深度优先遍历简称DFS(Depth First Search),广度优先遍历简称BFS(Breadth First Search),它们是遍历图当中所有顶点的两种方式。下面分别介绍两种基本的搜索算法。
理论介绍
深度优先遍历DFS
DFS属于图算法的一种,是针对图和树的遍历算法。深度优先搜索是图论中的经典算法,利用深度优先搜索算法可以产生目标图的相应拓扑排序表,利用拓扑排序表可以方便的解决很多相关的图论问题,如最大路径问题等等。一般用堆或栈来辅助实现DFS算法。其过程简要来说是对每一个可能的分支路径深入到不能再深入为止,如果遇到死路就往回退,回退过程中如果遇到没探索过的支路,就进入该支路继续深入,每个节点只能访问一次。
广度优先遍历BFS
广度优先搜索(也称宽度优先搜索)是连通图的一种遍历算法,也是很多重要的图的算法的原型。Dijkstra单源最短路径算法和Prim最小生成树算法都采用了和广度优先搜索类似的思想。属于一种盲目搜寻法,目的是系统地展开并检查图中的所有节点,以找寻结果。换句话说,它并不考虑结果的可能位置,彻底地搜索整张图,直到找到结果为止。基本过程,BFS是从根节点开始,沿着树(图)的宽度遍历树(图)的节点。如果所有节点均被访问,则算法中止。一般用队列数据结构来辅助实现BFS算法。
广度优先搜索应用:层序遍历、最短路径、求二叉树的最大高度、
由点到面遍历图、拓扑排序
深度优先搜索应用:先序遍历,中序遍历,后序遍历
图解
假设从0开始访问所有节点,可能的路径有哪些?
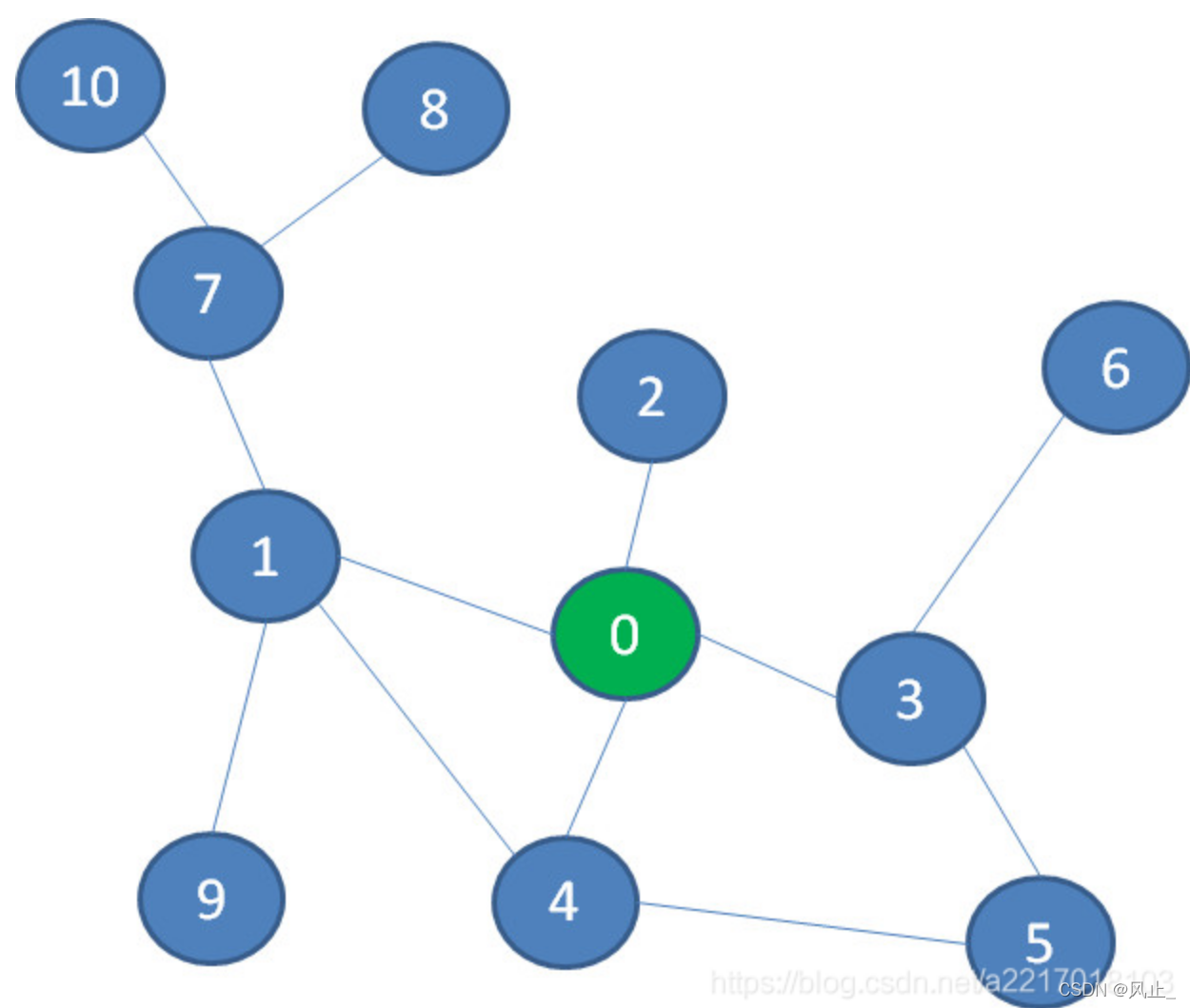 (1)DFS方法
(1)DFS方法
首先选择1,然后到7、8,发现走不动了。
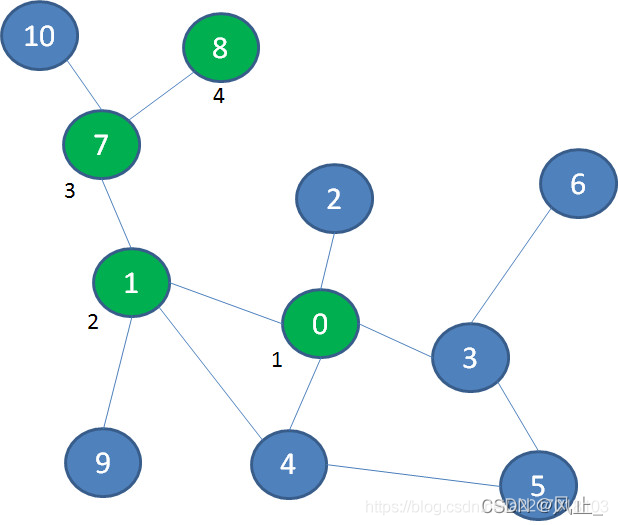
然后退回到7,再探索节点10。回退到1,探索9: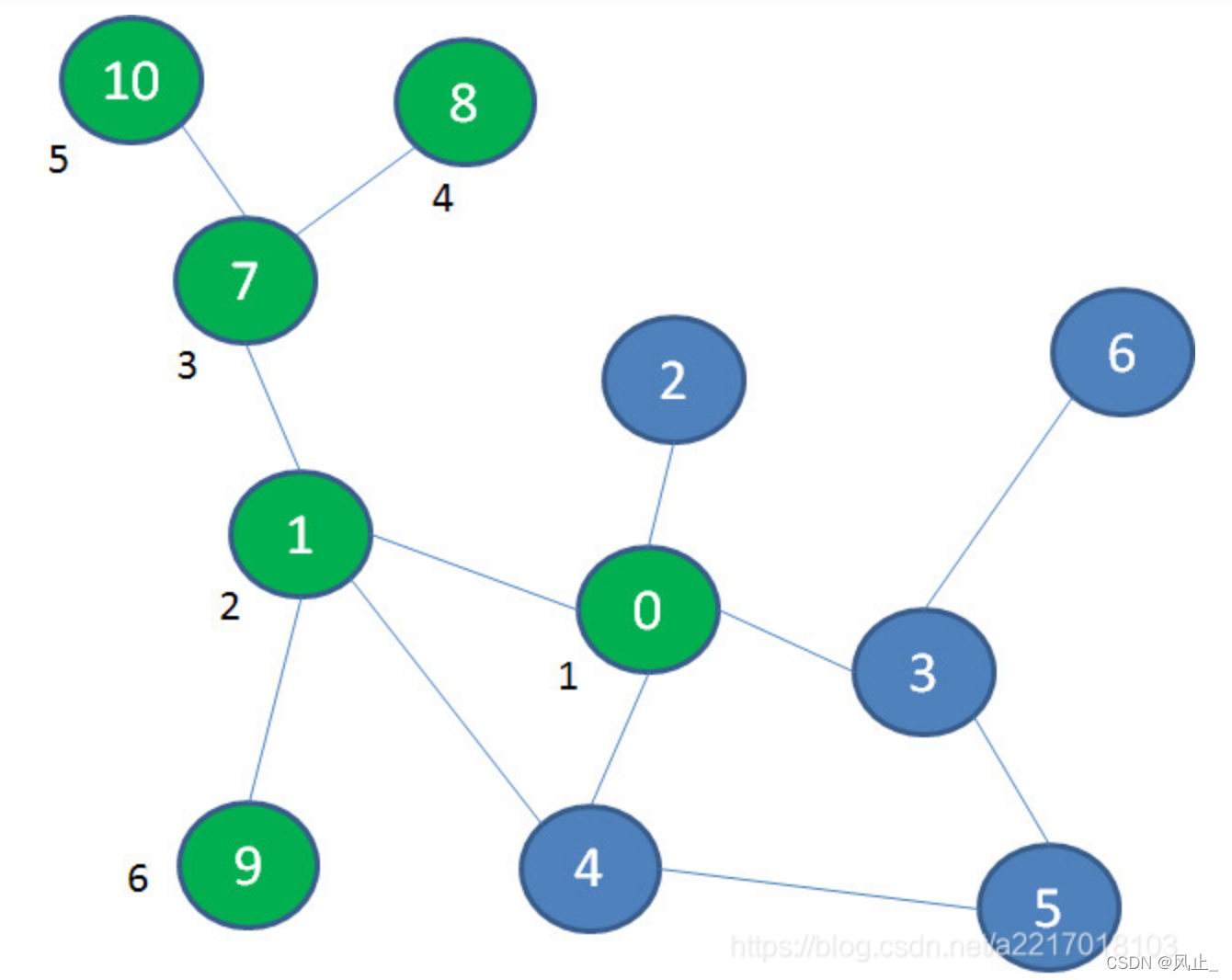
再退回到景点0,后续依次探索2、3、5、4、6,走完所有节点: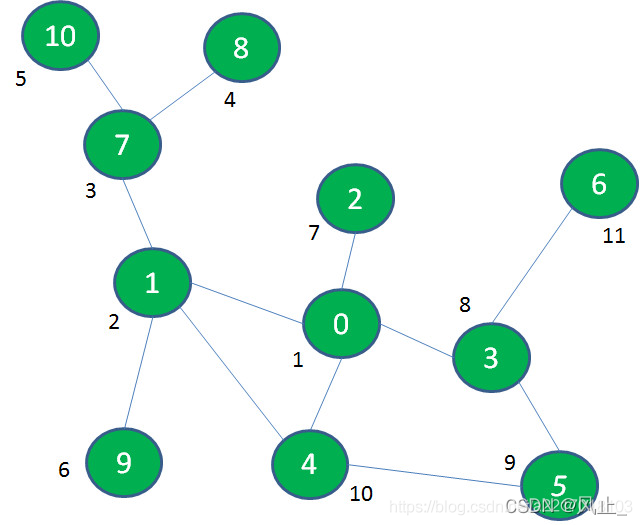
