使用线性回归构建波士顿房价预测模型
描述
波士顿房价数据集统计了波士顿地区506套房屋的特征以及它们的成交价格,这些特征包括周边犯罪率、房间数量、房屋是否靠河、交通便利性、空气质量、房产税率、社区师生比例(即教育水平)、周边低收入人口比例等 。我们的任务是根据上述数据集建立模型,能够预测房屋价格及其走势。
本任务涉及的主要实践内容:
1、 线性回归预测模型的构建
2、 模型的预测与评估
3、 使用matplotlib绘制房价预测曲线
源码下载
环境
-
操作系统:Windows 10、Ubuntu18.04
-
工具软件:Anaconda3 2019、Python3.7
-
硬件环境:无特殊要求
-
依赖库列表
matplotlib 3.3.4
numpy 1.19.5
pandas 1.1.5
scikit-learn 0.24.2
mglearn 0.1.9
分析
任务的输出(房价)是个连续值,因此这是一个回归问题,算法的目的是寻找房屋的特征数据和房价之间的规律(即回归函数)。
本任务涉及以下几个环节:
a)加载、查看波士顿房价数据集
b)将数据拆分为训练集与测试集
d)构建线性回归模型,拟合训练数据、
e)预测房价
f)评估模型
g)利用Matplotlib生成房价预测走势曲线
实施
1、加载、查看波士顿房价数据集
from sklearn.datasets import load_boston # 引入load_boston函数
from sklearn.model_selection import train_test_split # 引入数据集拆分函数
from sklearn.linear_model import LinearRegression # 引入LinearRegression类
# 加载boston数据集
boston = load_boston()
print(boston.keys()) # 查看boston数据集的组成
print(boston.data.shape) # 查看输入数据的形状-(506套房屋数据,每条数据包含13个特征值)
print(boston.target.shape) # 查看标签数组的形状-(506套房屋的成交价格)
print(boston.feature_names) # 查看特征名称(房屋的13个特征名称)
输出结果:
dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename'])
(506, 13)
(506,)
['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO'
'B' 'LSTAT']
通过keys()函数可以查看数据集中有哪些Keys(即数据项),依次查看其数据项。
通过观察,我们可以看到,波士顿数据集的特征数据(data数组)包含506套房屋的数据,有“犯罪率”、“房间数量”、“房屋年龄”、“师生比”等13个特征值,这506套房屋对应的成交价格(即数据的标签)存放在target数组中。我们的任务是基于这506套房屋的交易数据建立一个回归模型,能够对波士顿地区的房价数据进行预测。(即寻找房屋的特征与房价之间的线性规律)
2、数据集拆分
# 将data和target随机拆分为训练集和测试集(test_size=0.25代表25%的数据作为测试集,75%为训练集)
X_train, X_test, y_train, y_test = train_test_split(boston.data, boston.target,
test_size=0.25, random_state=0)
print(X_train.shape, X_test.shape) # 查看拆分结果
print(y_train.shape, y_test.shape)
输出结果:
(379, 13) (127, 13)
(379,) (127,) # 379+127=506
通过scikit-learn中的train_test_split函数将数据集随机拆分成训练集与测试集。注意掌握train_test_split函数的参数含义及返回值定义。另外,在机器学习中,一般用大写X_表示输入数据(即特征数据),小写的y_表示输出数据(即标签)。
3、创建线性回归模型,拟合训练数据
# 创建模型
model = LinearRegression()
# 拟合训练数据(即将特征数据和标签数据交给模型去训练)
model.fit(X_train, y_train)
# 注意:上面两步也可以合并写成这样
# model = LinearRegression().fit(X_train, y_train)
注意:Scikit-learn中所有模型的使用都是同样的过程。因此,学习机器学习最重要的是在熟悉模型的思想原理、参数及优缺点的前提下,根据任务选择不同的模型来实现。
4、使用模型预测房屋价格
import numpy as np
# 预测测试集的输出(即测试集中房屋的房价)
y_pred = model.predict(X_test)
print(y_pred[:10])# 预测前10套房屋的价格
# 将预测结果与实际价格做对比
print('\n预测价格:', np.round(y_pred[:10])) # np.round()-四舍五入取整
print('实际价格:', np.round(y_test[:10]))
输出结果:
[10.92635315 34.36995076 30.80593435 43.33525222 19.107834 18.8326957
22.14409312 20.47370887 36.85094144 17.84471519]
预测价格: [11. 34. 31. 43. 19. 19. 22. 20. 37. 18.]
实际价格: [16. 44. 24. 50. 20. 20. 17. 22. 42. 13.]
在Scikit-learn中,模型的预测使用predict方法,但仅看预测结果我们无法得知模型的准确率,所以还需要进行模型的准确性评估。另外,我们还会使用Matplotlib绘图,将房价预测曲线与实际房价曲线做对比,结果一目了然。(Matplotlib是机器学习中不可或缺的可视化利器)
5、评估模型
# 使用score方法评估模型的成绩
train_score = model.score(X_train, y_train) # 获得模型在训练集上的成绩
test_score = model.score(X_test, y_test) # 获得模型在测试集上的成绩
print('Train set score:', train_score)
print('Test set score:', test_score)
输出结果:
Train set score: 0.7697699488741149
Test set score: 0.6354638433202116
Scikit-learn中,模型的评估使用score方法,参数1为输入特征数据,参数2为标签(即实际房价)。本任务没有对数据进行预处理,经过预处理后模型的准确性还会有所提高。数据预处理(缩放)会有一个专门的章节讲述,届时我们会做个对比。
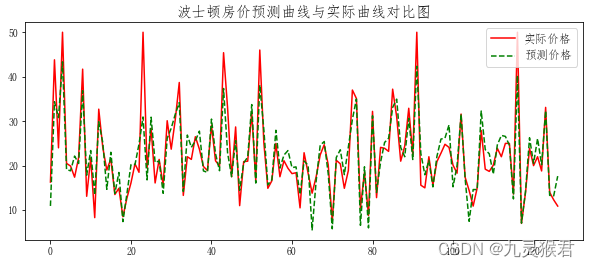
6、使用Matplotlib生成房价预测走势曲线
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 4)) # 设置画板尺寸
plt.rcParams['font.sans-serif'] = 'FangSong' # 设置中文字体
plt.title('波士顿房价预测曲线与实际曲线对比图', fontsize=15)
x = range(len(y_test)) # x轴数据
plt.plot(x, y_test, color='r', label='实际价格') # 实际价格曲线
plt.plot(x, y_pred, color='g', ls='--', label='预测价格') # 预测价格曲线
plt.legend(fontsize=12, loc=1) # 显示图例
plt.show()
显示结果:
7、使用岭回归(Ridge)建模
LinearRegression(标准线性回归)、Ridge、Lasso都在sklearn.linear_model模块中。Ridge和Lasso回归是在标准线性回归函数中加入正则化项,以降低过拟合现象。
from sklearn.datasets import load_boston # 引入load_boston函数
from sklearn.model_selection import train_test_split # 引入数据集拆分函数
from sklearn.linear_model import Ridge # 引入Ridge模型
# 加载boston数据集
boston = load_boston()
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(boston.data, boston.target,
test_size=0.25, random_state=66)
# 构建模型
model = Ridge(alpha=10).fit(X_train, y_train)
# 评估模型
train_score = model.score(X_train, y_train)
test_score = model.score(X_test, y_test)
print('train score:{:.2f}'.format(train_score), '\ntest score:{:.2f}'.format(test_score))
输出结果:
train score:0.70
test score:0.81