初学者学习Pytorch系列
第一篇 Pytorch初学简单的线性模型 代码实操
第二篇 Pytorch实现逻辑斯蒂回归模型 代码实操
第三篇 Pytorch实现多特征输入的分类模型 代码实操
第四篇 Pytorch实现Dataset数据集导入 必要性解释及代码实操
第五篇 Pytorch实现多分类问题 样例解释 通俗易懂 新手必看
前言
- 本文利用Mnist数据集学习多分类问题。Mnist数据集相当于C语言的Hello World,是初学者必学的一个集合。

上图为MNIST数据集样图
一、先上代码
代码如下(解释已经写在代码中):
import numpy as np
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class DiabetesDataset(Dataset):
def __init__(self, filePath):
xy = np.loadtxt(filePath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0] # 返回了一个元组,获得维度
self.x_data = torch.from_numpy(xy[:, :-1]) # 记得有两个:
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset("../data/diabetes.csv.gz")
train_loader = DataLoader(dataset=dataset, shuffle=True, batch_size=32, num_workers=2)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(reduction="mean")
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
if __name__ == '__main__':
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
inputs, labels = data # 这里获取就是我们定义的getitem函数
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
二、代码编写解释
1. Mnist数据集
对于Mnist数据集,pytorch中已经提供给我们了,在下面的代码中我们导入了数据集,并放入
train_dataset = datasets.MNIST(root="../data/mnist", train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
我们从torchvision中导入dataset数据集,并从其中拿出MNIST数据集进行训练。
其中有几个参数如下:
-
train 是否是训练集
-
download 如果在对应位置没有数据集,是否下载
-
transform 变化的函数(讲解在下面)
2. Transform类(Stochastic Gradient Descent)
transform和datasets都是torchvision图形库中的东西,
torchvision包括下面四种
- datasets 有常用的数据集和数据加载函数
- models 有常用的模型结构
- transforms: 有如裁剪、旋转,转张量等图片变换基本形式
- utils: 其他方法
在我们的代码中,使用的是datasets和transforms这两个,datasets在上面已经有表述,这里着重表述transforms。
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize([0.1307, ], [0.3081, ])])
在代码中我们使用了transforms这个类的Compose方法去帮助我们变化我们的图片。
Compose方法的主要作用是将我们所要进行的图片变化操作串联起来,其参数为一个列表,我们将所要进行的变化放入其中。如上代码所示,我们是将图片转化为张量,再将张量进行Normalize归一化处理。
3. 标准化(Standardization)和归一化(Normalization)处理
