最近重装SublimeText3和Anaconda,然后安装了pyquery包,跑代码
from pyquery import PyQuery as pq
在cmd>python,Anaconda Prompt>python,Anaconda Spyder下执行都没问题,
只有Sublime执行后控制台输出
ImportError: DLL load failed: 找不到指定的模块
#或者是这样的乱码
'python' �����ڲ����ⲿ���Ҳ���ǿ����еij���
查了一些资料,通过配置解决了。
网上相关内容太多,有些资料过时或没有解决问题。
这里整理记录一下方便以后重装。
一、首先关于Python环境变量
1. Anaconda和Python环境变量位置
在我的电脑,上鼠标右键,点属性,如图看到环境变量
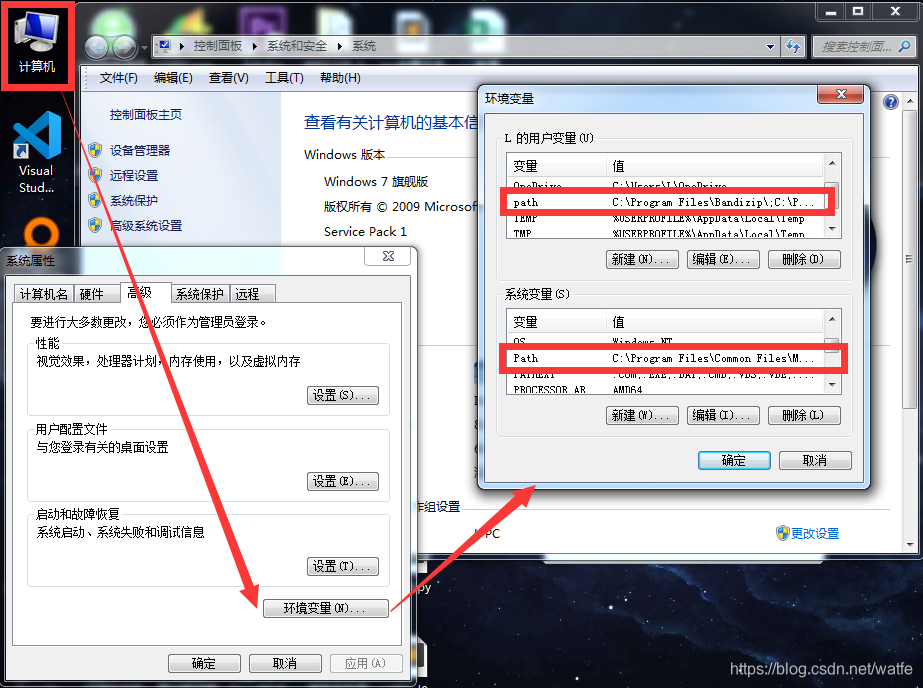
如果之前单独装过python和anaconda,
在用户变量和系统变量的path中,通常就会有写入内容。
另外系统变量中可能存在名为PYTHONPATH的变量。
在path中,下图中蓝色圈起来的部分,就是Anaconda相关的路径了。

Win7的path变量,所有路径是一行字符串,用";"号分开的;
而Win10后变成打开一排显示的每个路径的,
其实是一样的,都是将路径加入到path变量中。
2. 删除用不到的环境变量(谨慎操作)
因为我是卸载彻底重装,所以先将之前的python和anaconda相关环境变量都删了。
如果你有多个正在使用的python环境,请不要随意删除或改动环境变量
二、下载Anaconda安装
写这篇文章的时候,从官网下载到的是
Anaconda3-2020.02-Windows-x86_64.exe
可以从清华镜像站下载,注意最新版并不是最后一个,而是在页面中间偏下的位置,或者点一下日期栏排一下序。

双击安装包安装,如果不改安装路径的话,直接全点下一步。
