前言
深度学习最基础的网络类型的之一,全连接神经网络(Full Connect Neural Network)是大多数入门深度学习领域的初学者必学的内容,充分体现深度学习方法相比于传统机器学习算法的特点,即大数据驱动、去公式推导、自我迭代更新、黑匣子训练等。
本文介绍单层神经网络、浅层神经网络和深层神经网络,循序渐进地加深对于深度学习基本概念的理解。需要注意的是所有代码基于飞桨PaddlePaddle架构实现。
一、单层神经网络
Logistic回归模型是最简单的单层网络,常被用来处理二分类问题,它使一种用于分析各种影响因素
(
x
1
,
x
2
,
…
,
x
n
)
(x_1,x_2,…,x_n)
(x1,x2,…,xn)与分类结果
y
y
y之间的有监督学习方法。
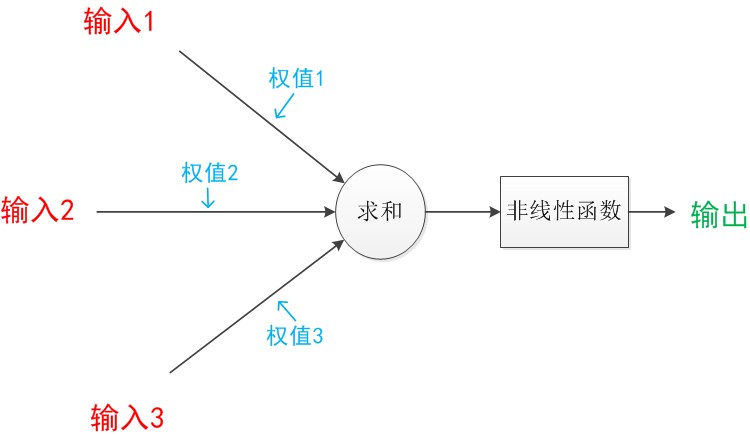
1.1 正向传播
此计算过程等同于线性回归计算,即给每一个输入向量x分配权值,计算出一个结果向量z。同时,为了使神经网络具有非线性特点,引入激活函数来处理线性变换得到的数值。
- 线性变换(加权和偏置):
z
=
w
T
x
+
b
z=w^Tx+b
z=wTx+b
- 非线性变换(激活函数):
δ
(
x
)
=
1
1
+
e
−
z
\delta (x) = \frac{1}{{1 + {e^{ - z}}}}
δ(x)=1+e−z1
上式中
w
w
w为权值,
b
b
b为偏置,
x
x
x为输入值,
z
z
z为线性输出值,
δ
\delta
δ为非线性输出值。
1.2 损失函数
模型需要定义损失函数来对参数
w
w
w和
b
b
b进行优化,损失函数的选择需要具体问题具体分析,以下为两种常见损失函数计算公式。
- 平方损失函数:
L
(
y
^
,
y
)
=
1
2
(
y
^
−
y
)
2
L(\hat y,y) = \frac{1}{2}{(\hat y - y)^2}
L(y^,y)=21(y^−y)2
- 对数似然损失函数:
L
(
y
^
,
y
)
=
−
[
y
log
y
^
+
(
1
−
y
)
log
(
1
−
y
^
)
]
L(\hat y,y) = - [y\log \hat y + (1 - y)\log (1 - \hat y)]
L(y^,y)=−[ylogy^+(1−y)log(1−y^)]
上式中
y
^
\hat y
y^为计算结果,
y
y
y为实际结果
1.3 梯度下降
