很多人都觉得 eBay 在 QCon (北京) 上的技术讲座不错,但对我来说,其实冲击力没那么大了。eBay 一两年前就是这个 PPT 。不过还是比 Amazon 的 Jeff Barr 强了很多,以后要是开个什么会,你把 Jeff Barr 请来还讲那个销售文档,估计自己都不好意思。
不过,eBay 这次的PPT 总算还是有点更新的。
1)数据分片(Partition Everything)
说是分区(Partition),这里不能简单等同于 Oracle 的分区,理解成分片(Sharding)就好啦。可以参考一下我以前写的科普小文:开源数据库 Sharding 技术 (Share Nothing)。这里要强调一下的是,分片是在数据量的确有规模的时候才适合进行,如果单节点足以应付,那么还是不要冒进。
从分片的模式上,eBay 主要根据功能切分(Functional Segmentation)和水平分割(负载均衡考虑),作为推论,所有会话都是无状态性的。
2)异步处理(Asynchrony Everywhere)
其实对于任何网站来说,过度追求"同步"化设计还是比较糟糕的做法。以用户能观察到的数据为视角进行设计,中间可以最大限度用异步来完成。
eBay 的举例的模式有两个,一个是事件队列(Event Queue),另一个是信息分发(Message Multicast)。前者基本上是个生产者--消费者的模型。后者主要用在搜索的架构上。
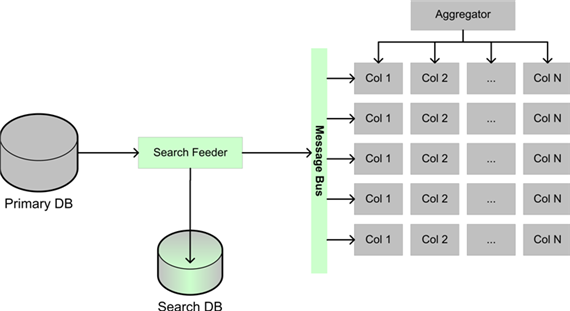
注意到图中的消息总线,这才是 eBay 整个架构中的动脉,估计轻易不会批露技术细节
3)自动化(Automate Everything)
这里的自动化举了两个例子,一个是针对运维方面的,另外举了关于机器学习的东西,这是演讲者 Randy Shoup 的强项所在。
eBay 的自动化,在一年前的另一篇文章里可以窥测一点东西。只是这篇文章当初没有被更多人重视,参见:eclipse at eBay。可以看到 eBay 能在自动化方面做得这么好(起码敢出来讲)不是一朝一夕之功。
4)故障检测与回溯(Remember Everything Fails)
更好的失败检测机制: 监控每天超过 2TB 的日志,根据日志中的相关事件得出判断或者预警。这个看起来简单,但实现起来还是需要一点技巧和策略的,重要的是,需要不断根据结果的反馈去改进。
完美回滚: 任何服务都通过服务配置中的标记来识别,无痛回滚。(个人感觉这个非常有难度,尤其是升级的时候)
优雅降级(Graceful Degradation):能够相对容易的对应用标记"Marks down(下线)"
5)拥抱不一致性(Embrace Inconsistency)
举了 CAP 原则,程立将其形象描述为帽子戏法,非常准确。说起一致性,自从 Amazon CTO Werner Vogels的 Eventually Consistent 一出,基本上不需要我废话了,这就是事务处理的九阴真经,大家回家慢慢参详好了。
eBay 也有自己的绝对准则: 绝对没有分布式事务(两阶段提交), 通过状态机与操作顺序最小化不一致性,通过异步事件(消息总线?)达到最终一致性。
--EOF--
另外小道消息:Amazon CTO Werner Vogels 可能会参加六月份在杭州举办的侠客行大会。
以前的老帖子:eBay 的Scalability最佳实践