二叉树的前序、中序、后序遍历,本质上可以认为是深度优先遍历。是一种回溯思想。
(2)BFS方法
首先探索节点0的相邻节点1、2、3、4:
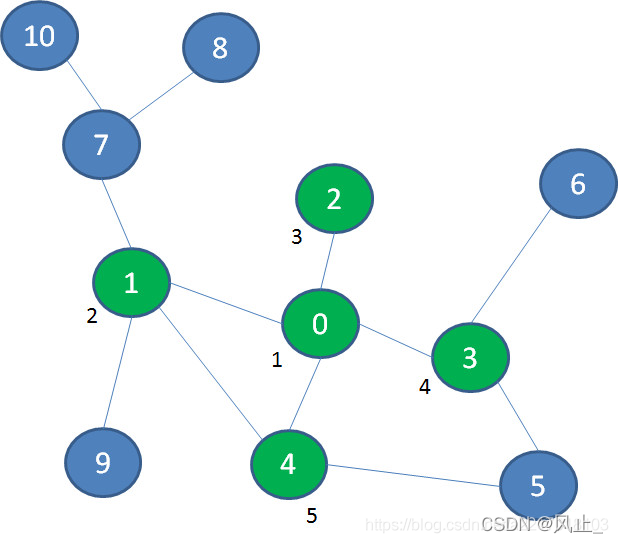 接着,探索与节点0相隔一层的7、9、5、6:
接着,探索与节点0相隔一层的7、9、5、6:
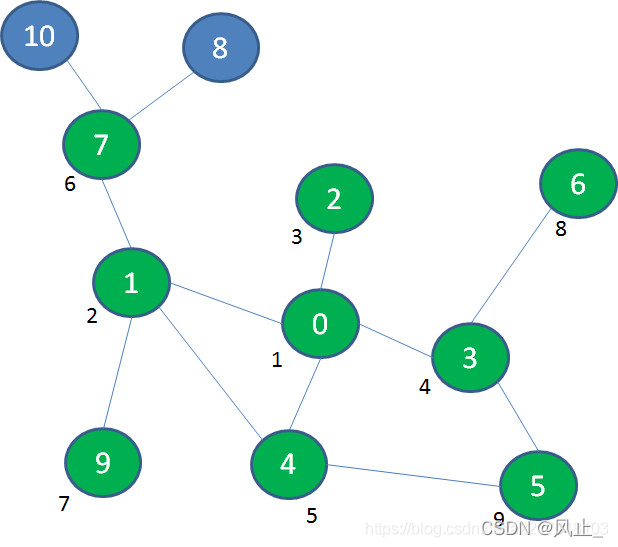 最后,探索与节点0相隔两层的节点8、10:
最后,探索与节点0相隔两层的节点8、10:

可以看出,BFS是一层一层的由内向外遍历,二叉树的层序遍历本质上可以认为是广度优先遍历。
代码框架
DFS
非递归:
1.利用栈实现
2.从源节点开始把节点按照深度放入栈,然后弹出
3.每弹出一个点,把该节点下一个没有进过栈的邻接点放入栈
4.直到栈为空
BFS
1.利用队列实现
2.从源节点开始依次按照宽度进队列,然后弹出
3.每弹出一个节点,就把该节点所有没有进过队列的邻接点放入队列
4.直到队列为空
供参考:
class Graph:
# *args 把参数打包成tuple供函数调用。**kwargs把 x = a,y=b打包成字典{x:a,y:b}供函数调用
def __init__(self, *args, **kwargs):
self.neighbors = {}
self.visited = {}
def add_nodes(self, nodes):
for node in nodes:
self.add_node(node)
def add_node(self, node):
print('self.nodes()',self.nodes())
if node not in self.nodes():
self.neighbors[node] = [node]
def add_edge(self, edge):
u, v = edge
if u not in self.neighbors[v] and v not in self.neighbors[u]:
