人脸识别分两个部分:
第一步:人脸图片预处理,即检测图片中人脸并裁剪成指定尺寸的人脸图。
第二步:人脸识别,包括模型训练、目标人脸分类训练、 预测目标人脸。
1. 人脸检测原理
人脸识别,首先得做人脸检测,也就是找到人脸在哪里,用矩形框框出位置。理想情况下,应该检测出图片中所有的人脸。
人脸检测模型:
1、MTCNN (TensorFlow)
2、SSD Face (Caffe)
获得人脸的矩形框后,然后就要做人脸对齐(Face Alignment),因为原始图片中,人脸的姿态、位置可能有较大区别,
为了统一处理,要把人脸“摆正”。“摆正”的方法,其实就是先找到人脸的关键点,比如眼睛、鼻子、嘴巴、脸轮廓等。根据这些
关键点,使用仿射变换将人脸统一标准,尽量消除姿势不同带来的误差。
这里采用基于TensorFlow的MTCNN(Multi-task convolutional neural networks) 模型。MTCNN是一种基于深度神经网络的
人脸检测和人脸对其的方法。MTCNN由3个神经网络构成,分别是P-Net,R-Net、O-Net。
在使用上述网络之前,要对原始图片进行预处理,先将原始图片缩放到不同尺寸,形成一个“图像金字塔”,如下图所示。
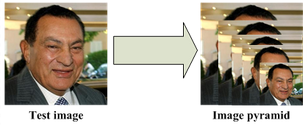
接着再对每个尺寸的图片通过神经网络计算一次。
这样做的原因是,原始图片中,人脸可能存在不同的尺寸,有的脸大,有的脸小。对于脸小的,可以在放大后的图片上检测,
对于脸大的,可以在缩小后的图片上检测,这样就可以在统一的尺寸下检测人脸了。
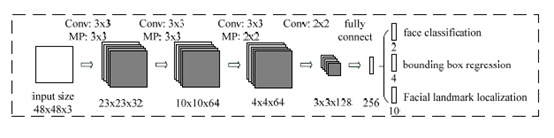
1、P-Net网络结构

如上图所示,就是一个P-Net网络结构,输入是一个12123的RGB图像块,该网络要判断这个12*12的图像中是否有人脸,
并给出人脸框和关键点(左眼、右眼、鼻子、左嘴角、右嘴角)位置。所以,对应有三个输出,下面分别介绍,
第一个输出(face classification):判断该图像是否是人脸。输出形状为112,其实就是两个值,分别对应该图像是人脸的概率
和该图像不是人脸的概率。这两个值加起来严格等于1。
第二个输出(bounding box regression):框回归,就是给出框的精确位置。输入的12*12的图像块可能不是完整的人脸框位置。
比如,有时候人脸并不是正好为方形;有时候图像块可能偏左,或偏右。所以,需要输出当前框位置相对与完整的人脸框位置的偏移,
这个偏移由4个变量组成。(一般图像中的框由4个数表示,分别为框左上角的横坐标、框左上角的纵坐标、框的宽度、框的高度),
所以,框回归的输出值为:框左上角的横坐标的相对偏移、框左上角纵坐标的相对偏移、框的宽度的误差、框高度的误差。所以输出
向量的形状为114.
第三个输出(Facial landmark localization): 这个输出就是给出人脸5个关键点的位置。分别为左眼的位置、右眼的位置、鼻子的
位置、左嘴角的位置、右嘴角的位置。每个关键点由横坐标和纵坐标表示,所以输出向量的形状为1110.
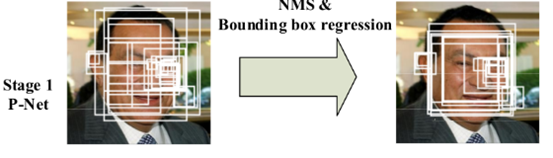
如上图所示,在实际计算中,通过P-Net中第一层卷积的移动,会对图像中的每一个12*12区域做一次人脸检测,得到结果
如上图所示。图中框的大小不一,除了框回归的影响之外,主要的原因是图片“金字塔”中的各个尺寸都用P-Net就算过一次,
所以形成的大小不同的人脸框。上面得到的结果很粗糙,还需要进一步优化,这就是R-Net网络的工作了。
2、R-Net网络

如上图所示,就是一个R-Net网络结构,输入是一个24243的RGB图像块,R-Net的作用也是判断24243的图像块中
是否包含人脸,以及给出关键点的位置。R-Net的输出和P-Net的输出结构和含义完全一样。
在实际应用中,一般都对每个P-Net输出的可能包含人脸的区域缩放到24243的大小,再输入到R-Net中。

经过R-Net优化后的结构如上图所示,消除了很多P-Net网络的误判情况。接着,将结果送给O-Net网络继续优化。
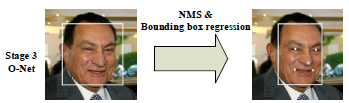
3、O-Net网络
如上图所示,就是一个O-Net网络结构,输入是一个48483的RGB图像块。O-Net网络的结构和P-Net网络结构
依然类似,只不过输入图像块的大小不一样,而且网络通道数和层数更多了。
如下图所示,就是经过了O-Net网络后的结果。
4、损失定义和训练过程
由上可知,每个网络的输出都是由3个部分组成,所以损失也是由这三个部分构成。
针对判断人脸是否存在的部分,直接使用交叉熵损失。针对框回归和关键点判定部分,使用L2损失。
最后由这三个部分损失各乘上自身的权重,再加起来,就形成最后的损失。
如何确定各自的权重呢?P-Net和R-Net更关心框位置的准确性,所以框位置的权重就比较大,
而O-Net更关心关键点的判定,所以关键点的权重就比较大。
2. 人脸预处理实例
开元源码工程
https://github.com/davidsandberg/facenet
下载完代码,
facenet-master\src\align 目录下
align_dataset_mtcnn.py 对齐
detect_face.py 人脸检测(MTCNN)
代码读者自行阅读
对齐命令,在facenet-master目录下运行:
python src/align/align_dataset_mtcnn.py …/test …/test_align_160 --image_size 160 --margin 32 --random_order
test为facenet-master同一级目录下,要预处理的图片文件夹:
Aaron_Eckhart 预处理前后的对比:
预处理前

预处理后

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)