梯度下降是一种前反馈计算方法,反映的是一种“以误差来修正误差”的思想,亦是神经网络进行迭代更新的核心过程。
- 迭代更新:
ω
=
ω
−
α
d
L
(
ω
)
d
ω
\omega = \omega - \alpha \frac{{dL(\omega )}}{{d\omega }}
ω=ω−αdωdL(ω)
- 链式法则:
d
L
(
a
,
y
)
d
ω
=
d
L
(
a
,
y
)
d
a
⋅
d
a
d
z
⋅
d
z
d
ω
\frac{{dL(a,y)}}{{d\omega }} = \frac{{dL(a,y)}}{{da}} \cdot \frac{{da}}{{dz}} \cdot \frac{{dz}}{{d\omega }}
dωdL(a,y)=dadL(a,y)⋅dzda⋅dωdz
单层网络的代码(Numpy实现和飞桨实现)
二、浅层神经网络
浅层神经网络相比单层网络的差别在于隐藏层有多个神经节点,这就使得其可以处理“多输入多输出”的复杂问题。每一层的每一个节点都与上下层节点全部连接,这种神经网络称作全连接网络。
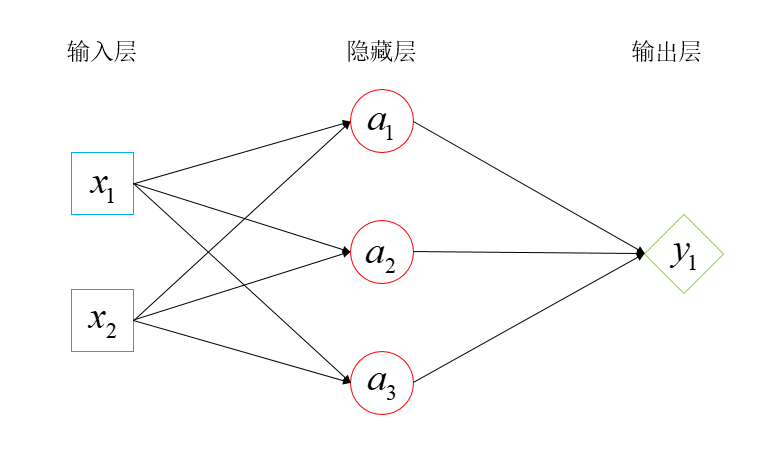
2.1 正向传播
z
[
1
]
=
(
z
1
[
1
]
z
2
[
1
]
z
3
[
1
]
)
=
(
w
1
(
1
]
T
⋅
x
+
b
1
(
1
)
w
2
[
1
]
T
⋅
x
+
b
2
[
1
]
w
3
[
1
]
T
⋅
x
+
b
3
[
1
]
)
=
(
w
1
[
1
]
T
⋅
x
w
2
[
1
]
T
⋅
x
w
3
(
1
]
T
⋅
x
)
+
b
[
1
]
=
W
[
1
]
x
+
b
[
1
]
a
[
1
]
=
(
a
1
[
1
]
a
2
[
1
]
a
3
[
1
]
)
=
(
t
(
z
1
(
1
]
)
t
(
z
2
(
1
]
)
t
(
z
3
[
1
]
)
)
=
t
(
z
1
[
1
]
z
2
[
1
]
z
3
[
1
]
)
=
t
(
z
[
1
]
)
\begin{array}{c} z^{[1]}=\left(\begin{array}{c} z_{1}^{[1]} \\ z_{2}^{[1]} \\ z_{3}^{[1]} \end{array}\right)=\left(\begin{array}{l} w_{1}^{(1] T} \cdot x+b_{1}^{(1)} \\ w_{2}^{[1] T} \cdot