遇到这一步的时候(借用网上的图,装的时候没截)
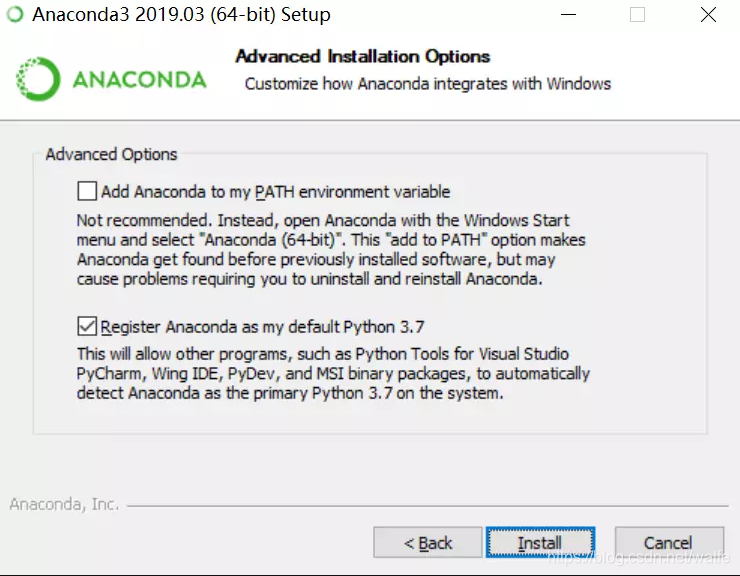
上面的 Add Anaconda to my PATH…… 默认是没勾选的。
这一项的作用就是问你,是否向系统中写入环境变量。
如果你已安装其他python环境的,建议你不要勾选。
如果没装其他python,以后也打算直接用Anaconda的,可以勾上。
勾选与不勾的对比:
勾选:
Anaconda会将自己写入环境变量,且排在其他软件的前面(勾了会在用户变量path变量值的最前面,添加以下内容C:\Users\L\anaconda3;C:\Users\L\anaconda3\Library\mingw-w64\bin;C:\Users\L\anaconda3\Library\usr\bin;C:\Users\L\anaconda3\Library\bin;C:\Users\L\anaconda3\Scripts;)。
不勾选:
不写入环境变量。最直观的体验就是,
你需要在Anaconda prompt中敲入python进入交互页面,
在cmd中敲入python是找不到的,因为系统不知道python在哪,pip或conda也一样。
然后点击安装,大概十几分钟装完。
如果没改安装路径安装路径的话,Anaconda Python解释器的默认路径一般为C:\Users\用户名\anaconda3\python.exe
三、安装SublimeText3
写这篇文章的时候,从官网下载到的是
Sublime Text Build 3211 x64 Setup.exe
1. 安装Sublime
没什么说的,官网下载,双击安装,1分钟装完。
2. 配置Anaconda插件(实现代码自动补全)
(1)安装插件控制台
Tool>install packages control,等待30s左右,成功弹窗提示你装好了;
