图像去水印
去水印代码代码部分
代码学习交流 请私信
摘要
水印是一种常用的保护技术媒体的版权。同时,为了提高水印的丰满度,攻击技术,如去除标记,也得到了关注。
以前的水印去除方法需要获得水印标记用户位置或训练多任务网络以无差别地恢复背景。
然而,当联合学习,网络在水印方面表现更好检测而不是恢复纹理。受此观察的启发-和盲目抹去可见的水印,我们建议一种新的两阶段叠加注意力引导框架重新设置以模拟检测、删除和精炼在第一阶段,我们设计了一个多任务网络称为SplitNet。
它学习三个子任务的基本特征而特定于任务的特性单独使用频道注意事项。然后,**使用预测的掩码和更粗糙的恢复图像,**我们设计了RefineNet来平滑带有掩模的水印区域引导了空间注意力。
所提出的算法还包括将多重感知损失结合起来,以获得更好的视觉质量-
在数量和数量上。我们广泛评估了我们的算法在不同设置下的四个不同数据集-
实验表明,我们的方法优于其他方法。
去水印效果

去除水印算法过程
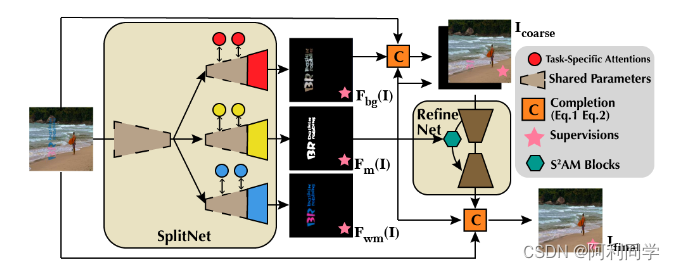
我们将基于单个图像的盲可见水印去除视为一个两阶段的任务。如图2所示,在第一阶段,给定单个带水印的图像I,我们提出了SplitNet F,一种受多域学习启发的多任务ResUNet,以生成更粗糙的中间结果:恢复的背景图像Fbg(I)、水印Fm(I)的位置(掩模)和恢复的水印Fwm(I)。因此,较粗的恢复图像Icoarse可以写为:
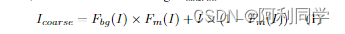
如前所述,**由于任务的难度不同,需要进一步细化以去除水印。因此,我们建议将RefineNet R作为第二阶段,它使用Icoarse和Fm(I)生成最终结果Ifinal,**并且该网络使用空间关注机制平滑预测的水印区域。最后,细化结果Ifinal可以由预测掩码Fm(I)和原始输入公式化:
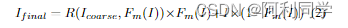
请注意,尽管所提出的方法是级联的第二网络的输入完全由第一级的输出生成。因此,我们的网络可以以端到端的方式进行培训和评估,而无需任何人工干预。下面,我们给出了建议的SplitNet、RefineNet和损失函数的详细信息
对比结果

结论
观察到检测比去除,在本文中,我们提出了一种新的两阶段框架SplitNet和RefineNet,用于基于单个图像的盲可见水印去除。SplitNet从多任务学习中获得好处,以生成更粗糙的输出(水印、掩码和背景)。此外,在SplitNet中,受多域学习的启发,我们通过共享主流解码器中的参数来构建紧凑的网络,同时单独学习任务特定的注意力。然后,RefineNet利用前一阶段的输出,学习利用空间注意力机制来细化预测区域。除了盲视觉图案/水印去除,我们的方法还可以应用于其他相关任务,如盲图像协调、阴影去除和未来工作中的反射去除