x+b_{2}^{[1]} \\ w_{3}^{[1] T} \cdot x+b_{3}^{[1]} \end{array}\right)=\left(\begin{array}{l} w_{1}^{[1] T} \cdot x \\ w_{2}^{[1] T} \cdot x \\ w_{3}^{(1] T} \cdot x \end{array}\right)+b^{[1]}=W^{[1]} x+b^{[1]} \\ a^{[1]}=\left(\begin{array}{l} a_{1}^{[1]} \\ a_{2}^{[1]} \\ a_{3}^{[1]} \end{array}\right)=\left(\begin{array}{c} t\left(z_{1}^{(1]}\right) \\ t\left(z_{2}^{(1]}\right) \\ t\left(z_{3}^{[1]}\right) \end{array}\right)=t\left(\begin{array}{c} z_{1}^{[1]} \\ z_{2}^{[1]} \\ z_{3}^{[1]} \end{array}\right)=t\left(z^{[1]}\right) \end{array}
z[1]=⎝⎜⎛z1[1]z2[1]z3[1]⎠⎟⎞=⎝⎜⎛w1(1]T⋅x+b1(1)w2[1]T⋅x+b2[1]w3[1]T⋅x+b3[1]⎠⎟⎞=⎝⎜⎛w1[1]T⋅xw2[1]T⋅xw3(1]T⋅x⎠⎟⎞+b[1]=W[1]x+b[1]a[1]=⎝⎜⎛a1[1]a2[1]a3[1]⎠⎟⎞=⎝⎜⎜⎜⎛t(z1(1])t(z2(1])t(z3[1])⎠⎟⎟⎟⎞=t⎝⎜⎛z1[1]z2[1]z3[1]⎠⎟⎞=t(z[1])
- 上角标中括号用于区分不同层
- 下角标数字表示神经元节点的映射关系
- 一个神经元节点包含上一层节点数
ω
x
ω_x
ωx和
b
x
b_x
bx和下一层节点数
z
y
z_y
zy
2.2 反向传播
- 梯度下降法
W
=
W
−
α
∂
L
∂
W
b
=
b
−
α
∂
L
∂
b
\begin{aligned} \boldsymbol{W} &=\boldsymbol{W}-\alpha \frac{\partial L}{\partial \boldsymbol{W}} \\ b &=b-\alpha \frac{\partial L}{\partial b} \end{aligned}