Preferences>packages control,选 install package,等待30s左右,弹出输入栏。
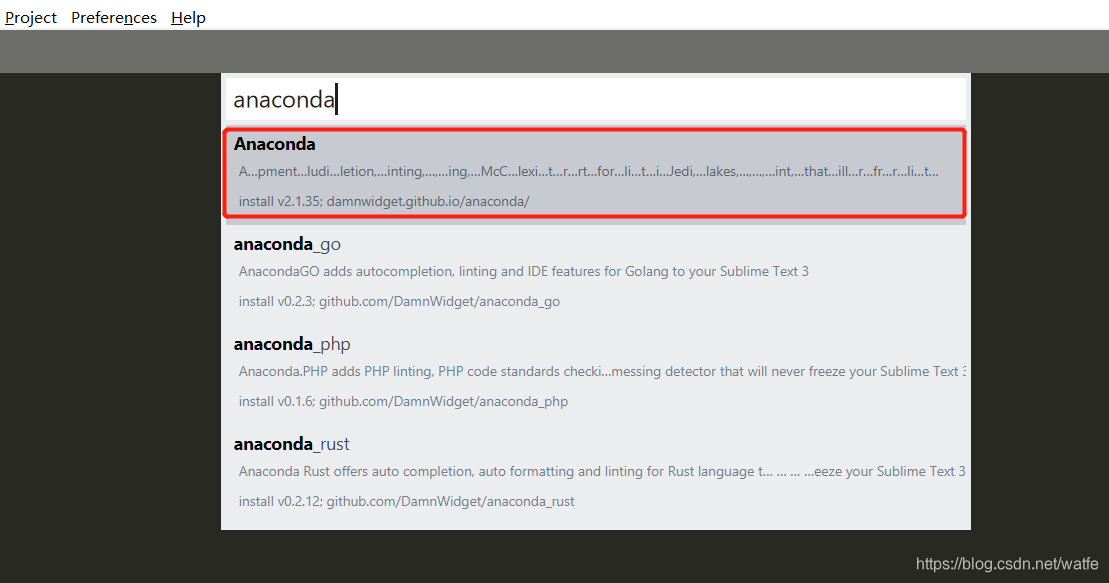
(2)安装Anaconda插件
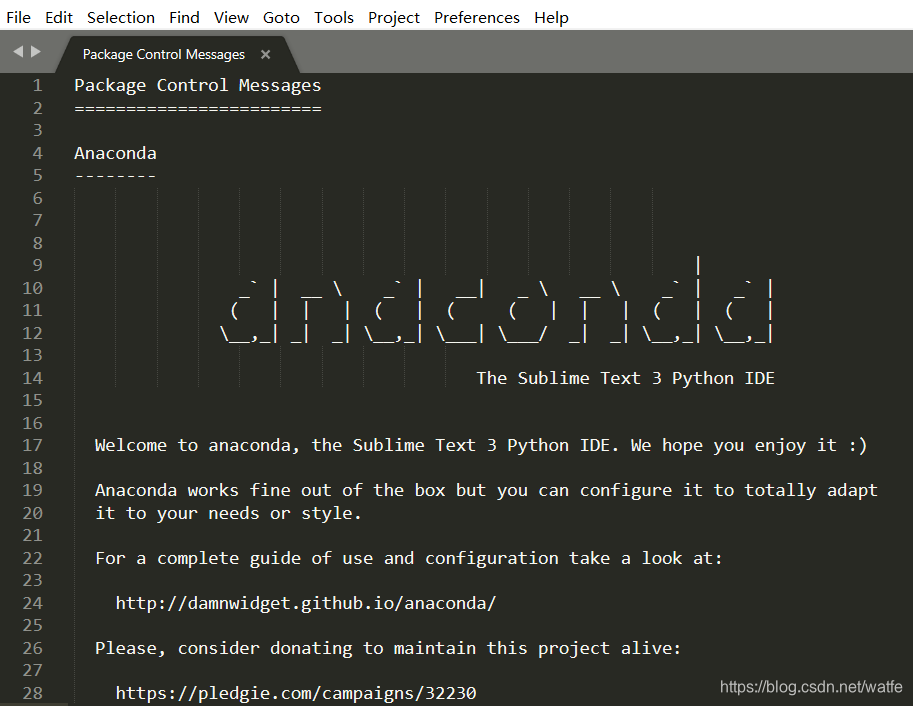
输入Anaconda,第一个就是,点击安装,安装成功跳出messages文档
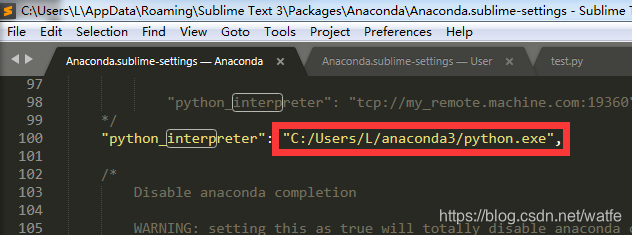
(3)配置Anaconda > Settings-Default:
点击Preferences > Package Settings > Anaconda > Settings-Default
找到“python_interpreter”修改为你安装的Anaconda python位置C:/Users/用户名/anaconda3/python.exe",然后保存
(4)配置Anaconda > Settings-Users:
点击Preferences > Package Settings > Anaconda > Settings-Users
粘贴以下内容后保存
{
"suppress_word_completions":true, //true会禁用sublime原生的自动补全,避免与anaconda补全冲突
"suppress_explicit_comletions":true, //同上
"complete_parameters":false, //true会导致print()带出一堆参数print(value, ..., sep, end, file, flush)
"swallow_startup_errors":true, //true可以避免一打开sublime,弹出错误窗“<Anaconda.anaconda lib.workers.local worker,LocalWorker object...”