为什么要进行归一化和标准化处理?
归一化的作用就是使区别比较大的特征缩小到某一范围内,便于统计分析,加快梯度下降的求解速度。
这里要注意归一化和标准化是不一样的
归一化的计算公式如下:
在我们的例子中,归一化,x代表0-255,最小是0,最大是255,所以每个x都会除以255,最后的数值的范围会缩小到[0,1]。由此实现归一化,但是此时并未进行标准化,此时的均值不为0,方差也不为1。
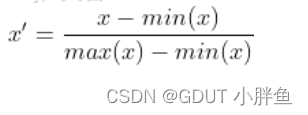
标准化的公式如下:
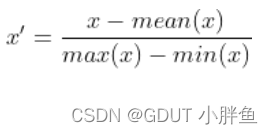
经过标准化后,能把均值转化为0,方差转化为1,而仅仅进行归一化的时候,并不具备这个性质。
通常来说,在深度学习中,我们会在图像训练前就对图像进行归一化和标准化的处理。
代码中的归一化处理我们使用的是零均值标准化,即均值为0,方差为1的标准化方法。
- 均值:也就是平均值,
- 方差:公式如下

在使用transforms.ToTensor() 的时候,我们将图片的形式从 (H x W x C) 转换到 (C x H x W) ,C为通道数Channel,H为高Height,W为宽Width,并进行归一化(依据公式,操作是除以255),但此时还没进行标准化。
在进行完ToTensor操作后要进行标准化,即使用transforms.Normalize函数,参数为均值和方差的两个列表。
注意:
- 这里Normalize是进行了标准化,而不是归一化,这个词有多个意思
- 当Normalize输入的均值和方差只有一个维度(单通道)的时候,list后要加一个逗号
 0.1307和0.3081是很多人在使用MNIST数据集后早已计算过的,我们拿过来使用即可。
0.1307和0.3081是很多人在使用MNIST数据集后早已计算过的,我们拿过来使用即可。
这里其他博主也做了一些小实验,我觉得文章对理解这部分知识点非常有帮助,链接如下:
PyTorch学习笔记——图像处理(transforms.Normalize 归一化)
4. 损失函数使用torch.nn.CrossEntropyLoss
由于我们的结果是多分类问题,以前的二分类问题的二分类交叉熵损失BCELoss已经不再适用于多分类中。
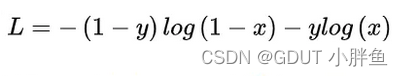
上图为而二分类损失函数。
CrossEntropyLoss中是包括了Softmax和求多分类交叉熵两个操作的。
Softmax:在多分类问题中,我们需要结果标签中的不同类别之间有相互抑制的效果(这个标签概率高,其他的就概率低,不能每一个都高),且满足分布(概率>=0,概率和=1),这时候用sigmoid是无法实现的,需要使用Softmax函数实现。我们在代码中,前几层都使用sigmoid进行更新即可,到最后一层使用Softmax进行更新,使我们的数据满足以上条件。
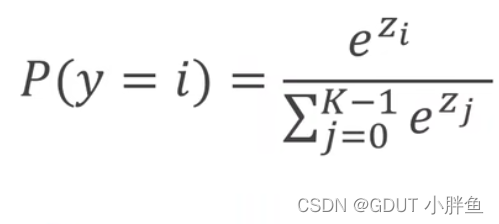
softmax函数如上,eZi能够让概率值永远>=0,而分母和则能让各个概率计算结果的和为1。
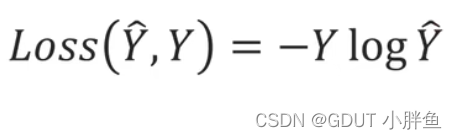
在多分类问题中,我们使用的交叉熵函数如上图,Y为预测值(在我们例子中为0或1),Y^为预测概率,而在多个分类中,因为分类只有一种,所以只有一个标签为1,其余为0(可以观察一下二分类的交叉熵,也是属于其中一个类的时候,其中有一个log项会因为前面系数为0而不用计算)。
CrossEntropyLoss就是进行上面两部操作。这里把刘二大人的示例图贴上,便于理解。
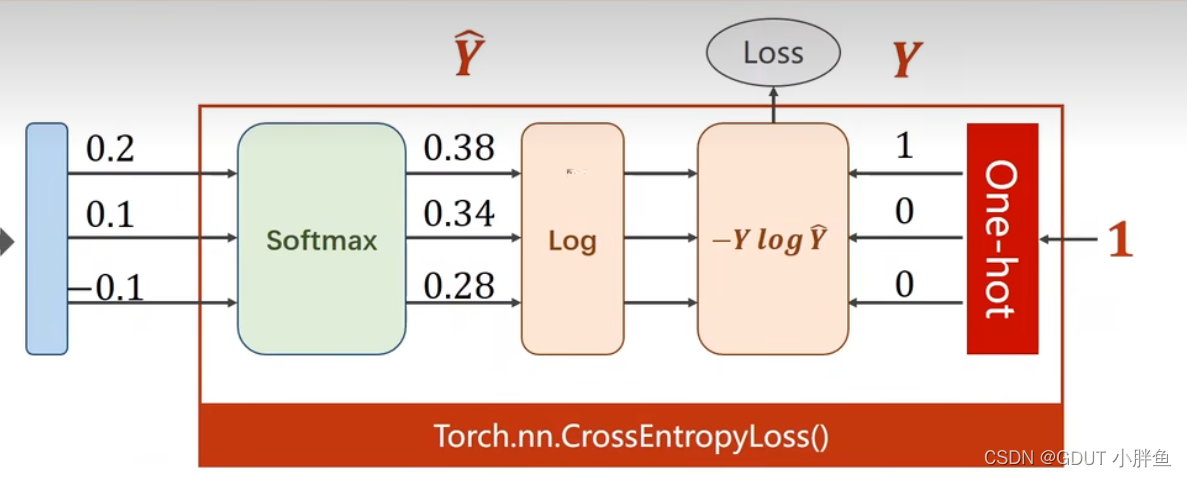
至于loss函数为什么使用log,前面还有负号,可以从数学上理解它
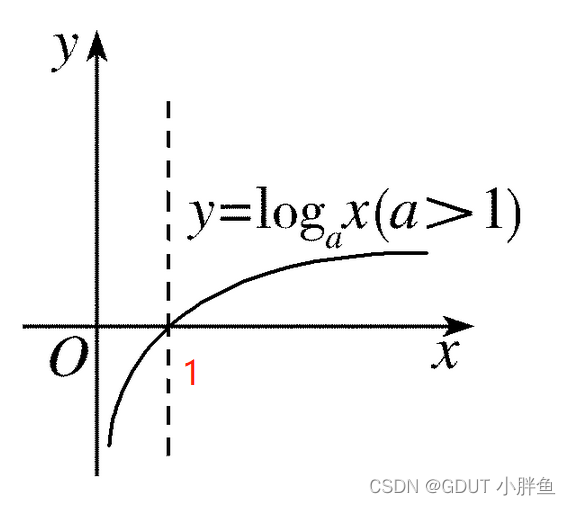
先给出一个log的图像,从图像上看,越接近1,它的loss数值越小,也就预测得越准,但是这个数值是负数的,所以前面加一个负号。
5. 优化器optimizer使用momentum参数
momentum是动量的意思,能够帮助梯度方向的调整。调整方法是按照历史梯度的方向和目前新的梯度方向结合进行调整(下面会具体讲解)。
为什么需要调整梯度方向?
