人工神经元的工作原理,大致如下: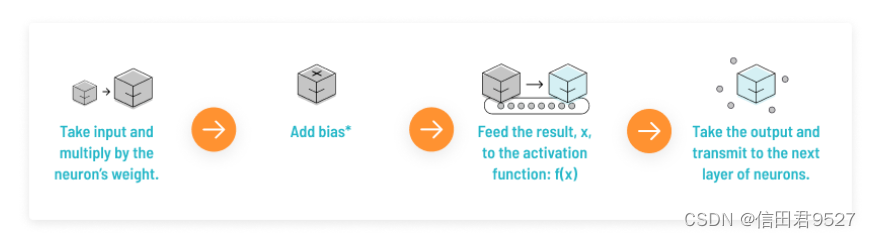
上述过程的数学可视化过程如下图: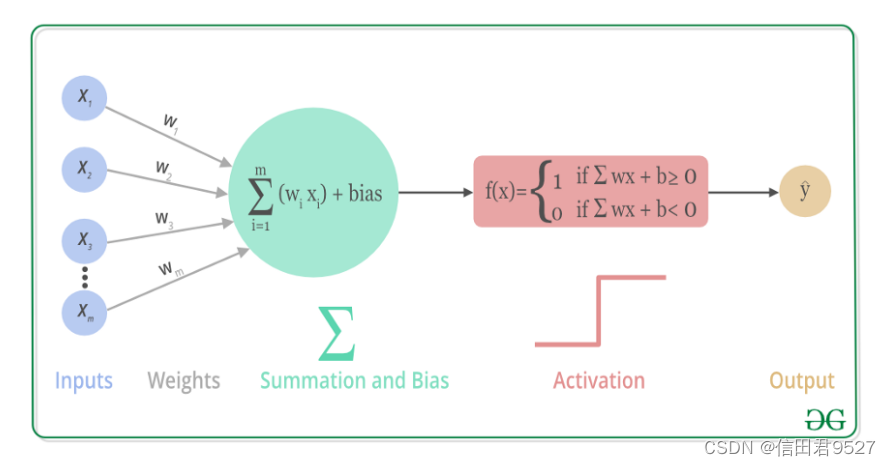
激活函数(Activation Function)是一种添加到人工神经网络中的函数,旨在帮助网络学习数据中的复杂模式。类似于人类大脑中基于神经元的模型,激活函数最终决定了要发射给下一个神经元的内容。
下面介绍一下常用的几个激活函数:
Sigmoid 激活函数
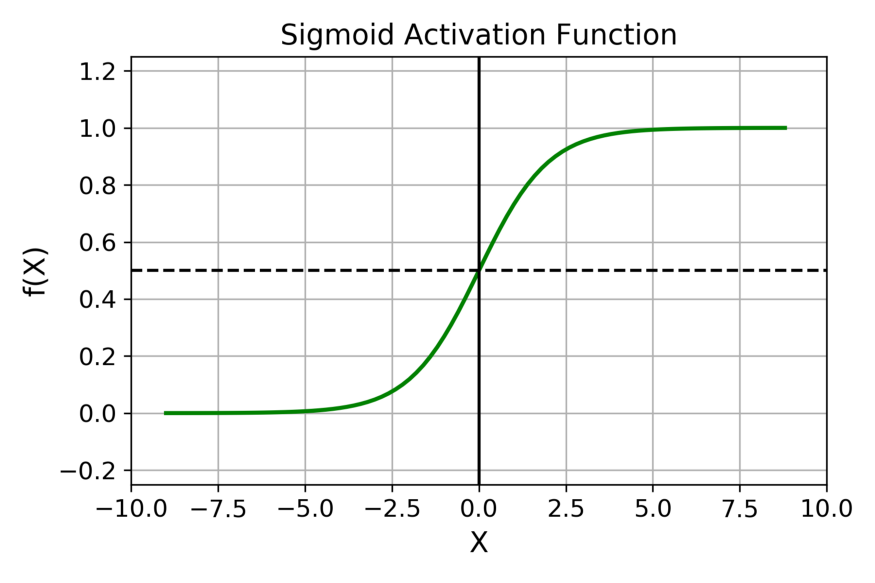

sigmoid的偏导数 g'(z)=a(1-a)
在什么情况下适合使用 Sigmoid 激活函数呢?
-
Sigmoid 函数的输出范围是 0 到 1。由于输出值限定在 0 到 1,因此它对每个神经元的输出进行了归一化;
-
用于将预测概率作为输出的模型。由于概率的取值范围是 0 到 1,因此 Sigmoid 函数非常合适;
-
梯度平滑,避免「跳跃」的输出值;
-
函数是可微的。这意味着可以找到任意两个点的 sigmoid 曲线的斜率;
-
明确的预测,即非常接近 1 或 0。
Sigmoid 激活函数有哪些缺点?
Tanh / 双曲正切激活函数


