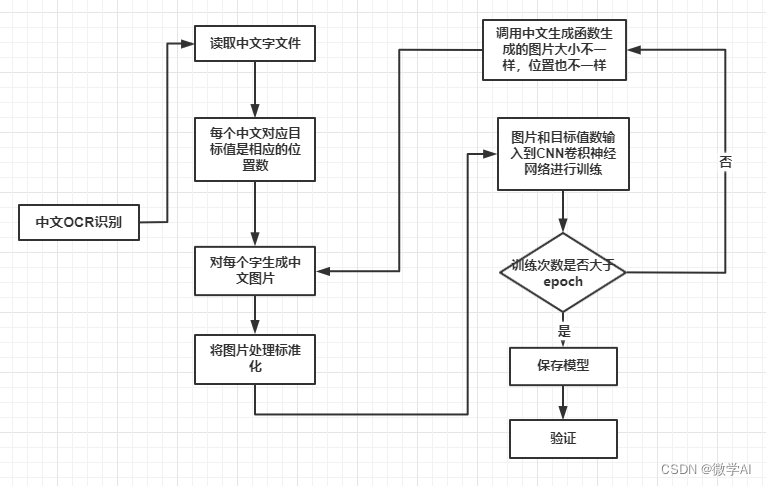
一、前期工作
1.导入库
import numpy as np
from PIL import Image, ImageDraw, ImageFont
import cv2
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.utils import plot_model
import matplotlib.pyplot as plt
#导入字体
DroidSansFallbackFull = ImageFont.truetype("DroidSansFallback.ttf", 36, 0)
fonts = [DroidSansFallbackFull,]
2.数据集生成函数
#生成图片,48*48大小
def affineTrans(image, mode, size=(48, 48)):
# print("AffineTrans ...")
if mode == 0: # padding移动
which = np.array([0, 0, 0, 0])
which[np.random.randint(0, 4)] = np.random.randint(0, 10)
which[np.random.randint(0, 4)] = np.random.randint(0, 10)
image = cv2.copyMakeBorder(image, which[0], which[0], which[0], which[0], cv2.BORDER_CONSTANT, value=0)
image = cv2.resize(image, size)
if mode == 1:
scale = np.random.randint(48, int(48 * 1.4))
center = [scale / 2, scale / 2]
image = cv2.resize(image, (scale, scale))
image = image[int(center[0] - 24):int(center[0] + 24), int(center[1] - 24):int(center[1] + 24)]
return image
#图片处理 除噪
def noise(image, mode=1):
# print("Noise ...")
noise_image = (image.astype(float) / 255) + (np.random.random((48, 48)) * (np.random.random() * 0.3))
norm = (noise_image - noise_image.min()) / (noise_image.max() - noise_image.min())
if mode == 1:
norm = (norm * 255).astype(np.uint8)
return norm
#绘制中文的图片
def DrawChinese(txt, font):
# print("DrawChinese...")
image = np.zeros(shape=(48, 48), dtype=np.uint8)
x = Image.fromarray(image)
draw = ImageDraw.Draw(x)
draw.text((8, 2), txt, (255), font=font)
result = np.array(x)
return result
#图片标准化
def norm(image):
# print("norm...")
return image.astype(np.float) / 255
3.导入数据
char_set = open("chinese.txt",encoding = "utf-8").readlines()[0]
print(len(char_set[0])) # 打印字的个数
4.生成数据集函数
# 生成数据:训练集和标签
def Genernate(batchSize, charset):
# print("Genernate...")
# pass
label = [];
training_data = [];
for x in range(batchSize):
char_id = np.random.randint(0, len(charset))
font_id = np.random.randint(0, len(fonts))
y = np.zeros(dtype=np.float, shape=(len(charset)))
image = DrawChinese(charset[char_id], fonts[font_id])
image = affineTrans(image, np.random.randint(0, 2))
# image = noise(image)
# image = augmentation(image,np.random.randint(0,8))
image = noise(image)
image_norm = norm(image)
image_norm = np.expand_dims(image_norm, 2)
training_data.append(image_norm)
y[char_id] = 1
label.append(y)
return np.array(training_data), np.array(label)
def Genernator(charset,batchSize):
print("Generator.....")
while(1):
label = [];
training_data = [];
for i in range(batchSize):
char_id = np.random.randint(0, len(charset))
font_id = np.random.randint(0,len(fonts))
y = np.zeros(dtype=np.float,shape=(len(charset)))
image = DrawChinese(charset[char_id],fonts[font_id])
image = affineTrans(image,np.random.randint(0,2))
#image = noise(image)
#image = augmentation(image,np.random.randint(0,8))
image = noise(image)
image_norm = norm(image)
image_norm = np.expand_dims(image_norm,2)
y[char_id] = 1
training_data.append(image_norm)
label.append(y)
y[char_id] = 1
yield (np.array(training_data),np.array(label))
二、CNN模型建立
def Getmodel(nb_classes):
img_rows, img_cols = 48, 48
nb_filters = 32
nb_pool = 2
nb_conv = 4
model = Sequential()
print("sequential..")
model.add(Convolution2D(nb_filters, nb_conv, nb_conv,
padding='same',
input_shape=(img_rows, img_cols, 1)))
print("add convolution2D...")
model.add(Activation('relu'))
print("activation ...")