Wb=W−α∂W∂L=b−α∂b∂L
- 向量表达式
W
[
1
]
=
(
w
1
[
1
]
,
w
2
[
1
]
,
w
3
[
1
]
)
T
=
[
w
1
[
1
]
T
w
2
[
1
]
T
w
3
[
1
]
T
]
=
[
w
11
[
1
]
,
w
12
[
1
]
w
21
[
1
]
,
w
22
[
1
]
w
31
[
1
]
,
w
32
[
1
]
]
b
[
1
]
=
[
b
1
[
1
]
b
2
[
1
]
b
3
[
1
]
]
\boldsymbol{W}^{[1]}=\left(\boldsymbol{w}_{1}^{[1]}, \boldsymbol{w}_{2}^{[1]}, \boldsymbol{w}_{3}^{[1]}\right)^{\mathrm{T}}=\left[\begin{array}{l} \boldsymbol{w}_{1}^{[1]^{\mathrm{T}}} \\ \boldsymbol{w}_{2}^{[1] \mathrm{T}} \\ \boldsymbol{w}_{3}^{[1] \mathrm{~T}} \end{array}\right]=\left[\begin{array}{c} w_{11}^{[1]}, w_{12}^{[1]} \\ w_{21}^{[1]}, w_{22}^{[1]} \\ w_{31}^{[1]}, w_{32}^{[1]} \end{array}\right] \quad b^{[1]}=\left[\begin{array}{l} b_{1}^{[1]} \\ b_{2}^{[1]} \\ b_{3}^{[1]} \end{array}\right]
W[1]=(w1[1],w2[1],w3[1])T=⎣⎢⎡w1[1]Tw2[1]Tw3[1] T⎦⎥⎤=⎣⎢⎡w11[1],w12[1]w21[1],w22[1]w31[1],w32[1]⎦⎥⎤b[1]=⎣⎢⎡b1[1]b2[1]b3[1]⎦⎥⎤
浅层网络的代码(Numpy实现和飞桨实现)
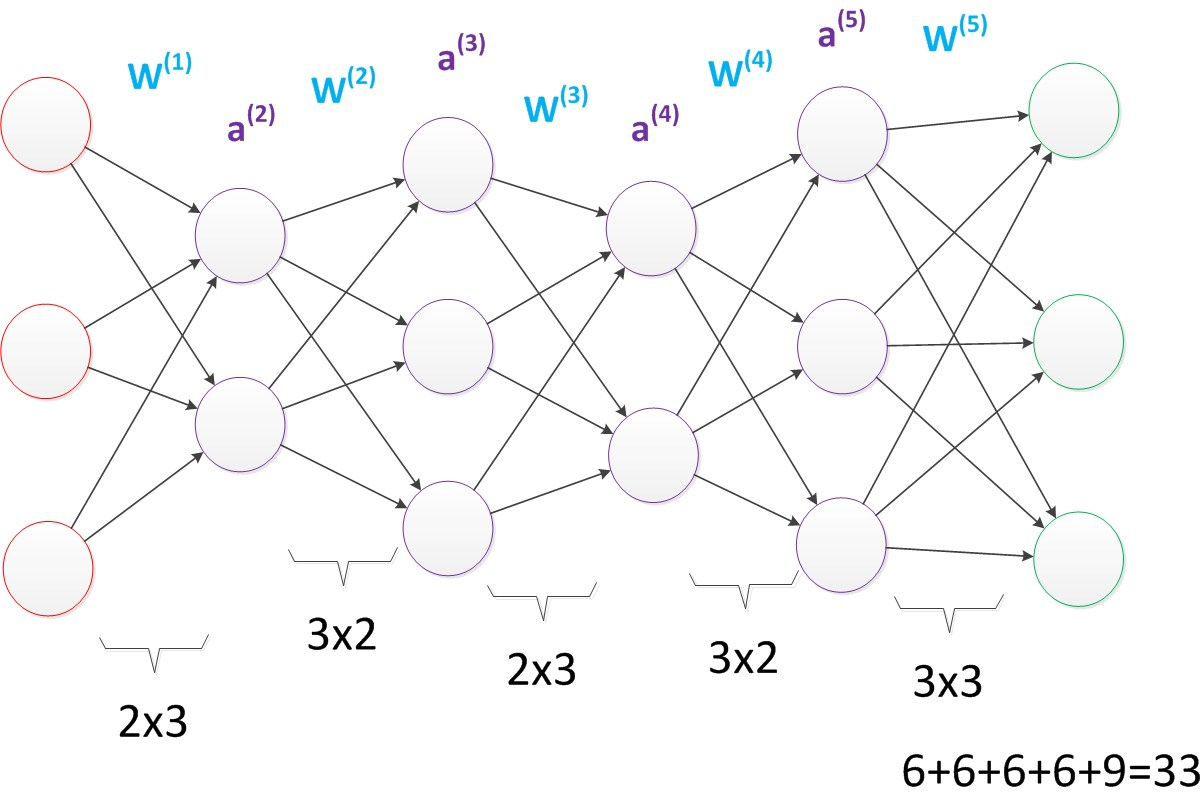
三、深层神经网络
随着网络的层数增加,每一层对于前一层次的抽象表示更深入。在神经网络中,每一层神经元学习到的是前一层神经元值的更抽象的表示。例如第一个隐藏层学习到的是"边缘”的特征,第二个隐藏层学习到的是由‘边缘"组成的"形状”的特征,第三个隐藏层学习到的是由"形状"组成的“图案”的特征,最后的隐藏层学习到的是由“图案"组成的"目标"的特征。通过抽取更抽象的特征来对事物进行区分,从而获得更好的区分与分类能力。