tanh的偏导数g'(z)=1-a^2
tanh 是一个双曲正切函数。tanh 函数和 sigmoid 函数的曲线相对相似。但是它比 sigmoid 函数更有一些优势
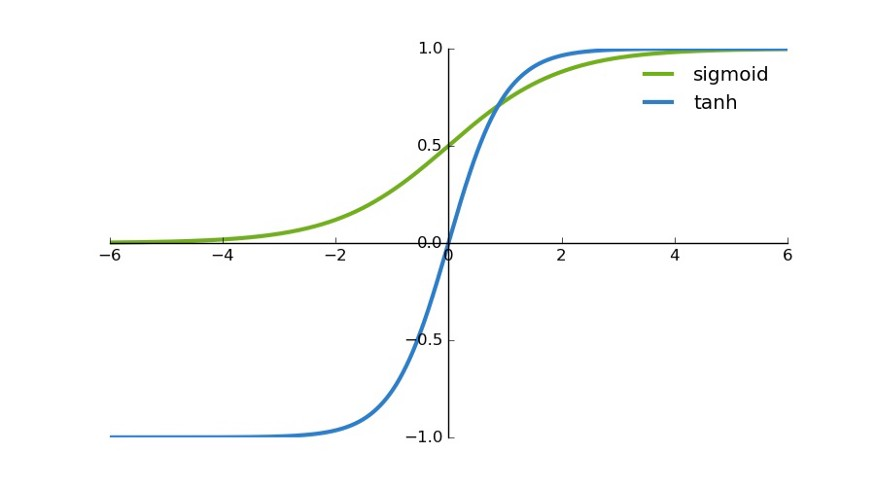
在一般的二元分类问题中,tanh 函数用于隐藏层,而 sigmoid 函数用于输出层,但这并不是固定的,需要根据特定问题进行调整。
ReLU 激活函数

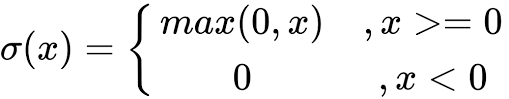
ReLU的偏导数为:
g'(z)= 0 (z<0)
g'(z)= 1 (z>=0)
ReLU 函数是深度学习中较为流行的一种激活函数,相比于 sigmoid 函数和 tanh 函数,它具有如下优点:
当然,它也有缺点:
-
Dead ReLU 问题。当输入为负时,ReLU 完全失效,在正向传播过程中,这不是问题。有些区域很敏感,有些则不敏感。但是在反向传播过程中,如果输入负数,则梯度将完全为零,sigmoid 函数和 tanh 函数也具有相同的问题;
-
我们发现 ReLU 函数的输出为 0 或正数,这意味着 ReLU 函数不是以 0 为中心的函数。
relu激活函数为分段线性函数,为什么会增加非线性元素?
我们知道激活函数的作用就是为了为神经网络增加非线性因素,使其可以拟合任意的函数。那么relu在大于的时候就是线性函数,如果我们的输出值一直是在大于0的状态下,怎么可以拟合非线性函数呢?
relu是非线性激活函数。
为什么relu这种“看似线性”(分段线性)的激活函数所形成的网络,居然能够增加非线性的表达能力:
1、首先什么是线性的网络,如果把线性网络看成一个大的矩阵M。那么输入样本A和B,则会经过同样的线性变换MA,MB(这里A和B经历的线性变换矩阵M是一样的)。
2、的确对于单一的样本A,经过由relu激活函数所构成神经网络,其过程确实可以等价是经过了一个线性变换M1,但是对于样本B,在经过同样的网络时,由于每个神经元是否激活(0或者Wx+b)与样本A经过时情形不同了(不同样本),因此B所经历的线性变换M2并不等于M1。因此,relu构成的神经网络虽然对每个样本都是线性变换,但是不同样本之间经历的线性变换M并不一样,所以整个样本空间在经过relu构成的网络时其实是经历了非线性变换的。
3、还有一种解释就是,不同样本的同一个feature,在通过relu构成的神经网络时,流经的路径不一样(relu激活值为0,则堵塞;激活值为本身,则通过),因此最终的输出空间其实是输入空间的非线性变换得来的。
4、更极端的,不管是tanh还是sigmoid,你都可以把它们近似看成是分段线性的函数(很多段),但依然能够有非线性表达能力;relu虽然只有两段,但同样也是非线性激活函数,道理与之是一样的。
5、relu的优势在于运算简单,网络学习速度快
Softmax
Softmax 是用于多类分类问题的激活函数,在多类分类问题中,超过两个类标签则需要类成员关系。对于长度为 K 的任意实向量,Softmax 可以将其压缩为长度为 K,值在(0,1)范围内,并且向量中元素的总和为 1 的实向量。

Softmax 与正常的 max 函数不同:max 函数仅输出最大值,但 Softmax 确保较小的值具有较小的概率,并且不会直接丢弃。我们可以认为它是 argmax 函数的概率版本或「soft」版本。
Softmax 函数的分母结合了原始输出值的所有因子,这意味着 Softmax 函数获得的各种概率彼此相关。
Softmax 激活函数的主要缺点是:
-
在零点不可微;
-
负输入的梯度为零,这意味着对于该区域的激活,权重不会在反向传播期间更新,因此会产生永不激活的死亡神经元。