"anaconda_linting":false, //true会出现一堆白框把代码圈起来,用于提示PEP8规范
}
配置完毕,关闭重开一下SublimeText3
3. Build System(Ctrl+B)执行python代码
有环境变量
如果安装Anaconda时,勾选了写入环境变量,直接Ctrl+B,然后选python执行就行
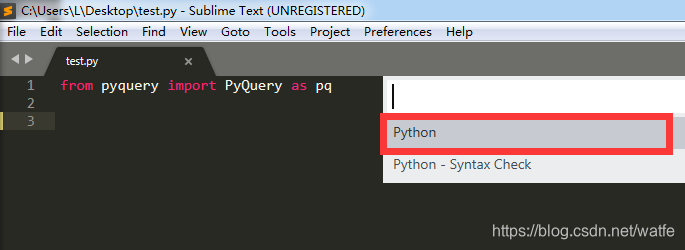
缺失环境变量 或 想要自定义
如果安装Anaconda时,没有勾选写入环境变量,就需要自己配置了。
点击Tools > Build System > New Build System…
粘贴以下内容(请结合自己安装路径修改)
{
"cmd": ["C:/Users/L/anaconda3/python.exe","-u","$file"],
"file_regex": "^[ ]*File \"(...*?)\", line ([0-9]*)",
"working_dir": "$file_path",
"selector": ["source.python"],
"path": "C:/Users/L/anaconda3;C:/Users/L/anaconda3/Library/mingw-w64/bin;C:/Users/L/anaconda3/Library/usr/bin;C:/Users/L/anaconda3/Library/bin;C:/Users/L/anaconda3/Scripts;",
"encoding": "utf-8",
"env": {"PYTHONIOENCODING": "utf8"}
}
保存,弹窗中修改文件名为 Anaconda3.sublime-build,点击保存。
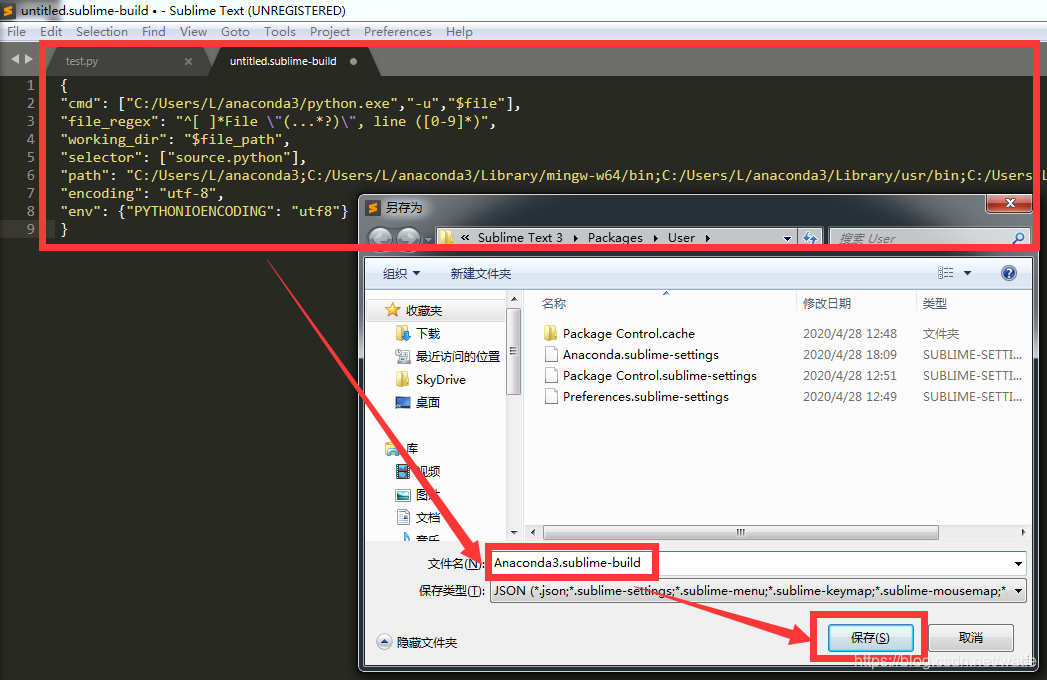
然后你会发现Build System中多了Anaconda3
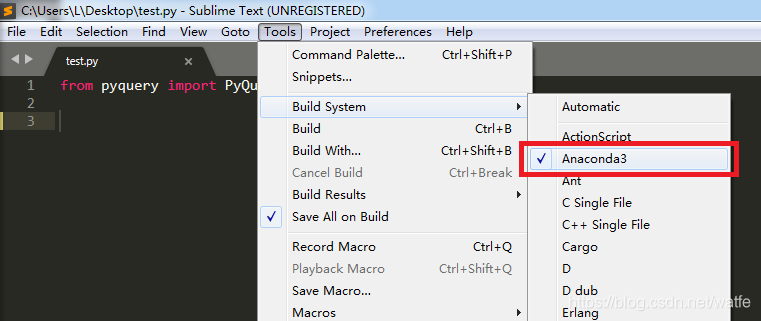
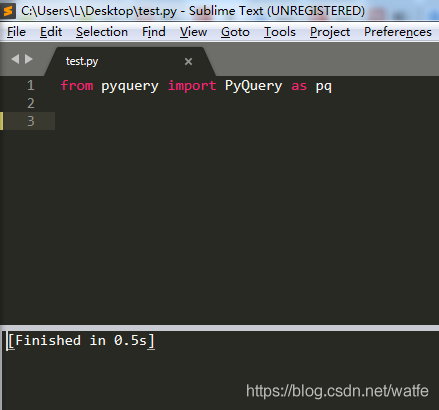
选中,然后再Ctrl+B,跑通了。
通过pip装上的pyquery包,能正常被import,说明配置成功了。
四、conda、pip基础指令与镜像代理
1. 基础指令
# pip 以 requests为例
pip install requests # 安装requests包
pip install requests==2.18.1 # 安装requests包2.18.1版
pip show requests # 查看已装requests包版本等信息
pip list # 列出所有已装模块及版本
pip list -o # 列出所有可升级的模块及版本
pip install --upgrade requests # 升级requests包
pip uninstall requests # 卸载requests包
pip install --upgrade pip # 更新pip本身
pip install pip-review # 可以安装pip-review,通过pip-review实现更新所有包
pip-review --local --interactive # 更新所有包
pip install -r requirements.txt # 批量下载安装项目依赖包(转移项目到其他机器时可能用到)
# conda 以requests为例
conda install requests # 安装requests包
conda install requests=2.18.1 # 安装requests包2.18.1版
conda list requests # 查看已装requests包版本等信息
conda list # 列出所有已装模块及版本
conda update requests # 升级requests包
conda uninstall requests # 卸载requests包
conda update conda # 更新conda本身
conda update anaconda # 更新anaconda(需先更新conda)
conda update --all # 更新所有包
2020-09-13
遇上RemoveError: ‘requests’ is a dependency of conda and cannot be removed from conda’s operating environment.