model.add(MaxPooling2D(pool_size=(nb_pool, nb_pool)))
model.add(Dropout(0.25))
model.add(Convolution2D(nb_filters, nb_conv, nb_conv,padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(nb_pool, nb_pool)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model
#评估模型
def eval(model, X, Y):
print("Eval ...")
res = model.predict(X)
三、训练模型函数
#训练函数
def Training(charset):
model = Getmodel(len(charset))
while (1):
X, Y = Genernate(64, charset)
model.train_on_batch(X, Y)
print(model.loss)
#训练生成模型
def TrainingGenerator(charset, test=1):
set = Genernate(64, char_set)
model = Getmodel(len(charset))
BatchSize = 64
model.fit_generator(generator=Genernator(charset, BatchSize), steps_per_epoch=BatchSize * 10, epochs=15,
validation_data=set)
model.save("ocr.h5")
X = set[0]
Y = set[1]
if test == 1:
print("============6 Test == 1 ")
for i, one in enumerate(X):
x = one
res = model.predict(np.array([x]))
classes_x = np.argmax(res, axis=1)[0]
print(classes_x)
print(u"Predict result:", char_set[classes_x], u"Real result:", char_set[Y[i].argmax()])
image = (x.squeeze() * 255).astype(np.uint8)
cv2.imwrite("{0:05d}.png".format(i), image)
四、训练模型与结果
TrainingGenerator(char_set) #函数TrainingGenerator 开始训练
Epoch 1/15
640/640 [==============================] - 63s 76ms/step - loss: 8.1078 - accuracy: 3.4180e-04 - val_loss: 8.0596 - val_accuracy: 0.0000e+00
Epoch 2/15
640/640 [==============================] - 102s 159ms/step - loss: 7.5234 - accuracy: 0.0062 - val_loss: 6.2163 - val_accuracy: 0.0781
Epoch 3/15
640/640 [==============================] - 38s 60ms/step - loss: 5.9793 - accuracy: 0.0425 - val_loss: 4.1687 - val_accuracy: 0.3281
Epoch 4/15
640/640 [==============================] - 45s 71ms/step - loss: 5.0450 - accuracy: 0.0889 - val_loss: 3.1590 - val_accuracy: 0.4844
Epoch 5/15
640/640 [==============================] - 37s 58ms/step - loss: 4.5251 - accuracy: 0.1292 - val_loss: 2.5326 - val_accuracy: 0.5938
Epoch 6/15
640/640 [==============================] - 38s 60ms/step - loss: 4.1708 - accuracy: 0.1687 - val_loss: 1.9666 - val_accuracy: 0.7031
Epoch 7/15
640/640 [==============================] - 35s 54ms/step - loss: 3.9068 - accuracy: 0.1951 - val_loss: 1.8039 - val_accuracy: 0.7812
...
910
Predict result: 妻 Real result: 妻
1835
Predict result: 莱 Real result: 莱
3107
Predict result: 阀 Real result: 阀
882
Predict result: 培 Real result: 培
1241
Predict result: 鼓 Real result: 鼓
735
Predict result: 豆 Real result: 豆
1844
Predict result: 巾 Real result: 巾
1714
Predict result: 跌 Real result: 跌
2580
Predict result: 骄 Real result: 骄
1788
Predict result: 氧 Real result: 氧
生成字体图片:

五、验证
model = tf.keras.models.load_model("ocr.h5")
img1 = cv2.imread('00001.png',0)
img = cv2.resize(img1,(48,48))
print(img.shape)
img2 = tf.expand_dims(img, 0)
res = model.predict(img2)
classes_x = np.argmax(res, axis=1)[0]
print(classes_x)
print(u"Predict result:", char_set[classes_x])
中文字:

预测结果为”莱;
数据集的获取私信我!后期有更深入的OCR识别功能呈现,敬请期待!
往期作品:
深度学习实战项目
1.深度学习实战1-(keras框架)企业数据分析与预测
2.深度学习实战2-(keras框架)企业信用评级与预测
3.深度学习实战3-文本卷积神经网络(TextCNN)新闻文本分类
4.深度学习实战4-卷积神经网络(DenseNet)数学图形识别+题目模式识别
5.深度学习实战5-卷积神经网络(CNN)中文OCR识别项目
6.深度学习实战6-卷积神经网络(Pytorch)+聚类分析实现空气质量与天气预测
7.深度学习实战7-电商产品评论的情感分析
8.深度学习实战8-生活照片转化漫画照片应用
9.深度学习实战9-文本生成图像-本地电脑实现text2img
10.深度学习实战10-数学公式识别-将图片转换为Latex(img2Latex)
11.深度学习实战11(进阶版)-BERT模型的微调应用-文本分类案例
12.深度学习实战12(进阶版)-利用Dewarp实现文本扭曲矫正
13.深度学习实战13(进阶版)-文本纠错功能,经常写错别字的小伙伴的福星
14.深度学习实战14(进阶版)-手写文字OCR识别,手写笔记也可以识别了
15.深度学习实战15(进阶版)-让机器进行阅读理解+你可以变成出题者提问
16.深度学习实战16(进阶版)-虚拟截图识别文字-可以做纸质合同和表格识别
17.深度学习实战17(进阶版)-智能辅助编辑平台系统的搭建与开发案例
18.深度学习实战18(进阶版)-NLP的15项任务大融合系统,可实现市面上你能想到的NLP任务
19.深度学习实战19(进阶版)-ChatGPT的本地实现部署测试,自己的平台就可以实现ChatGPT
…(待更新)