3.1 ImageNet发展史
针对ImageNet数据集的图像分类任务,人们提出了许多重要的网络模型,生动形象地向我们展示了深层网络的巨大优势,回顾整个发展史能够发现,深度学习的网络层数从8层到152层逐步增加,网络分类的能力也越来越强。
| 年份 |
算法 |
错误率 |
主要贡献 |
| 1994 |
LeNet5 |
- |
卷积、池化和全连接,标志CNN的诞生 |
| 2012 |
Alex |
15.3% |
ReLU、Dropout、归一化 |
| 2014 |
GoogLeNet |
6.66% |
没有最深只有更深、Inception模块 |
| 2015 |
ResNet |
3.57% |
152层,深度残差网络 |
| 2016、2017 |
Soushen、Momenta |
2.99%、2.251% |
SE模块嵌入残差网络 |
3.2 网络参数
- 参数:指算法运行迭代、修正最终稳定的值。权重W和偏置b。
- 超参:开发者人为设定的值。学习率、迭代次数、隐藏层层数、单元节点数、激活函数等
深层网络的代码(Numpy实现和飞桨实现)
总结及展望
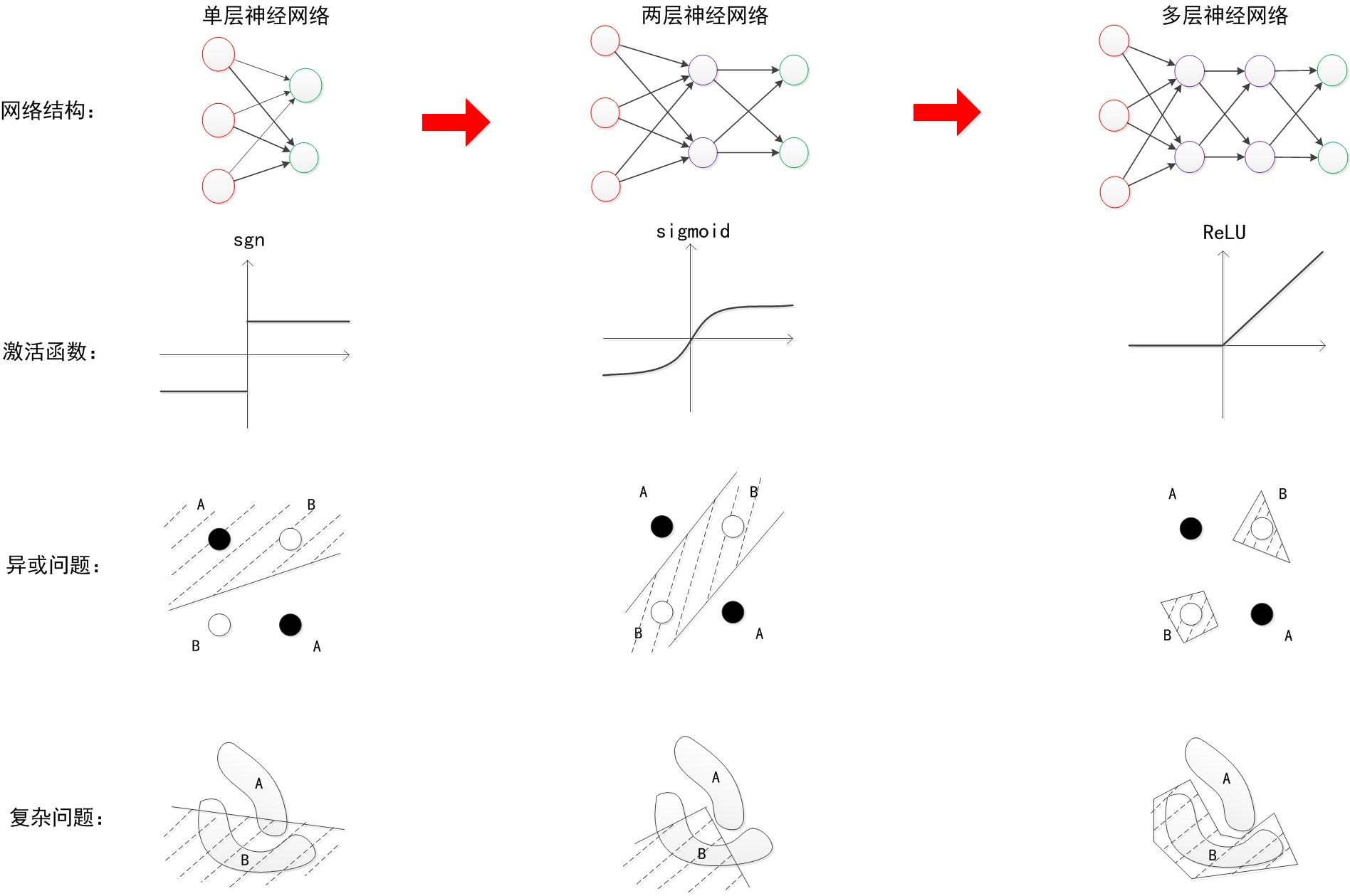 全连接神经网络可以用来解决回归任务、预测任务和分类任务,在不考虑计算机性能的条件下,无脑设置更深层次的网络模型往往可以取得更好的效果。本质上它是一种线性神经网络,无法避免地要面临处理非线性数据集精度差的问题。优化主要集中在以下几个方面。
全连接神经网络可以用来解决回归任务、预测任务和分类任务,在不考虑计算机性能的条件下,无脑设置更深层次的网络模型往往可以取得更好的效果。本质上它是一种线性神经网络,无法避免地要面临处理非线性数据集精度差的问题。优化主要集中在以下几个方面。
- 非线性因素:围绕激活函数展开来说,提高计算速率就要使激活函数去积分化、去微分化、易求偏导,解决梯度消失和梯度爆炸的问题。
- 迭代更新策略:围绕反向传播更新权值和偏置,如损失函数选择、优化器选择、学习率衰减策略等等,在一定程度上可以提高精度。这类问题本质上仍是一种寻优算法的探索,可以引入遗传算法、差分进化、多目标优化等寻找pareto最优解,
- 骨干网络:网络应该设置多少层,每一层应该有多少个节点,从来没有一套标准的设计模板,毫无方向的在不断测试中摸索前进。