通过 conda update --force conda 强制更新解决
2. 更新包时,如果下载过慢,可以通过代理或使用镜像站的方式更新包
conda添加镜像站
内容引自
清华大学开源软件镜像站 - Anaconda 镜像使用帮助 https://mirror.tuna.tsinghua.edu.cn/help/anaconda/
执行
conda config --set show_channel_urls yes # 设置搜索时显示通道地址
目的是,确保生成了.condarc文件,然后打开C:/Users/用户名/.condarc,粘贴以下内容后保存
channels:
- defaults
show_channel_urls: true
channel_alias: https://mirrors.tuna.tsinghua.edu.cn/anaconda
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
然后执行
conda clean -i # 清除一下索引缓存
就添加完成可以使用了。
pip添加镜像站
创建C:\Users\用户名\pip文件夹,新建文件pip.ini,输入以下内容后保存
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host=mirrors.aliyun.com
上面是加了清华的,还有一些其他可用的镜像地址,可供选择:
http://pypi.douban.com/simple/ # 豆瓣
http://mirrors.aliyun.com/pypi/simple/ # 阿里
http://pypi.hustunique.com/simple/ # 华中理工大学
http://pypi.sdutlinux.org/simple/ # 山东理工大学
http://pypi.mirrors.ustc.edu.cn/simple/ # 中国科学技术大学
如果不添加镜像,只是单次使用,也可以通过以下方法:
# 临时通过代理下载
pip --proxy 127.0.0.1:25378 install 包名
# 临时通过镜像站下载
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名
五、其他
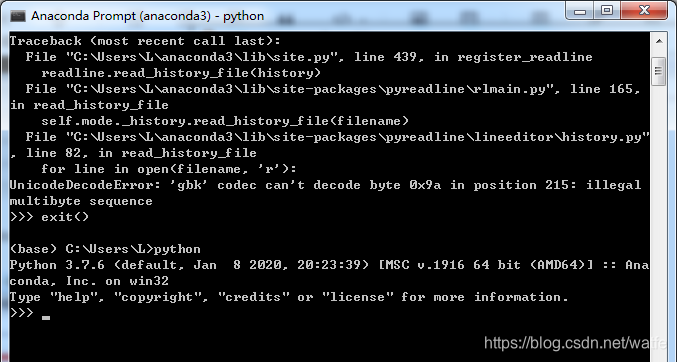
如果Anaconda prompt启动python遇到:UnicodeDecodeError: 'gbk' codec can't decode byte 0x9a in position 215: illegal multibyte sequence
从提示内容看,报错时正在read_history_file。
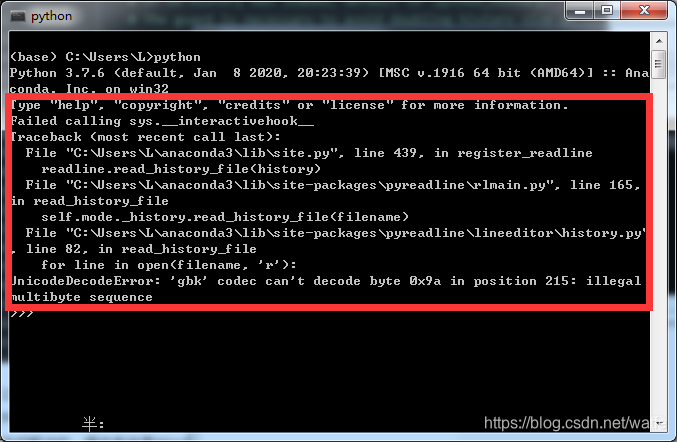
找到.python_history文件,删除掉。
再执行发现就正常了