self.neighbors[u].append(v)
if u != v: # 没有自环
self.neighbors[v].append(u)
def nodes(self):
return self.neighbors.keys()
# 递归 DFS
def depth_first_search(self, root = None):
order = []
def dfs(node):
self.visited[node] = True
order.append(node)
for n in self.neighbors[node]:
if n not in self.visited:
dfs(n)
if root:
dfs(root) # dfs(0)
# print('visited', self.visited)
#对于不连通的结点(即dfs(root)完仍是没有visit过的单独处理,再做一次dfs
for node in self.nodes():
if node not in self.visited:
dfs(node)
self.visited = {}
print(order)
# print('final visited', self.visited)
return order
# 非递归 DFS
def depth_first_search_2(self, root=None):
stack = []
order = []
def dfs():
while stack:
print('stack',stack)
node = stack[-1] # 栈顶元素
for n in self.neighbors[node]:
if n not in self.visited:
order.append(n)
stack.append(n)
# stack.append(self.neighbors[n])
self.visited[n] = True
print('self.visited', self.visited)
break
else:
stack.pop()
if root:
stack.append(root)
order.append(root)
self.visited[root] = True
dfs()
for node in self.nodes():
if node not in self.visited:
stack.append(node)
order.append(node)
self.visited[node] = True
dfs()
# self.visited = {} # 非必须
print(order)
return order
# BFS
def breadth_first_search(self,root=None):
que = []
order = []
def bfs():
while len(que) > 0: # 队列非空
node = que.pop(0) # 从左侧开始弹出 list对象有pop但是没有popleft
self.visited[node] = True
for n in self.neighbors[node]:
print('self.visited', self.visited)
print('que', que)
if n not in self.visited and n not in que:
que.append(n)
order.append(n)
if root:
que.append(root)
order.append(root)
bfs()
for node in self.nodes():
if not node in self.visited:
que.append(node)
order.append(node)
self.visited = {}
print(order)
return order
参考:
https://blog.csdn.net/weixin_40314737/article/details/80893507