那么momentum是怎么帮助梯度下降的呢?
对于线性模型来说,假如我们有W和B两个变量需要更新,那后台会多设置两个变量(假如为 Wi 和 Bi),用于记录 W 和 B 的历史梯度值。
在新的梯度值出来的时候(新梯度值表示为 dw 和 db ),我们使用一个参数 β(由我们设定)去更新 Wi 和 Bi。再用 Wi 和 Bi 去更新 W 和 B,而不使用momentum的时候是直接使用 dw 和 db 去更新 W 和 B 的。
步骤如下:
- Wi = β * Wi + (1 - β )* dw
- Bi = β * Bi + (1 - β )* db
- W = W - α * Wi
- B = B - α * Bi
注意:α为我们设置的学习率
在我们的代码中,我们在SDG函数中设置了momentum参数,其实就是参数,意思是要在多大程度上保留原来的梯度更新方向。
Tip:这里给出一个链接,可以直观地看到momentum的变化,它下面有学习率和momentum两个参数可以调整。
momentum的变化网址
6. with torch.no_grad():
我们在 test() 中,不再更新参数,只是对当前的数值的正确率进行评估,所以不需要追踪梯度,梯度就是多元函数参数的变化趋势, 只有一个自变量的时候为导数。
我们构建的model() 在计算的时候会追踪梯度,然后通过loss的backward进行回溯放在Tensor的grab中
7. 测试模块
测试中我们输出了准确率,代表我们模型的好坏程度。
在测试中,使用了DataLoader,具体为test_loader,因为在全局变量中定义了batch_size为64,所以,我们一次是拿64个图片进行测试,不是一个!!不是一个!!!!
所以在下面这语句中,如果我们输出outputs的shape,可以发现为[64,10],64个样本,每个有10种可能。
outputs = model(images)
这时候我们想知道我们正确的个数,那自然要拿得出的结果和labels的进行比较。但是!有个问题,我们的的结果经过model()后得到的outputs是概率值。而我们的labels是0-9的数字,代表我们的结果。
这里运用一个很巧妙的办法!我们知道outputs是[64,10]维度,在第1维度(从0开始)中,有10个概率,我们取概率最大的下标,下标0-9正好代表我们0-9的数字,这就是我们要预测,所以我们使用max函数去搜索最大值。
torch.max(inputs,dim)inputs是输入的张量的data,dim是指定维度开始寻找
_, predicted = torch.max(outputs.data, dim=1)
在这种参数输入形式中,max会返回64样本中每一个的最大值,并返回下标,我们分别存储到两个变量中,因为概率的最大值我们不需要使用,所以使用 ‘_’ 充当变量
_的值:
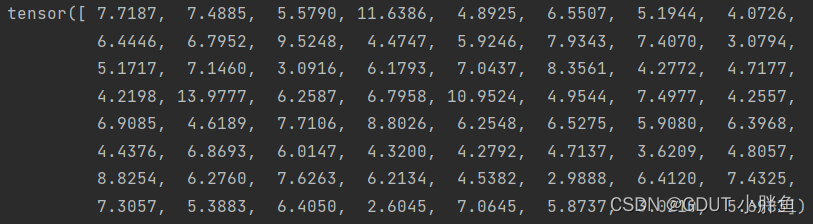 predicted的值:
predicted的值:

后面就简单了,正确数我们使用predicted的值和labels去比较,然后加起来。而总数我们使用Tensor的size函数 (是函数,不是变量,也不是列表) ,参数传入指定维度,获得其大小。两个数一除得准确数。
8. 全连接神经网络的输入问题
我们这个训练模型是一个全连接的神经网络,它要求输入必须为矩阵,我们的图像输入其实为[N,1 ,28,28]这个维度,N代表样本数,1代表通道数,28是纵轴 / 横轴的像素数量。这样子的形状不是矩阵,不支持输入。所以我们在Net类的输入中,才会使用view( ) 改变张量的形状,变成[N,784],784=28 * 28 * 1 ,而view的第一个参数为-1,意思是让模型自己去匹配,我们不确定,因为我们输入的样本数量可能会变化。
总结
以上就是Pytorch实现多分类问题的内容,对于初学者来说,搞懂原理搞懂基础,我认为是十分重要的。讲解过程属于个人理解,如表述有误,请谅解。如果觉得有用,请大家点赞支持!!!!。